1. DynamoDBиЎЁеҗ«д№ү
DynamoDBиЎЁжҰӮеҝөпјҢеҜ№дәҺж–°жүӢйқһеёёдёҚеҸӢеҘҪпјҢиҖҢдё”е®ҳзҪ‘д»Ӣз»ҚжҜ”иҫғзІ—з•ҘгҖӮдёҚе°‘еә”иҜҘжңүдҫӢеӯҗзҡ„ең°ж–№пјҢжІЎжңүз»ҷеҮәд»Јз ҒдҫӢеӯҗгҖӮд№ҹе°ұжҳҜиҜҙпјҢж–ҮжЎЈд№ҹдёҚеҸӢеҘҪгҖӮжҲ‘е°қиҜ•еҸӢеҘҪзҡ„иҜҙеҮ еҸҘпјҢзңӢзңӢиғҪеҗҰвҖңзӣҙеҮ»з—ӣзӮ№вҖқпјҡ
- NoSQLеһӢпјҡиҝҷзӮ№еӨ§е®¶е®№жҳ“зҗҶи§Ј
- еҝ…йЎ»иҰҒжңүдё»й”®пјҡиҝҷзӮ№е’ҢMongoDBеһӢNoSQLдёҚеҗҢпјҢд№ҹе’ҢMySQLзӯүSQLеһӢж•°жҚ®еә“дёҚеҗҢ
- дё»й”®иҝҳдёҖеӨ§е ҶзәҰжқҹ
- жҹҘиҜўд№ҹжңүдёҖеӨ§е ҶзәҰжқҹ
2. DynamoDBзҡ„дё»й”®
DynamoDBзҡ„дё»й”®пјҢеҸҜд»ҘжҳҜ1дёӘеӯ—ж®өпјҢд№ҹеҸҜд»ҘжҳҜ2дёӘеӯ—ж®өпјҢдёҚиғҪеҗ«жңү2дёӘд»ҘдёҠеӯ—ж®өгҖӮ
- еҰӮжһңжҳҜ1дёӘеӯ—ж®өдё»й”®пјҢйӮЈд№ҲиҝҷдёӘеӯ—ж®өеҸҜд»Ҙе®ҡдҪҚи®°еҪ•гҖӮиҝҷдёӘprimary keyд№ҹеҸ«пјҡpartition key
- еҰӮжһңжңү2дёӘеӯ—ж®өдё»й”®пјҢйӮЈд№ҲдёӘеӯ—ж®өеҸ«пјҡpartition keyпјӣ第дәҢдёӘеӯ—ж®өеҸ«пјҡsorted key
еҰӮжһңжғіиҰҒй«ҳж•ҲжҹҘиҜўпјҢеҚіQueryж“ҚдҪңпјӣеҸҰдёҖз§ҚдёҚй«ҳж•ҲвҖңжҹҘиҜўвҖқпјҢеңЁDynamoDBзҡ„дё–з•ҢпјҢеҸ«Scanж“ҚдҪңгҖӮ
- Queryж“ҚдҪңпјҢеҝ…йЎ»жҢҮе®ҡpartition keyпјҢsorted keyеҚідҪҝеӯҳеңЁпјҢд№ҹеҸҜд»ҘдёҚжҢҮе®ҡ
- Scanж“ҚдҪңпјҢе…ЁиЎЁжҹҘиҜўпјҢе®ҳж–№дёҚжҺЁиҚҗдҪҝз”Ё
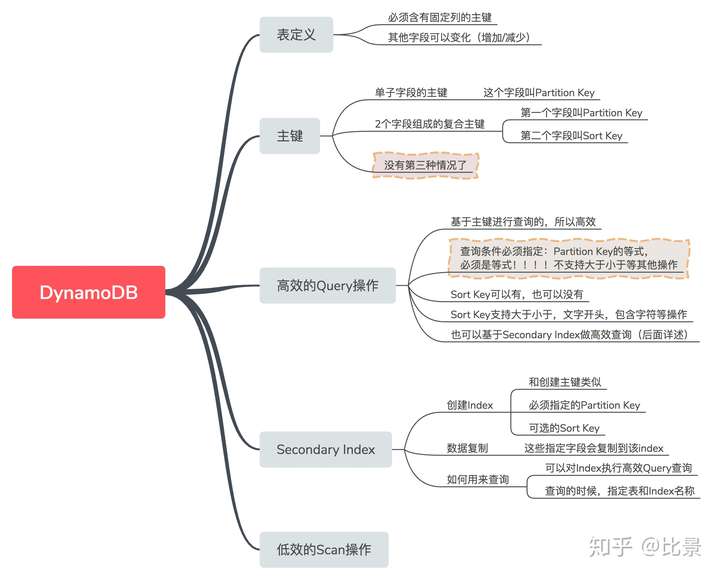
3. ж №жҚ®IndexжҹҘиҜў
жҜ”еҰӮпјҢдәӨжҳ“и®°еҪ•иЎЁпјҲTransпјүеҗ«жңүеӯ—ж®өпјҡ
