Kafka 是主流的消息流系统,其中的概念还是比较多的,下面通过图示的方式来梳理一下 Kafka 的核心概念,以便在我们的头脑中有一个清晰的认识。
01
基础


02
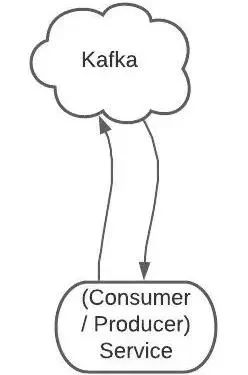
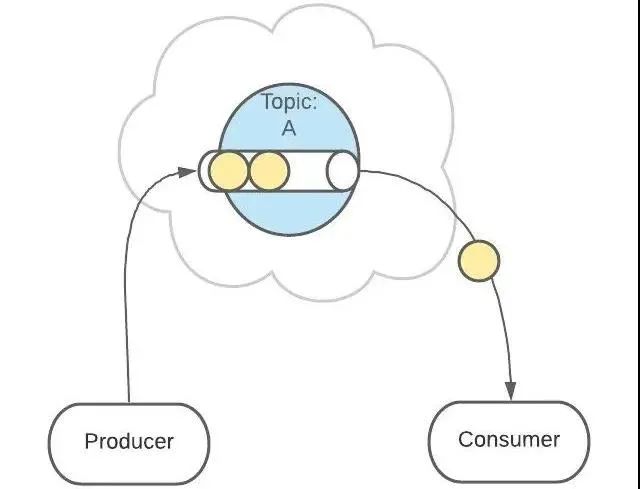
生产者消费者

一个服务可以同时为生产者和消费者。
03
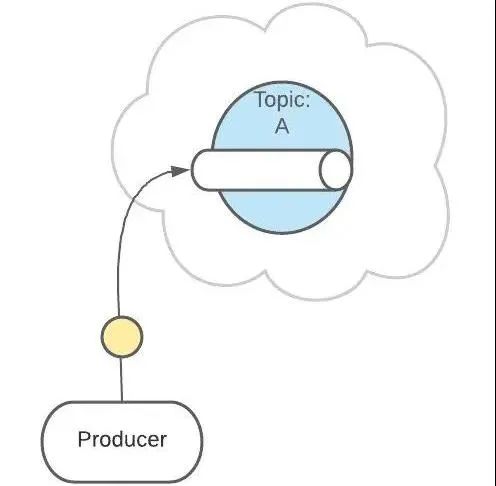
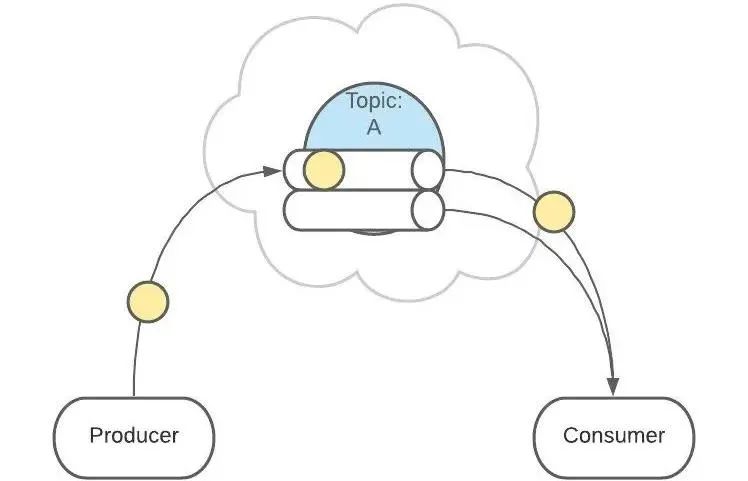
Topics 主题
Topic 是生产者发送消息的目标地址,是消费者的监听目标。
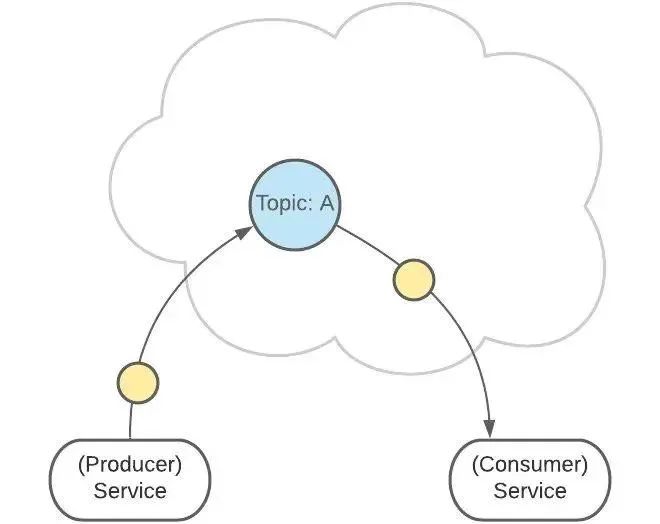
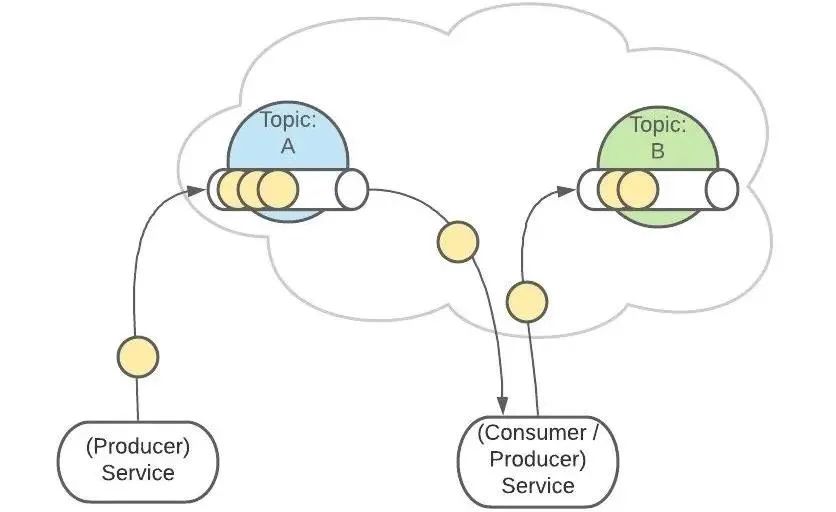
一个服务可以监听、发送多个 Topics。

