一、背景
在现网环境,一些使用Redis集群的业务随着业务量的上涨,往往需要进行节点扩容操作。
之前有了解到运维同学对一些节点数比较大的Redis集群进行扩容操作后,业务侧反映集群性能下降,具体表现在访问时延增长明显。
某些业务对Redis集群访问时延比较敏感,例如现网环境对模型实时读取,或者一些业务依赖读取Redis集群的同步流程,会影响业务的实时流程时延。业务侧可能无法接受。
为了找到这个问题的根因,我们对某一次的Redis集群迁移操作后的集群性能下降问题进行排查。
1.1 问题描述
这一次具体的Redis集群问题的场景是:某一个Redis集群进行过扩容操作。业务侧使用Hiredis-vip进行Redis集群访问,进行MGET操作。
业务侧感知到访问Redis集群的时延变高。
1.2 现网环境说明
目前现网环境部署的Redis版本多数是3.x或者4.x版本;
业务访问Redis集群的客户端品类繁多,较多的使用Jedis。本次问题排查的业务使用客户端Hiredis-vip进行访问;
Redis集群的节点数比较大,规模是100+;
集群之前存在扩容操作。
1.3 观察现象
因为时延变高,我们从几个方面进行排查:
带宽是否打满;
CPU是否占用过高;
OPS是否很高;
通过简单的监控排查,带宽负载不高。但是发现CPU表现异常:
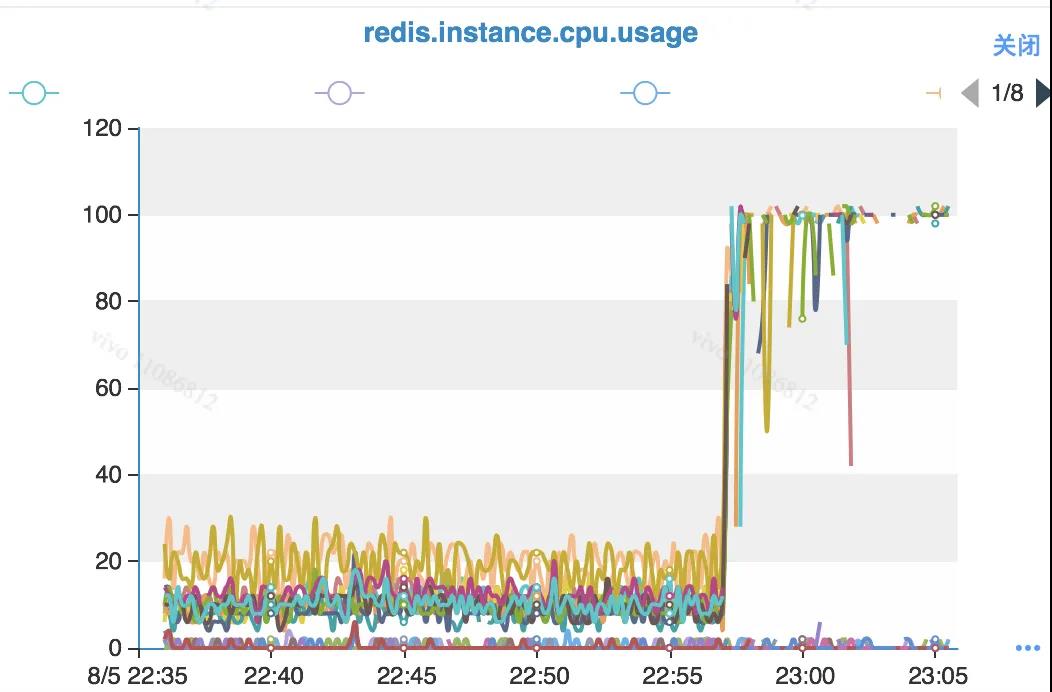
1.3.1 对比ops和CPU负载
观察业务反馈使用的MGET和CPU负载,我们找到了对应的监控曲线。
从时间上分析,MGET和CPU负载高并没有直接关联。业务侧反馈的是MGET的时延普遍增高。此处看到MGET的OPS和CPU负载是错峰的。
此处可以暂时确定业务请求和CPU负载暂时没有直接关系,但是从曲线上可以看出:在同一个时间轴上,业务请求和cpu负载存在错峰的情况,两者间应该有间接关系。
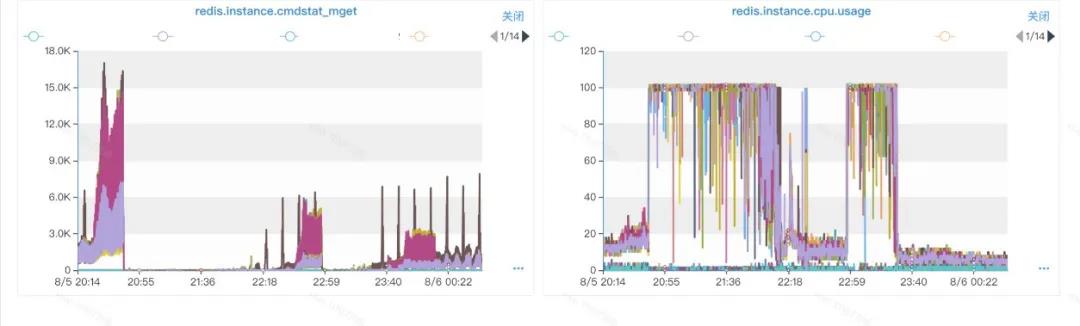
1.3.2 对比Cluster指令OPS和CPU负载
由于之前有运维侧同事有反馈集群进行过扩容操作,必然存在slot的迁移。
考虑到业务的客户端一般都会使用缓存存放Redis集群的slot拓扑信息,因此怀疑Cluster指令会和CPU负载存在一定联系。
我们找到了当中确实有一些联系:

此处可以明显看到:某个实例在执行Cluster指令的时候,CPU的使用会明显上涨。
根据上述现象,大致可以进行一个简单的聚焦:
业务侧执行MGET,因为一些原因执行了Cluster指令;
Cluster指令因为一些原因导致CPU占用较高影响其他操作;
怀疑Cluster指令是性能瓶颈。
同时,引申几个需要关注的问题:
为什么会有较多的Cluster指令被执行?
为什么Cluster指令执行的时候CPU资源比较高?
为什么节点规模大的集群迁移slot操作容易“中招”?
二、问题排查
2.1 Redis热点排查
我们对一台现场出现了CPU负载高的Redis实例使用perf top进行简单的分析:

从上图可以看出来,函数(ClusterReplyMultiBulkSlots)占用的CPU资源高达 51.84%,存在异常。
2.1.1 ClusterReplyMultiBulkSlots实现原理
