一、背景
转转早期的监控系统zzmonitor是纯自研的,其数据上报方式比较简单,有且仅有四种数据上报方式:SUM、MAX、MIN、AVG。示例如下:
public void test() {
long start = System.currentTimeMillis();
//do something
long cost = System.currentTimeMillis() - start;
ZMonitor.sum("执行次数", 1);
ZMonitor.max("大耗时", cost);
ZMonitor.min("小耗时", cost);
ZMonitor.avg("平均耗时", cost);
}
数据在客户端会每分钟做一次聚合,并以异步、批量的方式发送到zzmonitor服务端。另外,zzmonitor的存储选型是MySQL,分了128张表也仅能支持7天的数据存储。
以聚合方式来上报数据的目的是为了减少监控系统的数据存储量,但是同时也牺牲了太多,随着转转业务的发展,zzmonitor的弊端也逐渐显露:
功能少,业务反馈大
仅提供这四个函数,无法监控QPS、TP99等。
API设计不合理
以聚合方式来上报数据不够灵活,同样的数据,业务需要按照聚合方式多次上报;同时,部分数据无法二次加工,如:只能监控1分钟的平均值,无法监控到一天的平均值。
架构设计不合理
监控数据通常与时间强相关,使用MySQL存储性能差,数据压力也较大。存储数据常适合存储于时序数据库,时序数据库会带来良好的读写性能与数据压缩比。
维护&开发成本高
随着业务量的上升,系统的很多地方出现了性能瓶颈,需要人持续的维护、排查问题。新功能的迭代也需要持续投入人力。
另外,除了给业务使用的zzmonitor,运维层面还有各式各样的监控系统,如:Falcon、夜莺、ZABBIX、Prometheus等,这给业务线同学使用上带来一定的困惑。
二、调研选型
基于以上背景,我们决定落地一套全新的立体式监控系统,能够集业务服务、架构中间件、运维资源于一体,简单易用,同时便于维护。落地前期主要针对Cat、夜莺、Prometheus做了一部分调研选型。
| Cat | 夜莺 | Prometheus | |
|---|---|---|---|
| Contributors | 77 | 56 | 643 |
| Star | 16.3k | 4k | 40.2k |
| 偏向性 | 链路监控、日志监控 | 资源监控 | 任何业务指标与中间件监控 |
| 功能 | 一般 | 简单,但不够强大、不够灵活 | 接入Grafana后功能丰富,十分灵活 |
| 存储 | HDFS | 官方强烈推荐M3DB | 任何实现Prometheus远端存储协议的存储 |
| 开源时间 | 2011 | 2020 | 2012 |
| 数据上报方式 | 埋点构建消息树 | 调用Http接口推送本地Agent | Prometheus server主动pull |
| 社区活跃度 | 一般 | 一般 | 活跃 |
总体来说,Cat更适合链路监控,夜莺更像一个简化版的Prometheus+Grafana,而Prometheus拥有非常灵活的PromQL、完善的Exporter生态,我们终选择了Prometheus。
