注:本文基于spark-2.4.4版本源码进行分析
首先从整体上看一下Dependency相关类的继承关系,有一个直观的印象:

然后从Dependency源码开始看。如下图:

Dependency是一个抽象类,类中的rdd成员是父RDD。
接着看NarrowDependency类:

NarrowDependency是一个抽象类。NarrowDependency覆盖了Dependency的rdd变量。其值等于NarrowDependency的主构造函数传进来的RDD。也就是说,我们需要传一个RDD作为主构造函数的参数,这个传进来的RDD其实就是父RDD。
同时NarrowDependency还定义了一个getParents(partitionId: Int): Seq[Int]方法。此方法是用来获得子RDD分区的所有父RDD分区。 此方法参数是子RDD的一个分区ID,返回值是子RDD的这个分区依赖的所有父RDD分区的ID。所以返回值是一个Seq[Int]。
接着看NarrowDependency的个子类:OneToOneDependency

OneToOneDependency顾名思义就是一对一依赖。也是比较简单,像map,filter,flatMap这种类型的算子中间产生的就是OneToOneDependency。
OneToOneDependency重写了getParents方法。因为子RDD分区和父RDD分区是一一对应的,所以分区id是相同的,直接返回List(partitionId)即可。
继续看NarrowDependency的第二个子类:RangeDependency

RangeDependency是范围依赖,用于UnionRDD中。为了理解RangeDependency重写的getParents方法的逻辑,我们先进入到UnionRDD源码中看一下,看UnionRDD的getDependencies方法。

UnionRDD的getDependencies方法实现逻辑也很简单。我们直接看96-99行对应的源码。通过遍历传入UnionRDD的rdds,对每一个rdd创建一个RangeDependency。参数inStart是父rdd的分区id起始值,都是从0开始。参数outStart是子rdd的分区id起始值,通过pos变量不断累加记录。
这样的话,再回到RangeDependency的getParents方法的逻辑中。if语句里面的两个判断语句是为了验证传入的分区id是否合理。如果合理,就返回对应的父rdd分区id。举个栗子:

假如我们想要得到子RDD3中分区id为5的分区在父RDD中的分区id。经过getParents方法可知后返回List(partitionId - outStart + inStart)。
partitionId等于5,outStart等于3,inStart等于0。故返回List(2)。正是对应父RDD2中的2号分区。
后我们来看ShuffleDependency

ShuffleDependency的构造函数传入:父RDD,分区器,序列化器,key的排序规则,aggregator以及是否进行map-side combine。而且我们看到ShuffleDependency是直接继承的Dependency,所以并没有getParent方法,因为宽依赖中,子RDD的一个partition可能依赖于父RDD的多个partition,所以没有提供getParent方法。
为了更好地理解ShuffleDependency,我们从reduceByKey算子开始看。这个算子在PairRDDFunctions类中。
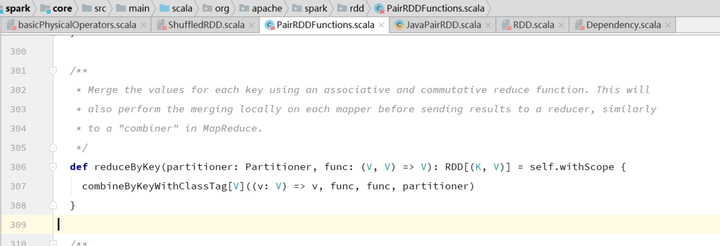
这里面其实还涉及到scala隐式转换的知识点。当我们这样使用时:rdd.reduceByKey。因为RDD类中没有定义reduceByKey这种[K,V]类型的算子,所以scala会自动进行隐式转换,从RDD的伴生对象中找到rddToPairRDDFunctions这个方法,把rdd转换为PairRDDFunctions类型。然后调用PairRDDFunctions中的reduceByKey。

reduceByKey这个算子内部会调用combineByKeyWithClassTag这个算子。

self就是调用reduceByKey算子的rdd。withScope用来做DAG可视化的。在withScope代码块里的创建的RDD,同属于一个scope。接着跟进combineByKeyWithClassTag这个算子。

看后的else里面的逻辑,new了一个ShuffledRDD。跟进ShuffledRDD源码的getDependencies源码:

后是返回了List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
直到这个时候才出现ShuffleDependency。参数prev就是调用shuffle算子的rdd。
至此,我们大概把Dependency的源码以及创建Dependency的逻辑了解了一下。
