前言
历史考试选择题:黄花岗起义枪谁开的? A宋教仁 B孙中山 C黄兴 D徐锡麟,考生选C。
又看第二题:黄花岗起义第二枪谁开的? 考生傻了,就选了个B。
接着看第三题:黄花岗起义中,第三枪谁开的? 考生疯了,胡乱选了A。
考试出来就去找出卷老师。老师拿出课本说:黄兴连开三枪,揭开了黄花岗起义的序幕。考生:......
相信大家都用过CASE表达式,尤其是做一些统计功能的时候,用的特别多,可真要说什么是 CASE表达式,我估计还真没几个人能清楚的表述出来。
CASE表达式和 “2+1” 或者 “120/3” 这样的表达式一样,是一种进行运算的功能,正如CASE(情况)这个词的含义一样,用于区分情况,在有条件分歧的时候使用它。
CASE表达式是从 SQL-92 标准开始被引入的,可能因为它是相对较新的技术,所以尽管使用起来非常便利,但其真正的价值却并不怎么为人所知。很多人不用它,或者用它的简略版函数,例如 DECODE(Oracle)、IF(MySQL)等。然而,CASE表达式也许是 SQL-92 标准里加入的有用的特性,如果能用好它,那么 SQL 能解决的问题就会更广泛,写法也会更加漂亮,而且,因为 CASE表达式 是不依赖于具体数据库的技术,所以可以提高 SQL 代码的可移植性。
基本格式如下
-- 简单 CASE表达式
CASE 列(或表达式)
WHEN <匹配值1> THEN <表达式>
WHEN <匹配值2> THEN <表达式>
......
ELSE <表达式>
END
-- 搜索 CASE表达式
CASE WHEN <判断表达式> THEN <表达式>
WHEN <判断表达式> THEN <表达式>
WHEN <判断表达式> THEN <表达式>
......
ELSE <表达式>
END
-- 简单 CASE表达式 示例
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他'
END
-- 搜索CASE表达式 示例
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他'
END
CASE表达式 之妙用
行转列
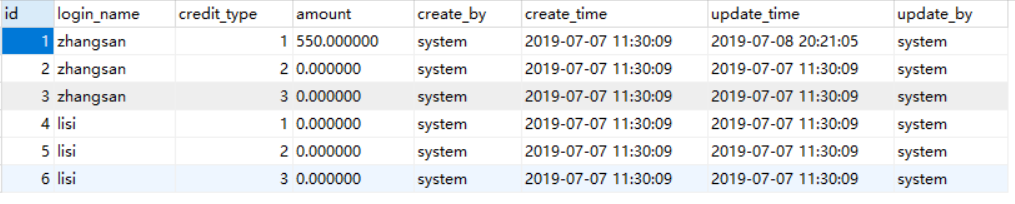
CREATE TABLE t_customer_credit (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键',
login_name VARCHAR(50) NOT NULL COMMENT '登录名',
credit_type TINYINT(1) NOT NULL COMMENT '额度类型,1:自由资金,2:冻结资金,3:优惠',
amount DECIMAL(22,6) NOT NULL DEFAULT '0.00000' COMMENT '额度值',
create_by VARCHAR(50) NOT NULL COMMENT '创建者',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
update_by VARCHAR(50) NOT NULL COMMENT '修改者',
