数仓建设离不开数据模型,数据分析师通过数据模型分析归纳各类数据,模型中离不开各种数据表,表代表不同维度数据,从而表/数据之间有上下游依赖关系,数据的产出是由任务计算得出,分为周期性或实时产出,所以数据之间的依赖等价于计算任务的依赖。数据平台的调度系统作用为根据任务配置,包括调度时间与依赖的上游任务,进行调度任务,即等待到达调度时间且上游任务完成,才提交运行下游任务。
调度系统的核心服务业务是数据开发,数据开发的开发模型为项目(Project),项目中可以创建多个任务(Job),项目由多个任务组成,计算分析一张表或多张表的任务DAG。基于项目模型,整体链路依赖模型为项目依赖,不支持跨项目的任务依赖,依赖模型不够准确,影响数据产出链路准确性以及实效。
数据开发为周期调度的离线批处理任务,而数据产出还有流任务实时产出,或者非数据平台产出。离线批任务均在数据开发,由调度系统判断依赖与提交执行,而实时任务或非数据平台的计算任务依赖需要打通,来避免任务空跑。
数据本身具有时间属性,比如4点小时计算得出上一个小时3点数据,明天计算得出今天的数据,周月类似,可以看出数据产出分为小时、天、周、月。回到依赖上,3点的小时数据可以依赖上游表3点数据,1号的天数据可以依赖1号0~23点小时数据做汇总,或者1号的天数据可以依赖1号23点小时数据取新,这么看来上下游依赖不是简单的一条边,而是在边上还有属性,来准确灵活描述具体怎么依赖上游。
二、名词解释
为方便大家理解,对于涉及的名词先进行解释
| 名词 |
英文 |
说明 |
| 任务 |
job |
任务开发和执行的小管理单元,一个任务包括可执行代码(或jar包)、执行参数、血缘配置和调度依赖 |
| 依赖 |
DAG |
任务之间有数据依赖,从而形成的任务依赖,多个任务依赖组成运行的上下游链路或DAG图,表示数据的生产关系 |
| 自依赖 |
-- |
后一个周期的数据依赖前一个周期的数据 |
| 项目 |
project |
调度开发的一种管理方式,为一组任务的画布 |
| 实例 |
instance |
任务每次执行产生的一次执行记录。包括该次执行的相关信息 |
| 业务时间 |
bizDate | 实例属性,即数据时间,任务计算产出表的分区时间 |
| 触发时间 |
-- |
实例属性,任务被定时执行的触发时刻 |
| T-1 |
-- |
触发时间与业务时间相差一个周期,以此类推T-2,即相差2个周期 |
| 偏移 |
offset | T-1,其中的"-1"为偏移量,形容业务时间和触发时间的偏差或依赖数据的偏差 |
三、依赖模型升级
1.项目依赖到任务依赖
由项目依赖过度到任务依赖难题:依赖为调度核心、依赖模型改造如何过渡、内外统筹,因此引入项目起始节点(root node)、结尾节点(end node),起始节点表示该项目的起点,实际用户创建的任务均依赖起始节点,表示项目开始,结尾节点表示该项目的终点,实际用户创建的任务均被结尾节点依赖,然后将项目间等价转换为root 和 end 节点,即项目依赖模型改造为任务依赖模型,终0风险将历史项目依赖切换为任务依赖、依赖模型改为任务依赖。由项目依赖切换为任务依赖个别链路提效4小时。
