在2016年发表了《The Snowflake Elastic Data WareHouse》 这篇paper后,snowflake引领了云数仓发展的潮流,也引爆了资本界对于数据库行业的狂热,无论国内国外,投资圈都在期待下一个"snowflake"的出现。时至今日,snowflake在美股IPO的一年半后,市值已接近900亿。个人感觉,snowflake在几个技术决策上做出了无比英明的决策:
- 原生的与云结合,包括引领了方向的计算与存储(状态)分离,从而可以在2个层次上独立的实现弹性和高可用能力,此外基于同一份海量数据的VWs可以针对不同租户的不同workload需求实现隔离。这种分离可以充分利用云资源的弹性,并降低成本。
- 提供SAAS能力,简单的配置使用方式,易用性强,降低用户入门门槛,小化维护成本。
- 对多类型数据的支持,随着大数据的发展,现在已经远不是简单的企业内部收集的一些固定源头的数据(ERP,CRM...),数据来源多样化,同时模式也更加丰富,除经典的结构化数据外,半结构/非结构化数据都变为了重要的数据资源。
今天介绍这篇paper是snowflake在2020年NSDI上发表的一篇,干货不算多,但也有一定的前瞻意义,算是对16年那篇paper的一个补充吧,关于16年的解读可以看这篇:

这篇paper是对这些年来云上运维snowflake的一些总结和展望,主要描述了在几个方面snowflake的现有设计和实现以及未来发展所面临的技术挑战:
- 临时性存储系统
- 查询的执行调度
- 资源弹性
- 多租户机制
此外还有一个重要的部分就是提供了snowflake线上采集的海量查询的一些统计数据,对这些数据的分析也非常有意思,这部分数据已经在github上: https://github.com/resource-disaggregation/snowset。从中得到的一些重要insight包括:
- 用户查询的类别差异较大,文中按照读/写用户数据的情况进行了分类:
- read-only query 占~28%,主要对应一些ad-hoc / OLAP 的分析型查询
- write-only query 占~13%,主要就是数据的注入
- read-write query 占~59%,主要是一些ETL pipelines,过程中有数据的查询 -> 清理/计算 -> 注入
这样看来数仓并没有直觉上那样大比例的只读查询,负载模式要更加复杂些,因此传统share nothing架构的数仓如何处理读/写资源的隔离就更加复杂。
- 查询中产生的intermediate data大小变化很大,大可能会有TB级别,而且data size和查询所读取的用户数据量、查询执行时间都没有很直接的关联。
- 虽然VW中的local cache数据量相比底层海量存储是很小的(0.1%),但由于数仓类的查询很多具有时间/空间上的局部性,这样小的cache,hit ratio也可以达到60% ~ 80%
- 约20%的用户使用了VW的弹性能力,而且这种弹性可能会有2个数量级的集群成员变化
- 虽然在高峰期的资源利用率较高,但平均来看,CPU / Memory / Network TX / Network RX的利用率还是较低的,分别为~51%,~19%,~11%,~32%。
临时性存储系统
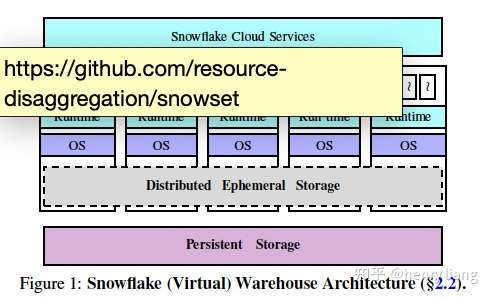
snowflake在计算层的弹性是通过Virtual Warehouse的抽象实现的,VW就是一组EC2实例构成的集群,集群中除了各个node中的cpu,还有本地的memory和SSD作为存储资源,而这些存储资源就构成了这个VW中的分布式的临时性存储系统。
这个存储系统对于VW的高性能是非常重要的,试想下所有查询的中间计算结果都要spill到底层的S3,那查询的延迟和吞吐都会很糟糕。。此外这部分存储资源也可以用于作为底层用户数据的local cache,来尽量避免到S3的远程访问。
作为中间结果数据的存储
对于查询中产生的中间结果数据,snowflake利用临时性存储来降低查询延迟,基本策略是3层存储层级,首先是尽可能保持在memory中,如果memory不足则spill到local SSD上,如果local SSD也无法发下所有数据则spill到底层的共享存储(S3)中。
未来发展的话,对于一些性能敏感的查询workload,spill到S3变得无法接受,因此针对当前VW内类似share nothing的架构,就需要做一些资源的provisioning来保证存储够用。但很明显provisioning和高的资源利用率是一对相互矛盾的点,用户负载可能变化,中间结果的数据量又很难预测(前面已给出了针对采集的查询profile数据已印证)。
解决这个难题可以把计算和临时性存储进一步解耦,然后两者各自独立的针对负载情况去做细粒度的弹性,这样就可以在保证资源够用的前提下,尽量提升资源利用率。
作为底层共享存储的cache
很明显中间结果数据是瞬时性的,用完就可以丢弃了,而在业务高峰时,它可能占用很多资源,但平均来看,对memory+SSD的利用率是较低的,这样就可以复用这些存储作为底层用户数据的cache,从上面profiling已经提到,cache虽小,但考虑到query pattern的局部性,cache hit ratio还是不错的。