PRIMARY KEY (id)
);
INSERT INTO `t_customer_credit` VALUES (1, 'zhangsan', 1, 550.000000, 'system', '2019-7-7 11:30:09', '2019-7-8 20:21:05', 'system');
INSERT INTO `t_customer_credit` VALUES (2, 'zhangsan', 2, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system');
INSERT INTO `t_customer_credit` VALUES (3, 'zhangsan', 3, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system');
INSERT INTO `t_customer_credit` VALUES (4, 'lisi', 1, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system');
INSERT INTO `t_customer_credit` VALUES (5, 'lisi', 2, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system');
INSERT INTO `t_customer_credit` VALUES (6, 'lisi', 3, 0.000000, 'system', '2019-7-7 11:30:09', '2019-7-7 11:30:09', 'system');
如果我们要一行显示用户的三个额度,而不是 3 条记录显示 3 个额度,我们应该怎么做,方式有很多种,这里提供如下 3 种
-- 1、容易想到的IF,不具备移植性,不推荐
SELECT login_name,
MAX(IF(credit_type=1, amount, )) freeAmount,
MAX(IF(credit_type=2, amount, )) freezeAmount,
MAX(IF(credit_type=3, amount, )) promotionAmount
FROM t_customer_credit GROUP BY login_name;
-- 2、CASE表达式,标准的 SQL 规范,具备移植性,推荐使用
SELECT login_name,
MAX(CASE WHEN credit_type = 1 THEN amount ELSE END) freeAmount,
MAX(CASE WHEN credit_type = 2 THEN amount ELSE END) freezeAmount,
MAX(CASE WHEN credit_type = 3 THEN amount ELSE END) promotionAmount
FROM t_customer_credit GROUP BY login_name;
-- 3、自连接,数据量大的情况下,结合索引,效率不错,具备移植性
SELECT
