Boostrapping是NLP领域当前的一个十分经典的算法,在缺少标注数据等业务场景下,通常很受欢迎,并在机器学习模型大行其道的今天也成为了积累伪标注数据【数据增强】的重要手段。例如,
文章 《A User-Centered Concept Mining System for Query and Document Understanding at Tencent》提出了一个概念挖掘的方法,其中包括基于bootstrapping的部分。
Pattern-Concept Bootstrapping,这种方法以一批种子模版为起点,匹配query得到一些候选概念再基于得到的候选概念,去生成新的模版。
新的模版应该既能匹配一定量的已有的概念,也能具有扩展性,匹配到一定量的新的概念,满足此条件的模版会被保留。如此循环往复,从而不断得到更多的候选概念以及匹配模版。
如下图所示:
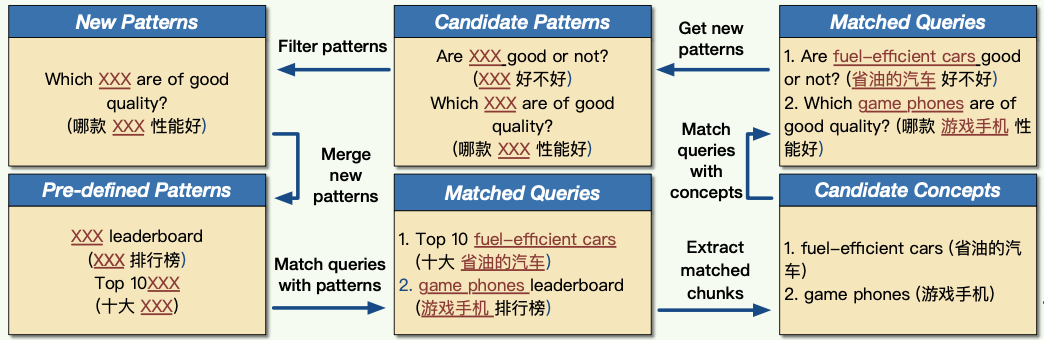
这种方法以一批种子模版为起点(方框1),匹配种子query(方框2)得到一些候选概念(方框3)。再基于得到的候选概念匹配更多Queries(方框4),从而得到候选模版(方框5),后过滤得到高质量模板(方框6)。
又如,文章 《Snowball: Extracting Relations from Large Plain-Text Collections》 是一种基于半监督学习bootstrapping方法实现关系抽取,发表于2000年,较为久远,但却是一篇经典之作。
此外,后续出现了Basilisk(Bootstrapping Approach to SemantIc Lexicon Induction using Semantic Knowledge)、NOMEN、AutoSlog-TS、MetaBoot + Basilisk等系列工作。
本文主要以Snowball这一系统为例,对其工作原理进行介绍,做Bootstrapping解读(一)的分享,其核心在于质量的控制【包括实例的控制以及模板的控制】,以解决语义漂移的问题。
一、整体思想
Snowball系统旨在从非结构化文本中抽取出<orgnization, location>二元组对,如下图所示,主要由以下几个部分构成:
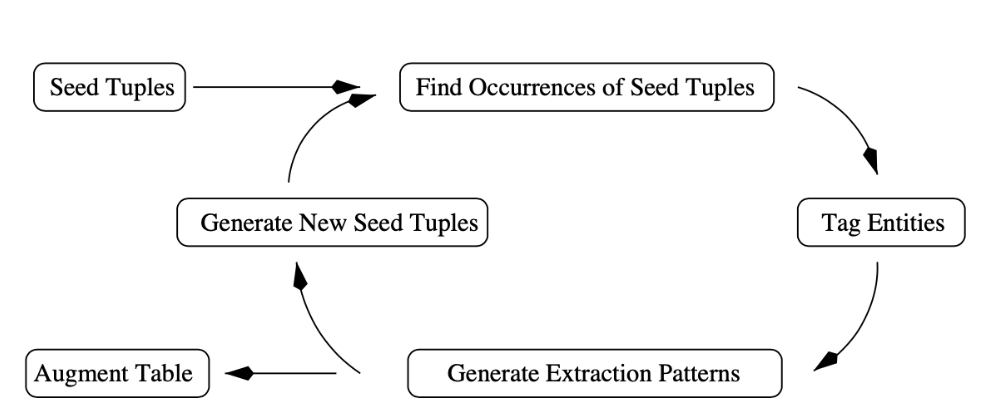
细分起来,包括7个子步骤:
1、准备种子元组。 找到对应的高质量结构化元组集合。
2、找到共现对。 即根据系统输入的种子元组,到待进行关系挖掘的语料库中搜索到所有种子元组的共现对。
3、实体打标签。 在Snowball系统中,实体是具有标签的,且关系挖掘过程中所产生的pattern也是具有标签的。在对pattern的匹配过程中,共现实体对不仅仅要匹配模型中的上下文定义,而且对应实体的标签属性也要相匹配,才能被认为是与一个pattern相匹配。
