索引几乎是当今每个数据库的核心功能,因此FaunaDB也拥有索引也就不足为奇了。 FaunaDB是一个云托管的分布式多模型数据库,非常适合Web和移动应用程序。
FaunaDB提供对GraphQL的本机支持,但也提供了自己的,功能更强大的查询语言FQL,我们将在这里的索引示例中使用它。
[ 也在InfoWorld上:为什么Oracle乐于输给AWS和MongoDB?
索引有多个用例。 明显的是在大量记录集中定位特定数据时的性能提高,但是索引也提供了分页,排序和搜索。
每当我们想要满足针对一个或多个文档的某些数据要求,而又不知道它们的refs(标识数据库中文档的全局引用)时,索引就是必经之路。
在本文中,我们将学习可以用索引解决的五个常见用例。 每个用例都有一个代码示例和说明。
- 排序文件
- 从索引返回特定字段(以避免获取完整的文档)
- 搜索文件
- 用另一个结果过滤一个集合
- 强制字段组合
因此,让我们开始吧! 登录到https://dashboard.fauna.com/ ,创建一个新数据库,然后使用命令行管理程序。
[ 通过InfoWorld的App Dev Report新闻通讯了解软件开发中的热门话题 ]
创建一个收藏
索引对集合起作用,因此在深入研究示例之前,我们需要先在FaunaDB中建立一些集合。
这是此的FQL:
CreateCollection({ name: "customers" });Map( [ { name: "Ali", purchase: "pan", otherInfo: "other data" }, { name: "Tina", purchase: "bowl", otherInfo: "other data" }, { name: "Frank", purchase: "bowl", otherInfo: "other data" } ], Lambda("customer", Create(Collection("customers"), { data: Var("customer") }) ));CreateCollection({ name: "products" });Map( [ { name: "pan", price: 500 }, { name: "bowl", price: 100 }, { name: "cup", price: 50 } ], Lambda("product", Create(Collection("products"), { data: Var("product") }) ));
我们使用一个客户集合,其中包含三个文档,而这些文档又包含三个字段; 名称,购买和其他信息。
我们还使用包含产品名称和价格的产品集合。
[ 也在InfoWorld上:10个软件开发崇拜者加入 ]