三、Prometheus能力
3.1 生态模型
Prometheus自带一个单机的TSDB,他以pull模式抓取指标,被抓取的目标需要以Http的方式暴露指标数据。对于业务服务,服务需要将地址注册到注册中心,Prometheus做服务发现,然后再做指标抓取。
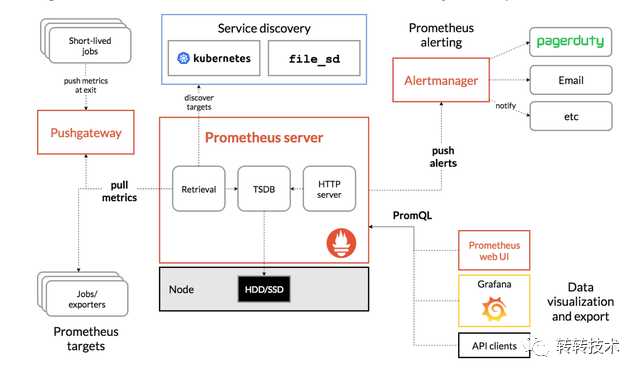
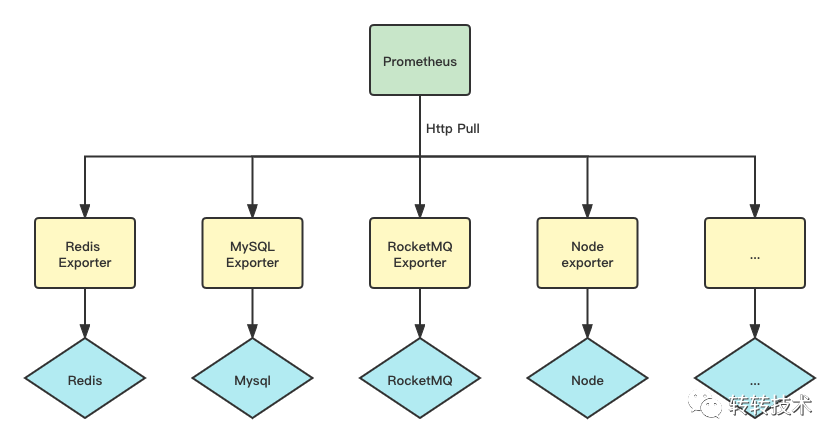
Prometheus拥有非常完善的Exporter生态,大部分我们使用的中间件都有成熟的Exporter,利用这些Exporter,我们可以快速的搭建起监控体系。
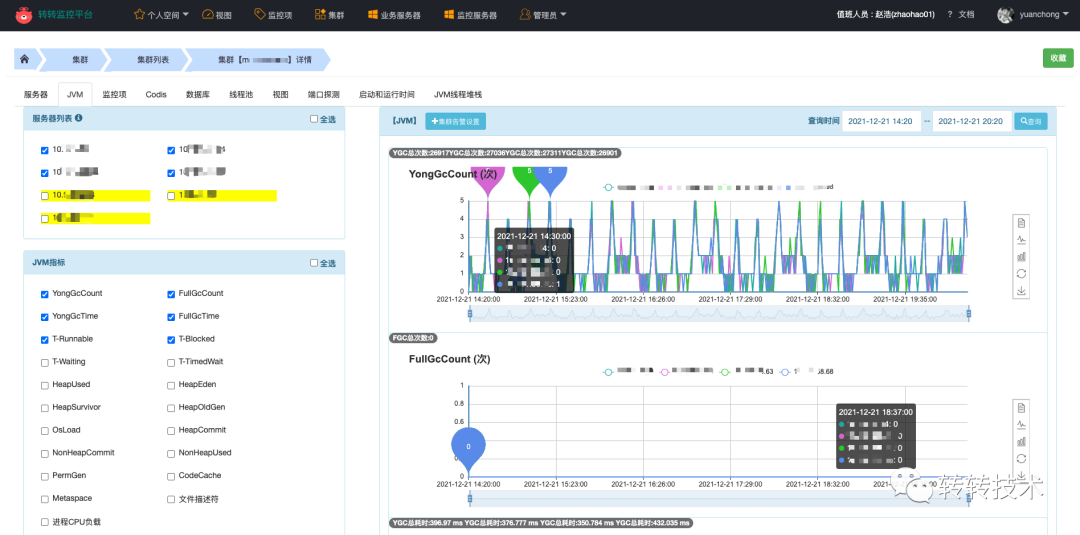
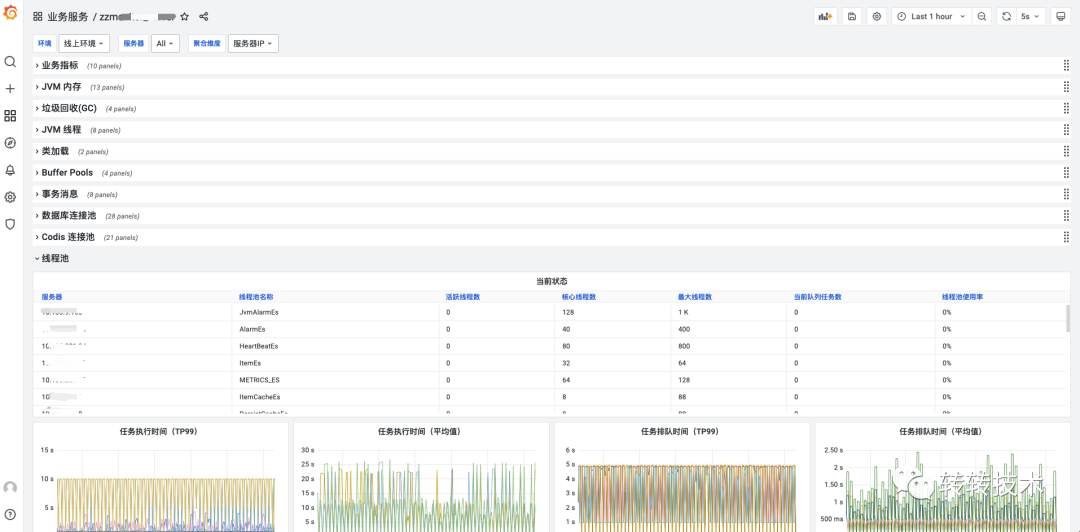
Prometheus的黄金搭档Grafana在可视化方面表现也十分不错,Grafana拥有非常丰富的面版、灵活易用。以下是我们落地的实际效果图。
Prometheus从客户端角度区分出了几种指标类型:Counter、Gauge、Histogram、Summary(转转内部不建议使用)。
3.2 Counter
Counter是一个只增不减的计数器,Prometheus抓取的是Counter当前累计的总量。常见的如GC次数、Http请求次数都是Counter类型的监控指标。
Counter counter = Counter.build().name("upload_picture_total").help("上传图片数").register();
counter.inc();
以下是Counter的样本数据特点,我们可以在查询时计算出任意一段时间的增量,也可以计算任意一段时间的增量/时间,即QPS。
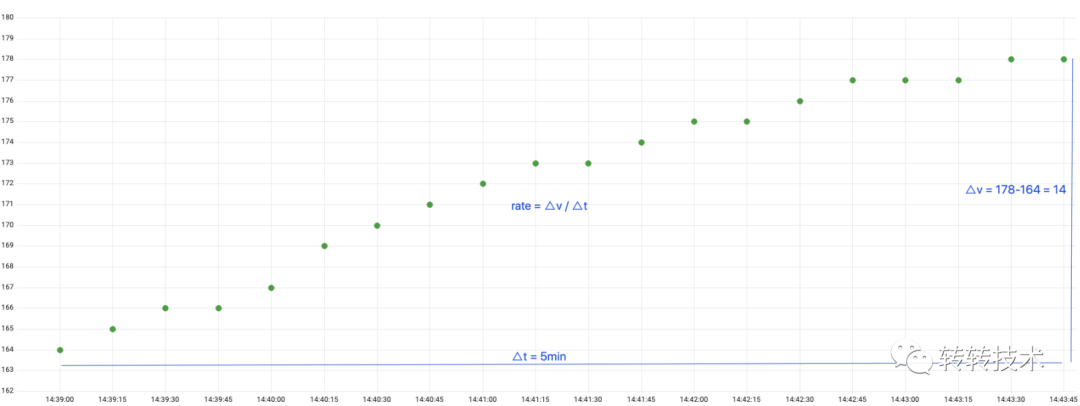
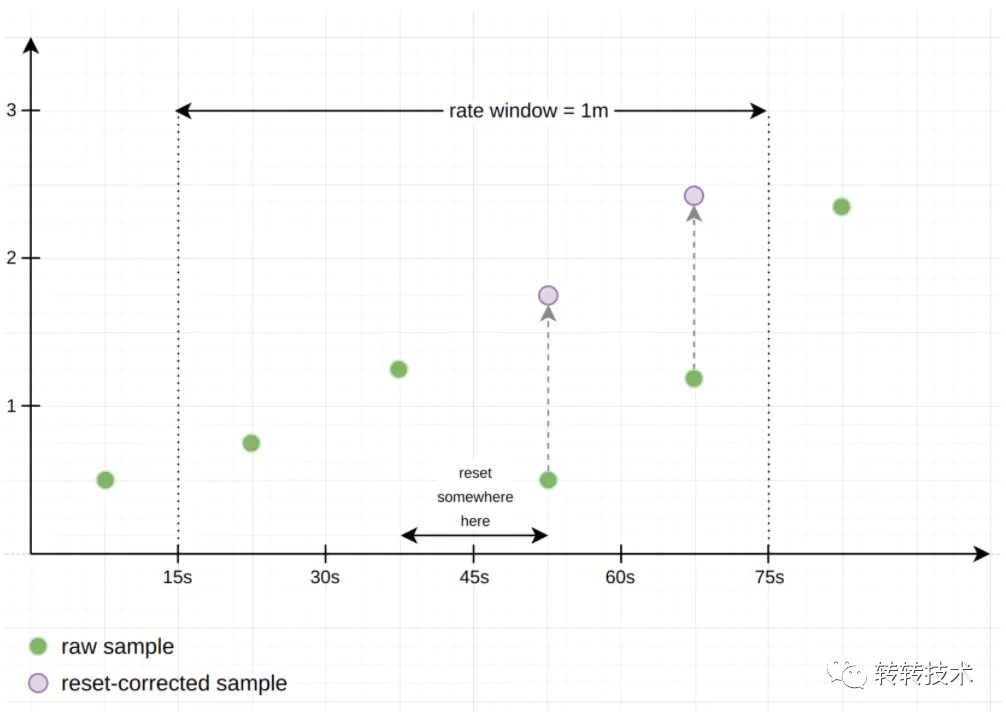
如果服务器重启,Counter累计计数归零,Prometheus还能计算出准确的增量或QPS吗?Prometheus称这种情况为Counter重置,Counter在重置后总是从0开始,那么根据这个假设,在给定的时间窗口计算增量时,只需将重置后的样本值叠加上重置前的值,以补偿重置,就像重置从未发生过一样。
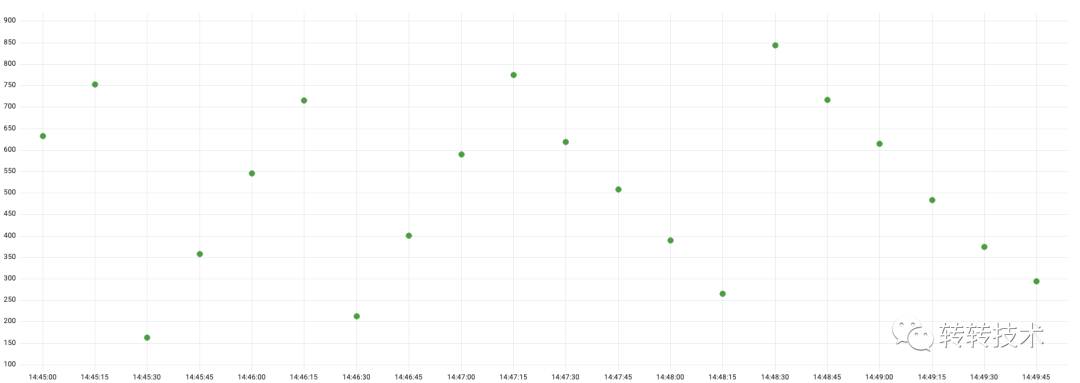
3.3 Gauge
Gauge是个可增可减的仪表盘,Prometheus抓取的是Gauge当前时刻设置的值。常见的如内存使用量、活跃线程数等都是Gauge类型的监控指标。
Gauge gauge = Gauge.build().name("active_thread_num").help("活跃线程数").register();
gauge.set(20);
以下是Gauge类型的样本数据特点,我们一般不做二次计算,直接展示Prometheus抓取的原始值。
3.4 Histogram