4、产生pattern。 在Snowball系统中,pattern被定义为一个五元组,且对应表示上下文的三个向量(left,middle, right)具有权重,权重体现了每个项目在相对的上下文中的重要程度。
5、对产生的pattern进行评估。 以可信度,对数可信度来考察产生的模型及后文要提到的抽取的元组的质量。在这个评估体系中,作者首先用高质量的种子元组来评估pattern,得到高质量的pattern后,又反过来用这些pattern来评价新抽取得到的元组。
6、抽取元组。 通过经过过滤的pattern,放回到语料库中进行元组匹配,后得到一定数量的元组。
7、评估元组。 系统会对产生的元组进行评价。在评估元组中,系统会通过元组与高质量模板的匹配程度,来计算出该元组的可信度。
下面就其中几个重要的部分进行介绍。
二、种子元组收集
文章的主要任务是抽取机构-所在地的关系,因此从网上下载得到包含13000个组织信息的公共数据,并借助Whirl来抽取信息对,经过实体达标后,形成如下标准模板。
<ORGANIZATION>’s headquarters in <LOCATION>
<LOCATION>-based <ORGANIZATION>
<ORGANIZATION>, <LOCATION>
三、实体打标
针对输入的文本,先进行分词和实体识别,然后用实体类型代替具体的实体名称,生成pattern。有意思的是,snowball将一个pattern表示为一个五元组,其中tag1和tag2表示命名实体,middle和right表示对应的权重向量。

其中,left和right向量的值计算,主要方法是:
在识别了字符串S中的实体后,通过分析命名实体周围的左、右和中间上下文,从S中创建三个权重向量lS、rS和mS。
每个向量对出现在各自上下文中的每个项都具有非零权重,其中lS和rS对应于在实体对左侧和右侧窗口大小为wd的多个词,其中每个词对应的权重为该词在实体上下文中出现的频次,并作归一化,特别的,其在在中间词的权重分配比左词和右词的要高。
例如,句子“the Irving- based Exxon Corporation,”
,终形成的pattern为:
<{<the, 0.2>}, LOCATION, {<-,0.5>, <based,0.5>}, ORGANIZATION, {}>
表示left有the一词,中间有-、based两个词,对应的频次分别为0.2、0.5、0.5。
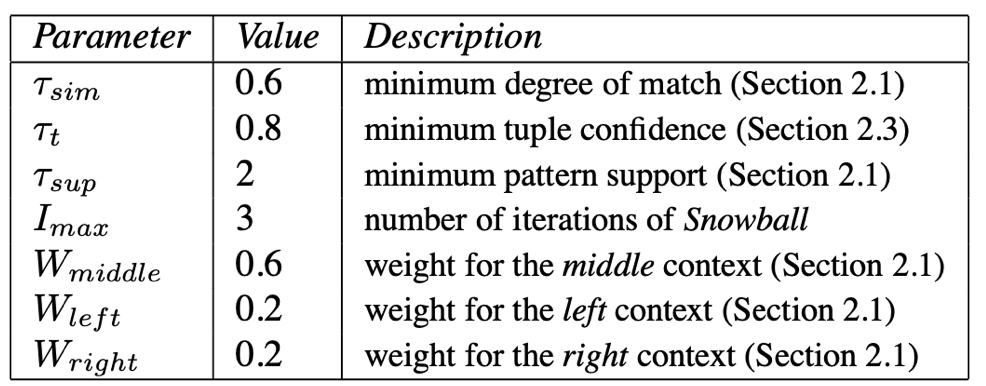
四、pattern生成
为了获得高质量的种子pattern集合,snowball使用singlepass对所有抽取出来的五元组进行向量聚类,将相似的元组集合进行分组。
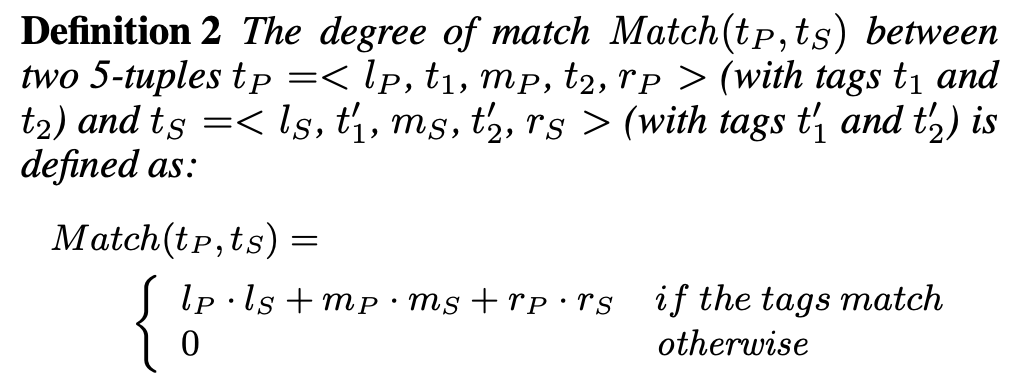
如上图所示,在计算相似度时,计算相应的左、中、右向量的内积,并设定相似度超参记为τsim。终基于类簇,生成每个组对应的left向量和right向量,向量的值分别为类簇中心向量,后组合成新的向量。
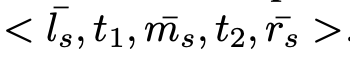
五、元组抽取
基于上一步得到的pattern,给定一个文本,识别出其中的两个实体organization o and location l
,按照类似的方式,构造成五元组t=<lc,t1,mc,t2,rc>
,这一步的目标是检验候选结果<o,l>
是否成立。

如上图给出的算法逻辑,snowball将构造好的元组t与已有的五元组模版tp集合进行相似度匹配,查看是否存在相似度阈值高于τsim【上面聚类时用到的值】的pattern,如果存在,那么该实例就可以作为候选实体保留;
六、元组准入评估
由于抽取出来的实体会参与后续的迭代当中,因此,需要保证候选实体的准确性。
简单的方式就是以准确的实体为爆照已进行匹配,例如,嘉定,实体库中存在一个实体对t=<o,l>,对于新抽取的元组t'=<o',l'>,假设o与o'相同,那么则比较位置l和l'。
如果l=l',那么元组t'是正样本元组,否则就作为负样本,反之亦然。
但这种方式无法解决新抽取实体中,o和l均不在实体库中的情况,所以后续又提出了新的评估方法。
七、pattern质量评估
质量控制用于对新生成pattern进行控制,生成如下图所示的结果:
由于可以将候选实体区分为正样本和负样本。作为一个例子,考虑模式P,其置信度计算公式为: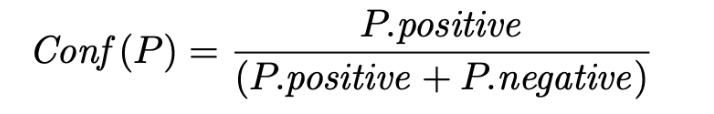 其中:P.positive表示模板P正确匹配的实例个数,P.negative表示模板P错误匹配的实例个数。
其中:P.positive表示模板P正确匹配的实例个数,P.negative表示模板P错误匹配的实例个数。
<{}, ORGANIZA- TION, <“,”, 1>, LOCATION, {}>
上面提到的,假设此模式仅与以下三行文本匹配:
“Exxon, Irving, said”
“Intel, Santa Clara, cut prices”
“invest in Microsoft, New York-based analyst Jane Smith said”
前两行生成候选元组:
<Exxon, Irving>
<Intel, Santa Clara >
第三行生成元组<Microsoft,New York>
,此元组中的位置与元组<Microsoft,Redmond>
中的位置冲突,因此后一行被视为负例。
然后,模式P的置信度 Conf(P)=2/(2+1)=0.67。
不过这种度量方法,并没有考虑到一个pattern的覆盖度,所以提出了一个新的度量公式Conf RlogF(P)。
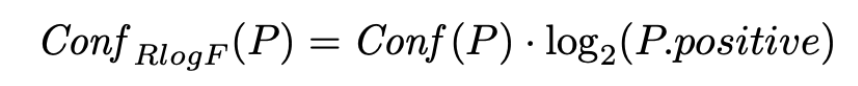
八、元组质量评估
紧接着,对于每个元组T,可以得到生成它的模式pattern集合、元组出现的上下文以及匹配模式之间的相似性度量信息,所以对此可以进一步建模。