Kafka 中有一个【consumer-group(消费者组)】的概念。
这是一组服务,扮演一个消费者。
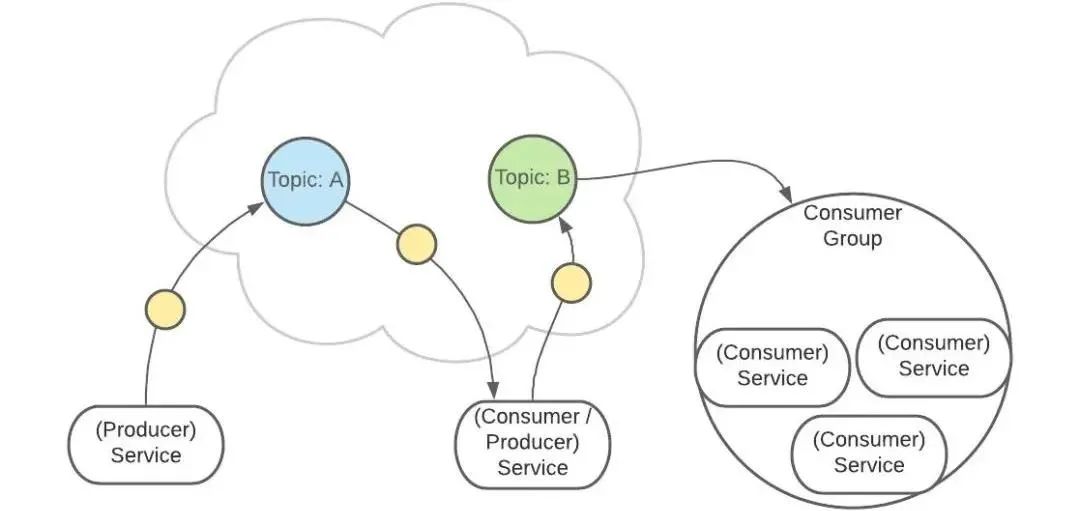
如果是消费者组接收消息,Kafka 会把一条消息路由到组中的某一个服务。
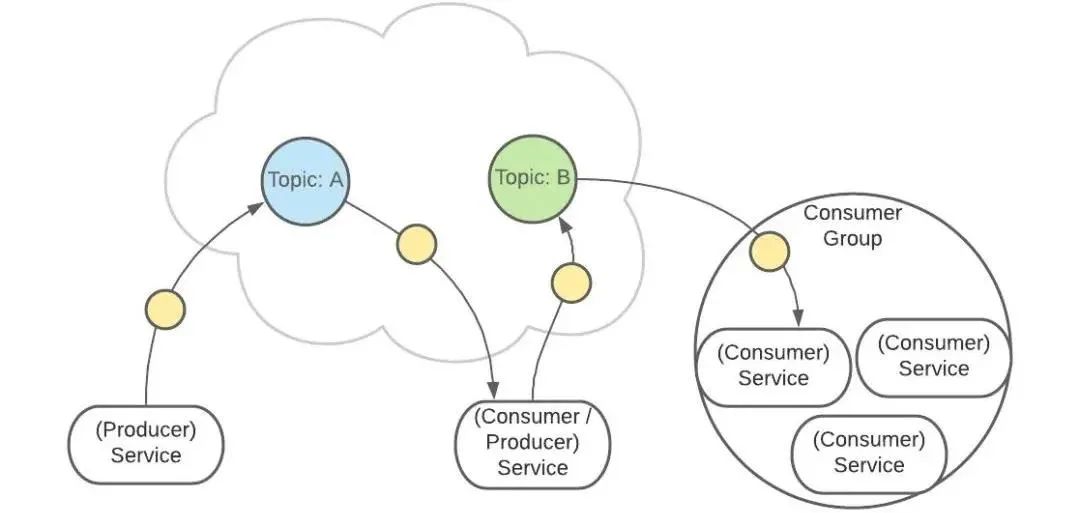
这样有助于消息的负载均衡,也方便扩展消费者。

接下来,消息会被发送给此 Topic 的消费者。


04
Partitions 分区
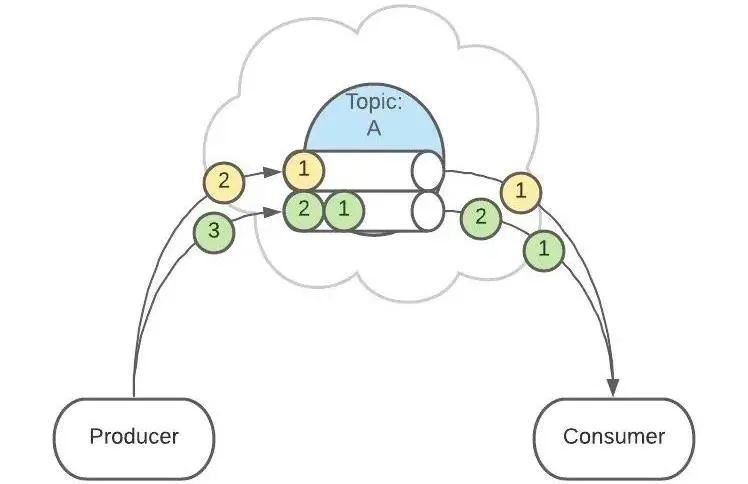
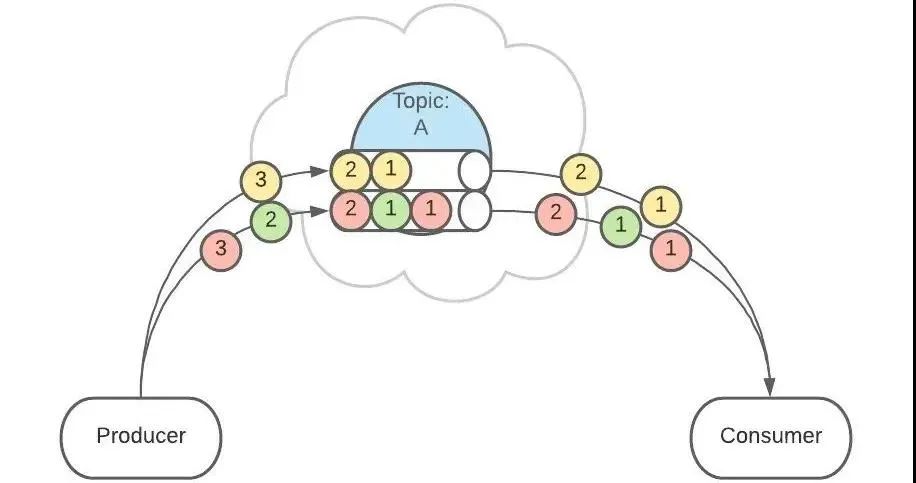
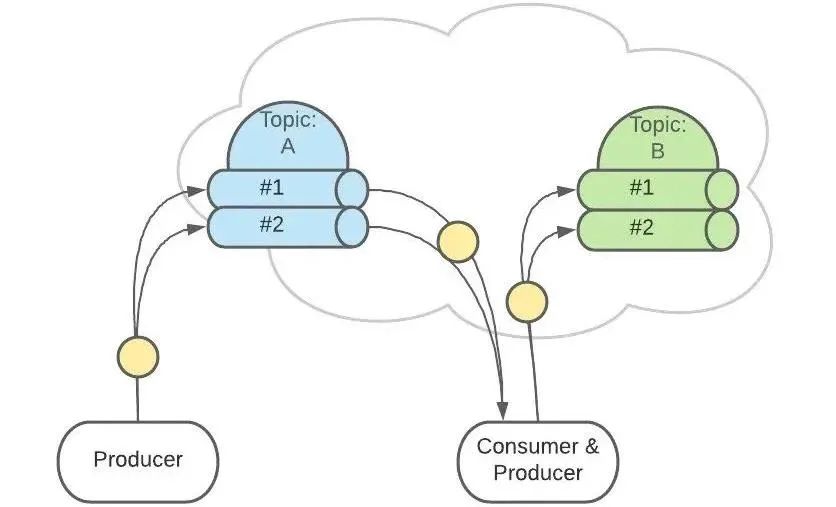
上面 Topic 的描述中,把 Topic 看做了一个队列,实际上,一个 Topic 是由多个队列组成的,被称为【Partition(分区)】。
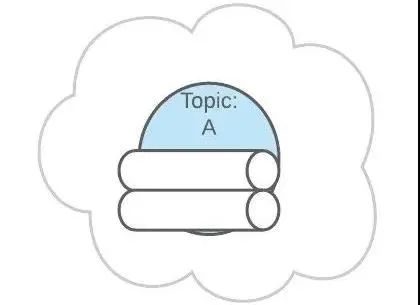


也可以配置 Topic,让同类型的消息都在同一个 Partition。
