前言
这篇文章的主题是记录一次 Python 程序的性能优化,在优化的过程中遇到的问题,以及如何去解决的。为大家提供一个优化的思路,首先要声明的一点是,我的方式不是的,大家在性能优化之路上遇到的问题都不止一个解决方案。如何优化
首先大家要明确的一点是,脱离需求谈优化都是耍流氓,所以有谁跟你说在xx机器上实现了百万并发,基本上可以认为是不懂装懂了,单纯的并发数完全是无意义的。其次,我们优化之前必须要有一个目标,需要优化到什么程度,没有明确目标的优化是不可控的。再然后,我们必须明确的找出性能瓶颈在哪里,而不能漫无目的的一通乱搞。
需求描述
这个项目是我在上家公司负责一个单独的模块,本来是集成在主站代码中的,后来因为并发太大,为了防止出现问题后拖累主站服务,所有由我一个人负责拆分出来。对这个模块的拆分要求是,压力测试 QPS 不能低于3万,数据库负载不能超过50%,服务器负载不能超过70%,单次请求时长不能超过70ms,错误率不能超过5%。服务器:4核8G内存,CentOS7系统,SSD 硬盘
数据库:MySQL 5.7,大连接数 800
缓存: Redis,1G 容量。压测工具:locust,使用腾讯的弹性伸缩实现分布式的压测。用户进入首页,从数据库中查询是否有合适的弹窗配置,如果没有,则继续等待下一次请求、如果有合适的配置,则返回给前端。这里开始则有多个条件分支,如果用户点击了弹窗,则记录用户点击,并且在配置的时间内不再返回配置,如果用户未点击,则24小时后继续返回本次配置,如果用户点击了,但是后续没有配置了,则接着等待下一次。重点分析
根据需求,我们知道了有几个重要的点,1、需要找出合适用户的弹窗配置,2、需要记录用户下一次返回配置的时间并记录到数据库中,3、需要记录用户对返回的配置执行了什么操作并记录到数据库中。调优
我们可以看到,上述三个重点都存在数据库的操作,不只有读库,还有写库操作。从这里我们可以看到如果不加缓存的话,所有的请求都压到数据库,势必会占满全部连接数,出现拒绝访问的错误,同时因为 SQL 执行过慢,导致请求无法及时返回。所以,我们首先要做的就是讲写库操作剥离开来,提升每一次请求响应速度,优化数据库连接。整个系统的架构图如下:

将写库操作放到一个先进先出的消息队列中来做,为了减少复杂度,使用了Redis 的 list 来做这个消息队列。QPS 在 6000 左右 502 错误大幅上升至 30%,服务器 CPU 在 60%-70% 之间来回跳动,数据库连接数被占满 TCP 连接数为 6000 左右,很明显,问题还是出在数据库,经过排查 SQL 语句,查询到原因就是找出合适用户的配置操作时每次请求都要读取数据库所导致的连接数被用完。因为我们的连接数只有 800,一旦请求过多,势必会导致数据库瓶颈。好了,问题找到了,我们继续优化,更新的架构如下: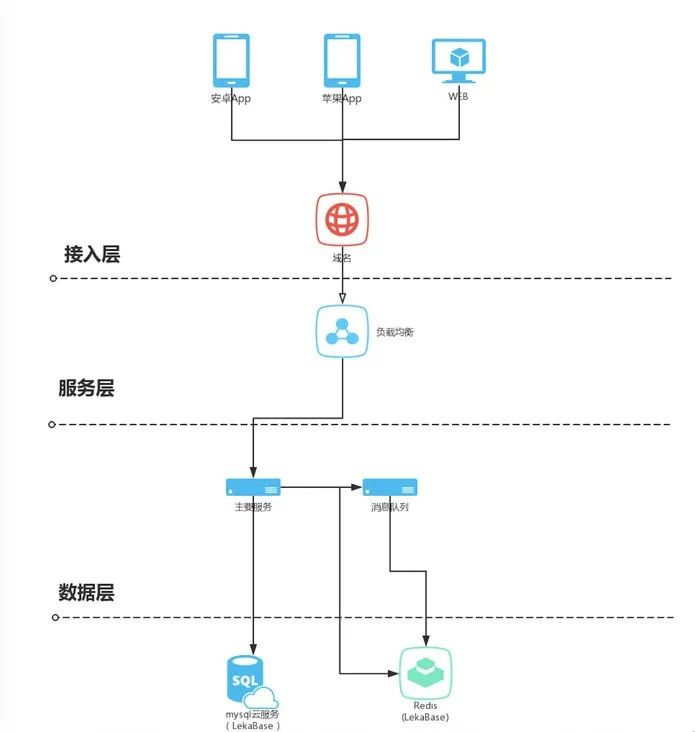
我们将全部的配置都加载到缓存中,只有在缓存中没有配置的时候才会去读取数据库。接下来我们再次压测,结果如下:
QPS 压到 2万左右的时候就上不去了,服务器 CPU 在 60%-80% 之间跳动,数据库连接数为300个左右,每秒TPC连接数为1.5万左右。这个问题是困扰我比较久的一个问题,因为我们可以看到,我们2万的 QPS,但是TCP 连接数却并没有达到2万,我猜测,TCP连接数就是引发瓶颈的问题,但是因为什么原因所引发的暂时无法找出来。
这个时候猜测,既然是无法建立 TCP 连接,是否有可能是服务器限制了 socket 连接数,验证猜测,我们看一下,在终端输入 ulimit -n 命令,显示的结果为65535,看到这里,觉得 socket 连接数并不是限制我们的原因,为了验证猜测,将 socket 连接数调大为100001.QPS压到2.2万左右的时候就上不去了,服务器cpu在60%-80%之间跳动,数据库连接数为300个左右,每秒 TCP 连接数为1.7万左右。虽然有一点提升,但是并没有实质性的变化,接下来的几天时间,我发现都无法找到优化的方案,那几天确实很难受,找不出来优化的方案,过了几天,再次将问题梳理了一遍,发现,虽然socket连接数足够,但是并没有全部被用上,猜测,每次请求过后,tcp连接并没有立即被释放,导致socket无法重用。经过查找资料,找到了问题所在,TCP 链接在经过四次握手结束连接后并不会立即释放,而是处于 timewait 状态,会等待一段时间,以防止客户端后续的数据未被接收。
好了,问题找到了,我们要接着优化,首先想到的就是调整 TCP 链接结束后等待时间,但是 Linux 并没有提供这一内核参数的调整,如果要改,必须要自己重新编译内核,幸好还有另一个参数 net.ipv4.tcp_max_tw_buckets, timewait 的数量,默认是180000。我们调整为 6000,然后打开 timewait 快速回收,和开启重用,完整的参数优化如下:
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_tw_reuse = 1
我们再次压测,结果显示:QPS 5万,服务器 CPU 70%,数据库连接正常,TCP 连接正常,响应时间平均为 60ms,错误率为 0%。结语
到此为止,整个服务的开发、调优、和压测就结束了。回顾这一次调优,得到了很多经验,重要的是,深刻理解了web开发不是一个独立的个体,而是网络、数据库、编程语言、操作系统等多门学科结合的工程实践,这就要求web开发人员有牢固的基础知识,否则出现了问题还不知道怎么分析查找。ps:服务端开启了 tcp_tw_recycle 和 tcp_tw_reuse是会导致一些问题的,我们为了优化选择牺牲了一部分,获得另一部分,这也是我们要明确的。来源:https://segmentfault.com/a/1190000018075241
- EOF -