idпјҢfromпјҢtoпјҢamountпјҢcreateAtпјҢstatusиҝҷдәӣеӯ—ж®өпјҢе…¶дёӯidдёәдё»й”®гҖӮеӣ дёәжҹҘиҜўпјҲQueryпјүж“ҚдҪңпјҢеҝ…йЎ»иҰҒжҢҮе®ҡPartition Keyзҡ„зӯүејҸзӯӣйҖүжқЎд»¶гҖӮеҒҮеҰӮеҪ“еүҚиҰҒжҹҘиҜўstatus=1зҡ„дәӨжҳ“и®°еҪ•гҖӮеӣ дёәstatusдёҚжҳҜPartition KeyпјҢеӣ жӯӨж— жі•жү§иЎҢиҝҷж ·зҡ„whereжқЎд»¶пјҡ
where status=1 // иҝҷдёӘжҳҜдјӘд»Јз Ғ
table.Get("status", 1) // Go жҹҘиҜўиҜӯжі•еӣ жӯӨпјҢжҢүз…§DynamoDBзҡ„规еҲҷпјҢжҲ‘们еҸҜд»ҘеҲӣе»әSecondary IndexжқҘе®һзҺ°гҖӮ
Partition Key: status
Sort Key: idиҝҷж ·пјҢжҹҘиҜўиҜӯеҸҘзұ»дјј
where status=$status4. еҲҶйЎө
MySQLзҡ„еҲҶйЎөиҜӯжі•жҳҜпјҡ
select * from Table limit 20, 10 //жҹҘиҜў21пҪһ40иЎҢи®°еҪ•DynamoDBзҡ„еҲҶйЎөиҜӯжі•жҳҜпјҡ
// status=1зҡ„жҹҘиҜўпјҢжҹҘиҜўеҮәжқҘзҡ„第20жқЎи®°еҪ•зҡ„id
// дёҖиҲ¬жғ…еҶөдёӢпјҢз”ұеүҚз«ҜдҝқеӯҳеүҚйқў20жқЎи®°еҪ•пјҢжҹҘиҜўз¬¬дәҢйЎөзҡ„ж—¶еҖҷпјҢдј з»ҷеҗҺеҸ°
lastEvaluatedKey=map[string]*dynamodb.AttributeValue{
param.SortKeyName: {
pageKeyValue.S = aws.String("第20жқЎи®°еҪ•зҡ„id")
},
}
table.Get("status", 1).StartFrom(lastEvaluatedKey).Limit(20)
5. дёҖдәӣжҖқиҖғ
ејҠз«Ҝпјҡ
- жҳҫ然зңӢиө·жқҘпјҡDynamoDBжҹҘиҜўжҳҜеҫҲдёҚж–№дҫҝзҡ„
- дё»й”®зәҰжқҹйқһеёёеӨ§пјҢеӨҡ2дёӘеӯ—ж®ө
- жҹҘиҜўиҜӯжі•еҸҲжҳҜиҮӘе·ұжҗһдёҖеҘ—пјҢе’Ңд№ӢеүҚSQLжІЎжңүе•Ҙе…ізі»
зҢңжөӢDynamoDBдҪіе§ҝеҠҝпјҡ
- йҮҚи§Ҷж•°жҚ®еӯҳеӮЁ
- ж•°жҚ®жҸҗеҸ–йҖ»иҫ‘иҫғдёәз®ҖеҚ•пјҡжҜ”еҰӮе°ұжҢүз…§idжҲ–иҖ…еҸҜж•°зҡ„еҮ з§ҚеңәжҷҜпјҢиҖҢдё”иҝҷдәӣеңәжҷҜдёӢPartition Keyзҡ„hashеