作者简介
Roy,携程软件技术专家,负责MySQL双向同步DRC和数据库访问中间件DAL的开发演进,对分布式系统高可用设计、分布式存储,数据一致性领域感兴趣。
一、前言
在携程国际化战略背景下,海外业务将成为新的发力点,为了保证用户高品质的服务体验,底层数据势必需要就近服务业务应用。一套标准且普适的数据复制解决方案能够提升业务决策效率,助力业务更快地触达目标用户。
DRC (Data Replicate Center) 作为携程内部数据库上云标准解决方案,支撑了包括但不限于即时通讯、用户账号、IBU在内的核心基础服务和国际业务顺利上云。
二、业务上云场景
业务上云前,要先要思考2个问题:
数据库是否需要上云?
在数据库上云情况下,海外数据库提供只读还是读写操作?
2.1 应用上云
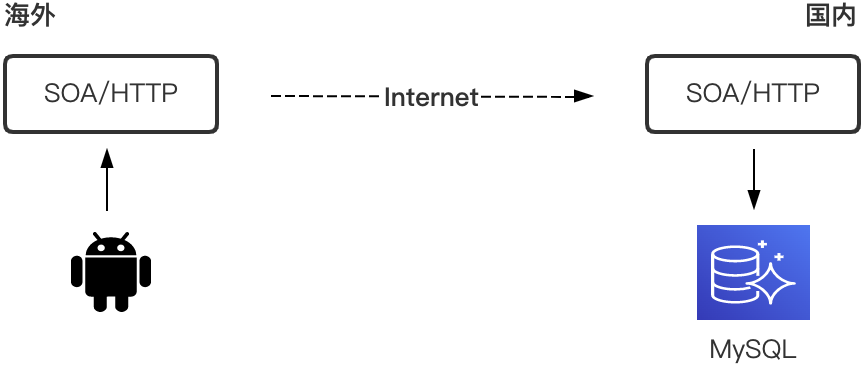
针对用户延迟不敏感或者离线业务,可以采用只应用上云数据库不上云,请求回源国内。该方案下业务需要改造应用中读写数据库操作,根据应用部署地,决定流量是否需要转发。
不建议海外应用直连国内数据库,网络层面专线距离远,成本太高,不现实;安全层面应禁止跨海访问,否则可能导致预期就近访问流量由于非预期错误,将海外流量写入国内数据库,从而引起国内数据错误。
2.2 数据库上云
对于在线用户延迟敏感应用,数据库必须跟随应用一同上云,将请求闭环在海外,从而就近提供服务响应。在确定数据库上云的前提下,根据不同业务特点,可再细分为海外只读和读写两种场景。
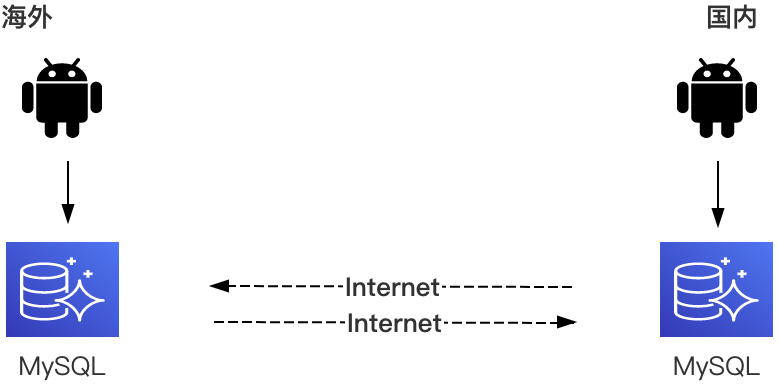
只读场景
对于海外只读场景,国内数据只需要单向复制,该方案下业务海外账号默认无写权限或者业务改造写操作,避免出现由于误写导致国内海外数据不一致。

读写场景
对于海外读写场景,国内海外数据需要双向复制,业务代码无需改造。该方案下由于有2个Master可以写入,业务需要在应用层对流量进行切分,比如用户归属地维度,从而避免在两侧同时修改同一条数据,进而导致复制过程出现数据冲突。
2.3 上云成本
数据距离用户越近,应用直接提供的服务功能越丰富,对应业务改造量越小,机器资源消耗量越大。携程海外应用部署在AWS公有云上,AWS入口流量不计费,只针对出口流量计费。应用上云数据库不上云场景,请求回源国内产生出口流量费用;只读业务单方向数据复制流入,不收费;读写业务数据复制回国内产生出口流量费用。
| 上云场景 |
