首先来简述一下Presto的发展起源,Presto其实是由FaceBook开源的一个MPP计算引擎,主要用来以解决 Facebook 海量 Hadoop 数据仓库的低延迟交互分析问题,Facebook版本的Presto更多的是以解决企业内部需求功能为主,也叫Presto DB,版本号以http://0.xxx来划分。后来,Presto其中的几个人出来创建了更通用的Presto分支,取名Presto SQL,版本号以xxx来划分,例如345版本,这个开源版本也是更为被大家通用的版本。前一段时间,为了更好的与Facebook的Presto进行区分,Presto SQL将名字改为Trino,除了名字改变了其他都没变。所以我们以后慢慢接受Trino这个引擎吧~(后面统一用Trino吧)
二、特点及原理
Trino这个查询引擎之前在大数据查询一章中讲到过,那时候还叫他Presto,这个查询引擎的特点正如文章标题描述的这样,多源、即席。多源就是它可以支持跨不同数据源的联邦查询,即席即实时计算,将要做的查询任务实时拉取到本地进行现场计算,然后返回计算结果。
那么Trino是如何支持这两个特点的呢,我们首先来看一下他的架构:
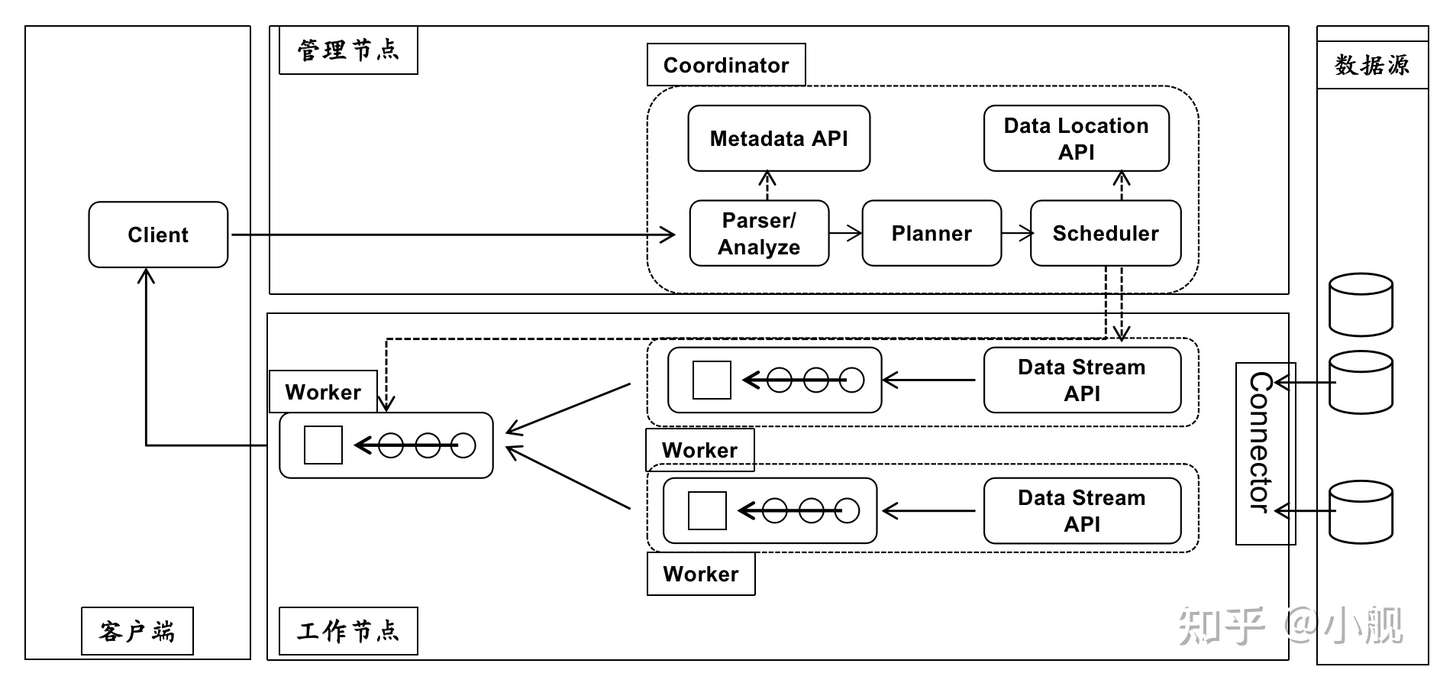
整个Trino主要是由Client、Coordinator、Worker以及Connector来构成。
Client就是来接受客户端查询请求的;Coordinator来对接受到的查询进行词法、语法分析,然后进行任务和资源的调度;接下来就是实际执行任务的Worker来做具体的工作了,例如去数据源拉取数据,然后进行计算;那Connector就是Worker去数据源拉取数据的连接器(适配器/管道)。
通过Trino的架构我们就可以看出来为什么Trino可以支持多源数据的查询了,因为引擎本身是通过Connector与数据源进行交互的,Trino提供了一套自定义数据源的统一接口,也就是说,无论我们想要连接什么数据源,我们只需要按照规范开发对应的数据源接口即可,其实开发起来也不是很麻烦,我前几节就带大家看了如何开发一个基于http协议的文本文件数据源Connector。
那么即席查询又是如何做到的呢,Trino是一个基于内存的MPP计算引擎,通过并行+内存的计算方式,可以大大提高计算速度,再加上一些优化(例如剪枝、谓词下推等),就可以达到大数据量计算任务下的秒级响应。
三、应用与意义