例如,对于一个候选元组T和用于生成T的一组模式P={Pi},假设知道每个模式Pi产生有效元组的概率Prob(Pi),这些概率相互独立,那么一个有效的元组T成立的概率Prob(T)可计算为:
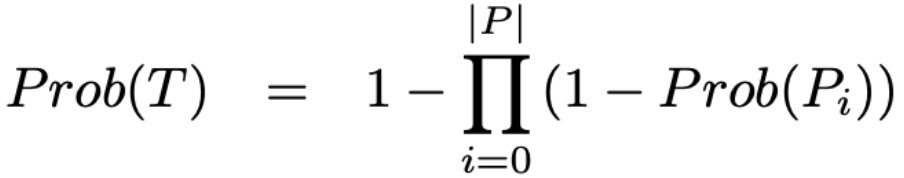 这样一来,Conf(Pi),可以作为模式Pi生成一个有效元组的概率估计。
这样一来,Conf(Pi),可以作为模式Pi生成一个有效元组的概率估计。
进一步的,有了个这个概率,那么可以进一步生成对元组T的成立性估计,进一步加入pattern的置信度以及实例上下文与pattern的匹配度,即如下图:
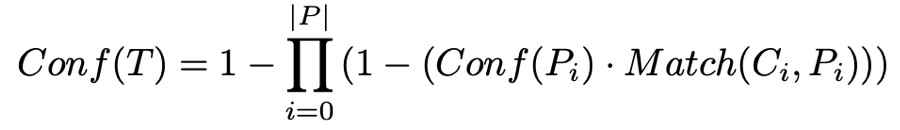
其中,P={Pi}是生成T的一组模式,而Ci是T出现过的上下文,Match(Ci,Pi)参照聚类过程中的相似度计算方法,表示与pattern的匹配度。
九、pattern迭代更新
由于整个迭代过程中,pattern的置信度一直在变,所以需要对其变化加以控制。
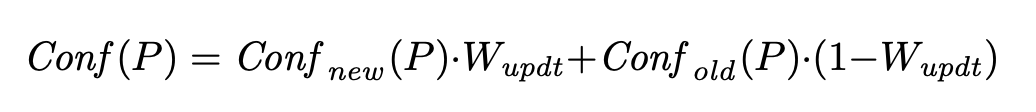 如上述公式所示,加入缩放因子Wupdt。当参数Wupdt小于0.5,则系统实际上在每次迭代中对新示例的信任度较低,这将生成更保守的模式,并产生阻尼效应。
如上述公式所示,加入缩放因子Wupdt。当参数Wupdt小于0.5,则系统实际上在每次迭代中对新示例的信任度较低,这将生成更保守的模式,并产生阻尼效应。
十、bootstrapping的朴素实现
特别的,我们选取一个概念挖掘的任务,采用朴素的方法,来进行bootstrapping实验,针对输入的title文本,利用种子模板集合,生成对应的高质量pattern和concept集合。
完整代码参考:https://github.com/liuhuanyong/BootstrappingTool
1、种子模板
^(.*?)大全
^(.*?)汇总
^(.*?)(大)?盘点
^(.*?)(都)?有哪些$
^(.*?)(都)?有哪些(.*?)电影$
^(.*?)(都)?有哪些(.*?)电视剧$
^(.*?)(都)?有哪些[??,.,。!!\s]+
^(.*?)(的|总|人气|终|性价比|竞争力|操控测试|测试|合规|票房|票房总|武功|战斗力|吸引力|魅力|综合能力|能力|热度)?排名
^(.*?)(的|总|人气|终|性价比|竞争力|操控测试|测试|合规|票房|票房总|武功|战斗力|吸引力|魅力|综合能力|能力|热度)?排行
^(.*?)(的|总|人气|终|性价比|竞争力|操控测试|测试|合规|票房|票房总|武功|战斗力|吸引力|魅力|综合能力|能力|热度)?排行榜
2、条件设定
针对每次迭代,都需要进行实体的质量控制与概念的质量控制,分别设置limit_pattern_count、limit_concept_count,为了加速计算,还需要配置done_pattern和done_concept。