a.login_name,a.amount freeAmount,
b.amount freezeAmount,
c.amount promotionAmount
FROM (
SELECT login_name, amount FROM t_customer_credit WHERE credit_type = 1
)a
LEFT JOIN t_customer_credit b ON a.login_name = b.login_name AND b.credit_type = 2
LEFT JOIN t_customer_credit c ON a.login_name = c.login_name AND c.credit_type = 3;
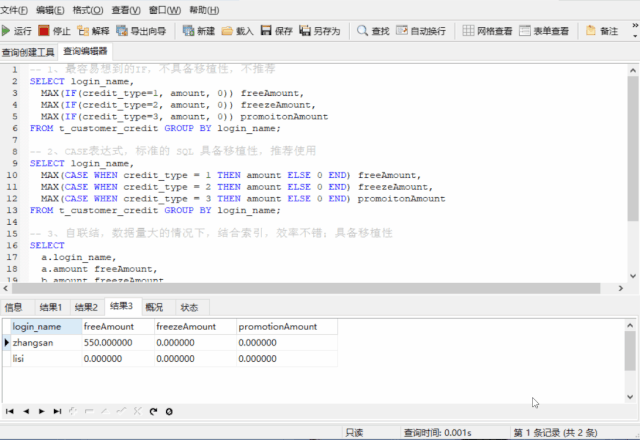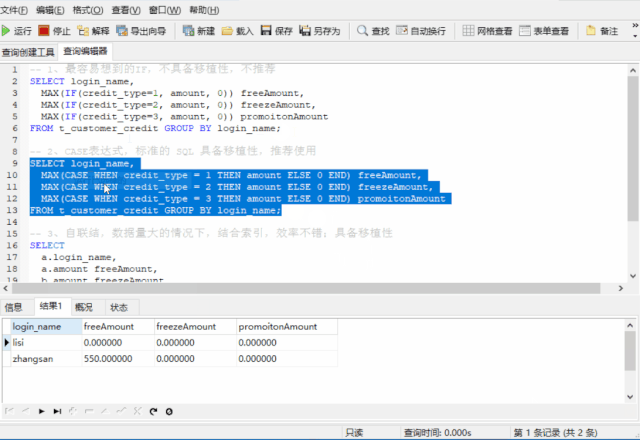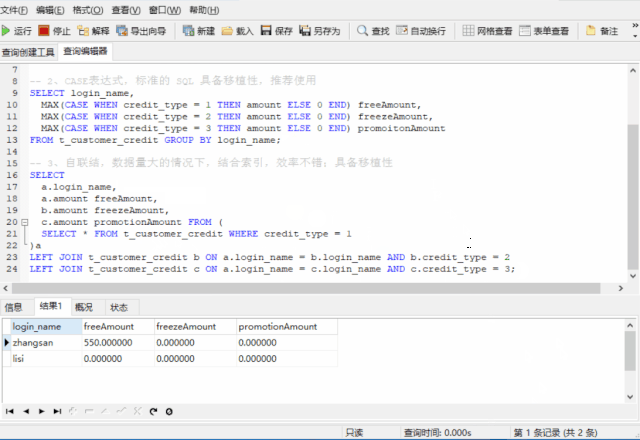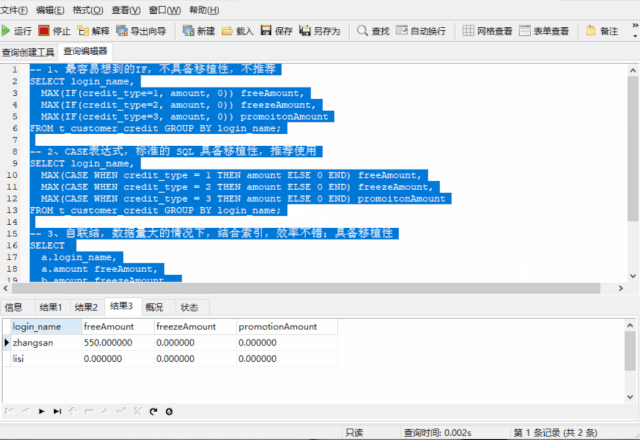
无论是 IF 还是 CASE表达式,都结合了 GROUP BY 与聚合函数,效率是个问题,而自连接是效率高的,不管在不在 login_name 上加索引
转换统计
将已有编号方式转换为新的方式并统计,在进行非定制化统计时,我们经常会遇到将已有编号方式转换为另外一种便于分析的方式并进行统计的需求。假设我们有如下表
DROP TABLE t_province_population;
CREATE TABLE t_province_population (
id tinyint(2) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
province_name varchar(50) NOT NULL COMMENT '省份名',
sex tinyint(1) NOT NULL COMMENT '性别,1:男,2:女',
population int(11) NOT NULL COMMENT '人口数',
PRIMARY KEY (id)
);
INSERT INTO t_province_population(province_name,sex,population)
VALUES
("黑龙江", 1 ,20),
("黑龙江", 2 ,18),
("内蒙古", 1 ,7),
("内蒙古", 2 ,8),
("海南", 1 ,20),
("海南", 2 ,22),
("西藏", 1 ,8),
("西藏", 2 ,7),
("浙江", 1 ,35),
("浙江", 2 ,35),
("台湾", 1 ,26),
("台湾", 2 ,23),
("河南", 1 ,40),
("河南", 2 ,38),
("湖北", 1 ,27),
("湖北", 2 ,24);
SELECT * FROM t_province_population;
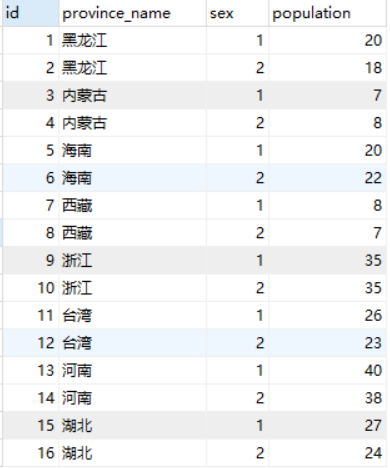
我们需要按各个省所在的位置,统计出东南西北中,各个区域内的人口数量
东:浙江、台湾,西:西藏,南:海南,北:黑龙江、内蒙古,中:湖北、河南