使用索引对文档进行排序
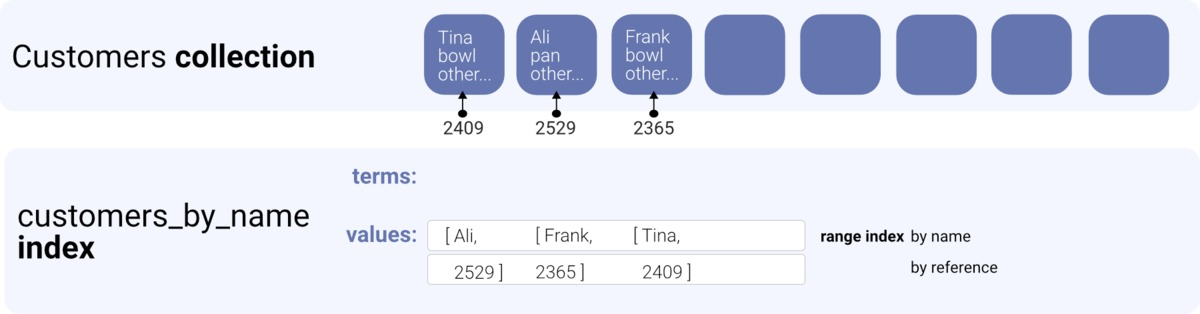
索引的个也是直接的用例是排序。 即使是在我们在控制台中创建集合时自动创建的集合索引 ,也会按其引用进行排序。
 动物群
动物群大多数时候,我们想检索以某种顺序排序的数据。 例如,我们有一个带有名称的客户,我们想按字母顺序对它们进行排序。
可以使用一组值来创建索引。 这些是文档数据中用于排序的字段,只要我们创建或更新文档,索引就会更新。 我们必须为要对文档进行排序的每种不同方式创建索引,例如名称升序,名称降序,购买升序或购买降序。
FaunaDB索引的优点在于, 可以随时创建索引。 这意味着我们不必想一开始就想对数据进行排序的所有可能方式。
让我们看一下创建索引的FQL代码示例:
CreateIndex({ name: "customers_by_name_asc", source: Collection("customers"), values: [ { field: ["data", "name"] }, { field: ["ref"] } ]});
然后,我们可以使用以下方式以排序的方式检索文档:
Map( Paginate(Match(Index("customers_by_name_asc"))), Lambda(["name", "ref"], Get(Var("ref"))));
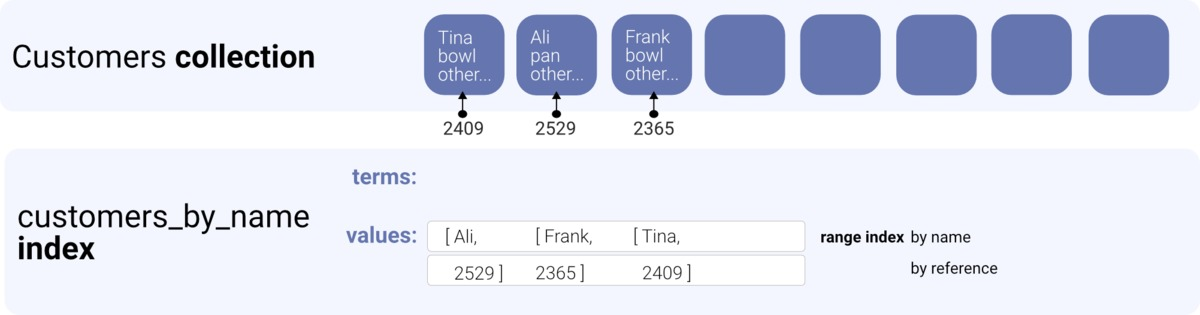
首先,我们为集合创建索引。 它包含两个值,即我们根据其排序的名称,以及稍后用于从客户集合中检索实际文档的引用。
 动物群
动物群其次,我们将页面从索引传递到Map函数。
 动物群
动物群由于索引为值指定了两个字段,因此索引中的每个条目都包含一个values数组; 项是我们客户的名字; 第二项是参考。
我们使用ref并将其传递给Get函数。 因为ref全局地标识了我们数据库中的文档,所以Get返回我们要获取的文档。
 动物群
动物群在这里,我们使用Map函数遍历客户文档的引用,并使用Get检索实际文档。 由于索引是按其值排序的,首先是按名称排序,然后按ref排序,因此将以相同的顺序检索文档。
[ 同样在InfoWorld上:什么是CI / CD? 持续集成和持续交付的解释 ]
使用索引返回特定字段
这里的目标是减少响应,因为快的字节是未发送的字节! 通过从索引返回特定字段,我们可以避免获取完整文档。
我们通过创建一个包含我们感兴趣的值的索引来实现这一点。
通常,当我们要获取一些文档时,我们将首先查询索引以检索引用,然后使用这些引用从集合中获取文档(使用Map和Get)。
因为Fauna索引就像视图,所以我们可以创建一个单独的索引,将所有感兴趣的字段值都保存为值,以便我们可以直接使用这些值,而不必自己获取文档。