AWS出口流量 |
数据库成本 |
机器成本 |
业务改造 |
| 应用上云 | 业务请求流量 |
无 |
无 | 改造读写请求 |
数据库上云/只读 |
无 |
RDS费用 |
单向复制 |
改造写请求 |
数据库上云/读写 |
海外→国内复制流量 |
RDS费用 |
双向复制 |
无 |
上云成本主要集中在流量和数据库费用。AWS出口Internet流量0.09$/GB,当流量大时,可通过数据压缩,损耗复制延迟降低出口流量;RDS根据核数计费,1004元/核/月,业务流量少时采用普通4C16G机型即可,流量增加后动态提升配置。核心业务RDS配置一主一从,非核心业务单主即可,并且多个DB可共用一个集群,进而降低成本。
2.4 小结
为了提供高品质的用户体验,数据势必需要上云。在解决了是否上云的问题后,如何上云就成为新的疑问点。下面就详细分析携程内部上云过程中依赖的数据库复制组件DRC实现细节。
三、数据库上云方案
DRC基于开源模式开发,公司内部生产版本和开源保持一致,开源地址https://github.com/ctripcorp/drc,欢迎关注。
DRC孵化于异地多活项目,参见《携程异地多活-MySQL实时双向(多向)复制实践》,解决国内异地机房间数据库同步问题。当其中一个或多个机房位置转变为公有云时,伴随着物理距离的扩大,新的问题应运而生。
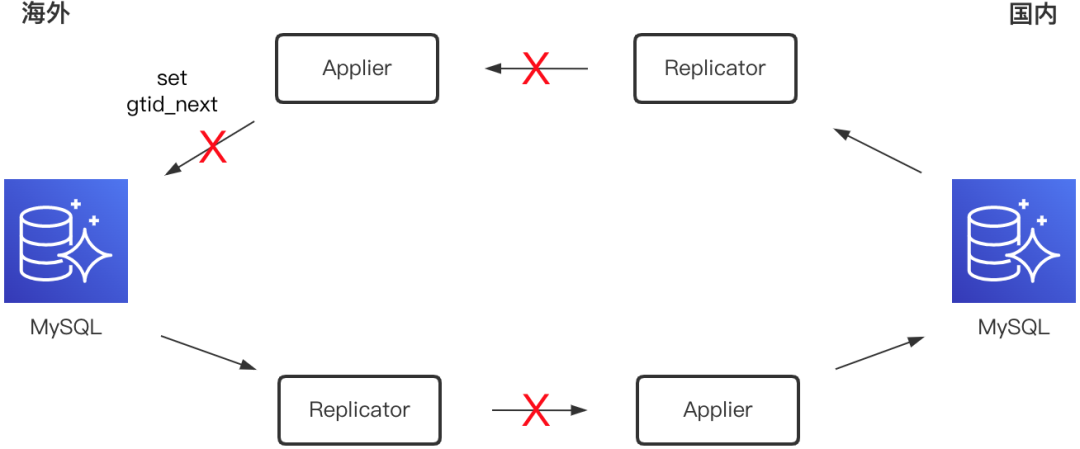
就DRC自身架构实现而言:
公有云和国内机房间互不联通,同步链路被物理阻断
公网传输不如国内跨机房之间专线质量,丢包频发
公有云数据库自主运维灵活性下降,如无法获取root权限,直接导致set gtid_next无法正常工作
就业务接入而言:
国内海外数据隔离,按需复制成为刚需
公有云数据库成本压力导致混部,一对一复制不再满足业务灵活多变的真实部署场景
基于以上限制,DRC调整架构,引入代理模块解决网络联通性问题,借用事务表降低复制链路对权限的要求;为了适应业务的多样性,分别从库、表和行维度支持按需复制。
3.1 架构改造挑战
1)架构升级
DRC中有2个核心功能需要跨公网传输数据:
业务Binlog数据复制
DRC内部延迟监控探针
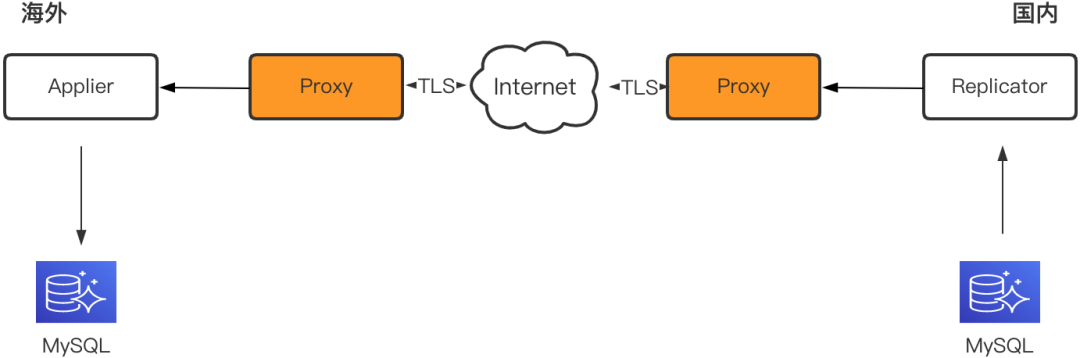
数据复制
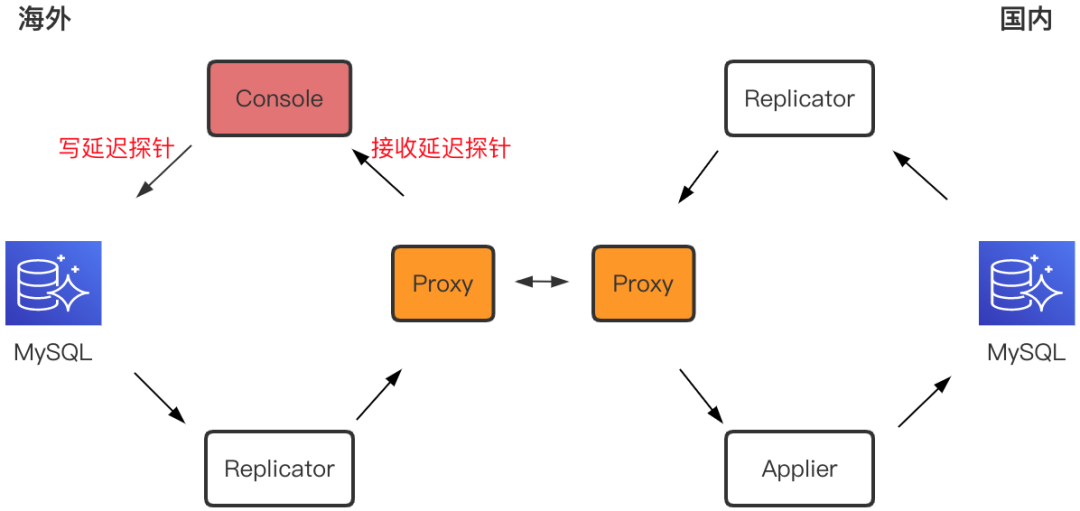
以单向复制为例,在Binlog拉取模块Replicator和解析应用模块Applier之间引入Proxy,负责在TCP层将内网/公网流量转发到公网/内网。Proxy绑定公网IP,采用TLS协议加密传输内网流量。鉴于公网质量不稳定特性,Proxy使用BBR拥塞控制算法,优化丢包引起的卡顿。
Proxy作为公网数据传输携程内部统一的解决方案,参见《携程Redis海外机房数据同步实践》,开源地址:https://github.com/ctripcorp/x-pipe,欢迎关注。
延迟监控
延迟监控探针从业务流量同侧机房的Console写入到业务数据库延迟监控表(初始化时新建),经过双向复制链路,从异侧机房接收延迟探针,从而计算差值得到复制延迟。为了提升Proxy间隔离性,数据复制和延迟监控可以分别配置不同的Proxy实例实现数据传输。
Proxy Client
由于Applier和Console都需要对接Proxy,如何降低Proxy对DRC系统的侵入性就成为一个需要解决的问题。为此我们借助Java Agent技术,动态修改字节码,实现了可插拔的接入方式。接入方只需要引入proxy-client独立Jar包,业务层按需实现Proxy的注册和注销。
2)网络优化
公网网络丢包和拥塞频发,为了在弱网环境下实现平稳复制,就需要快速地异常检测恢复机制。除了在系统层将Proxy拥塞控制算法优化为BBR外,DRC在应用层额外增加:
心跳检测,实现连接自动切换
流量控制,避免突增流量引起资源耗尽进而影响数据复制
2条互备海外出口运营商线路,随机切换

心跳检测
Binlog生产方Replicator定时对下游消费方进行心跳检测,消费方接收到心跳检测需回复响应,Replicator根据后一次接收时间检测并自动关闭长期没有响应的连接。
这里有一种场景需要特别处理,当下游消费方比较忙,主动关闭连接auto_read属性时,由于应用层无法读取暂存在缓冲区的心跳包,从而造成无法响应。这就需要消费方在auto_read改变时,主动上报生产方自身的auto_read状态。
流量控制
公网网络质量下降导致复制延迟变大,数据堆积在发送端Proxy,进而引起Replicator和Proxy触发流控;MySQL性能抖动,应用Binlog速度减缓,数据堆积在Applier,进而引起Applier触发流控并逐层反馈到Replicator。
运营商线路
针对Proxy出口IP,分别配置移动和联通两条运营商线路,当Binlog消费方由于触发空闲检测出现超时重连时,Proxy会随机选择一个运营商出口IP,从而实现运营商线路的互备。
3)事务表复制
国内机房间数据复制时,DBA可以给予DRC拥有root权限的账号,以实现Applier模拟原生Slave节点set gtid_next工作方式应用Binlog,从而将一个事务变更从源机房复制到目标机房,并且在两端分配到同一个gtid下。但是公有云上RDS出于安全原因是无法开放root权限,直接从原理上否定了原有的复制方案。
为了找到合理的替换方案,我们首先从MySQL服务端视角分析下set gtid_next的效果:
事务在提交后会被分配指定的gtid值,否则MySQL服务端会自动分配一个gtid值
gtid值加入MySQL服务端全局变量gtid_executed中
其根本性作用在于将DRC指定的gtid值保存到MySQL系统变量。既然无法利用MySQL系统变量,那么从业务层增加一个复制变量保存gtid信息即可实现同等效果。
其次,转换到DRC复制视角,set gtid_next起到如下作用:
记录Applier复制消费位点,并以此向Replicator请求Binlog
解决循环复制,Replicator根据gtid_event中的uuid判断是否是DRC复制产生的事件
综上分析,新的替代方案需要引入持久化变量,记录复制位点并且能够提供循环阻断信息功效,为此DRC引入基于事务表的同步方案解决了海外复制难题。
位点记录
海外复制业务集群需要新增复制库drcmonitordb,其中新建事务表gtid_executed。
CREATE TABLE `drcmonitordb`.`gtid_executed` (
`id` int(11) NOT NULL,
`server_uuid` char(36) NOT NULL,
`gno` bigint(20) NOT NULL,
`gtidset` longtext,
PRIMARY KEY (`id`,`server_uuid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
server_uuid:源端数据库UUID号
gno:事务id。该列值为0的行为汇总行
gtidset:对于gno=0的汇总行,该列批量存储gno编号,例如server_uuid:1-10:20:30
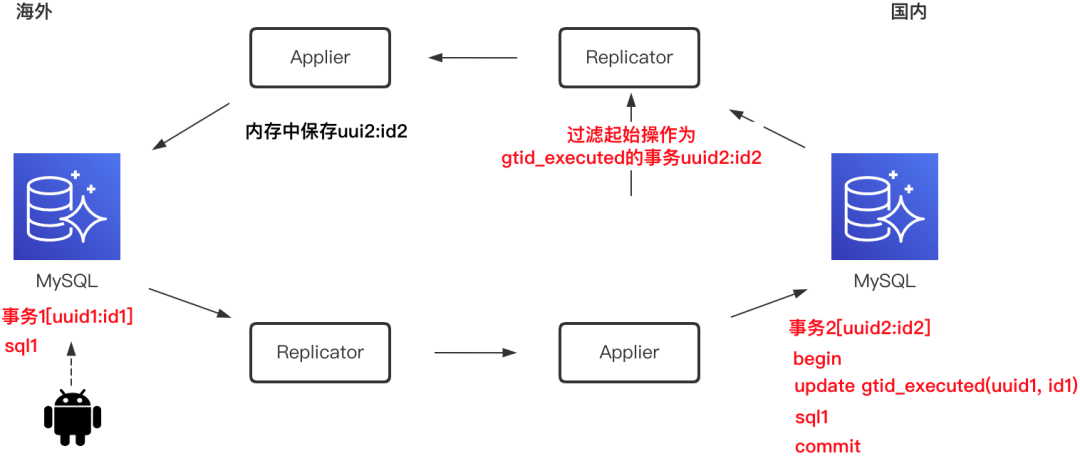
当Applier应用SQL到目标数据库前,需要先更新事务表,记录gtid,然后再执行事务中变更语句,完整的复制流程如下图所示。事务表中gno=0行中gtidset等效MySQL系统变量gtid_executed,Applier执行过程中定时汇总非0行事务gno,从而达到记录位点功能。
循环阻断
针对Binlog中个写事件是事务表gtid_executed操作的事务,Replicator将其判断为DRC复制数据,从而阻断循环复制,否则一条数据会在双向复制环内无限死循环。
3.2 业务落地挑战
至此DRC解决了理论上阻碍复制的已知技术问题,在实际业务落地过程中,出于数据安全、费用和改造成本的考虑,业务对数据复制提出了更精细化控制的需求。
1)数据隔离
出于合规的要求,业务上云后,需要完成国内和海外用户数据的隔离。业务上云前,国内和海外用户数据全部在国内数据库;上云时就需要将海外用户数据单独复制到公有云而过滤掉国内用户数据。
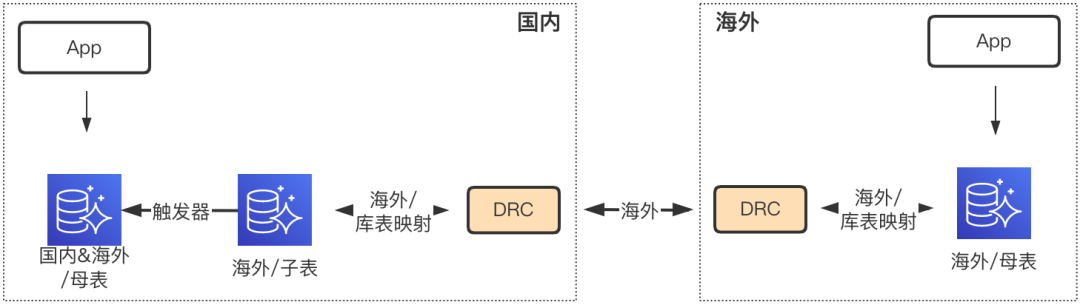
库表映射
上云前国内和海外数据在同一张母表。为了上云,业务通过在国内数据库新增子表,实现国内数据的分离。海外由于只存在海外数据,所以物理上只需要一张母表即可,即国内子表与海外母表相对应,搭建DRC实现双向复制即可。由于母表和子表表名不同,复制时需要做库表映射,从而屏蔽应用层对不同表名的感知,降低业务改造量。
行过滤
库表映射不涉及数据过滤,经过DRC的流量都会进行复制,因此映射在Applier端处理,直接根据映射规则替换表名即可。为此业务需要进行2处改造:
人工分离国内机房国内和海外数据
为了使国内母表保存全量数据,海外用户数据经过DRC复制回国内时,需要通过触发器自动同步到母表
为了进一步降低业务改造量,DRC提供行过滤功能,用户无需进行业务改造,只需保证表中包含Uid字段即可,DRC根据Uid自动判断数据归属地,进行数据过滤。

单向复制链路级别添加行过滤配置,其中包括:
过滤类型
(1)Uid过滤,业务层面一般通过Uid维度进行拆分,通过SPI动态加载Uid过滤实现,携程内部由于Uid无特殊标记,无法通过Uid名称判断出归属地,只能通过SOA远程调用实时判断Uid归属地获得过滤结果;如果Uid有规则可循,则可以通过正则表达式匹配即可
(2)Java正则表达式,支持针对单字段的Java正则表达式简单匹配计算,适合单一维度数值有规则的业务场景
(3)Aviator表达式,支持针对多字段的Aviator表达式复杂匹配计算,适合多维度数值相关联的业务场景