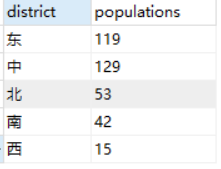
可能有人觉得这个表设计的不合理,应该在设计之初就应该多加一个区域字段(district)来标明各省所属区域。好的做法确实是这样,但这得需要我们在设计之初的时候能考虑得到,或者有这样的需求,假设我们设计之初没有这样的需求,而我们也没考虑到,那么有没有什么办法来实现了?我们可以这样来写 SQL
-- 通用写法,适用于多种数据库
SELECT CASE province_name
WHEN '浙江' THEN '东'
WHEN '台湾' THEN '东'
WHEN '海南' THEN '南'
WHEN '西藏' THEN '西'
WHEN '黑龙江' THEN '北'
WHEN '内蒙古' THEN '北'
WHEN '河南' THEN '中'
WHEN '湖北' THEN '种'
ELSE '其他' END district,
SUM(population) populations
FROM t_province_population
GROUP BY CASE province_name
WHEN '浙江' THEN '东'
WHEN '台湾' THEN '东'
WHEN '海南' THEN '南'
WHEN '西藏' THEN '西'
WHEN '黑龙江' THEN '北'
WHEN '内蒙古' THEN '北'
WHEN '河南' THEN '中'
WHEN '湖北' THEN '中'
ELSE '其他' END;
-- MySQL支持写法,移植性差
SELECT CASE province_name
WHEN '浙江' THEN '东'
WHEN '台湾' THEN '东'
WHEN '海南' THEN '南'
WHEN '西藏' THEN '西'
WHEN '黑龙江' THEN '北'
WHEN '内蒙古' THEN '北'
WHEN '河南' THEN '中'
WHEN '湖北' THEN '中'
ELSE '其他' END district,
SUM(population) populations
FROM t_province_population
GROUP BY district;
结果如下
假设我们需要对各个省份做一个人口数级别的统计,统计出各个级别的数量
level_1:population < 20,level_2:20 <= population < 50 ,level_3:50 <= population < 70 ,level_4:>= 70;统计出 level_1 ~ level_4 的数量各有多少
SQL 与执行结果如下
SELECT
CASE WHEN population < 20 THEN 'level_1'
WHEN population >= 20 AND population < 50 THEN 'level_2'
WHEN population >= 50 AND population < 70 THEN 'level_3'
WHEN population >= 70 THEN 'level_4'
ELSE NULL
END pop_level,
COUNT(*) cnt