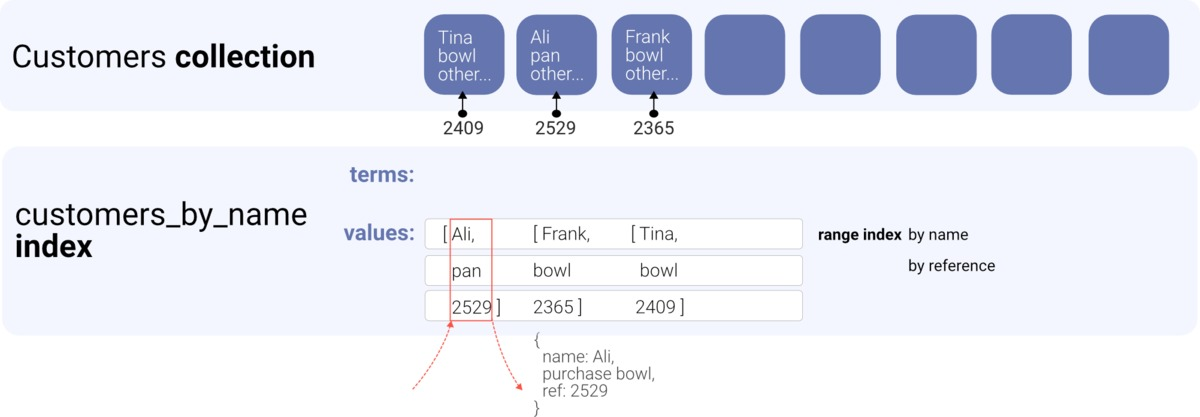
CreateIndex({ name: "customers_name_purchase", source: Collection("customers2"), values: [ { field: ["data", "name"] }, { field: ["data", "purchase"] }, { field: ["ref"] } ]});
索引的名称customers_name_purchase告诉我们,它是customers集合的索引,其中个值是名称,第二个值是purchase。 要检索我们需要的数据,我们可以运行以下查询:
Paginate(Match(Index("customers_name_purchase")));
 动物群
动物群在前面的示例中,我们从索引中获取文档,然后需要使用Get从集合中检索文档。 这次,我们创建了一个包含三个值的索引:客户文档的名称,购买和引用。 当我们有一个只需要这些值的用例时,我们现在可以简单地获取页面。 由于索引已经包含我们需要的值,因此我们不再需要检索完整的文档。 结果看起来像这样:
{ data: [ ['Ali', 'pan', Ref(Collection("customers"), "246578504281358850")], ['Frank', 'bowl', Ref(Collection("customers"), "246578504281360898")], ['Tina', 'bowl', Ref(Collection("customers"), "246578504281359874")] ]}
使用索引搜索文档
下一个用例是搜索特定文档或过滤文档。 为此,我们必须创建一个索引,其中包含我们要使其可搜索为术语的字段。
在此示例中,将使用术语而不是值来创建索引。
CreateIndex({ name: "customers_search_by_name", source: Collection("customers"), terms: [ { field: ["data", "name"] } ]});
检索文档与个示例相似,但是这次我们提供了一个匹配的属性(在本例中为“ Tina”)。
Map( Paginate(Match(Index("customers_search_by_name"), "Tina")), Lambda("ref", Get(Var("ref"))));
创建索引时,条件字段用于搜索或过滤,而值字段用于排序或提供结果。
 动物群
动物群另外,使用Paginate(Match(Index(...())))读取索引时会检索值,但术语不是。