Histogram通常用于数据分布统计,Histogram需要定义桶区间分布,根据用户上报的数据,来决定具体落到哪个桶内。
Histogram histogram = Histogram.build().name("http_request_cost").help("Http请求耗时").buckets(10, 20, 30, 40).register();
histogram.observe(20);
以下是部分源码,各个桶内存储上报的总次数,Prometheus抓取的是各个桶的当前状态。
public void observe(double value) {
for (int i = ; i < bucket.length; ++i) {
//遍历所有桶,如果数据小于桶上限,对应桶+1
if (value <= bucket[i].le) {
bucket[i].add(1);
break;
}
}
//增加sum总值
sum.add(value);
}
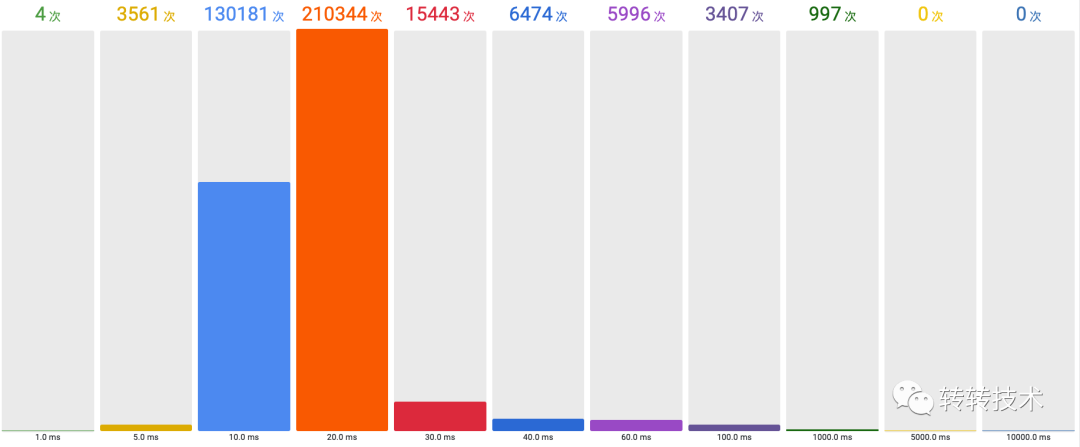
基于各个时刻的桶内数据,我们可以计算出任意一段时间的数据分布情况。如下为例,我们可以利用桶内数据计算出10:01~10:02的数据分布情况。
| 10ms | 20ms | 30ms | 40ms | |
|---|---|---|---|---|
| 2021-10-01 10:01 | 5 | 10 | 20 | |
| 2021-10-01 10:02 | 1 | 10 | 10 | 20 |
| increase[1m] | 1 | 5 |
这个计算结果可视化后可能如下图所见,实际意义可能是一天的RPC调用耗时分布。基于这个计算结果,还可以计算出TP值,即n%的值都不高于x。
如果我们每个时间点都计算一次分布,我们就得到了这样的面板:分布折线图。
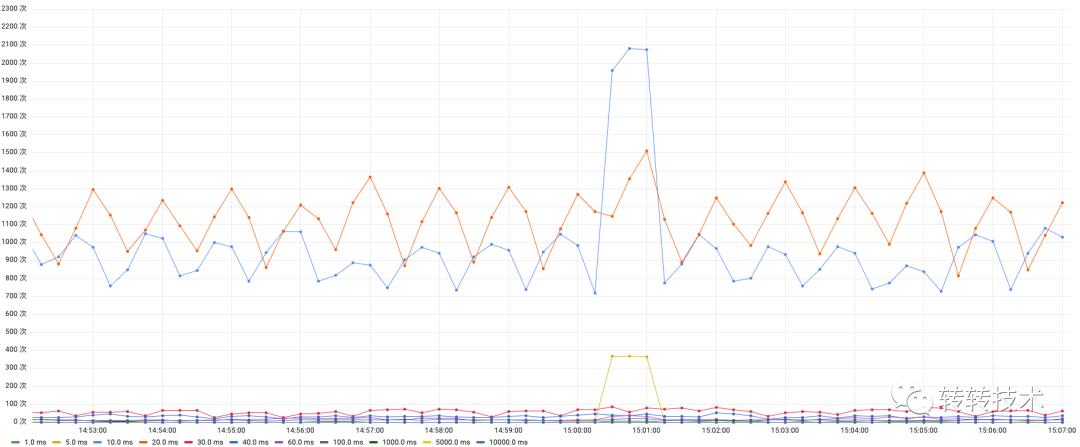
利用这个数据,我们还可以换一种表现形式:热力图。热力图每个时刻都是一个直方图,热力图通过颜色深浅区分出数据分布的占比。
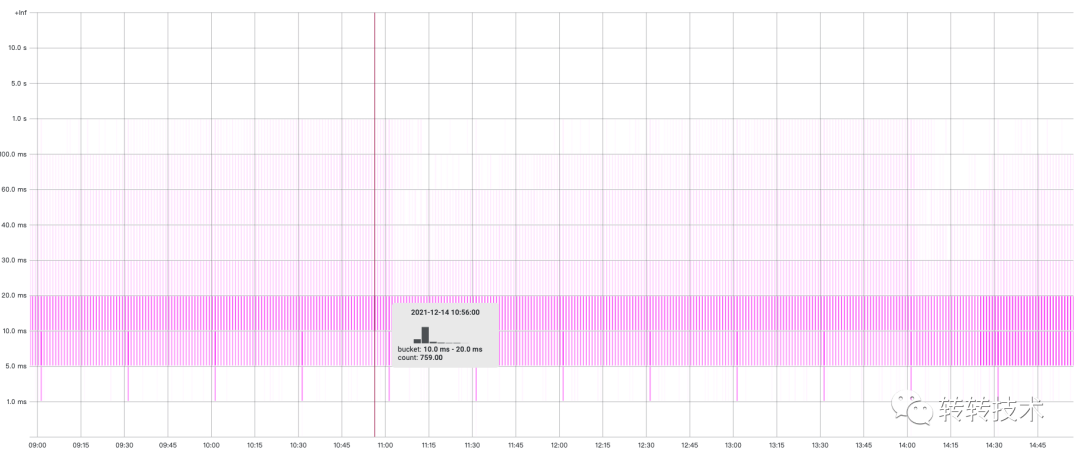
Histogram除了buckets,还记录了sum(上报数据的总值)、count(上报数据的总次数)。我们通过一段时间内sum的增量/count的增量,即可算出上报数据的平均值。
3.5 多维标签
Prometheus的指标可以定义多个标签,比如对于以下指标:
Counter counter = Counter.build().name("http_request").labelNames("method","uri").help("Http请求数").register();
counter.labels("POST", "/addGoods").incr();
counter.labels("POST", "/updateGoods").incr(2);
counter.labels("GET", "/getGoods").incr();
数据上报后,类比MySQL表,表名为http_request,某一时刻的表数据如下:
| method | uri | value |
|---|---|---|
| POST | /addGoods | 1 |
| POST | /updateGoods | 2 |
| GET | /getGoods | 1 |
有了这些结构化的数据,就可以在任意维度进行查询和聚合。比如,查询uri=/addGoods的数据;再比如,按照method维度做SUM聚合,查看总数。
3.6 误差
Prometheus 在设计上就放弃了一部分数据准确性,得到的是更高的可靠性,架构简单、数据简单、运维简单、节约机器成本与人力成本。通常对于监控系统,数据拥有少量的误差是可以接受的。
如计算增量时,给定的时间窗口中的个和后一个样本,永远不会与真实的采样点重合,Prometheus会做数据线性外推,估算出对应时间的样本值。
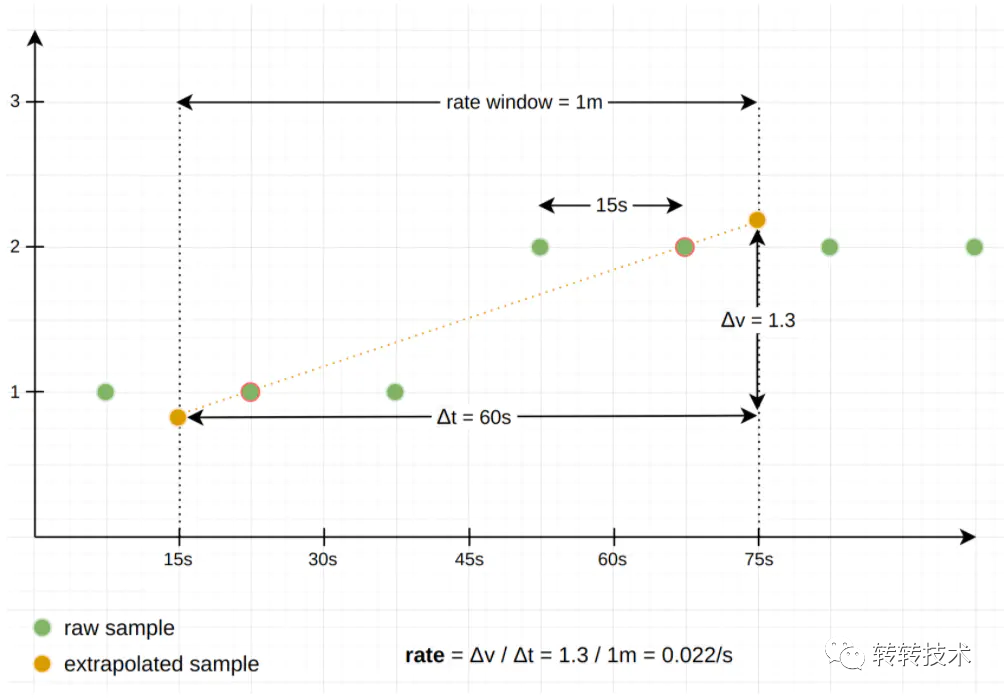
四、架构设计
4.1 远端存储
Prometheus自带一个单机的TSDB,显然这是远远不够的,好在Prometheus提供了存储的扩展,自定义了一套读写协议。当发送读写事件时,Prometheus会将请求转发到三方存储中。

我们经过选型对比,终选定M3DB作为远端存储。M3DB是Uber开源的专为Prometheus而生的时序数据库,拥有较高的数据压缩比,同时也是夜莺强烈推荐的三方存储。
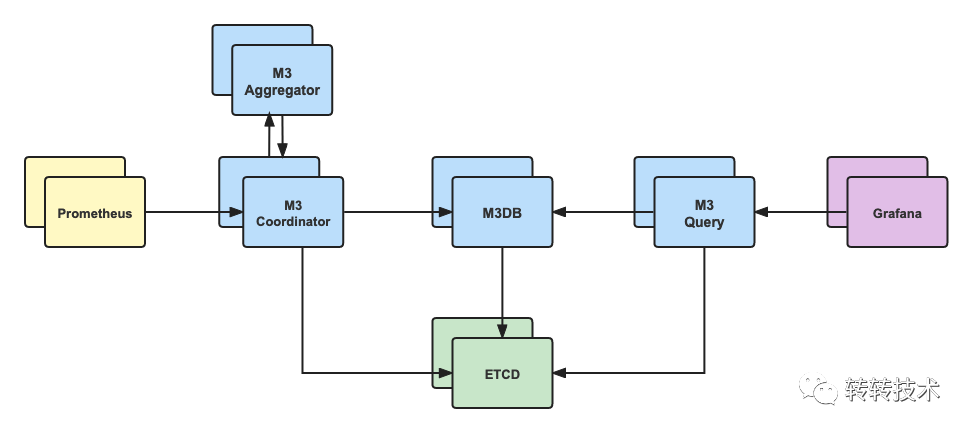
M3 Coordinator(M3 协调器) :M3协调器是一个协调Prometheus和 M3DB 之间的读写的服务。它是上下游的桥梁,自身无状态。 M3DB(存储数据库) :M3DB是一个分布式时间序列数据库,是真正的存储节点,提供可扩展的存储和时序索引。 M3 Query (M3 查询引擎) :M3DB专用查询引擎,兼容Prometheus查询语法,支持低延迟实时查询和长时间数据的查询,可以聚合更大的数据集。 M3 Aggregator (M3 聚合器) :M3聚合器是一个专用的指标聚合器,会保证指标至少会聚合一次,并持久化到M3DB存储中,可用于降采样,提供更长久的存储。
4.2 官方路线
以下是完全以官方路线设计出的系统架构,转转的线上环境比较复杂,并没有完全容器化,我们需要单独引入注册中心。各个业务的服务在启动时将地址注册到注册中心,Prometheus再从注册中心做服务发现,然后再做指标的拉取,终将数据推送到M3DB中。
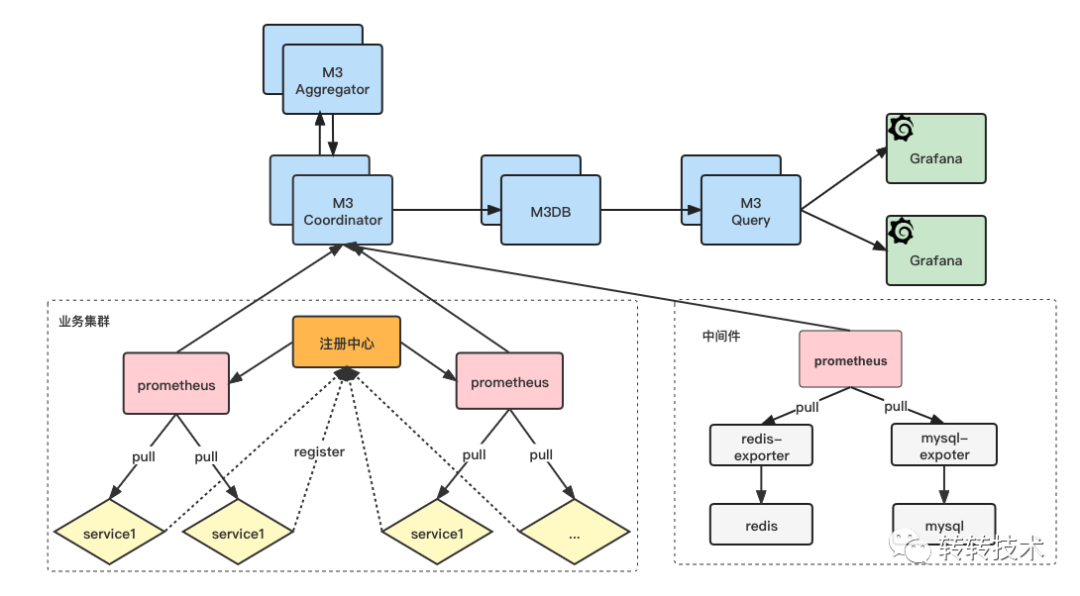
这套架构模型比较复杂,主要体现在以下几点:
架构复杂、层级太深、模块太多,运维成本高 客户端较重,需要引入注册中心 Prometheus的作用仅仅是个指标抓取的中转,即没必要也容易增加问题点,还需要考虑分片的问题
4.3 客户端设计
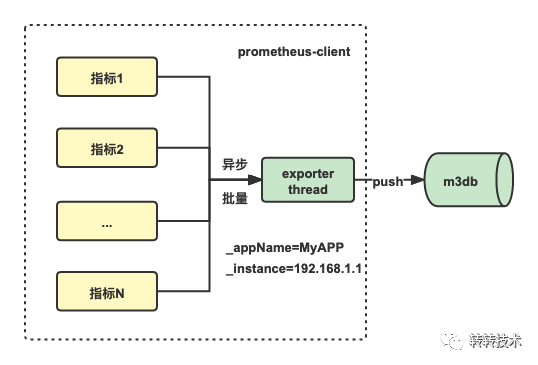
面对以上架构,我们做了一些思考,既然Prometheus可以将拉取到的指标数据推送到三方存储,为什么我们不能在业务服务上绕过Prometheus而直接推送到三方存储呢?
于是,我们调研了Prometheus远端存储协议,改进了客户端的设计。客户端遵循Prometheus远端存储协议(ProtoBuf + Http),并以异步、批量的方式主动将指标推送到M3DB。
改进之后客户端非常轻量,近乎零依赖,并且完全兼容原生客户端用法,因为我们只修改了数据上报的内核逻辑,对API无任何修改。
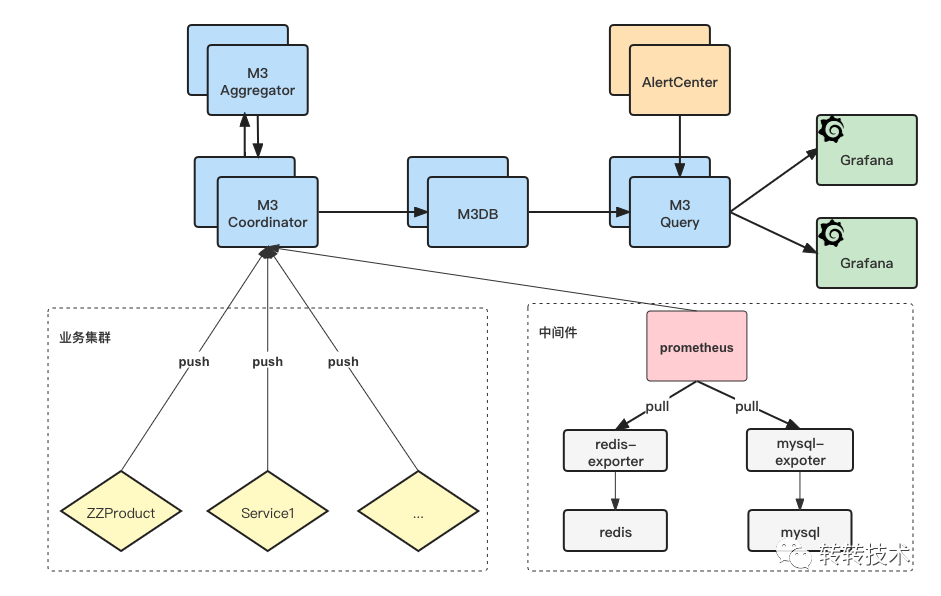
4.4 终架构
终,我们的系统架构如下图所示,对于业务服务,我们会通过客户端主动将指标推送到M3DB中;而对于各个中间件,由于服务IP变动不频繁,继续沿用Exporter生态。
这样,我们省去了注册中心,省去了服务发现,也省去了抓取分片。对于业务服务我们甚至省去了Prometheus,我们只用了Prometheus的协议,而没有使用Prometheus的服务。
4.5 性能测试
由于Prometheus需要在客户端埋点上报数据,我们对客户端的性能也做了重点测试。
| Counter | Gauge | Histogram | ||
| QPS | 单线程 | 4300W | 4100W | 2600W |
| 10线程 | 3030W | 2600W | 3030W | |
| 50线程 | 2940W | 2940W | 2380W | |
| 平均耗时 | 单线程 | 23ns | 24ns | 38ns |
| 10线程 | 33ns | 38ns | 33ns | |
| 50线程 | 34ns | 34ns | 42ns | |
| 内存 | 100个标签 | 20KB | 20kb | 77kb |
| 200个标签 | 39KB | 39KB | 153KB | |
| 500个标签 | 96KB | 96KB | 381KB |
五、落地实现
5.1 Grafana规划
个规划是多环境统一,不管线上、沙箱、测试环境,都统一使用同一个Grafana,避免维护多套面板、避免业务记多套地址。
第二个是维度划分,我们目前对Dashboard划分四个维度:
业务大盘
我们每个研发同学、每个部门都会负责很多服务,业务大盘摘取了大家负责服务的重点指标,提供一个全局的视角。
业务服务
这里是以业务服务为维度,拥有我们内置的各种监控面板,是一个All In One的视角。
架构组件
以各个组件为维度,监控所有服务整体使用情况,如线程池监控、日志监控。
运维组件
以运维视角来看到各个中间的监控,如Redis、Nginx等。
5.2 数据打通
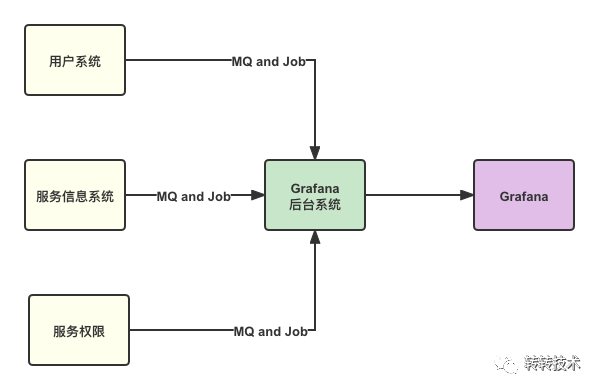
对于监控数据,尤其是业务指标监控,有些数据是比较敏感的,我们打通公司内部用户系统,就可以实现认证、鉴权权限控制。除此之外,我们还打通了服务信息系统、服务权限系统。
5.3 企业微信认证
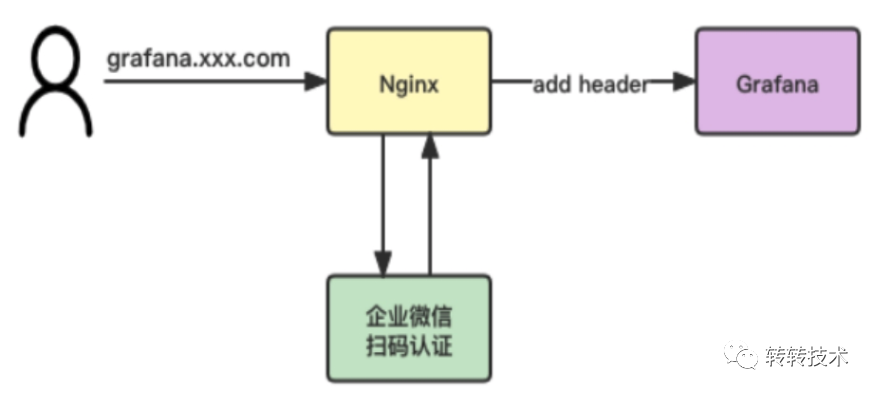
转转的内部系统统一走的企业微信扫码认证,我们基于Grafana的一个小功能Auth Proxy实现了企业微信认证。简单来说,当开启了Auth Proxy,访问Grafana的请求如果携带了Header用户名,Grafana就认为是对应用户访问了系统。
对于转转,当用户访问grafana.xxx.com时,Nginx会做拦截跳转企业微信扫码认证,认证之后由Nginx种入对应Header访问Grafana。
有些同学看到这里可能会担心会不会有安全问题,无需担心。
Header是由Nginx层种入,不会泄露到前端;
如果走域名访问,Nginx会做统一拦截认证;
如果走IP访问,我们封禁了非80端口的IP访问。
5.4 组件面板自动初始化
转转的架构中间件基于客户端做了各种埋点,包括不限于:JVM、线程池监控、数据库连接池、Codis、Web监控、日志监控、Docker监控等。
Grafana的Dashboard是一整个大JSON,我们只需提前定义好我们的模板,向Dashboard JSON内添加一行模板即可。
{
"panels": [
{
"title": "业务指标",
"panels": []
},
{
"title": "JVM",
"panels": []
},
{
"title": "日志监控",
"panels": []
}
]
}
5.5 自动建图
光有组件监控还不够,业务也有监控需求,但是PromQL与Grafana的复杂却让人望而却步。没关系,有问题找架构,架构给解决。我们会按照指标类型为业务自动在Grafana上创建出不同的面板。

Counter类型自动创建三张面板:
QPS 增量 区间增量:根据所选时间所计算的增量
Counter counter = Counter.build().name("upload_picture_count").help("上传图片数").register();

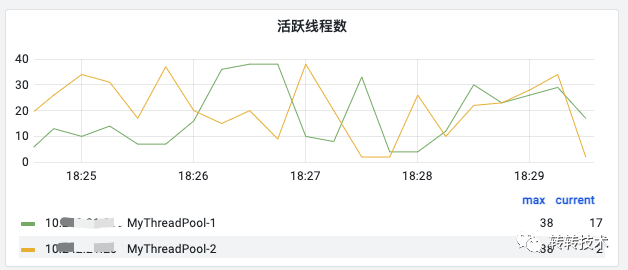