我们对clusterReplyMultiBulkSlots函数进行分析:
void clusterReplyMultiBulkSlots(client *c) {/* Format: 1) 1) start slot* 2) end slot* 3) 1) master IP* 2) master port* 3) node ID* 4) 1) replica IP* 2) replica port* 3) node ID* ... continued until done*/int num_masters = ;void *slot_replylen = addDeferredMultiBulkLength(c);dictEntry *de;dictIterator *di = dictGetSafeIterator(server.cluster->nodes);while((de = dictNext(di)) != NULL) {/*注意:此处是对当前Redis节点记录的集群所有主节点都进行了遍历*/clusterNode *node = dictGetVal(de);int j = , start = -1;/* Skip slaves (that are iterated when producing the output of their* master) and masters not serving any slot. *//*跳过备节点。备节点的信息会从主节点侧获取。*/if (!nodeIsMaster(node) || node->numslots == ) continue;for (j = ; j < CLUSTER_SLOTS; j++) {/*注意:此处是对当前节点中记录的所有slot进行了遍历*/int bit, i;/*确认当前节点是不是占有循环终端的slot*/if ((bit = clusterNodeGetSlotBit(node,j)) != ) {if (start == -1) start = j;}/*简单分析,此处的逻辑大概就是找出连续的区间,是的话放到返回中;不是的话继续往下递归slot。如果是开始的话,开始一个连续区间,直到和当前的不连续。*/if (start != -1 && (!bit || j == CLUSTER_SLOTS-1)) {int nested_elements = 3; /* slots (2) + master addr (1). */void *nested_replylen = addDeferredMultiBulkLength(c);if (bit && j == CLUSTER_SLOTS-1) j++;/* If slot exists in output map, add to it's list.