由于我们没有为索引提供值,因此索引仅包含引用。 因此,分页的结果将是引用数组而不是值数组。 这次,我们的Lambda仅具有一个参数,而不是直接传递到Get函数以检索文档的多个参数。
与前面的示例一样,如果我们需要加载特定客户的购买,则可以将购买字段添加到索引的值中,而不必再在集合上调用Get。
使用索引将一个集合与另一个集合的结果过滤
让我们看一个更复杂的例子。 我们有两个集合。 一个拥有我们所有产品,另一个拥有我们所有客户及其近购买的产品。 现在,我们只想检索客户后购买的产品。
这是构建所需索引的FQL:
CreateIndex({ name: "customer_purchases", source: Collection("customers"), values: [ { field: ["data", "purchase"] } ]});CreateIndex({ name: "product_names", source: Collection("products"), terms: [ { field: ["data", "name"] } ]});
以及根据近一次客户购买来检索产品的代码:
Map( Paginate(Distinct(Match(Index("customer_purchases")))), Lambda( "product_name", Get(Match(Index("product_names"), Var("product_name"))) ));
我们创建了两个索引。 个是带有值的索引,正如我们在前面的示例中看到的那样,带有值的索引已排序。 在这种情况下,个索引在来自客户集合的购买字段上排序。 第二个索引是基于产品集合的索引。 由于个索引是根据购买排序的,并且对结果进行了分页,因此我们可以使用该索引来获取包含近一次客户购买的页面,然后使用第二个索引来检索产品。
Distinct函数过滤掉所有重复项 ,因此我们终得到了一个产品名称数组,但是每个产品名称在返回的数组中仅出现一次。
使用Map函数,我们将每个产品的名称传递给Match函数,并使用其返回值ref从其集合中检索产品文档。
使用索引强制字段组合
本节中的示例是关于保持索引条目及其相关文档的。 创建索引时,我们可以使用参数,该参数仅允许一个具有特定值/术语组合的条目。
以下代码将创建一个集合和一个索引,要求名称,州和国家/地区的组合。
CreateCollection({ name: "cities" });CreateIndex({ name: "cities_unique", source: Collection("cities"), unique: true, values: [ { field: ["data", "name"] }, { field: ["data", "state"] }, { field: ["data", "country"] } ]});
