深入了解支持服务间通信的 3 个原生 K8s 对象:ClusterIP Service、DNS 和 Kube-Proxy。


现在在 Kubernetes 集群中,我们拥有构成集群管理组件和一组工作机器(称为节点)的控制平面。这些节点托管 Pod,这些 Pod 将后端微服务作为容器化服务运行。

根据 Kubernetes 网络模型:
集群中的每个 pod 都有自己的集群范围 IP 地址 所有 pod 都可以与集群内的每个 pod 通信 -
通信在没有 NAT 的情况下发生,这意味着目标 pod 可以看到源 pod 的真实 IP 地址。Kubernetes 认为容器网络或在其上运行的应用程序是可信的,不需要在网络级别进行身份验证。
ClusterIP 服务 ~ 基于 Pod 的抽象
既然集群中的每个 pod 都有自己的 IP 地址,那么一个 pod 与另一个 pod 通信应该很容易吧?
不,因为 Pod 是易变的,每次创建 pod 时都会获得一个新的 IP 地址。所以客户端服务必须以某种方式切换到下一个可用的 pod。

Pod 直接相互交谈的问题是另一个目标 Pod 的短暂性(随时可能销毁),其次是发现新 Pod IP 地址。
因此 Kubernetes 可以在一组 Pod 之上创建一个层,该层可以为该组提供单个 IP 地址并可以提供基本的负载平衡。
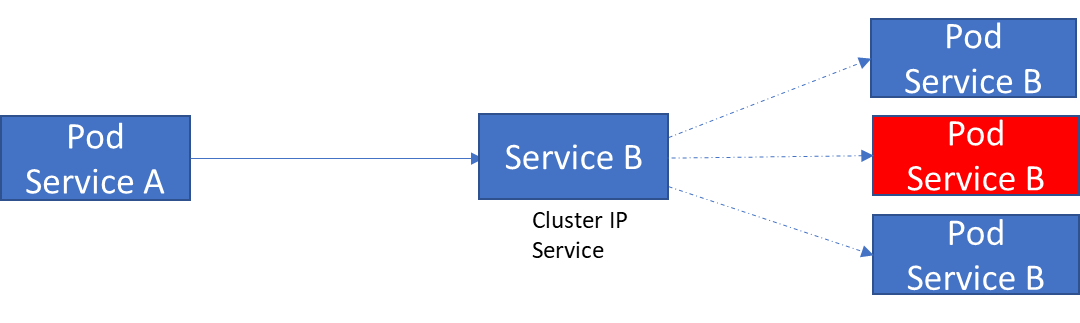
通过持久 IP 地址上的 ClusterIP 服务公开的 Pod,客户端与服务对话,而不是直接与 Pod 对话。
这种抽象是由 Kubernetes 中一个名为ClusterIP service的服务对象提供的。它在多个节点上产生,从而在集群中创建单个服务。它可以接收任何端口上的请求并将其转发到 pod 上的任何端口。
因此,当应用服务 A 需要与服务 B 对话时,它会调用服务 B 对象的 ClusterIP 服务,而不是运行该服务的单个 pod。
ClusterIP 使用 Kubernetes 中标签和选择器的标准模式来不断扫描匹配选择标准的 pod。Pod 有标签,服务有选择器来查找标签。使用它,可以进行基本的流量拆分,其中新旧版本的微服务在同一个 clusterIP 服务后共存。
现在服务 B 已经获得了一个持久的 IP 地址,服务 A 仍然需要知道这个 IP 地址是什么,然后才能与服务 B 通信。
Kubernetes 支持使用 CoreDNS 进行名称解析。服务 A 应该知道它需要与之通信的 ClusterIP 的名称(和端口)。

CoreDNS 扫描集群,每当创建 ClusterIP 服务时,它的条目就会添加到 DNS 服务器(如果已配置,它还会为每个 pod 添加一个条目,但它与服务到服务的通信无关)。 接下来,CoreDNS 将自己暴露为 cluster IP 服务(默认称为 kube-dns),并且该服务被配置为 pod 中的 nameserver。 -
发起请求的 Pod 从 DNS 获取 ClusterIP 服务的 IP 地址,然后可以使用 IP 地址和端口发起请求。
Kube-proxy 打通 Service 和后端 Pod 之间(DNAT)
到目前为止,从本文来看,似乎是 ClusterIP 服务将请求调用转发到后端 Pod。但实际上,它是由 Kube-proxy 完成的。
Kube-proxy 在每个节点上运行,并监视 Service 及其选择的 Pod(实际上是 Endpoint 对象)。
当节点上运行的 pod 向 ClusterIP 服务发出请求时,kube-proxy 会拦截它。 通过查看目的 IP 地址和端口,可以识别目的 ClusterIP 服务。并将此请求的目的地替换为实际 Pod 所在的端点地址。
如何协同工作?

目标的 ClusterIP 服务在 CoreDNS 中注册 DNS 解析:每个 pod 都有一个 resolve.conf 文件,其中包含 CoreDNS 服务的 IP 地址,pod 执行 DNS 查找。 Pod 使用它从 DNS 收到的 IP 地址和它已经知道的端口来调用 clusterIP 服务。 目标地址转换:Kube-proxy 将目标 IP 地址更新为服务 B 的 Pod 可用的地址。
总结
通过本文,我们看到了使服务到服务通信成为可能的原生 Kubernetes 对象,这些细节对应用程序层是隐藏的。
原文:
https://medium.com/codex/east-west-communication-in-kubernetes-how-do-services-communicate-within-a-cluster-310e9dc9dd53