* else, create a new output map for this slot */if (start == j-1) {addReplyLongLong(c, start); /* only one slot; low==high */addReplyLongLong(c, start);} else {addReplyLongLong(c, start); /* low */addReplyLongLong(c, j-1); /* high */}start = -1;/* First node reply position is always the master */addReplyMultiBulkLen(c, 3);addReplyBulkCString(c, node->ip);addReplyLongLong(c, node->port);addReplyBulkCBuffer(c, node->name, CLUSTER_NAMELEN);/* Remaining nodes in reply are replicas for slot range */for (i = ; i < node->numslaves; i++) {/*注意:此处遍历了节点下面的备节点信息,用于返回*//* This loop is copy/pasted from clusterGenNodeDescription()* with modifications for per-slot node aggregation */if (nodeFailed(node->slaves[i])) continue;addReplyMultiBulkLen(c, 3);addReplyBulkCString(c, node->slaves[i]->ip);addReplyLongLong(c, node->slaves[i]->port);addReplyBulkCBuffer(c, node->slaves[i]->name, CLUSTER_NAMELEN);nested_elements++;}setDeferredMultiBulkLength(c, nested_replylen, nested_elements);num_masters++;}}}dictReleaseIterator(di);setDeferredMultiBulkLength(c, slot_replylen, num_masters);}/* Return the slot bit from the cluster node structure. *//*该函数用于判断指定的slot是否属于当前clusterNodes节点*/int clusterNodeGetSlotBit(clusterNode *n, int slot) {return bitmapTestBit(n->slots,slot);}/* Test bit 'pos' in a generic bitmap. Return 1 if the bit is set,* otherwise 0. *//*此处流程用于判断指定的的位置在bitmap上是否为1*/int bitmapTestBit(unsigned char *bitmap, int pos) {off_t byte = pos/8;int bit = pos&7;return (bitmap[byte] & (1<<bit)) != ;}typedef struct clusterNode {.../*使用一个长度为CLUSTER_SLOTS/8的char数组对当前分配的slot进行记录*/unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */...} clusterNode;