FROM (
SELECT province_name,SUM(population) population FROM t_province_population GROUP BY province_name
)a
GROUP BY
CASE WHEN population < 20 THEN 'level_1'
WHEN population >= 20 AND population < 50 THEN 'level_2'
WHEN population >= 50 AND population < 70 THEN 'level_3'
WHEN population >= 70 THEN 'level_4'
ELSE NULL
END;
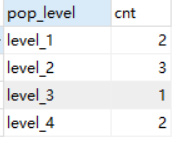
这种转换统计还是比较常用的,重点就是 GROUP BY 子句的写法。
条件分支
SELECT 条件分支
还是以上面的 t_province_population 为例,如果我们想要直观的知道各个省份的男、女数量情况,类似如下

我们要怎么写 SQL?有如下两种方法
-- 1、CASE表达式 集合 GROUP BY
SELECT province_name,
SUM(CASE WHEN sex = 1 THEN population ELSE END) c,
SUM(CASE WHEN sex = 2 THEN population ELSE END) f_pops
FROM t_province_population
GROUP BY province_name;
-- 2、自关联
SELECT t.province_name, t.population m_pops, a.population f_pops
FROM t_province_population t
LEFT JOIN t_province_population a
ON t.province_name = a.province_name
WHERE t.sex = 1 AND a.sex = 2;
其实就是行转列,行转列更容易懂
UPDATE 条件分支
我们有一张薪资表,如下
CREATE TABLE t_user_salaries(
id int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
name varchar(50) NOT NULL COMMENT '姓名',
sex tinyint(1) NOT NULL COMMENT '性别,1:男,2:女',
salary int(11) NOT NULL COMMENT '薪资',
PRIMARY KEY (id)
);
INSERT INTO t_user_salaries(name, sex,salary) VALUES
("张三", 1, 30000),
("李四", 1, 27000),
("王五", 1, 22000),
("菲菲", 2, 24000),
("赵六", 1, 29000);
SELECT * FROM t_user_salaries;
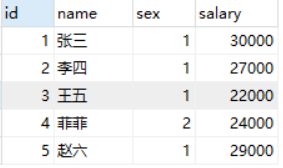
