在一个炎热的夏天,引爆了埋藏已久的大炸弓单。
兔哥曾经所在单位一个产品线开发人员搭建起了一套庞大的价格存储系统,底层是关系型数据库,只用来处理一些事务性的操作和存放一些基础数据。
在关系型数据库的上面还有一套 MongoDB,因为 MongoDB 的文档型数据结构,让他们用起来很顺手,同时也可以支撑一定量的并发。
在大部分的情况下,一次大数据量的计算后结果可以重用但会出现细节数据的频繁更新,所以他们又在 MongoDB 上搭建了一层 Redis 的缓存。
这样就形成了数据库→MongoDB→Redis三级的方式,方案本身先不评价不是本文重点,我们来看 Redis 这层的情况。
由于数据量巨大,所以需要 200GB 的 Redis,并且在真实的调用过程中,Redis 是请求量大的点。当然如果 Redis 有故障时,也会有备用方案,从后面的 MongoDB 和数据库中重新加载数据到 Redis,就是这么一套简单的方案上线了。
当这个系统刚开始运行的时候,一切都还安好,只是运维同学有点傻眼了, 200GB 的 Redis 单服务器去做,它的故障可能性太大了。所以大家建议将它分片,没分不知道,一分吓一跳,各种类型用的太多了,特别是里面还有一些类似消息队列使用的场景。由于开发同学对 Redis 使用的注意点关注不够,一味的滥用,一锤了事,所以让事情变的困难了。
有些侥幸不死的想法是会传染,这时的每个人都心存侥幸,懒惰心理,都想着:“这个应该没事,以后再说吧,先做个主从,挂了就起从”,这种侥幸也是对 Redis 的虚伪的信心,无知者无畏。
可惜事情往往就是怕什么来什么,在大家快乐的放肆使用时,系统中重要的节点 MongoDB 由于系统内核版本的 Bug,造成整个 MongoDB 集群挂了!(这里不多说 MongoDB 的事情,这也是一个好玩的哭器)。
当然,这个对天天与故障为朋友的运维同学来说并没什么,对整个系统来说问题也不大,因为大部分请求调用都是在上层的 Redis 中完成的,只要做一定降级就行,等拉起了 MongoDB 集群后自然就会好了。
但此时可别忘了那个 Redis,是一个 200G 大的 Redis,更是带了个从机的 Redis。所以这时的 Redis 是不能出任何问题的,一旦有故障,所有请求会立即全部打向低层的关系型数据库,在如此大量的压力下,数据库瞬间就会瘫痪。
但是,怕什么来什么,还是出了状况:主从 Redis 之间的网络出现了一点小动荡,想想这么大的一个东西在主从同步,一旦网络动荡了一下下,会怎么样呢?
主从同步失败,同步失败,就直接开启全同步,于是 200GB 的 Redis 瞬间开始全同步,网卡瞬间打满。
为了保证 Redis 能够继续提供服务,运维同学直接关掉从机,主从同步不存在了,流量也恢复正常。不过,主从的备份架构变成了单机 Redis,心还是悬着的。
俗话说,福无双至,祸不单行。这 Redis 由于下层降级的原因并发操作量每秒增加到四万多,AOF 和 RDB 库明显扛不住。同样为了保证能持续地提供服务,运维同学也关掉了 AOF 和 RDB 的数据持久化,连后的保护也没有了(其实这个保护本来也没用,200GB 的 Redis 恢复太大了)。至此,这个 Redis 变成了完全的单机内存型,除了祈祷它不要挂,已经没有任何方法了。
这事悬着好久,直到修复 MongoDB 集群才了事。如此的侥幸,没出大事,但心里会踏实吗?回答是不会。
在这个案例中主要的问题在于:对 Redis 过度依赖,Redis 看似为系统带来了简单又方便的性能提升和稳定性,但在使用中缺乏对不同场景的数据的分离造成了一个逻辑上的单点问题。
当然这问题我们可以通过更合理的应用架构设计来解决,但是这样解决不够优雅也不够彻底,也增加了应用层的架构设计的麻烦。Redis 的问题就应该在基础缓存层来解决,这样即使还有类似的情况也没有问题。
因为基础缓存层已经能适应这样的用法,也会让应用层的设计更为简单(简单一直是架构设计所追求的,Redis 的大量随意使用本身就是追求简单的副产品,那我们为什么不让这简单变为真实呢?)