每一个节点(ClusterNode)使用位图(char slots[CLUSTER_SLOTS/8])存放slot的分配信息。
简要说一下BitmapTestBit的逻辑:clusterNode->slots是一个长度为CLUSTER_SLOTS/8的数组。CLUSTER_SLOTS是固定值16384。数组上的每一个位分别代表一个slot。此处的bitmap数组下标则是0到2047,slot的范围是0到16383。
因为要判断pos这个位置的bit上是否是1,因此:
off_t byte = pos/8:拿到在bitmap上对应的哪一个字节(Byte)上存放这个pos位置的信息。因为一个Byte有8个bit。使用pos/8可以指导需要找的Byte在哪一个。此处把bitmap当成数组处理,这里对应的便是对应下标的Byte。
int bit = pos&7:拿到是在这个字节上对应哪一个bit表示这个pos位置的信息。&7其实就是%8。可以想象对pos每8个一组进行分组,后一组(不满足8)的个数对应的便是在bitmap对应的Byte上对应的bit数组下标位置。
(bitmap[byte] & (1<<bit)):判断对应的那个bit在bitmap[byte]上是否存在。
以slot为10001进行举例:
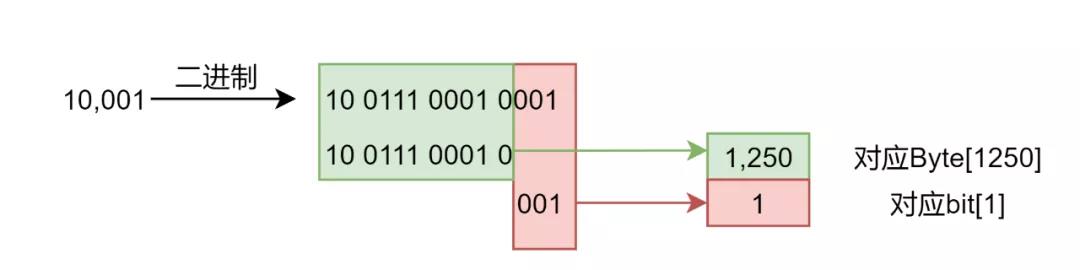
因此10001这个slot对应的是下标1250的Byte,要校验的是下标1的bit。
对应在ClusterNode->slots上的对应位置:

图示绿色的方块表示bitmap[1250],也就是对应存放slot 10001的Byte;红框标识(bit[1])对应的就是1<<bit 的位置。bitmap[byte] & (1<<bit),也就是确认红框对应的位置是否是1。是的话表示bitmap上10001已经打标。
总结ClusterNodeGetSlotBit的概要逻辑是:判断当前的这个slot是否分配在当前node上。因此ClusterReplyMultiBulkSlots大概逻辑表示如下:
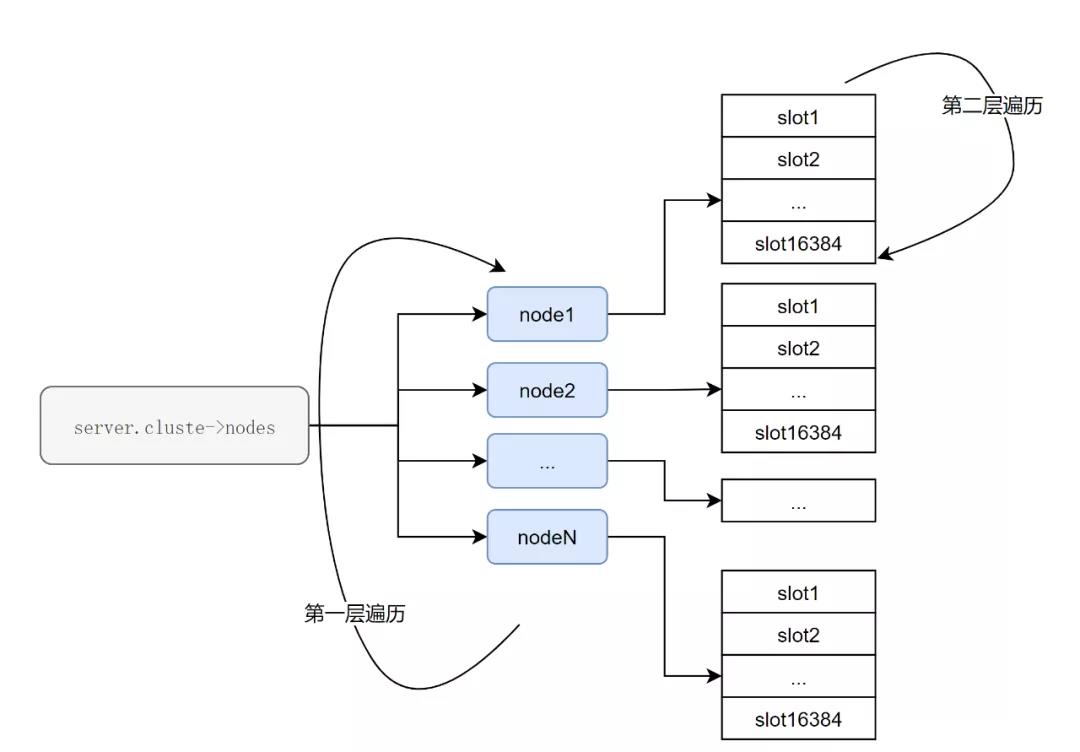
大概步骤如下:
对每一个节点进行遍历;
对于每一个节点,遍历所有的slots,使用ClusterNodeGetSlotBit判断遍历中的slot是否分配于当前节点;
从获取CLUSTER SLOTS指令的结果来看,可以看到,复杂度是<集群主节点个数> *<slot总个数>。其中slot的总个数是16384,固定值。
2.1.2 Redis热点排查总结
就目前来看,CLUSTER SLOTS指令时延随着Redis集群的主节点个数,线性增长。而这次我们排查的集群主节点数比较大,可以解释这次排查的现网现象中CLUSTER SLOTS指令时延为何较大。
2.2 客户端排查
了解到运维同学们存在扩容操作,扩容完成后必然涉及到一些key在访问的时候存在MOVED的错误。