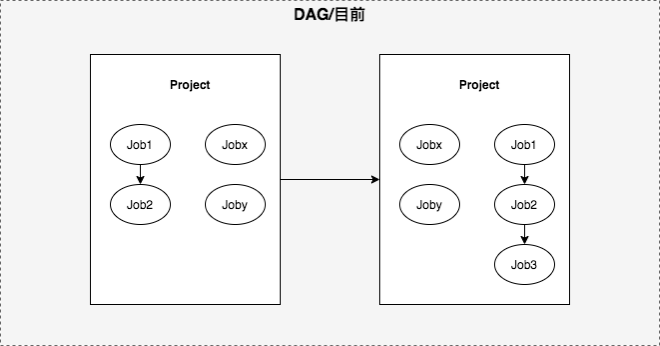


2.打通外部依赖
目标:提供一种通用方案,各个系统均可接入,且不增加用户开发效率。
方案1:表分区打通依赖,即当上游表小时或天分区数据ready后,下游调起执行
优点:
通过某种表分区ready约定,由调度系统适配,实现成本低
缺点:
当表有业务分区时,会扩大依赖范围,即必须等待所有业务分区都写入ok下游才调度执行,这样依赖放大不够准确
表分区ready的标志为表分区创建事件或hdfs有succss文件,前者和实时数仓查询有冲突,后者需要下游轮询hdfs文件,有性能瓶颈,且当有业务分区时,依然不能准确依赖,且考虑其他数据源不够通用
没有完整任务依赖DAG,和数据开发任务依赖不统一,有用户解释成本
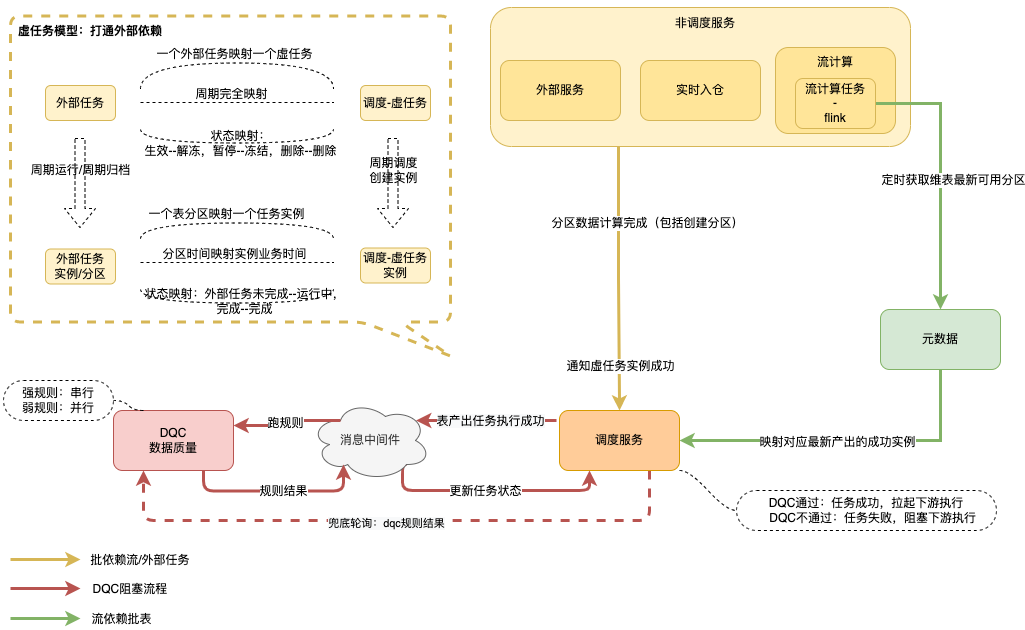
方案2:虚任务打通外部依赖,即虚任务逻辑上表示某份数据,且有产出周期,比如一张小时表,虚任务实例表示某个时间的数据,比如3点小时数据,由下游依赖虚任务等价依赖上游实际任务
优点:
可细化到业务分区或任意粒度,准确依赖
依赖统一为任务依赖,无外部依赖性能瓶颈、场景局限性
通过虚任务可以构建出准确的任务DAG
缺点:
虚任务有维护成本,归属各外部服务
基于上述分析我们选择虚任务打通外部依赖,细节如下图所示,并复用调度串联质量DQC服务,外部上游任务产出数据质量也自动得到保障。
3.依赖偏移
业务时间偏移:任务实际产出的数据时间相对调度时间相差周期数,如今天产出昨天数据为T-1,今天产出前天数据为T-2
依赖偏移:用于描述下游具体依赖上游任务的哪个或哪些业务时间,是下游任务的调度配置属性,举例如下:
| 依赖场景(以下时间均为业务/数据时间) |
下游依赖偏移配置 |
| 2号天下游依赖2号天上游 | 集合,0 |
| 2号天下游依赖1号天上游 | 集合,-1 |
| 2号天下游依赖2号小时上游 | 区间,0-23 |
| 某周周下游依赖当周天上游 |
集合,0,1,2,3,4,5,6 或 区间,0-6 |

四、技术实现
B站目前有任务数8W,每天运行实例15W,任务依赖关系边12W,依赖实现的关键目标:
实效性:高峰5W下游,16W边,依赖判断时延要低、调度吞吐高
准确性:依赖无误、定时调度和回刷/回补数据依赖独立
1.抽象依赖模型
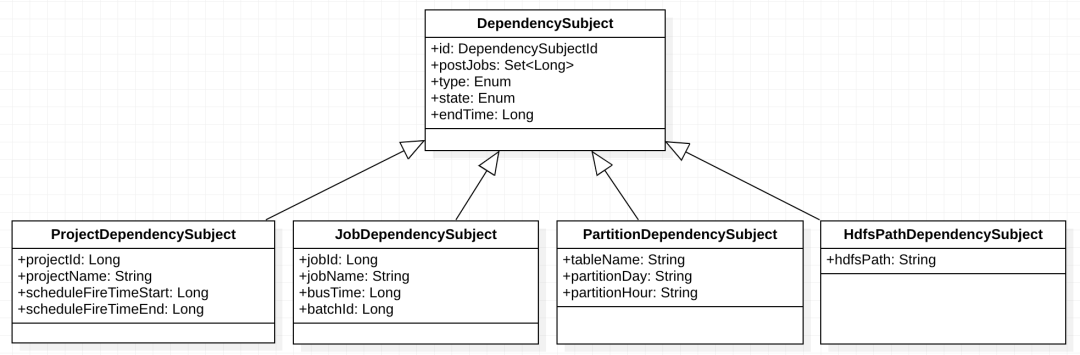