limit_pattern_count = 5 ## 用于pattern质量控制
limit_concept_count = 4 ## 用于实体质量控制
done_pattern = set() ## 存储已经迭代过的pattern
done_concept = set() ## 存储已经存储过的
concept_dict = dict()
epochs = 3
3、基于pattern进行迭代instance挖掘
我们认为,一个pattern高频出现,那么就是正例。因此,当某个pattern出现的频次高于设定值,并且没有参与过挖掘时,则进入到下一轮迭代。
def extract_concept(self, text):
ress =[]
for pattern, tf in self.pattern_dict.items():
if tf >= self.limit_pattern_count and pattern not in self.done_pattern:
res = re.findall(pattern, text)
if res:
ress += res
else:
self.done_pattern.add(pattern)
return ress
4、基于挖掘出来的概念实例,进行迭代pattern模板挖掘
我们认为,一个实例高频出现,那么就是正例。因此,当某个实例出现的频次高于设定值,并且没有参与过挖掘时,则进入到下一轮迭代。
def mining_pattern(self, s):
for concept, tf in self.concept_dict.items():
if concept not in s or tf < self.limit_concept_count:
continue
if concept not in self.done_concept:
if concept == s:
continue
pattern = s.replace(concept, "(.*?)")
if pattern not in self.pattern_dict:
self.pattern_dict[pattern] = 1
else:
self.pattern_dict[pattern] += 1
return
else:
self.done_concept.add(concept)
5、挖掘效果
通过设定高频的pattern阈值,我们可以得到对应的扩展pattern集合;
(.*?)大全 、(.*?)排行榜、(.*?)排行榜前十名、(.*?)网、(.*?)大全免费、(.*?)下载、(.*?)排名、(.*?)排名、免费(.*?)、搞笑(.*?)、在线(.*?)
同样的,我们也可以得到高频的一些概念实体,作为输出。
小说、影视、游戏、作文、动画片、4399小游戏、电影、电视剧、官场小说、都市小说、歌曲、二战电影、言情小说