当前使用的Hiredis-vip客户端代码进行简单的浏览,简要分析以下当前业务使用的Hiredis-vip客户端在遇到MOVED的时候会怎样处理。由于其他的大部分业务常用的Jedis客户端,此处也对Jedis客户端对应流程进行简单分析。
2.2.1 Hiredis-vip对MOVED处理实现原理
Hiredis-vip针对MOVED的操作:
查看Cluster_update_route的调用过程:
此处的cluster_update_route_by_addr进行了CLUSTER SLOT操作。可以看到,当获取到MOVED报错的时候,Hiredis-vip会重新更新Redis集群拓扑结构,有下面的特性:
因为节点通过ip:port作为key,哈希方式一样,如果集群拓扑类似,多个客户端很容易同时到同一个节点进行访问;
如果某个节点访问失败,会通过迭代器找下一个节点,由于上述的原因,多个客户端很容易同时到下一个节点进行访问。
2.2.2 Jedis对MOVED处理实现原理
对Jedis客户端代码进行简单浏览,发现如果存在MOVED错误,会调用renewSlotCache。
继续看renewSlotCache的调用,此处可以确认:Jedis在集群模式下在遇到MOVED的报错时候,会发送Redis命令CLUSTER SLOTS,重新拉取Redis集群的slot拓扑结构。
2.2.3 客户端实现原理小结
由于Jedis是Java的Redis客户端,Hiredis-vip是c++的Redis客户端,可以简单认为这种异常处理机制是共性操作。
对客户端集群模式下对MOVED的流程梳理大概如下:
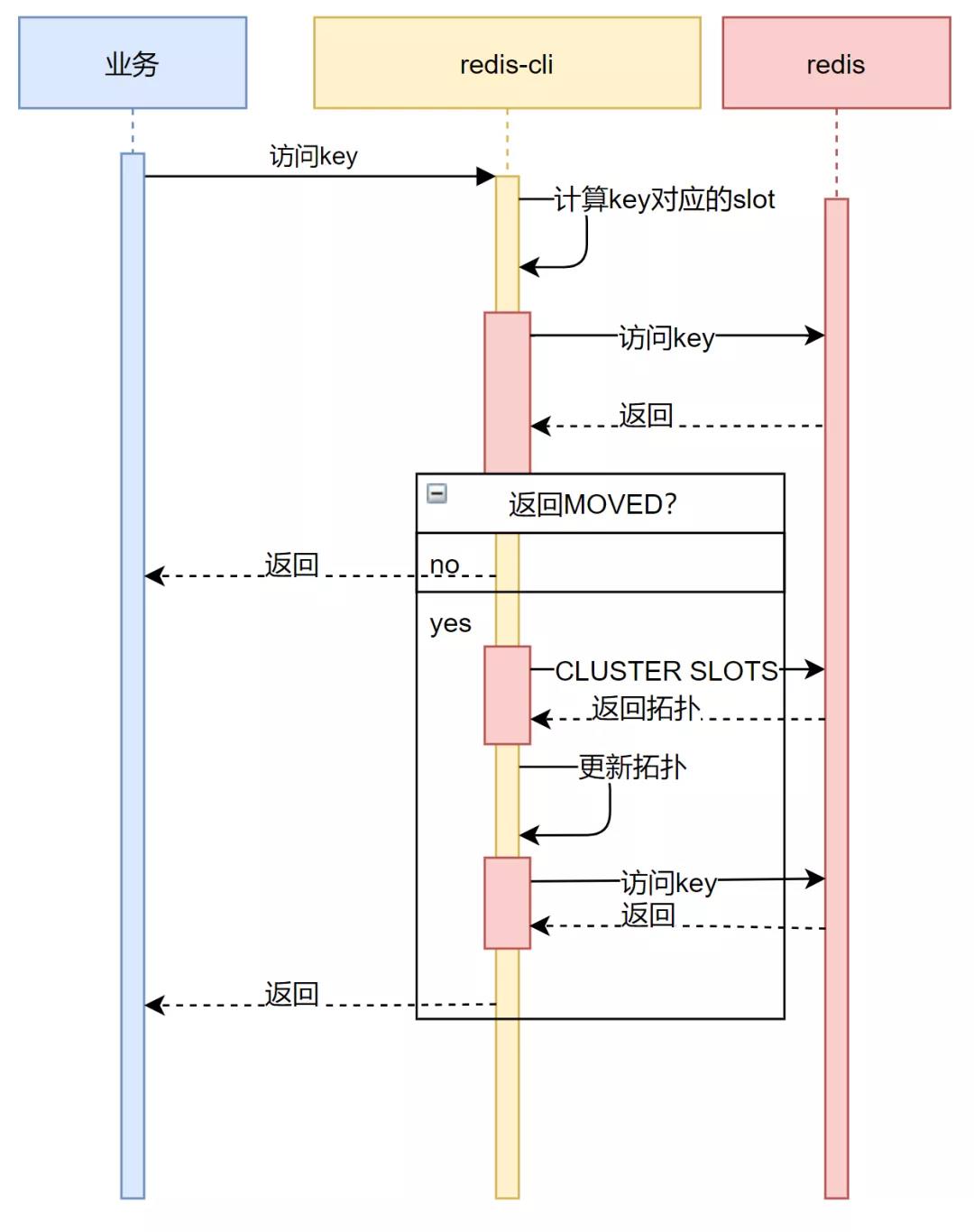
总的来说:
1)使用客户端缓存的slot拓扑进行对key的访问;
2)Redis节点返回正常:
访问正常,继续后续操作
3)Redis节点返回MOVED:
对Redis节点进行CLUSTER SLOTS指令执行,更新拓扑;
使用新的拓扑对key重新访问。
2.2.3 客户端排查小结
Redis集群正在扩容,也就是必然存在一些Redis客户端在访问Redis集群遇到MOVED,执行Redis指令CLUSTER SLOTS进行拓扑结构更新。
如果迁移的key命中率高,CLUSTER SLOTS指令会更加频繁的执行。这样导致的结果是迁移过程中Redis集群会持续被客户端执行CLUSTER SLOTS指令。
2.3 排查小结
此处,结合Redis侧的CLUSTER SLOTS机制以及客户端对MOVED的处理逻辑,可以解答之前的几个个问题:
为什么会有较多的Cluster指令被执行?
因为发生过迁移操作,业务访问一些迁移过的key会拿到MOVED返回,客户端会对该返回重新拉取slot拓扑信息,执行CLUSTER SLOTS。
为什么Cluster指令执行的时候CPU资源比较高?
分析Redis源码,发现CLUSTER SLOT指令的时间复杂度和主节点个数成正比。业务当前的Redis集群主节点个数比较多,自然耗时高,占用CPU资源高。
为什么节点规模大的集群迁移slot操作容易“中招”?
迁移操作必然带来一些客户端访问key的时候返回MOVED;