有项目、job依赖、表数据依赖(ods层数据系统默认有分区兜底检测)共存,而且分为定时、手动回刷场景,通过抽象依赖模型,来灵活适配各种依赖并且可持续迭代,定义DependencySubject对象,该对象表示某种上游依赖,ID通过DependencySubjectId表示,DependencySubjectId由多个条件表示,比如 1月1号数据的上游表示为“任务id=1234&&业务时间=20220101”、1月1号至5号数据的上游表示为“任务id=1234&&业务时间>=20220101&&业务时间<=20220105”、某张上游表分区表示为“表名=ods.tt_a&&day=20220101”,非常灵活可拓展。模型如下:
2.依赖异步回调
调度中核心组件:依赖中心DependencyCenter,主要功能计算依赖、依赖巡检、依赖监听回调。功能图如下:任务定时触发或手动回补到达依赖提交组件(该组件负责任务依赖判断与提交),依赖提交组件询问DependencyCenter上游依赖是否OK,若依赖的上游任务执行完成,则依赖提交组件提交到下一组件,反之任务实例停留在该组件。由DependencyCenter监听上游完成后,判断依赖该上游的下游是否所有依赖都已完成,若都已完成则回调依赖提交组件提交任务,反之继续监听其他未完成上游不进行回调。监听功能由每种依赖检测器完成,每种DependencySubject依赖对象对应一个依赖检测器,依赖检测方式支持巡检、消息订阅、接口调用。

3.依赖异步回调
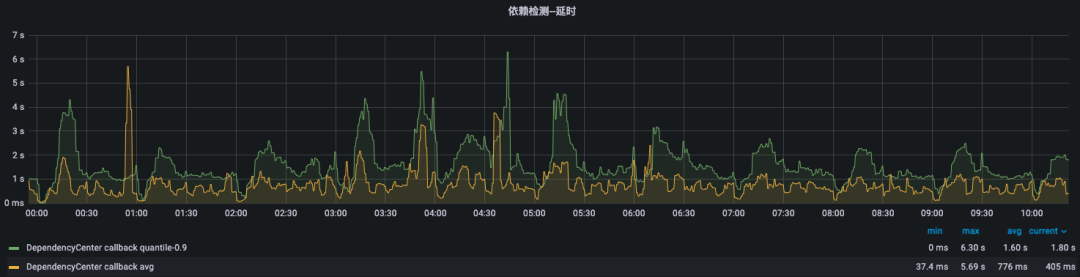
依赖模块性能,准确率,依赖时延(上游任务状态成功到通知下游任务收到上游成功时差)平均秒级别,90线平均1.6秒,大6.3秒,稳定运行3年
五、未来规划
1.依赖自动化
目前的数据依赖实际是通过任务进行串联的,包括流、批之间的依赖,当用户调整模型时,比如产出表调整,需要同步调整任务依赖,降低一定开发效率,如果没有变更造成空跑、下游延时严重问题。当我们任务数据血缘解析准确时,或者大部分准确时,可以大面积使用“自动依赖”,而任务依赖作为补充,解决“自动依赖”解决不了的很少部分场景。
2.依赖规则丰富
目前依赖规则支持偏移,且都是强依赖(上游们必须都完成),某些场景下需要弱依赖,使用场景不多,但是很有用,具体分为:
等待到某个时间点,如果上游失败或还未执行完成,下游不再等待开始执行,常见特征应用场景;
同一个上游任务,只要配置区间中 新的一个 或 其中任意一个 任务实例,下游开始执行,常见上游表每小时全量更新;
3.依赖周边支持
依赖规则的丰富,会给运维工具、基线带来很大挑战。
当进行链路修数时,运维工具需要从root节点+root节点的修数时间,根据依赖规则先计算层的修数时间,然后再根据层的修数时间与第二层的依赖规则计算第二层的修数时间,后续依次......,层数越多,计算复杂度越高,性能为瓶颈。
基线的出发点为保障任务,复杂的依赖规则对于基线应该是黑盒,但是又要考虑基线预测的准确性,是个待解决问题。
