近期要连续出差,这几天加上周末除了整理出差资料就是在学习R语言,终于按期完成学习任务。前面、二章的学习可以算是入门和熟悉,这期简单数据处理则正式开始用R语言进行实战了。因此本关的笔记废话不叙,直奔主题。
1、书本基本数据管理实操练习
(1)生成一个数据框示例
manager <- c(1,2,3,4,5)
date <- c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country <- c("US","US","UK","UK","UK")
gender <- c("M","F","F","M","F")
age <- c(32,45,25,39,99)
q1 <- c(5,3,3,3,2)
q2 <- c(4,5,5,3,2)
q3 <- c(5,2,5,4,1)
q4 <- c(5,5,5,NA,2)
q5 <- c(5,5,2,NA,1)
leadership <- data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors = FALSE)
(2)创建新变量的3种方法
#种方法
mydata <- data.frame(x1 = c(2,2,6,4),x2=c(3,4,2,8))
mydata$sumx <- mydata$x1 + mydata$x2
mydata$meanx <- (mydata$x1 + mydata$x2)/2
#第二种方法
attach(mydata)
mydata$sumx <- x1 + x2
mydata$meanx <- (x1 + x2)/2
detach(mydata)
#第三种方法
mydata <- transform(mydata,sumx=x1 + x2,meanx=(x1 + x2)/2)
(3)变量重编码的2种方法
#变量的重编码(1)
leadership$age[leadership$age == 99] <- NA
leadership$agecat[leadership$age > 75] <- "Elder"
leadership$agecat[leadership$age >= 55 & leadership$age <= 75] <- "Middle Aged"
leadership$agecat[leadership$age < 55] <- "Young"
#变量的重编码的紧凑写法(2)
leadership <- within(leadership,{
agecat <-NA
agecat[age > 75] <- "Elder"
agecat[age >=55 & age <=75] <- "Middle Aged"
agecat[age < 55] <- "Young" })
(4)变量重命名的3种方法
#变量的重命名(1)
fix(leadership)
#变量的重命名(2)
names((leadership))
names(leadership)[2] <- "testdate"
leadership
#变量的重命名(3)
install.packages("plyr")
library(plyr)
leadership <- rename(leadership,
c(manager="managerID",date="testdate"))
(5)缺失值的检测和排除
#缺失值的检测
is.na(leadership[,6:10])
#在分析中排除缺失值
leadership
newdata <- na.omit(leadership)
(6)日期格式转化
#日期格式转化
myformat <- "%m/%d/%y"
leadership$testdate <- as.Date(leadership$testdate,myformat)
leadership
(7)数据集的选入和剔除
#数据的升序和降序排序
newdate2 <- leadership[order(leadership$age),]
newdate2
newdata3 <- leadership[order(-age),]
newdata3
#数据集中取子集
myvars <- c("q1","q2","q3","q4","q5")
newdata4 <- leadership[myvars]
newdata4
#剔除数据集中的部分变量
myvars1 <- names(leadership) %in% c("q3","q4")
newdata1 <- leadership[!myvars1]
newdata5 <- leadership[c(-8,-9)] #知道被剔除的变量是第几列情况下
newdata5
(8)图形初阶实践
dose <- c(20,30,40,45,60)
drugA <- c(16,20,27,40,60)
drugB <- c(15,18,25,31,40)
#直接键入值修改图形绘制参数
plot(dose,drugA,type="b",lty=3,lwd=3,pch=15,cex=2)
#使用plot()和par()组合函数修改图形参数
plot(dose,drugA,type = "b")
opar <- par(no.readonly = TRUE)
par(lty=2,pch=17)
plot(dose,drugA,type="b")
par(opar)
#灰度颜色图形绘制
n <- 10
mycolors <- rainbow(n)