Gauge类型展示一张面板:
15秒上报一次的原始点
Gauge gauge = Gauge.build().name("active_thread_size").help("活跃线程数").labelNames("threadPoolName").register();
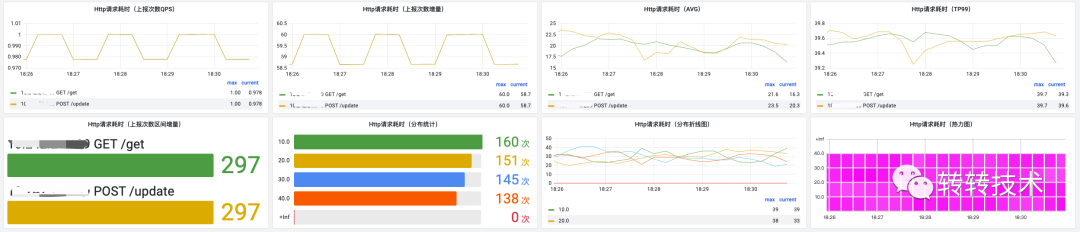
Histogram类型自动创建八张面板,分别为:
上报数据平均值 上报数据TP99 上报次数QPS:即调用Histogram observe函数的QPS 上报次数增量:即调用Histogram observe函数的增量 上报次数区间增量:即调用observe函数的所选时间的增量 分布统计:根据自定义桶与所选时间展示各个区间的上报次数 分布折线图:根据自定义桶展示各个区间的分布趋势图 分布热力图:根据自定义桶用颜色表示数据的分布区间
Histogram histogram = Histogram.build().name("http_request_cost").help("Http请求耗时").labelNames("method", "uri").buckets(10, 20, 30, 40).register();
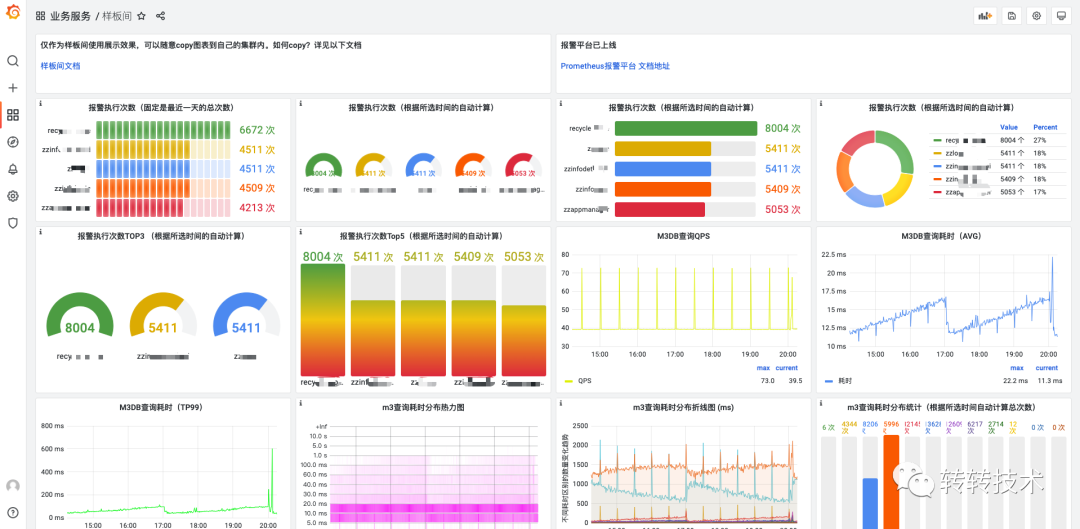
5.6 样板间
除此之外,我们还在Grafana上提供了一个样板间,样板间拥有着业务同学所需要的大部分面板,只需简单复制,按照提示做略微的修改即可做出同样的效果。
六、报警系统
6.1 背景
监控系统的另一个重要领域是报警系统,Grafana8.0之前的报警系统诟病较多,2021年6月,Grafana8.0之后推出了一个新报警系统ngalert。不过ngalert在我们实测过程中也不太理想,主要体现在以下几个问题:
业务自己写PromQL,学习成本较高 业务需要理解我们内置的指标的含义 发布时间短,我们实测8000个报警就会出现性能瓶颈
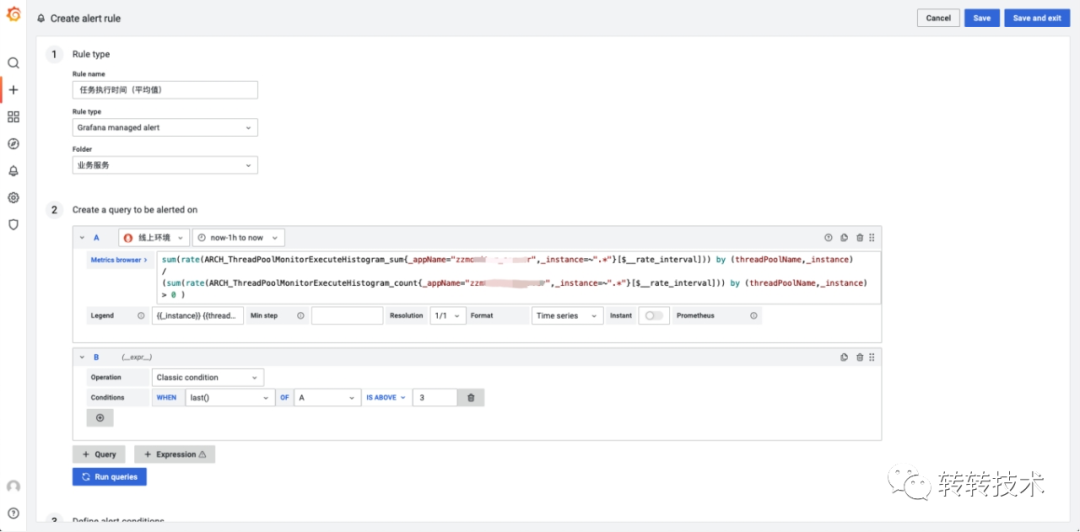
6.2 设计
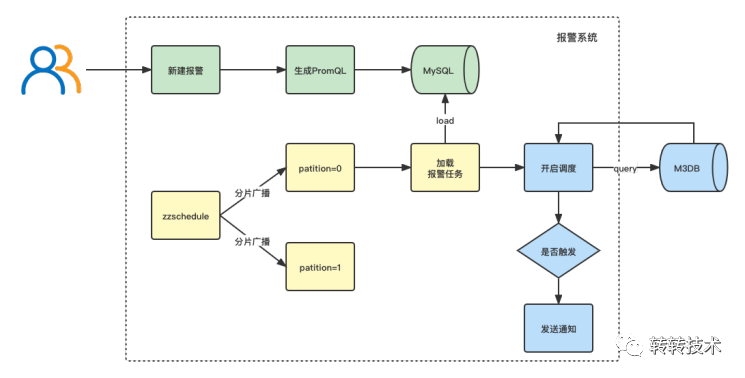
基于以上背景,我们决定自研报警系统。我们参考了夜莺的设计与源码,当用户新建报警后,我们会自动生成PromQL持久化到MySQL中,报警服务通过xxl-job的分片广播调度去加载任务,对于每个任务,报警服务直接查询M3DB判断是否触发报警。