我们创建的索引使用unique参数,因此当我们在citys集合中创建新文档时,添加到该索引的所有值都必须是的组合。
下面的Create调用返回一个带有其引用的新文档:
Create(Collection("cities"), { data: { name: "Mexico City", state: "Mexico City", country: "Mexico" }});
下一个创建 呼叫使用名称,州和国家/地区的新组合。
Create(Collection("cities"), { data: { name: "New York City", state: "New York", country: "USA" }});
请注意,如果我们尝试添加已经存在的组合,则Create调用将失败,并显示错误消息“ instance not unique”。
Create(Collection("cities"), { data: { name: "New York City", state: "New York", country: "USA" }});
与索引一起生活得更好
索引是使用FaunaDB完成工作的方式。 它们不仅是我们在查询未达到预期效果时提供的一些速度改进; 他们是整个企业的骨干! 索引使我们可以对文档进行分页,排序和过滤,甚至可以暴露对其构成的限制。 每当我们想要获取多个文档并且不知道其引用时,都需要使用它们。
Brecht De Rooms是Fauna的开发倡导者。 他是一名程序员,在创业和IT咨询领域都曾作为一名全职开发人员和研究员从事IT领域的广泛工作。 他的任务是阐明新兴和强大的技术,这些技术使开发人员更容易构建吸引用户的应用程序和服务。
-
新技术论坛提供了一个以前所未有的深度和广度探索和讨论新兴企业技术的场所。 选择是主观的,是基于我们对InfoWorld读者认为重要和感兴趣的技术的选择。 InfoWorld不接受发布的营销担保,并保留编辑所有贡献内容的权利。 将所有查询发送到newtechforum@infoworld.com 。
From: https://www.infoworld.com/article/3454398/5-common-problems-faunadb-indexes-solve-for-you.html
 动物群
动物群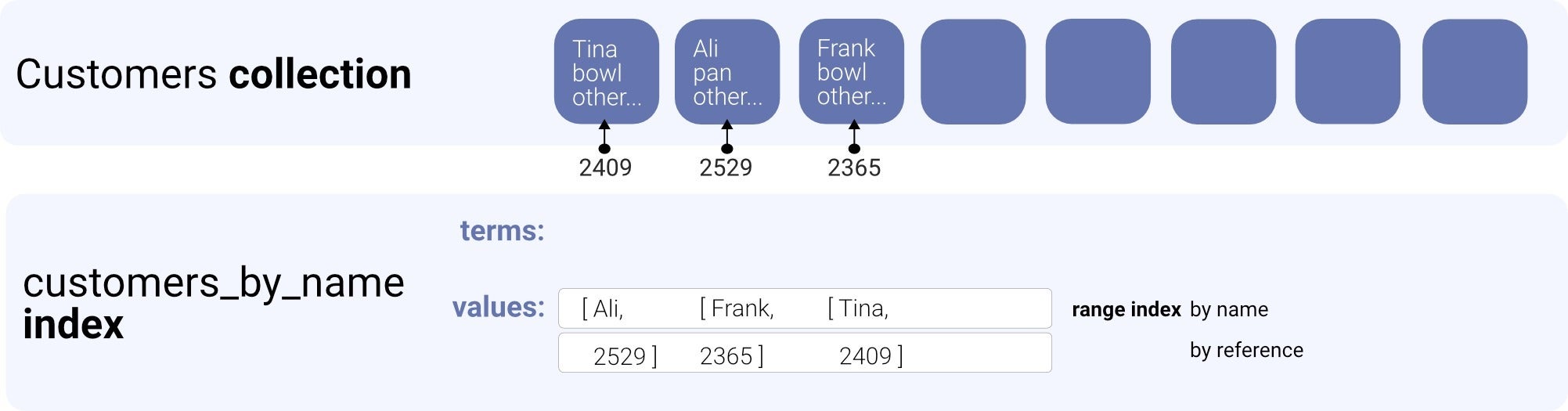 动物群
动物群 动物群
动物群 动物群
动物群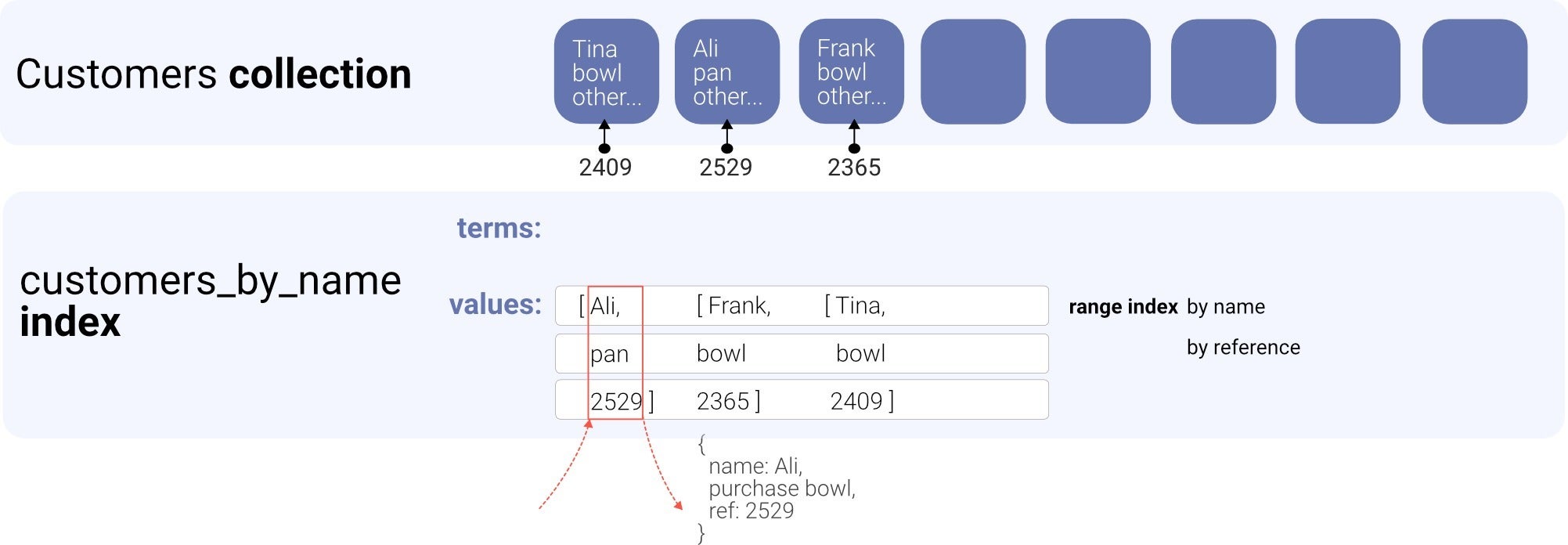 动物群
动物群 动物群
动物群