pie(rep(1,n),labels=mycolors,col=mycolors)
mygrays <- gray(0:n/n)
pie(rep(1,n),labels=mygrays,col=mygrays)
2、朝阳医院Excels数据实践练习
(1)Excels数据的导入
#读入Excels数据
install.packages("openxlsx")
library(openxlsx)
readFilepath <- "G:/大数据作业实践和有用资料/第三关作业实践/课件源代码和数据/朝阳医院2016年销售数据.xlsx"
excelData <- read.xlsx(readFilepath,1)
(2)数据的预处理
##………………………………………………………………………………数据预处理阶段
#列名重命名
names(excelData) <- c("time","cardno","drugld","drugName","saleNumber","virtualmoney","actualmoney")
excelData1 <- excelData[!is.na(excelData$time),]
#安装stringr包并对time列截取出年月日部分
install.packages("stringr")
library(stringr)
timesplit <-str_split_fixed(excelData1$time," ",n=2)
excelData1$time <- timesplit[,1]
#转化成日期数值类型
fix(excelData1) #查看导入后的excelData1中数据存储类型
excelData1$time <- as.Date(excelData1$time,"%Y-%m-%d")
class(excelData1$time)
excelData1$saleNumber <- as.numeric(excelData1$saleNumber)
excelData1$virtualmoney <- as.numeric(excelData1$virtualmoney)
excelData1$actualmoney <- as.numeric(excelData1$actualmoney)
#按销售时间进行排序
excelData1 <- excelData1[order(excelData1$time,decreasing = FALSE),]
(3)月均消费次数统计
###月均消费次数统计——————项任务
kpi1 <- excelData1[!duplicated(excelData1[,c("time","cardno")]),]
consumeNumber <- nrow(kpi1)
consumeNumber
startTime <- kpi1$time[1]
endTime <- kpi1$time[nrow(kpi1)]
day <- endTime - startTime
class(day)
day <- as.numeric(day)
month <- day %/% 30
monthConsume <- consumeNumber %/% month
monthConsume
(4)月均消费金额计算
###月均消费金额计算——————第二项任务
totalMoney <- sum(excelData1$actualmoney,na.rm = TRUE)
monthMoney <- totalMoney / month
monthMoney
(5)客单价统计
###客单价----------——————第三项任务
pct <- totalMoney /consumeNumber
pct <- round(pct,2)
pct
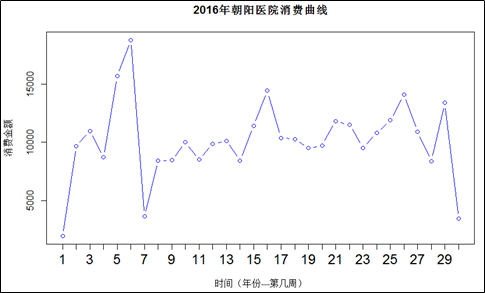
(6)消费趋势图形绘制和终趋势图
###消费趋势--------——————第四项任务
week <- tapply(excelData1$actualmoney,
format(excelData1$time,"%Y-%U"),
sum)
week <- as.data.frame.table(week)
week
names(week) <- c("time","actualmoney")
week$time <- as.character(week$time)
week$timeNumber <- c(1:nrow(week))
plot(week$timeNumber,week$actualmoney,
xlab = "时间(年份---第几周)",
ylab="消费金额",
xaxt="n",
main="2016年朝阳医院消费曲线",
col="blue",
type="b")
axis(1,at=week$timeNumber,labels = week$times,cex.axis=1.5)
3、几点心得和体会
(2)代码的目的是实现终想法,但写法可以是不拘一格、风格迥异的,发现这也是学编程的一大乐趣。
(3)函数的熟练应用和代码编写细节(如“[]”的应用)仍需边实践边加强巩固。
(4)有些函数功能无法使用,首先要检查其功能支持包是否安装,再查看哪些地方出错。
按照猴子老师的思路和给出的函数,照猫画虎的成功运行出结果,可见自己要想独立解决问题还是“路漫漫其修远兮”。但回看身后,出发的起点已经渐渐模糊,已经在漫漫的征途之中了,在自我成长的路上唯有快马加鞭,奋力向目标奔驰了。
这关学习很辛苦,自己给自己兑现奖励了。^_^ ^_^ ^_^