过滤参数
包含表到过滤字段的映射关系,以及与过滤类型对应的上下文,比如正则表达式。
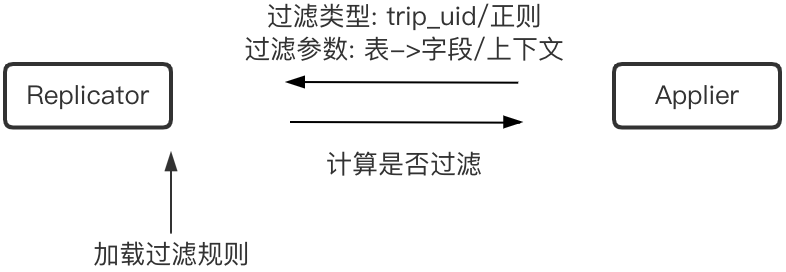
Applier Binlog请求中携带行过滤配置,Replicator根据过滤类型加载对应的过滤规则,从而计算出过滤结果。
行过滤在发送端Replicator实现,这样实现的好处是跨海发送数据量大大降低,但同时也带来了解析和重构Rows Event的复杂性和性能损耗,即先解析Rows Event并根据过滤后的行数据生成新的Rows Event。Rows Event的解析需要表结构信息,而表结构信息是保存在Binlog的头中,势必在Rows Event前保证能够获得对应的表结构;解析后就可以将每行过滤字段值应用到过滤规则上,若匹配出需要过滤的行,则需要根据过滤后的行构造新的Rows Event并发送,否则直接发送即可。

2)数据库混部
核心业务随着数据量的膨胀,会采用分库来降低数据库压力,在公有云部署时,鉴于云上初始流量不多,并且可动态提升机器配置,DBA部署时会将所有分库部署在同一个RDS集群,此时复制从一对一变成一对多。

表过滤
单向复制链路级别添加库表过滤配置,支持Aviator表达式。Replicator发送前,通过将从Binlog中解析的库表名作用于Aviator表达式从而得到过滤结果。

3.3 数据库上云流程
完整的业务上云流程一般分为四步:
数据库先上云,搭建国内海外数据库复制,验证海外数据可用性和完整性
在海外数据可用的前提下,应用上云,就近访问海外数据库,验证部署海外应用可行性
流量路由层灰度业务流量,可根据Uid白名单、流量百分比在流量接入层进行灰度,验证业务逻辑正确性
灰度完成,国内和海外流量完成切分,验证国内和海外业务隔离性,为此后下线底层数据复制做准备

数据库上云在每一步都有所涉及,步通过DRC解决了数据的可用性问题,第二步通过数据库访问中间件解决了数据可达性问题,第三步业务通过流量准确切分保证数据一致性问题,第四步国内海外实现数据隔离后,即可下线DRC数据复制。在分析完DRC原理后,下面再分析下其他几步数据库相关问题。
1)数据访问层
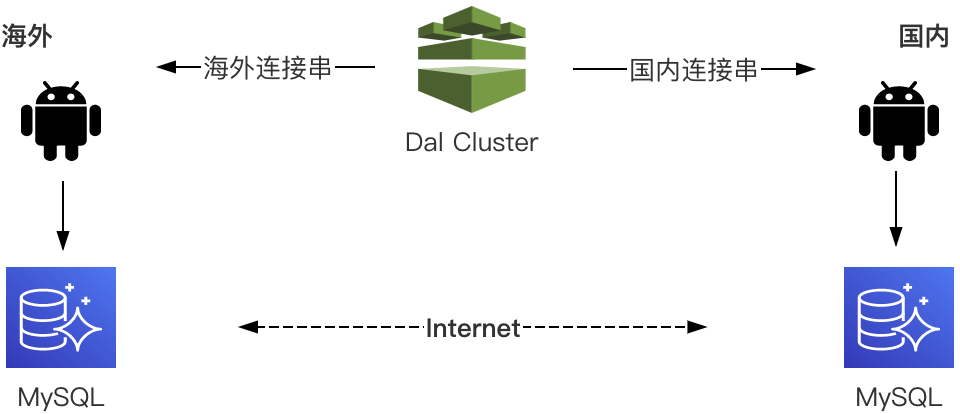
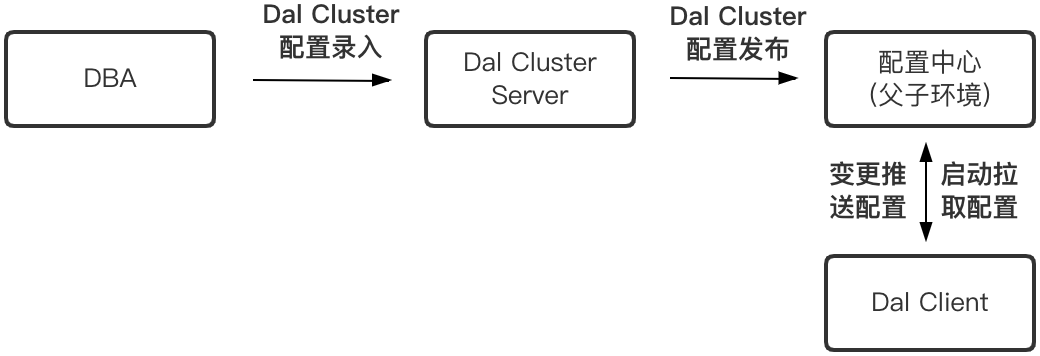