假设现在需要根据以下条件对该表的数据进行更新:1、对当前工资为 30000 元以上的员工,降薪 10%,2、对当前工资为 25000 元以上且不满 28000 元的员工,加薪 20%。调整之后的薪资如下所示
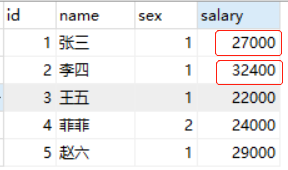
乍一看,分别执行下面两个 UPDATE 操作好像就可以做到,但是我们执行下看看结果
-- 条件1
UPDATE t_user_salaries
SET salary = salary * 0.9
WHERE salary >= 30000;
-- 条件2
UPDATE t_user_salaries
SET salary = salary * 1.2
WHERE salary >= 25000 AND salary < 28000;
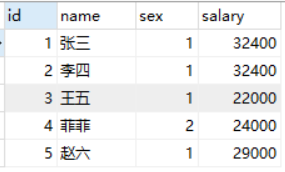
我们发现张三的薪资不降反升了!这是因为执行 条件1的SQL后,张三的薪资又满足条件2了,所以又更新了一遍,导致他的薪资变多了,有人可能会说,把条件1和条件2的SQL换下顺序不就好了吗,我们来试试
-- 条件2
UPDATE t_user_salaries
SET salary = salary * 1.2
WHERE salary >= 25000 AND salary < 28000;
-- 条件1
UPDATE t_user_salaries
SET salary = salary * 0.9
WHERE salary >= 30000;
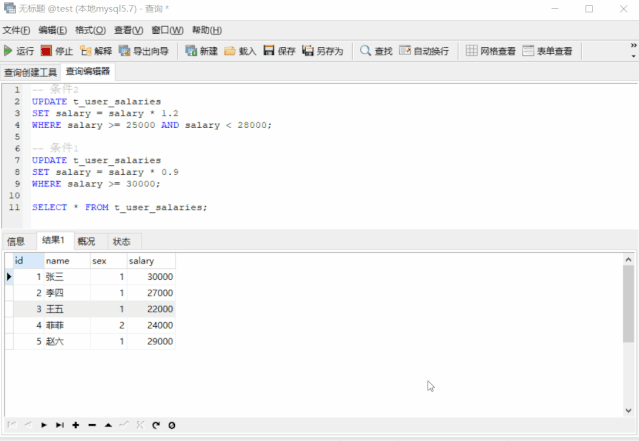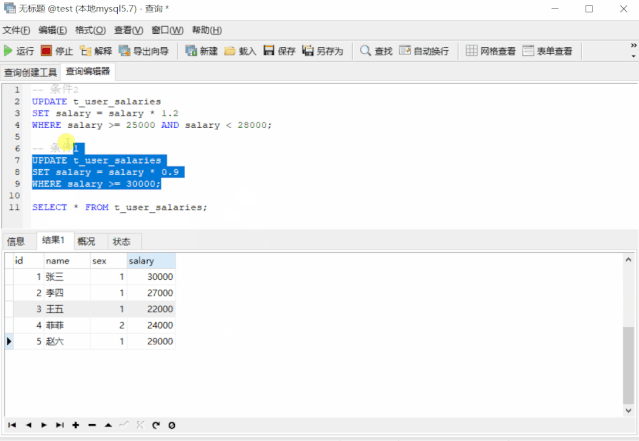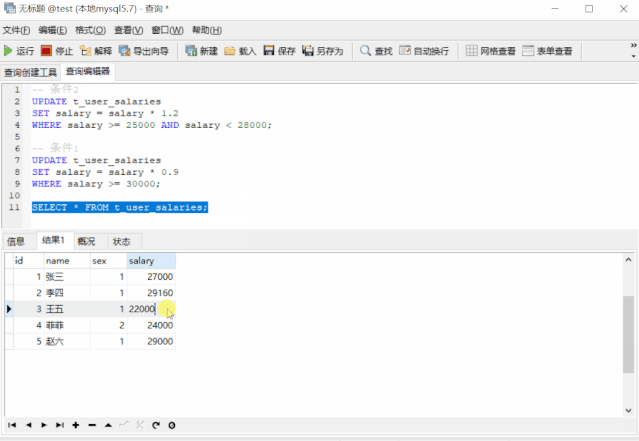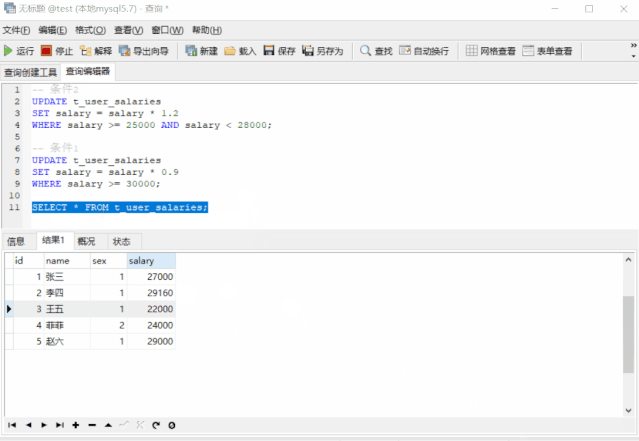
张三的薪资是降对了,可李四的薪资却涨错了!这是因为李四的薪资满足条件2,升了 20% 之后又满足条件1,又降了 10%。难道就没有就没有正确的方式了?我们来看看这个 SQL
UPDATE t_user_salaries SET salary =
CASE WHEN salary >= 30000 THEN salary * 0.9
WHEN salary >= 25000 AND salary < 28000 THEN salary * 1.2
ELSE salary
END;
SELECT * FROM t_user_salaries;
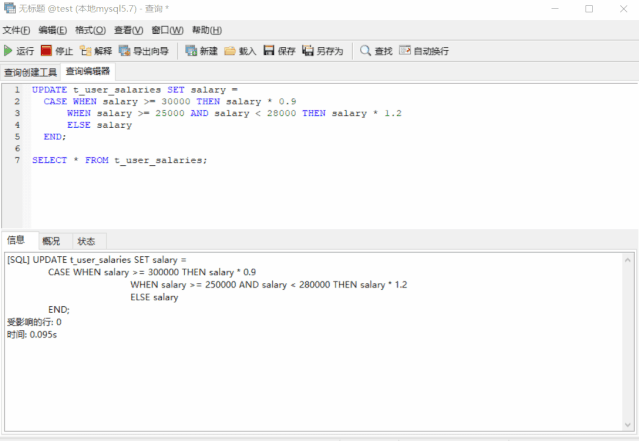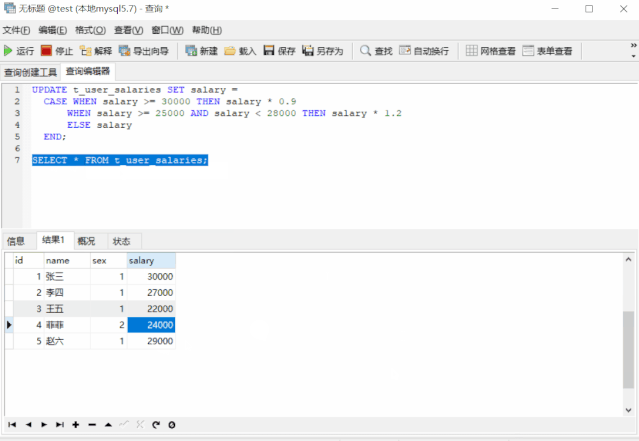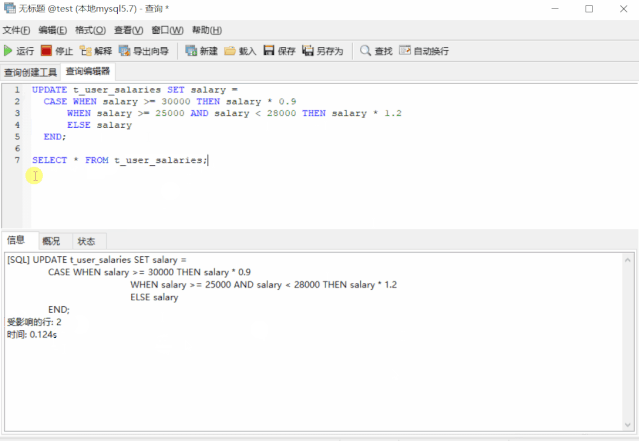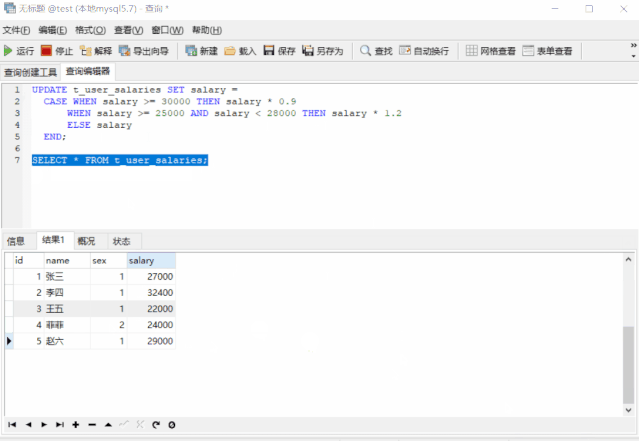
完美不?特别完美,这个技巧的应用范围很广,值得我们掌握
CHECK 约束
注意:CHECK 是标准的 SQL,但是 MySQL 却没有实现它,所以 CHECK 在 MySQL 中是不起作用的!
