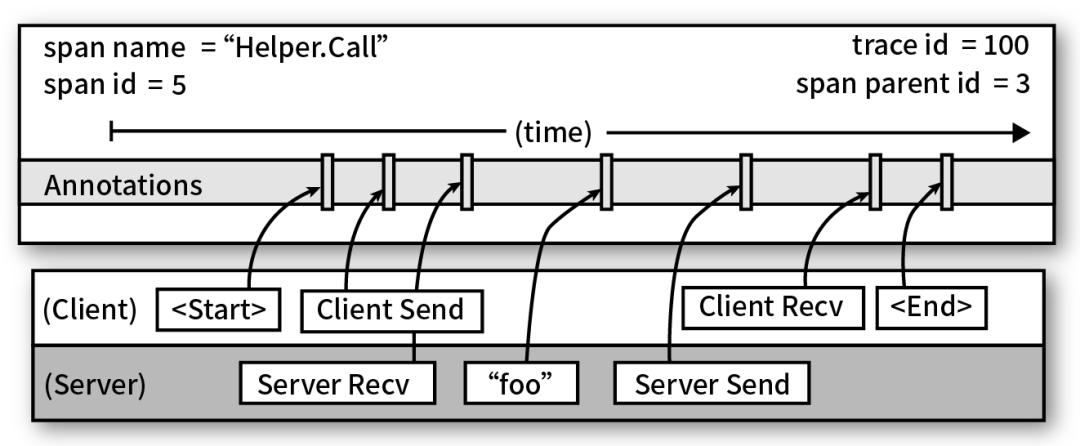
采样数据 VS 全量数据
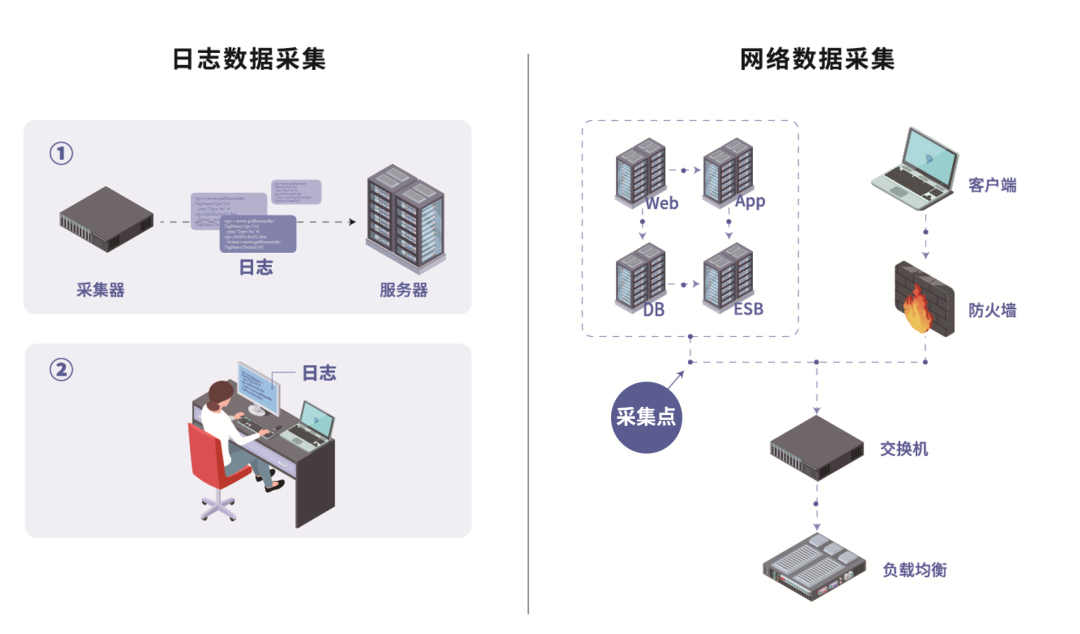
时间精度和实时性
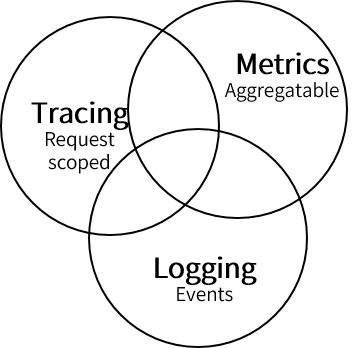
Metrics即指标,反映组件实时状况与健康度;
Trace即链路,反映在单次请求的范围内如何处理信息;
Log即日志,反映离散的事件或过程;
-
种做法:首先通过指标(Metrics),查看组件的健康程度、受影响的交易类型;再通过指标关联,查看整个交易路径的健康度(Trace);后,定位具体的问题节点(Log),找出根因。
第二种做法:当交易出现问题,首先查看出错的具体路径(Trace),再查看相对应的指标(Metrics),如服务器或应用性能指标等,后查看详细日志数据(Log)。
大问题:改造周期过长。
第二大问题:成本过高。
每个服务运行在自己的进程中;
微服务之间采用轻量级通信;
微服务应基于业务能力进行构建;
采用自动化部署机制实现微服务的独立部署;
服务的管理应采用小的中心化管理。