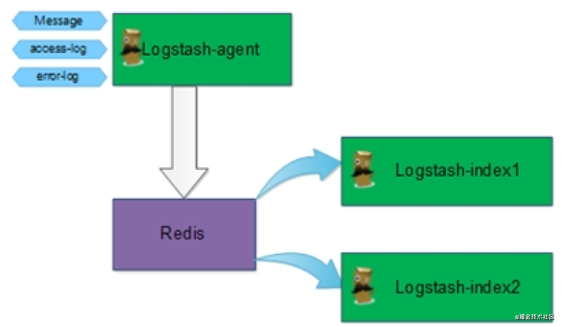
再来看第二个案例,有个部门用自己现有 Redis 服务器做了一套日志系统,将日志数据先存储到 Redis 里面,再通过其他程序读取数据并进行分析和计算,用来做数据报表。
当他们做完这个项目之后,这个日志组件让他们觉得用的还很过瘾。他们都觉得这个做法不错,可以轻松地记录日志,分析起来也挺快,还用什么公司的分布式日志服务啊?
随着时间的流逝,这个 Redis 上已经悄悄地挂载了数千个客户端,每秒的并发量数万,系统的单核 CPU 使用率也接近 90% 了,此时这个 Redis 已经开始不堪重负。
终于,压死骆驼的后一根稻草来了,有程序向这个日志组件写入了一条 7MB 的日志(哈哈,这个容量可以写一部小说了,这是什么日志啊)。
于是 Redis 堵死了,一旦堵死,数千个客户端就全部无法连接,所有日志记录的操作全部失败。其实日志记录失败本身应该不至于影响正常业务,但是由于这个日志服务不是公司标准的分布式日志服务,所以关注的人很少。
开始写它的开发同学也不知道会有这么大的使用量,运维同学更不知有这个非法的日志服务存在。这个服务本身也没有很好地设计容错,所以在日志记录的地方就直接抛出异常,结果全公司相当一部分的业务系统都出现了故障,监控系统中“5XX”的错误直线上升。
一帮人欲哭无泪,顶着巨大的压力排查问题,但是由于受灾面实在太广,排障的压力是可以想像的。
这个案例中看似是一个日志服务没做好或者是开发流程管理不到位,而且很多日志服务也都用到了 Redis 做收集数据的缓冲,好像也没什么问题。其实不然,像这样大规模大流量的日志系统从收集到分析要细细考虑的技术点是巨大的,而不只是简单的写入性能的问题。
在这个案例中 Redis 给程序带来的是超简单的性能解决方案,但这个简单是相对的,它是有场景限制的。在这里,这样的简单就是毒yao,无知的吃下是要害死自己的,这就像“一条在小河沟里无所不能傲慢的小鱼,那是因为它没见过大海,等到了大海……”。
在这个案例的另一问题:一个非法日志服务的存在,表面上是管理问题,实质上还是技术问题。因为 Redis 的使用无法像关系型数据库那样有 DBA 的监管,它的运维者无法管理和提前知道里面放的是什么数据,开发者也无需任何申明就可以向 Redis 中写入数据并使用。
所以这里我们发现 Redis 的使用没这些场景的管理后在长期的使用中比较容易失控,我们需要一个对 Redis 使用可治理和管控的透明层。
两个小例子中看到在 Redis 乱用的那个年代里,使用它的兄弟们一定是痛的,承受了各种故障的狂轰滥炸:
Redis 被 Keys 命令堵塞了;
Keepalived 切换虚 IP 失败,虚IP被释放了;
用 Redis 做计算了,Redis 的 CPU 占用率成了 了;
主从同步失败了;
Redis 客户端连接数爆了;
……。
如何改变 Redis 用不好的误区?
这样的乱象一定是不可能继续了,少在兔哥所在单位,这样的使用方式不可以再继续了,使用者也开始从喜欢到痛苦了。
怎么办?这是一个很沉重的事情:“一个被人用乱的系统就像一桌烧坏的菜,让你重新回炉,还让人叫好,是很困难的”。关键是已经用的这样了,总不可能让所有系统都停下来,等待新系统上线并瞬间切换好吧?这是个什么活:“高速公路上换轮胎”。
但问题出现了总是要解决的,想了再想,论了再论,总结以下几点:
必须搭建完善的监控系统,在这之前要先预警,不能等到发生了,我们才发现问题;
控制和引导 Redis 的使用,我们需要有自己研发的 Redis 客户端,在使用时就开始控制和引导;
Redis的部分角色要改,将 Redis 由 Storage 角色降低为 Cache 角色;
Redis 的持久化方案要重新做,需要自己研发一个基于 Redis 协议的持久化方案让使用者可以把 Redis 当 DB 用;
