背景
大家平时在开发过程中,会用Git来进行我们的代码管理。如Git这些,使用这些版本控制系统能轻松的帮我们
- 解决不同开发人员之间的代码冲突
- 处理版本回退
- 实现软件代码的CI/CD等
那大家考虑过么,针对数据库脚本怎么办的呢?有如下几个问题?
- 我们如何比对多环境的数据库版本是否一致?
- 几个人同时修改一个表,如何进行协同合作?
- 我们如何确定该脚本是否在生产环境运行过?
针对上述这些问题,可以通过一些Database migrations工具来进行解决,而Flyway就是其中一种工具!那么,目前为止 介绍flyway的文章,都紧紧的java生态关联在一起了,不具备工程化的能力!因此,才有了本文诞生,可以迅速在生产上搭建出工程化的数据库版本控制工具。
正文
约定
ok,为了避免歧义,我们先达成一些约定,避免后文看着看懵了!我们在开发过程中呢,一般有如下环境:
Dev环境:开发环境,该环境是程序猿们专门用于开发的环境,配置可以比较随意,主要是为了开发调试方便,例如可用来前后端联调等。
Test环境:测试环境,该环境一般为测试人员所用,主要验证我们所实现的功能是否满足我们业务所要求的规格。
Uat环境:用户验收测试环境,该环境一般为真实用户所用,例如你是给XX企业开发的系统,那么该环境就是给XX企业的人员进行验收测试环境
Staging环境:预发布环境,该环境一般是生产环境的镜像环境, 测试人员在Staging 环境上对新版本做后一轮验证, 通过后才能deploy到生产环境上
Prd环境:生产环境,该环境是正式提供对外服务的环境。
那么我们在开发过程中,在各个环境有对应分支,每次对应分支的代码变动时,Jenkins流水线会自动触发,将对应的分支代码Build到对应的环境上。一般情况下,Dev环境对应的就是Dev分支,Test环境对应的就是Test分支,。。。而Staging环境和Prd环境,对应的是基于master分支拉出的版本分支。
一般来说,版本分支有三位版本号,如1.3.0,位代表重大变更,例如涉及到代码框架替换这种级别的变更,改位。每次功能发布,改第二位。每次有紧急BugFix版本,改第三位~可能不同公司有不同的规范,但是这和本文关系不大。
那么开发流程一般如下

ok,到上面为止,都是大家懂的一些常识,可能流程上不同公司会有一些不大一样,例如有的公司上test环境,一定是从dev分支合过去,并不是从feature分支来合。大家在落地过程中,可以按照自己公司的流程进行对应修改,当然这并不影响后文阅读。
下面我们简单的介绍一下Flyway,不墨迹,几句话就能讲明白!
Flyway原理
Flyway在官网上提供了多种执行方式,但是我们要在项目中工程化的使用,我只推荐一种,就是命令行的方式~
那么,我只教一个命令就行了,只需要会这个命令,就能在项目中搭建出工程化的数据库版本控制工具。(画外音:么错,孤独烟老师就是这么diao,一个命令就能搞定一切~)
flyway -configFiles=config/flyway.conf migrateflyway.conf文件里头放的就是一些db的配置,主要是长这样的
flyway.driver=org.hsqldb.jdbcDriver
flyway.url=jdbc:hsqldb:file:/db/flyway_sample
flyway.user=SA
flyway.password=mySecretPwd
flyway.locations=database/migrations懂的人一看就知道,前面四个是数据库驱动的配置,第五个是sql脚本的位置!那么这个配置的含义就是,用前面四个配置连上数据库,然后执行sql脚本,就能操作数据库写入数据库~
Flyway的执行原理,我用大白话来说明一下,有如下几步:
- (1)FLyway会在数据库中创建一个flyway_schema_history的表,用于记录数据库当前的版本。
- (2)执行flyway migrate命令,根据config/flyway.conf配置中的连接信息连接到数据库。
- (3)检查指定目录下的sql文件,查找符合flyway命令格式的文件,然后比较这些sql文件的版本,如果sql文件版本比实际数据库中flyway_schema_history表里记录的版本要低,则执行升级版本的sql文件。
- (4)执行成功后,则更新flyway_schema_history表中记录。
ok,看到这里,你一定要问我两个问题~~
- (1)什么是符合flyway命令格式的文件?
- (2)什么是sql文件的版本,sql文件还有版本这个概念么?
我们看一张图