例如,处理用户消息,可以让某一个用户所有消息都在一个 Partition。
例如,用户 1 发送了 3 条消息:A、B、C,默认情况下,这 3 条消息是在不同的 Partition 中(如 P1、P2、P3)。

这个功能有什么用呢?这是为了提供消息的【有序性】。
05
架构
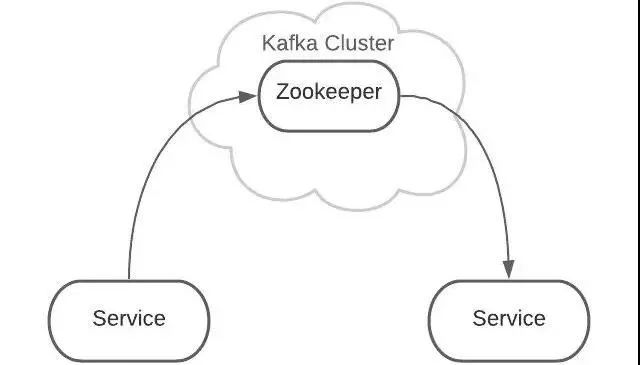
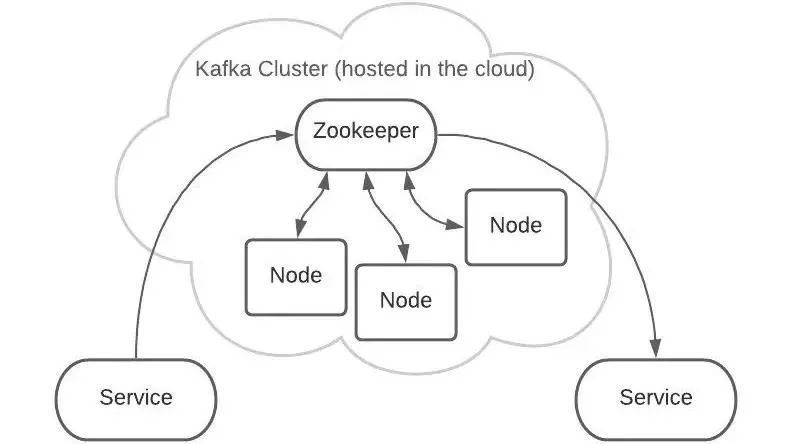
ZooKeeper 管理着所有的 Topic 和 Partition。
例如,有 2 个 Topic,各自有 2 个 Partition。