Dal包含中心化配置管理服务端Dal Cluster和Dal客户端两部分。上云前同一个数据库物理上只有一个集群,上云后海外增加相同集群,服务端Dal Cluster就需要根据客户端环境下发正确的MySQL配置文件。
Dal Cluster原理
Dal Cluster变更推送功能借由分布式配置中心完成,配置中心提供子环境功能,国内数据库配置默认放在父环境,海外数据库则会在上线流程中生成对应的子环境数据库配置。这样在Dal Client启动时,带有不同环境配置的客户端会拉取到不同的配置,从而实现数据库的就近访问,整个过程对业务透明,代码无需改造。
2)流量切分
业务上云一般采用Uid归属地进行流量切分,当流量开始灰度后,两端数据库都开始接收写流量。如果流量灰度不干净,针对同一个Uid数据在两端同时被修改,则会导致底层DRC数据复制时出现数据冲突。
当冲突发生时,Applier默认根据时间戳进行冲突策处理,接入DRC的表都有一个到毫秒自动更新的时间戳,时间戳新的数据会被采用,从而实现数据的一致。
3)表结构变更
通过DRC复制的集群,在表结构变更流程中,会自动关联到公有云集群,在两端同时进行变更操作。
由于变更完成时间有先后,假设一个增加字段的变更海外先完成,在国内完成变更前的时间范围内,针对该表海外到国内的复制将出现复制冲突,默认DRC会捕获该异常,并从异常信息中提取出列名,将多出的列从SQL中移除后再执行,从而自动处理掉冲突。
当国内集群完成表结构变更后,新增列的值在两端都为默认值,数据仍然一致。

3.4 业务落地成果
海外数据库复制从2021年11月上线至今,接入公司90+复制集群;
上海↔新加坡AWS复制平均延迟90ms,上海↔法兰克福AWS复制平均延迟260ms;
账号集群通过库表映射,常旅、收藏等通过行过滤实现用户数据隔离;
通过一对多部署,公有云/国内机房MySQL集群比维持在1/5,DRC复制成本/MySQL集群成本维持在2/5;
四、未来规划
为了支持更多Binlog消费方,支持消息投递;
-
DRC当前只支持增量数据的实时复制,后续会支持存量数据的复制以及敏感数据的初始化过滤,覆盖业务上云过程中更多数据复制场景;
Replicator作为有状态实例,使用本地磁盘保存Binlog,公有云使用的块存储本身即是分布式存储系统,Replicator可探究存储架构改造,实现主备共用同一份存储,从而降低使用成本。
DRC开源地址:
https://github.com/ctripcorp/drc
【推荐阅读】

“携程技术”公众号
分享,交流,成长