只要你在脚本文件夹下,建立符合上述规范的文件,flyway就会将其认为是有效文件,从而执行。例如文件名可以是V2.1__init_request.sql . 注意:version和descprition之间的分割符是双下划线__
但是,孤独烟老师不得不说一句了!我们实战中文件不这么命名,因为这么命名,维护起来不方便。
其实,我们这些sql文件也是有规范的~可以像下面这么叫
V{version}_{date}_{num}__{type}_{description}_{Author}.sql例如V1_0_0_20220418_1__DDL_alter_table_medicinenames_guduyan.sql
当然,你不守这个规范,也是可以的。只是这么做,以后维护起来方便而已~
在这里
- version : 每次发版的项目版本号,参考我上面提到的项目版本号的概念呢,_会翻译为小数点,1_0_0 即为项目1.0.0 版本
- date: 提交日期2022年4月18日
- num: 开发人员自由命名,格式必须为数字,主要是为了防止有同版本文件文件出现
- type: sql文件类型 DML 数据更新(插入、更新、删除); DDL 结构更新; DCL 权限控制;
- description: 文件描述
- Author: 开发人员姓名
注意了,这种命名规范下,有两个版本的概念,一个是sql文件的版本,一个是项目的版本。我用一张图来对比一下
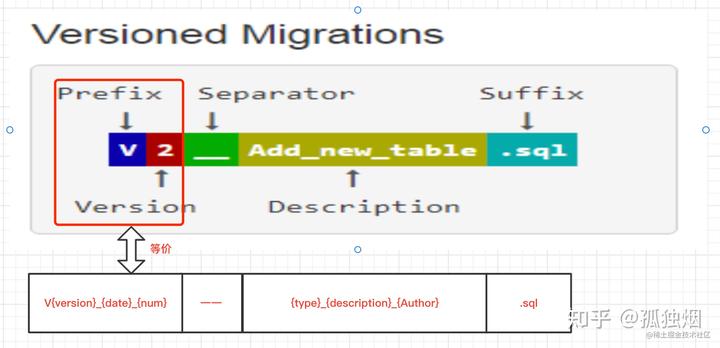
也就是说sql文件的版本是1.0.0.20220418.1(_会翻译为小数点),项目的版本是1.0.0
当然,可能这里你们会有点懵,来来来,孤独烟老师打个实战比方,一点就通! 打个比方: 假设今天是2022年4月18日,孤独烟老师要发布一个1.0.0项目的sql脚本~
这个项目对于数据库的改动,刚好要创建一个person_tab,并且初始化两条数据在里头~
因此只要在对应的脚本目录下,准备两个文件时,分别是: V1_0_0_20220418_1__DDL_create_person_table_guduyan.sql 内容为
CREATE TABLE Person_table(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
Feature varchar(255)
);V1_0_0_20220418_2__DML_insert_person_table_guduyan.sql 内容为
INSERT INTO Person_table
(PersonID, LastName, FirstName, Address, Feature)
VALUES(1, '烟', '孤独', NULL, '帅');
INSERT INTO Person_table
(PersonID, LastName, FirstName, Address, Feature)
VALUES(2, '雄', '周', NULL, '非常帅');执行命令
flyway migrate此时呢,就会连上对应数据库,与flyway_schema_history的表中数据对比,判断则两个sql是否在该数据库中执行过,发现没有,则执行sql脚本,创建表,并且插入两条数据。执行完结果如下~
Person_table表的数据为

flyway_schema_history表的数据为
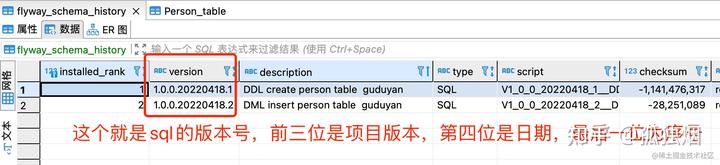
看到这里,回忆一下我们的规范
V{version}_{date}_{num}__{type}_{description}_{Author}.sql能明白为什么有{num}位了么,因为如果没有该位,sql版本就是1.0.0.20220418,此时容易产生冲突,总不可能一天就一份sql文件吧?因此在后面再带一位编号~ 当然,各公司可能有自己的规范,按照各自规范实现即可~
ok,有了上面的基础知识,可以来说说说项目中如何使用了(这才是实战经验)~
项目中使用
实战中,我们往往不单独用Flyway,必定是和Jenkins一起用~
大家莫急,听我细细到来~
假设,我们有一个仓库,专门放项目的sql脚本的,推荐仓库名这么命名~
{项目名}-database-flyway我们姑且认为这个项目叫guduyan,那么这个仓库名字就是guduyan-database-flyway,仓库下目录结构如下
guduyan-database-flyway
├── config
│ ├── Jenkinsfile
│ ├── flyway.conf
├── README.md
└── sql
├─V1_0_0_20220418_1__DDL_create_person_table_guduyan.sql
├─V1_0_0_20220418_2__DML_insert_person_table_guduyan.sql当然,分支和我们的项目一样,有dev分支,test分支等~提交sql流程,和我们提交项目代码流程类似,不赘述~
Jenkins上我们需要配置一个多任务流水线,可以监听各个分支的变更,然后执行
Jenkinsfile里头的pipeline脚本,去操作对应环境的数据库,执行flyway命令~
后,我们不要忘了在gitlab上配一个Hook,这样代码发生变更,才能通知到jenkins。
(可能会有人觉得这里写的比较简单,木有图,我只想说,我又不是教你jenkins怎么用,讲思路就行了~但凡配过jenkins的,基本都能get到我在说啥~)
那么,我们在提交sql脚本的时候,例如从feature分支,合并到dev分支~
我们把代码提交到feature分支后,发起一个从feature分支到dev的Merge Request,由对应人员Merge代码以后,Gitlab可以自动通知jenkins进行build操作,然后对应data-flyway流水线就会拉取gitlab代码,执行pipeline脚本,执行指定目录下面的sql脚本,完成对数据库的操作~
具体如下图所示

总结
写到这里,基本上将Flyway工程化的套路讲完了!那么,接下来思考两个问题 - (1)已经上线的项目,数据库里已经有大量表,如何接入Flyway进行管理? - (2)如果我在Test环境执行了脚本,上到Uat后,发现这个脚本在Uat执行有风险,如何回滚?
后,谢谢大家阅读~~