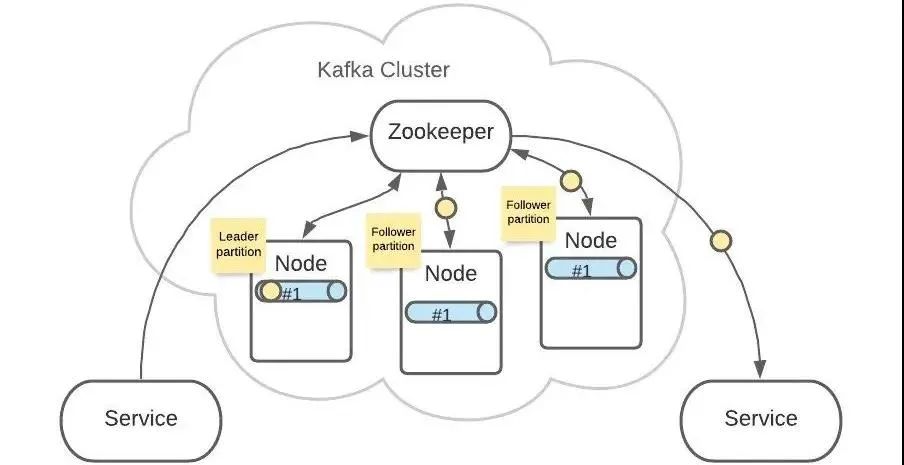
Topic A 的 Partition #1 有 3 份,分布在各个 Node 上。
这样可以增加 Kafka 的可靠性和系统弹性。

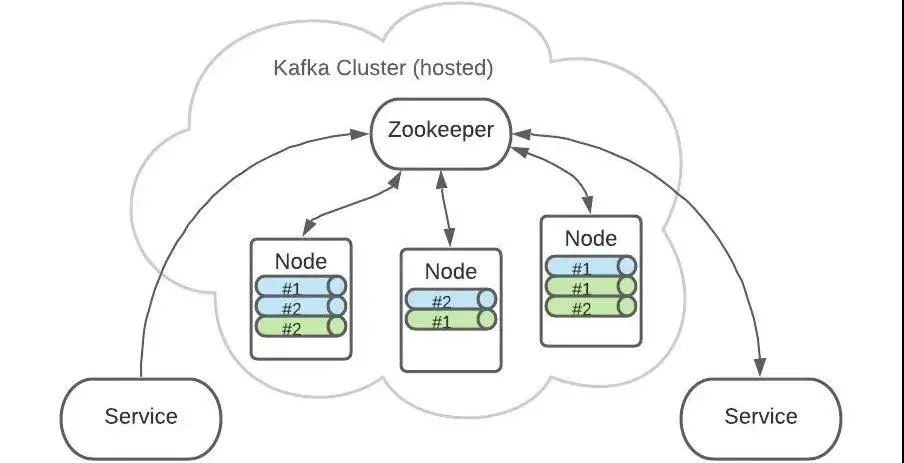
这样,每个 Partition 都含有了全量消息数据。

即使某个 Node 节点出现了故障,也不用担心消息的损坏。
感谢阅读,希望对你有所帮助!
编辑:陶家龙
出处:https://timothystepro.medium.com/visualizing-kafka-20bc384803e7
整理:51CTO