客户端对于MOVED的返回会执行CLUSTER SLOTS指令;
CLUSTER SLOTS指令随着集群主节点个数的增加,时延会上升;
业务的访问在slot的迁移期间会因为CLUSTER SLOTS的时延上升,在外部的感知是执行指令的时延升高。
此段与本文无关(webflux 是兼容Spring MVC 基于@Controller,@RequestMapping等注解的编程开发方式的,可以做到平滑切换)
三、优化
3.1 现状分析
根据目前的情况来看,客户端遇到MOVED进行CLUSTER SLOTS执行是正常的流程,因为需要更新集群的slot拓扑结构提高后续的集群访问效率。
此处流程除了Jedis,Hiredis-vip,其他的客户端应该也会进行类似的slot信息缓存优化。此处流程优化空间不大,是Redis的集群访问机制决定。
因此对Redis的集群信息记录进行分析。
3.1.1 Redis集群元数据分析
集群中每一个Redis节点都会有一些集群的元数据记录,记录于server.cluster,内容如下:
typedef struct clusterState {...dict *nodes; /* Hash table of name -> clusterNode structures *//*nodes记录的是所有的节点,使用dict记录*/...clusterNode *slots[CLUSTER_SLOTS];/*slots记录的是slot数组,内容是node的指针*/...} clusterState;
如2.1所述,原有逻辑通过遍历每个节点的slot信息获得拓扑结构。
3.1.2 Redis集群元数据分析
观察CLUSTER SLOTS的返回结果:
/* Format: 1) 1) start slot* 2) end slot* 3) 1) master IP* 2) master port* 3) node ID* 4) 1) replica IP* 2) replica port* 3) node ID* ... continued until done*/
结合server.cluster中存放的集群信息,笔者认为此处可以使用server.cluster->slots进行遍历。因为server.cluster->slots已经在每一次集群的拓扑变化得到了更新,保存的是节点指针。
3.2 优化方案
简单的优化思路如下:
对slot进行遍历,找出slot中节点是连续的块;
当前遍历的slot的节点如果和之前遍历的节点一致,说明目前访问的slot和前面的是在同一个节点下,也就是是在某个节点下的“连续”的slot区域内;
当前遍历的slot的节点如果和之前遍历的节点不一致,说明目前访问的slot和前面的不同,前面的“连续”slot区域可以进行输出;而当前slot作为下一个新的“连续”slot区域的开始。
因此只要对server.cluster->slots进行遍历,可以满足需求。简单表示大概如下:
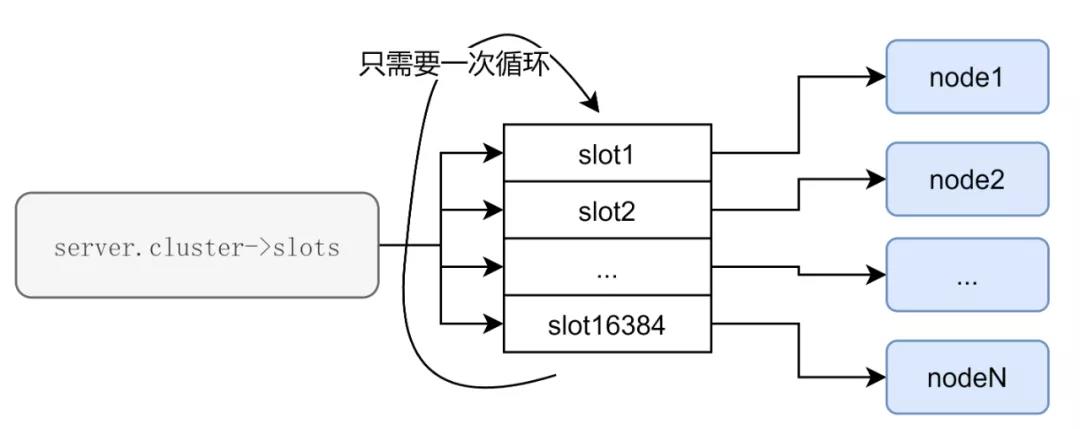
这样的时间复杂度降低到<slot总个数>。
3.3 实现
优化逻辑如下:
void clusterReplyMultiBulkSlots(client * c) {/* Format: 1) 1) start slot* 2) end slot* 3) 1) master IP* 2) master port* 3) node ID* 4) 1) replica IP* 2) replica port* 3) node ID* ... continued until done*/clusterNode *n = NULL;int num_masters = , start = -1;void *slot_replylen = addReplyDeferredLen(c);for (int i = ; i <= CLUSTER_SLOTS; i++) {/*对所有slot进行遍历*//* Find start node and slot id. */if (n == NULL) {if (i == CLUSTER_SLOTS) break;n = server.cluster->slots[i];start = i;continue;}/* Add cluster slots info when occur different node with start* or end of slot. */if (i == CLUSTER_SLOTS || n != server.cluster->slots[i]) {/*遍历主节点下面的备节点,添加返回客户端的信息*/addNodeReplyForClusterSlot(c, n, start, i-1);num_masters++;if (i == CLUSTER_SLOTS) break;n = server.cluster->slots[i];start = i;}}setDeferredArrayLen(c, slot_replylen, num_masters);}
通过对server.cluster->slots进行遍历,找到某个节点下的“连续”的slot区域,一旦后续不连续,把之前的“连续”slot区域的节点信息以及其备节点信息进行输出,然后继续下一个“连续”slot区域的查找于输出。
四、优化结果对比
对两个版本的Redis的CLUSTER SLOTS指令进行横向对比。
4.1 测试环境&压测场景
操作系统:manjaro 20.2
硬件配置:
CPU:AMD Ryzen 7 4800H
DRAM:DDR4 3200MHz 8G*2
Redis集群信息:
1)持久化配置
关闭aof
关闭bgsave
2)集群节点信息:
节点个数:100
所有节点都是主节点
压测场景:
使用benchmark工具对集群单个节点持续发送CLUSTER SLOTS指令;
对其中一个版本压测完后,回收集群,重新部署后再进行下一轮压测。
4.2 CPU资源占用对比
perf导出火焰图。原有版本:

优化后:
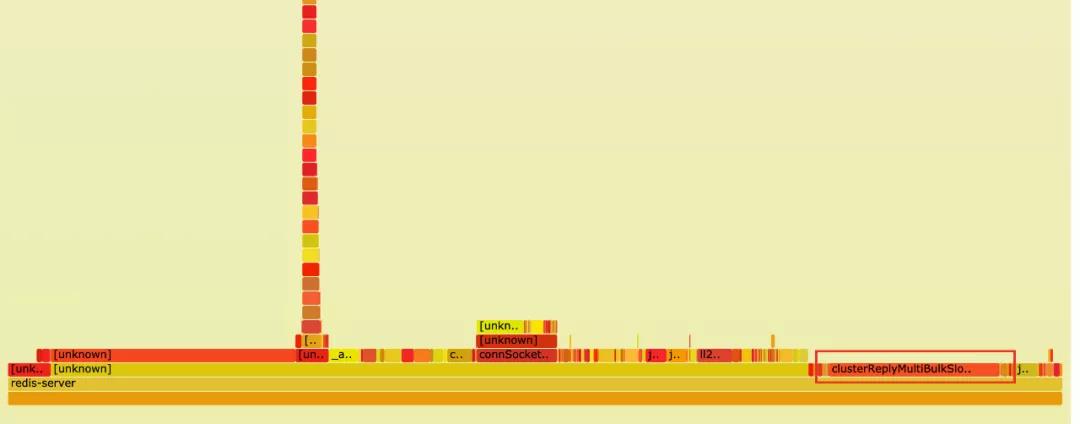
可以明显看到,优化后的占比大幅度下降。基本符合预期。
4.3 耗时对比
在上进行测试,嵌入耗时测试代码:
else if (!strcasecmp(c->argv[1]->ptr,"slots") && c->argc == 2) {/* CLUSTER SLOTS */long long now = ustime();clusterReplyMultiBulkSlots(c);serverLog(LL_NOTICE,"cluster slots cost time:%lld us", ustime() - now);}
输入日志进行对比;
原版的日志输出:
37351:M 06 Mar 2021 16:11:39.313 * cluster slots cost time:2061 us。
优化后版本日志输出:
35562:M 06 Mar 2021 16:11:27.862 * cluster slots cost time:168 us。
从耗时上看下降明显:从2000+us 下降到200-us;在100个主节点的集群中的耗时缩减到原来的8.2%;优化结果基本符合预期。
五、总结
这里可以简单描述下文章上述的动作从而得出的这样的一个结论:性能缺陷。
简单总结下上述的排查以及优化过程:
Redis大集群因为CLUSTER命令导致某些节点的访问延迟明显;
使用perf top指令对Redis实例进行排查,发现clusterReplyMultiBulkSlots命令占用CPU资源异常;
对clusterReplyMultiBulkSlots进行分析,该函数存在明显的性能问题;
对clusterReplyMultiBulkSlots进行优化,性能提升明显。
从上述的排查以及优化过程可以得出一个结论:目前的Redis在CLUSTER SLOT指令存在性能缺陷。
因为Redis的数据分片机制,决定了Redis集群模式下的key访问方法是缓存slot的拓扑信息。优化点也只能在CLUSTER SLOTS入手。而Redis的集群节点个数一般没有这么大,问题暴露的不明显。
其实Hiredis-vip的逻辑也存在一定问题。如2.2.1所说,Hiredis-vip的slot拓扑更新方法是遍历所有的节点挨个进行CLUSTER SLOTS。如果Redis集群规模较大而且业务侧的客户端规模较多,会出现连锁反应:
1)如果Redis集群较大,CLUSTER SLOTS响应比较慢;
2)如果某个节点没有响应或者返回报错,Hiredis-vip客户端会对下一个节点继续进行请求;
3)Hiredis-vip客户端中对Redis集群节点迭代遍历的方法相同(因为集群的信息在各个客户端基本一致),此时当客户端规模较大的时候,某个Redis节点可能存在阻塞,就会导致hiredis-vip客户端遍历下一个Redis节点;
4)大量Hiredis-vip客户端挨个地对一些Redis节点进行访问,如果Redis节点无法负担这样的请求,这样会导致Redis节点在大量Hiredis-vip客户端的“遍历”下挨个请求:
5)终的表现是大部分Redis节点的CPU负载暴涨,很多Hiredis-vip客户端则继续无法更新slot拓扑。
终结果是大规模的Redis集群在进行slot迁移操作后,在大规模的Hiredis-vip客户端访问下业务侧感知是普通指令时延变高,而Redis实例CPU资源占用高涨。这个逻辑可以进行一定优化。
目前上述分节3的优化已经提交并合并到Redis 6.2.2版本中。