具体来说,用户表会被partition为一系列的data files,当去访问这些data file时,查询的调度层(Cloud Service)会把对应的task根据data file name做consistent hash,调度到对应的VW node上。这样在VW拓扑不变化的时候,一个data file始终由一个node来负责,临时性存储由memory + SSD组成,两者之间使用了LRU策略做淘汰,而从SSD -> 远程存储则又是一个独立的LRU。在VW拓扑发生变化时,通过类似Druid的lazy consistent hash策略来避免掉share nothing存储的reshuffle操作。
caching这方面也有很多未来演进的挑战:
- 目前中间结果数据和cache数据是共享同一套临时性存储的,两者之间如何分配是一个很值得研究的问题,目前snowflake的策略很简单,中间结果数据具有高的优先级,但实际上可以由其他选择:中间结果只属于一条query,而caching数据则可能被多query共享,因此也许提高cache数据的优先级,可以从整体上提高workload的性能。
- 目前memory -> SSD -> S3的淘汰的策略是2个独立LRU来完成,但一个能够协同多层的cache机制可能更为合适。
查询的执行调度
查询到来时首先进入Cloud Service一层(核心FoundationDB),完成查询解析、优化、执行task的生成,然后CS层要把任务调度到VW中的各个node上,目前采用了刚才提到的consistent hash机制,task调度到哪里取决于它所访问的data file的情况,data file也会cache到目标node上。由于一般的分析型查询会访问大量底层数据,一个query的所有tasks可能会调度到VW的所有node中,这充分打散了查询执行,提升了并行度,但也意味着后续中间数据的shuffle/broadcast成本更高。此外为了避免热点问题,VW中实现了work stealing机制。
当前这种基于consistent hash的策略提升了数据局部性,但副作用就是exchange数据的成本更高,未来的研究方向可以考虑只选择一组node的子集做task调度,但这个决策方式和平衡点是难点。
资源弹性
刚才提到的Lazy consistent hash机制其实非常简单:
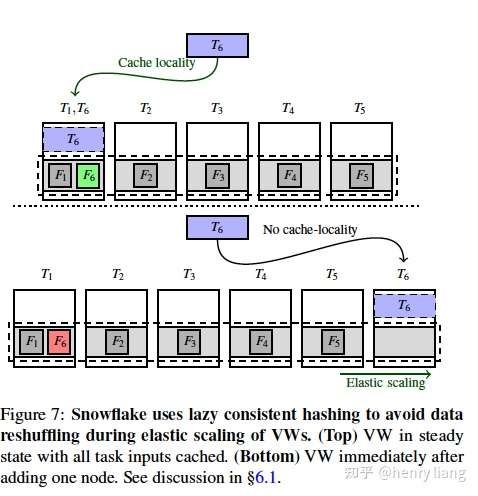
如上图所示,当集群中加入一个新节点T6时,原来hash到T1的data file F6在后续新来的查询task中,被调度到了T6中,从而按需的被加载到T6的local cache中,而T1中的F6则随着后续查询不再使用而被LRU淘汰置换掉,这样既实现了拓扑变化不会影响现有查询,也避免了主动reshuffle带来的资源开销和对前台负载的性能影响。
前面的profling数据已经说明了目前有20%用户使用了VW的弹性,但数据显示,从弹性的节奏上来看,节点变更的密度和查询变化的密度并不匹配,这其实说明当前的弹性响应速度不够快。根本原因在于两点
- VW的集群拓扑变化是由用户主动触发的,而这种响应速度不敏捷是由于用户缺乏对负载的监控能力较弱。
- 弹性的粒度较粗,目前也只能做到随着query的变化而调整,未来则希望是task/stage这个粒度。
多租户机制
目前多租户的隔离通过VW的物理集群隔离实现,但这样也带来了资源利用率会更低的问题,通过profling中的数据已经可以看出这点(除了CPU,memory、网络的平局利用率都很低)。而且在proling的数据中可以看到这样一点:各个VW的workload高峰并不同步,这就为错峰利用资源提供了可能性。
此外还有个成本问题:snowflake为了提升弹性速度,为每个VW后备了一组pre-warming的EC2 pool,但这样自然也存在成本,原来云服务提供商(snowflake自身)是以hour为单位向用户计费,这样只要在1小时内有用户使用了池子中的节点,哪怕只用一会也可以按小时收费,这样就分摊了整个pool的成本,但现在云上的收费模式细化为按秒级计费,pre-warming pool的成本就不再可以忽视了,这也驱动着从预置资源到共享资源的演进。
所谓共享资源就是多个VW共用同一组EC instances集群,实现资源复用,但这样就带来隔离性的难题,不解决就会有长尾性能差这个大问题,尤其是临时性存储系统,如何实现一个解耦的、弹性的、多租户共享的临时性存储,同时提供租户间隔离性是一个具有巨大挑战的课题。
总结
这篇文章虽然关于系统实现的细节仍然很少,但给出的针对大量用户负载的profiling数据,以及结合这些数据对未来产品技术发展方向的规划,还是很有参考和借鉴意义的。现在云上数仓的形态基本都沿着snowflake的方向在演进,海外有firebolt和databricks,此外像Azure的Synapse等大厂的数仓、数据湖产品也是类似的架构思路;国内腾讯云、阿里云也都有团队在做类似的工作。在大家去参考snowflake的同时,它已经开始探索未来5年的技术演进方向了。
来源 https://zhuanlan.zhihu.com/p/469582442