6.3 效果
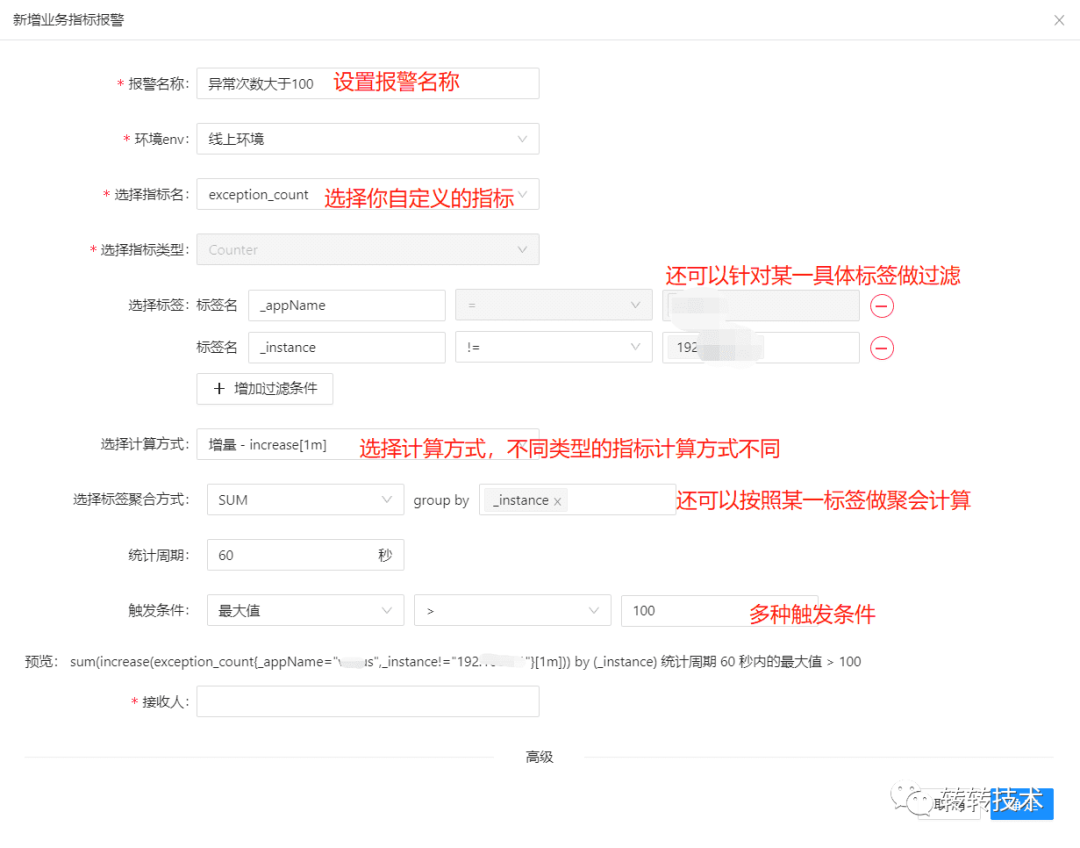
对于业务自定义的指标,只需要点点点就可以设置好报警,报警系统会自动生成对应的PromQL。
对于我们内置的中间件指标,只需填个阈值即可。
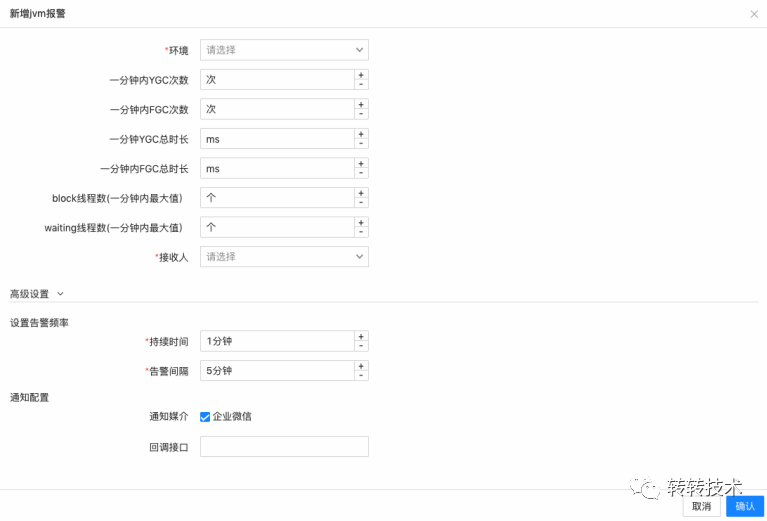
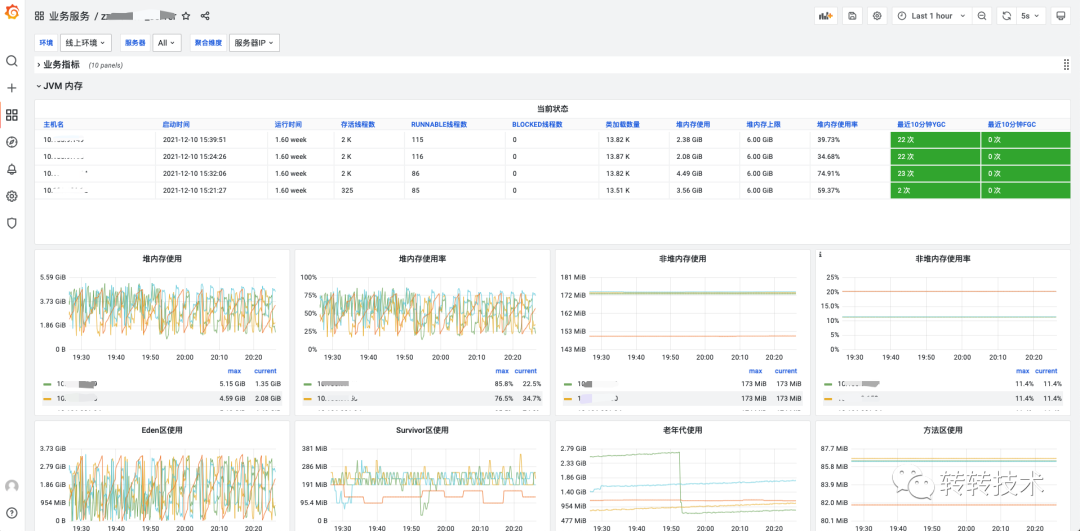
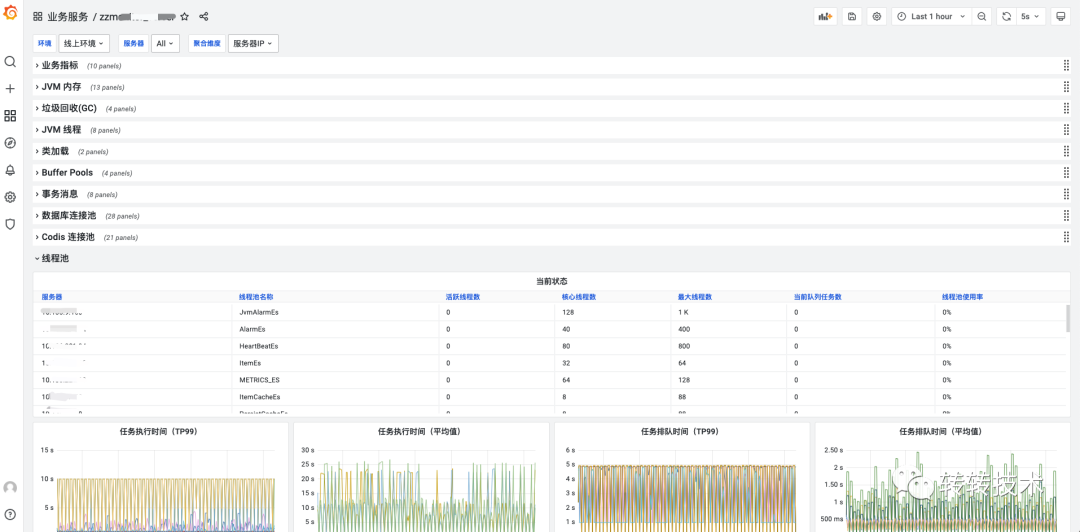
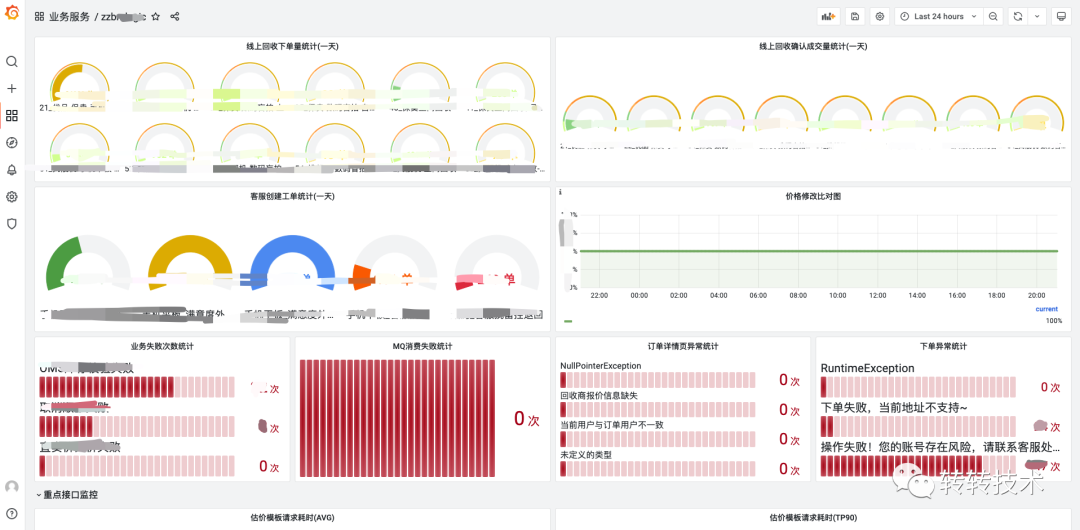
七、终效果
7.1 业务服务维度
以服务为维度,内置丰富的组件面板,提供All In One的视角。
7.2 架构组件维度
以转转的架构中间件为维度,监控各个服务的使用详情,如日志、Codis连接池、线程池等。

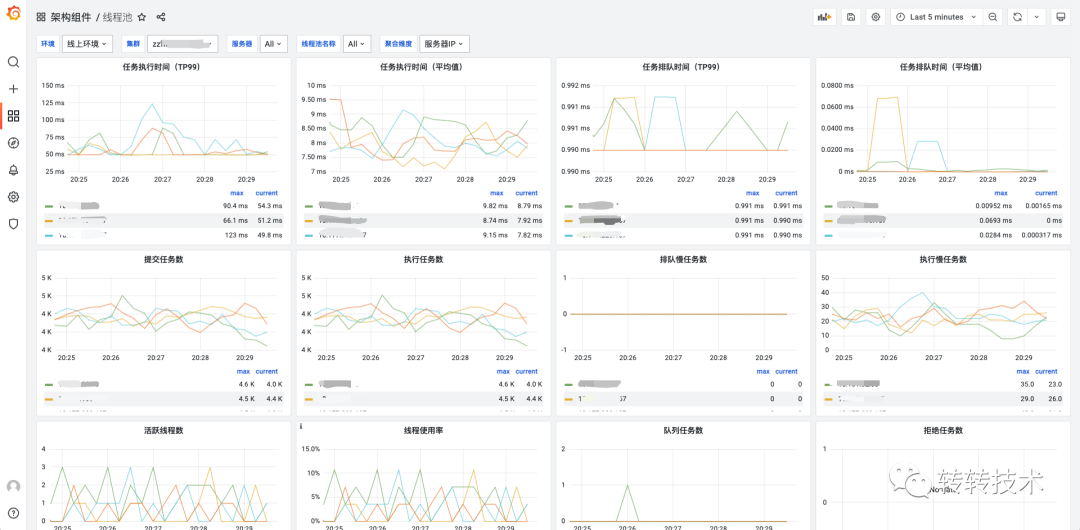
7.3 运维组件维度
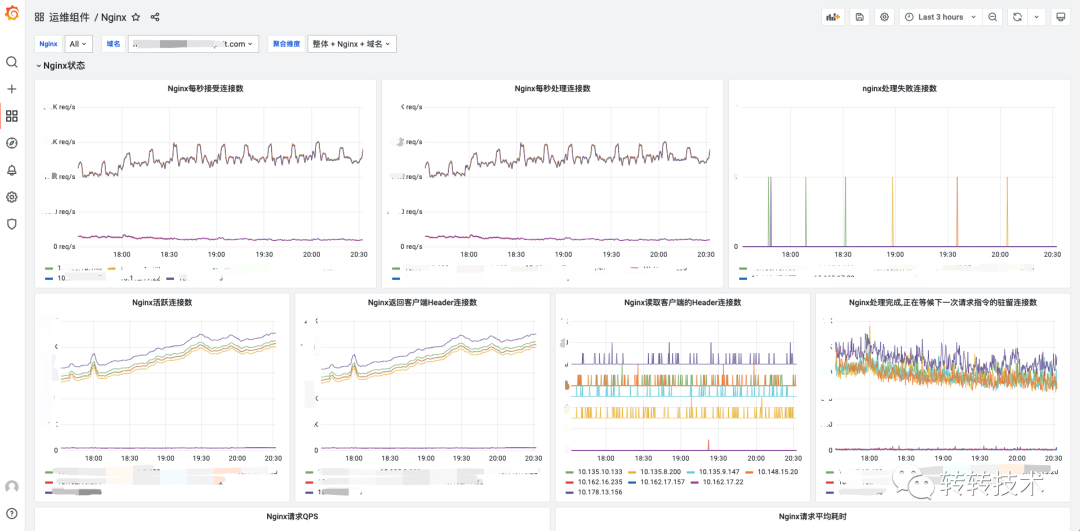
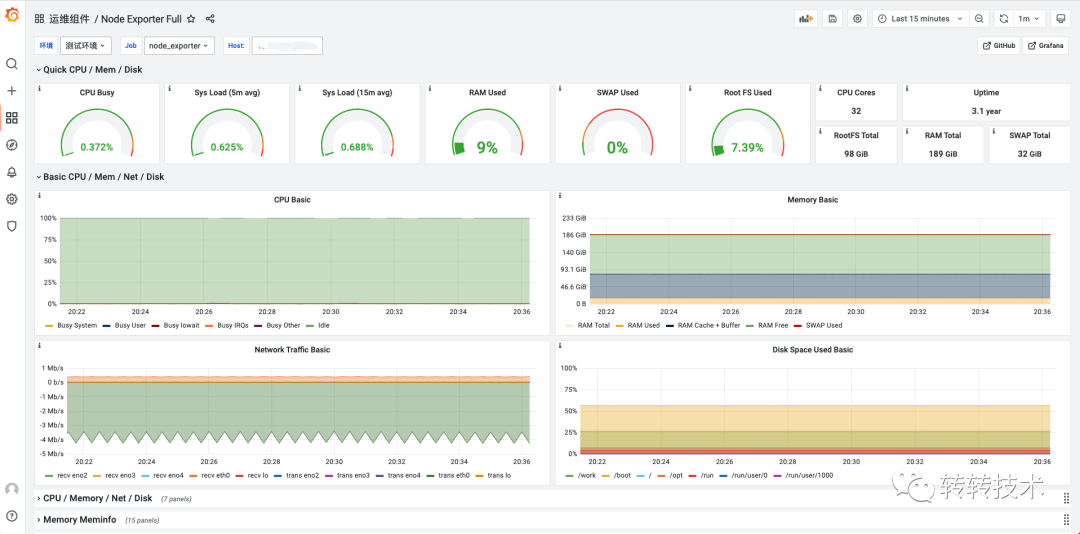
利用Prometheus丰富的Exporter监控运维资源的整体使用情况,如Nginx、机器、MySQL等。
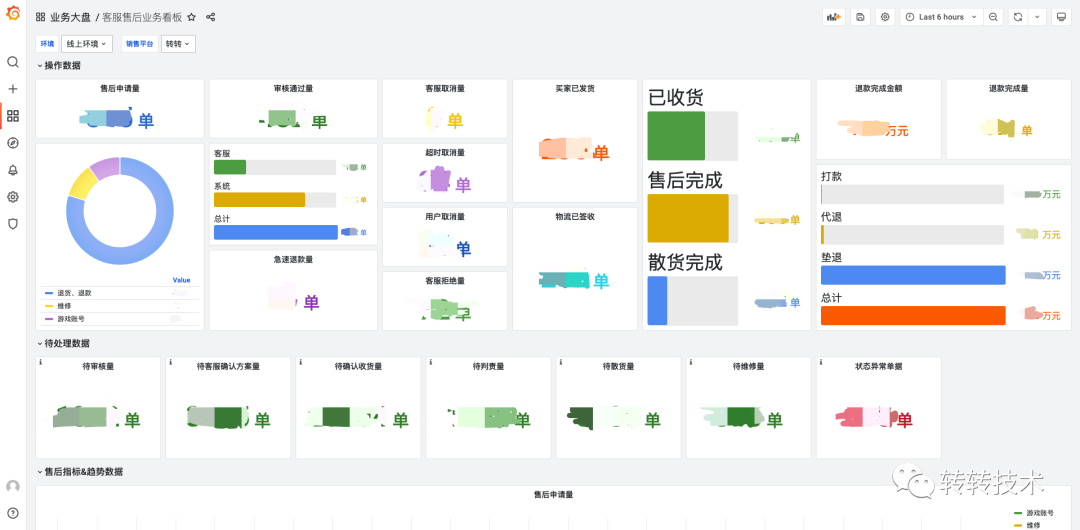
7.4 业务大盘
业务大盘提供一个全局的业务监控、分析视角。

八、总结
至此,我们通过借助开源社区的力量,并结合转转的业务场景做了简单二次扩展,落地了一套集业务服务、架构中间件、运维资源于一体的立体式监控平台,为全公司的各个业务提供一站式的监控报警服务。
这套监控系统在落地时核心扩展点主要围绕以下几块:
简化链路, Pull模型修改为Push+Pull模型自动建图、面板自动初始化 自研报警系统,可视化PromQL 打通转转内部信息系统,如服务信息系统、用户系统等
整体上来说,这套系统架构简洁、功能丰富、简单易用、维护成本低,还能借助开源社区的力量不断迭代。自上线三个月以来,各业务线积极接入,广受业务好评。
open source, open future.
作者简介
苑冲,转转架构部存储服务负责人,负责MQ、监控系统、KV存储、时序数据库、Redis Cluster等基础组件,主导转转MQ流量路由、新监控系统的落地。热爱思考,热爱架构。