回到我们的薪资表,假设某个公司有这样一个无理的规定:女性员工的工资不得高于50000,我们如果实现它? 方式有两种:1、代码层面控制 、2、数据库表加约束。
代码层面控制就不多说了,这我们平时能想到的,实际也是用的多的;那从表约束,我们该如何实现了,像这样吗?
-- 创建表的时候增加约束
CREATE TABLE t_user_salaries_check(
name varchar(50) NOT NULL COMMENT '姓名',
sex tinyint(1) NOT NULL COMMENT '性别,1:男,2:女',
salary int(11) NOT NULL COMMENT '薪资',
CONSTRAINT chk_sex_salary CHECK (sex=2 AND salary <= 50000)
);
-- 若t_user_salaries_check已创建,则补充上约束
ALTER TABLE t_user_salaries_check
ADD CONSTRAINT chk_sex_salary CHECK (sex=2 AND salary <= 50000);
这么实现你会发现公司的男同事都会提着刀来找你了,因为没有他们的薪资,这个约束会导致录入不了男性的薪资!因为我们的约束是:sex=2 AND salary < = 50000 表示 “是女性,并且薪资不能高于50000”,而不是:“如果是女性,薪资不高于50000”。正确的约束条件应该这么写
-- 创建表的时候增加约束
CREATE TABLE t_user_salaries_check(
name varchar(50) NOT NULL COMMENT '姓名',
sex tinyint(1) NOT NULL COMMENT '性别,1:男,2:女',
salary int(11) NOT NULL COMMENT '薪资',
PRIMARY KEY (id),
CONSTRAINT chk_sex_salary CHECK(
CASE WHEN sex = 2 THEN
CASE WHEN salary <= 50000 THEN 1
ELSE
END
ELSE 1
END = 1 )
);
-- 若t_user_salaries_check已创建,则补充上约束
ALTER TABLE t_user_salaries_check
ADD CONSTRAINT chk_sex_salary CHECK(
CASE WHEN sex = 2 THEN
CASE WHEN salary <= 50000 THEN 1
ELSE
END
ELSE 1
END = 1
);
CASE表达式还有很多其他的用处,强大的不得了,而且高度灵活;用好它,能让我们写出更加契合的 SQL。
总结
1、CASE表达式 是支撑 SQL 声明式编程的根基之一,也是灵活运用 SQL 时不可或缺的基础技能。作为表达式,CASE 表达式在执行时会被判定为一个固定值,因此它可以写在聚合函数内部;也正因为它是表达式,所以还可以写在SELECE 子句、GROUP BY 子句、WHERE 子句、ORDER BY 子句里。简单点说,在能写列名和常量的地方,通常都可以写 CASE 表达式
2、写 CASE表达式 的注意点
a、各个分支返回的数据类型要一致
b、养成写 ELSE 的好习惯
c、不要忘了写 END
参考
《SQL基础教程》《SQL进阶教程》
youzhibing2904
https://www.cnblogs.com/youzhibing/p/11240536.html