Redis 的高可用要按照场景分开,根据不同的场景决定采用不同的高可用方案。
留给开发同学的时间并不多,只有两个月的时间来完成这些事情。这事还是很有挑战的,考验开发同学这个轮胎到底能不换下来的时候到来了。
同学们开始研发我们自己的 Redis 缓存系统,下面我们来看一下这个代号为凤凰的缓存系统版方案:
首先是监控系统。原有的开源 Redis 监控从大面上讲只是一些监控工具,不能算作一个完整的监控系统。当然这个监控是全方位从客户端开始一直到返回数据的全链路的监控;
其次是改造 Redis 客户端。广泛使用的 Redis 客户端有的太简单,有的太重,总之不是我们想要的东西。
比如 .Net 下的 BookSleeve 和 servicestack.Redis(同程还有一点老的 .Net 开发的应用),前者已经好久没人维护了,后者直接收费了。好吧,我们就开发一个客户端,然后督促全公司的研发用它来替换目前正在使用的客户端。
在这个客户端里面,我们植入了日志记录,记录了代码对 Redis 的所有操作事件,例如耗时、Key、Value 大小、网络断开等。我们将这些有问题的事件在后台进行收集,由一个收集程序进行分析和处理,同时取消了直接的 IP 端口连接方式,通过一个配置中心分配 IP 地址和端口。
当 Redis 发生问题并需要切换时,直接在配置中心修改,由配置中心推送新的配置到客户端,这样就免去了 Redis 切换时需要业务员修改配置文件的麻烦。
另外,把 Redis 的命令操作分拆成两部分:
安全的命令,对于安全的命令可以直接使用;
不安全的命令,对于不安全的命令需要分析和审批后才能打开,这也是由配置中心控制的。
这样就解决了研发人员使用 Redis 时的规范问题,并且将 Redis 定位为缓存角色,除非有特殊需求,否则一律以缓存角色对待。
后,对 Redis 的部署方式也进行了修改,以前是 Keepalived 的方式,现在换成了主从+哨兵的模式。
另外,我们自己实现了 Redis 的分片,如果业务需要申请大容量的 Redis 数据库,就会把 Redis 拆分成多片,通过 Hash 算法均衡每片的大小,这样的分片对应用层也是无感知的。
当然重客户端方式不好,并且我们要做的是缓存,不仅仅是单单的 Redis,于是我们会做一个 Redis 的 Proxy,提供统一的入口点。
Proxy 可以多份部署,客户端无论连接的是哪个 Proxy,都能取得完整的集群数据,这样就基本完成了按场景选择不同的部署方式的问题。这样的一个 Proxy 也解决了多种开发语言的问题,例如,运维系统是使用 Python 开发的,也需要用到 Redis,就可以直接连 Proxy,然后接入到统一的 Redis 体系中来。
做客户端也好,做 Proxy 也好,不只是为代理请求而是为了统一的治理 Redis 缓存的使用,不让乱象出现。
让缓存在一个可管可控的场景下稳定的运维,让开发者可以安全并肆无忌惮继续乱用 Redis,但这个“乱”是被虚拟化的乱,因为它的底层是可以治理的。
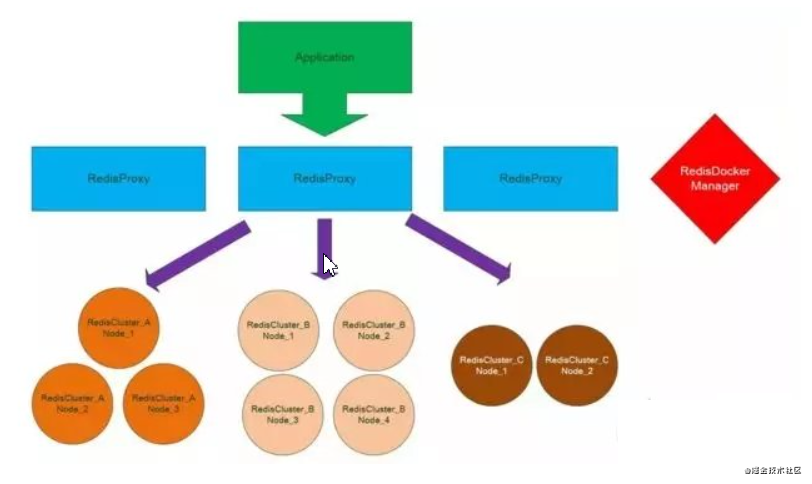
系统架构图
当然以上这些改造都需要在不影响业务的情况下进行。实现这个还是有不小的挑战,特别是分片。
将一个 Redis 拆分成多个,还能让客户端正确找到所需要的 Key,这需要非常小心,因为稍有不慎,内存的数据就全部消失了。
在这段时间里,我们开发了多种同步工具,几乎把 Redis 的主从协议整个实现了一遍,终于可以将 Redis 平滑过渡到新的模式上了。
PS:大家可能会有这样的疑问,为什么不用 Redis 的集群模式?我们在线的情况是 2.X 和 3.X 的版本居多,2.X 也正在大量减少,代理的加入不是为简单的分片,是为了更多的其他功能,比如单 Key 的高热度问题等,总的来看我们做的是一个私有缓存云,并不只有一个缓存管理容器。