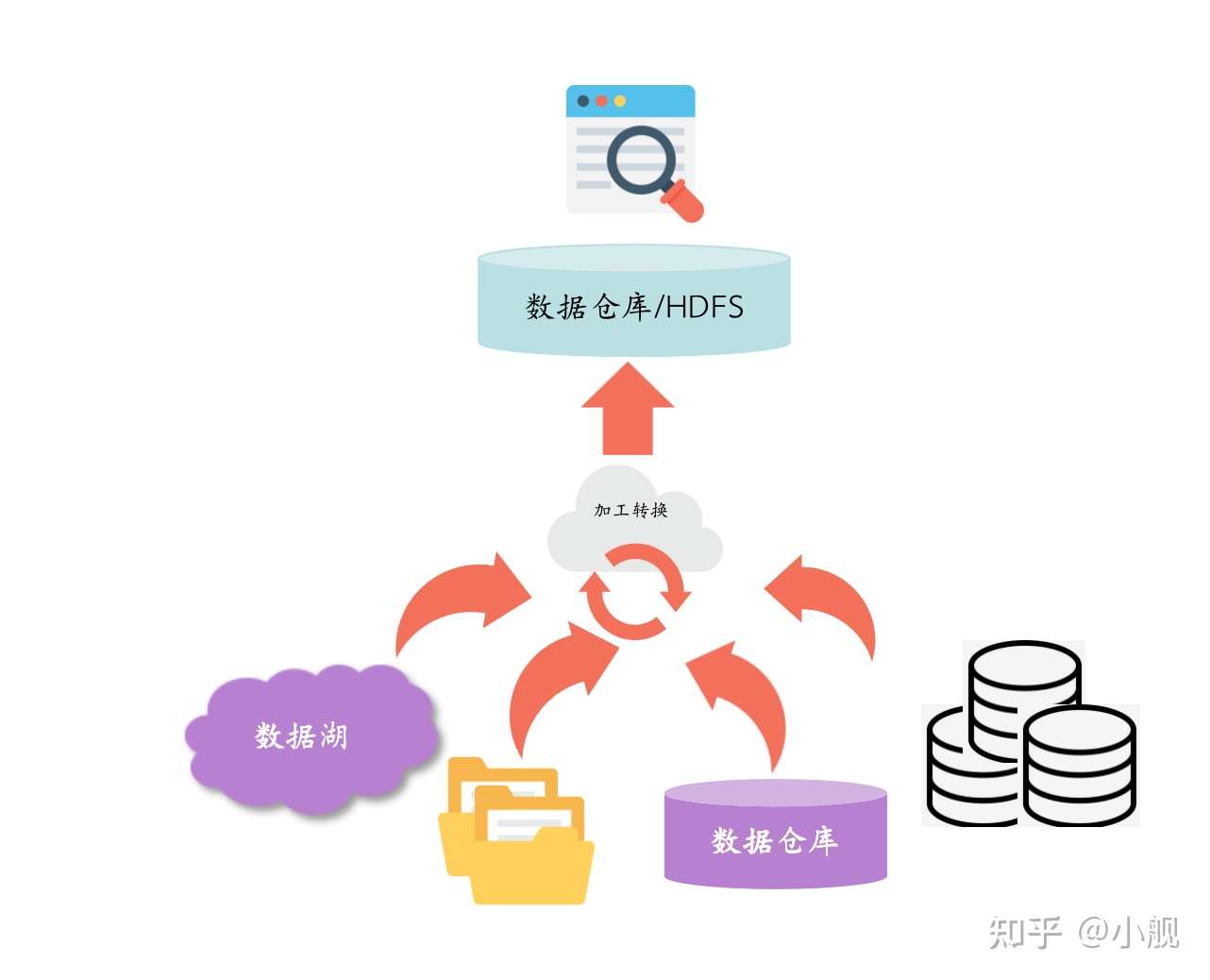
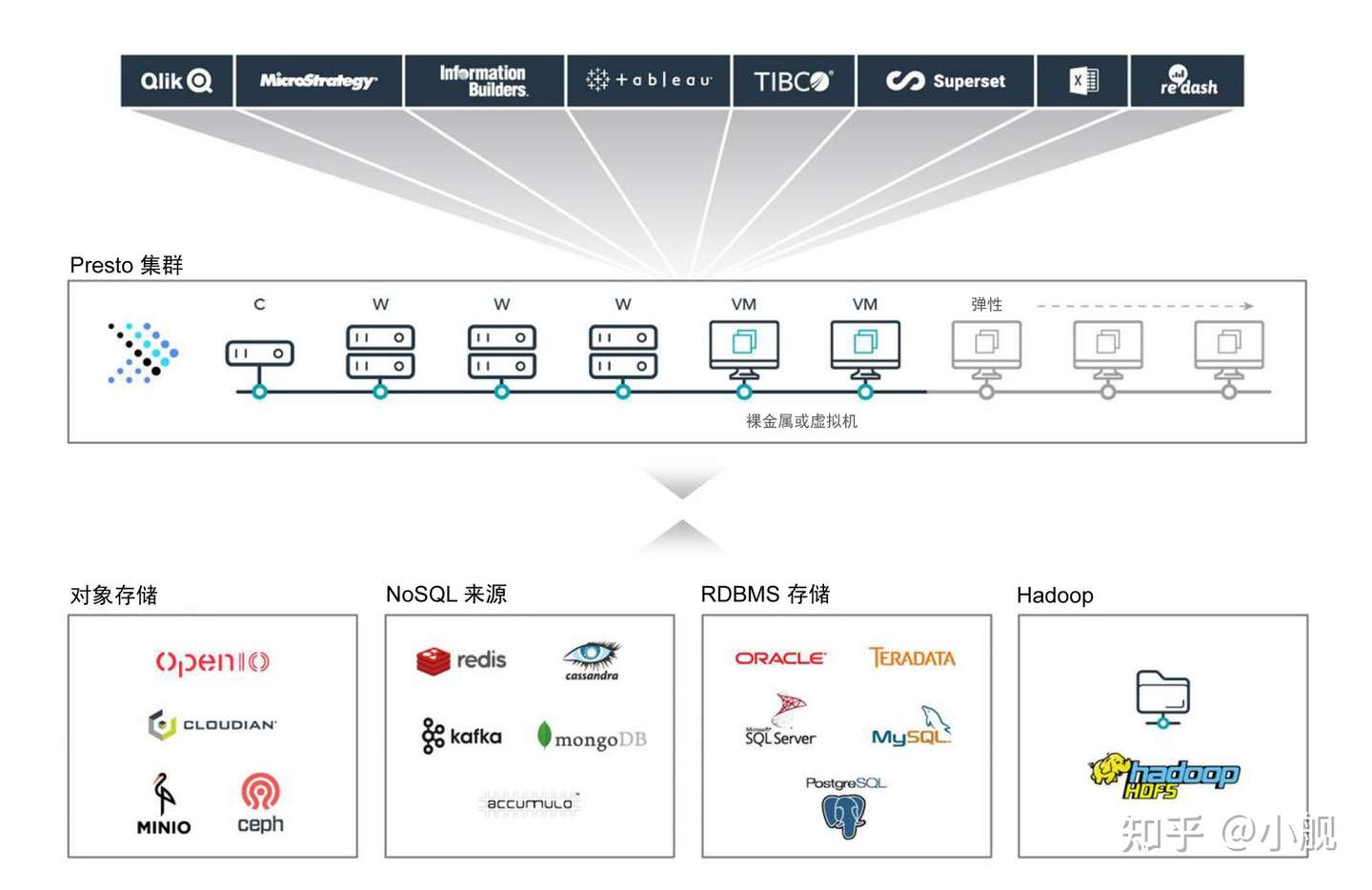
上图能够非常形象等展示出Trino这种多源数据即席查询引擎的优点:
(1)屏蔽底层数据源,提供统一的查询接口:通过统一的SQL查询,你可以查询结构化的数据库(例如Oracle、MySql等)、非结构化数据库(Neo4j、MongoDB)、Hive/HDFS、Kafka以及Terradata、GreemPlum等等;
(2)提高效率:一方面,基于内存计算,查询速度快是其一个特点;另一方面,由于它可以跨不同的数据源拉取数据并进行连接、聚合等操作,这也减少了数据搬家、数据迁移等步骤,从整个的计算逻辑上来看也是大大加快了;
(3)提高数据治理能力:在大数据时代,提高数据治理能力、发挥数据价值是重中之重,通过Trino可以很方便的进行异构数据的提取、整合与分析,对于打破数据孤岛、提高数据治理能力至关重要。
四、总结
以上是对Trino计算引擎进行了特点的剖析与安利,后面我会从部署到应用再到深入理解内部机制为大家来继续分享~
来自:https://zhuanlan.zhihu.com/p/352710120
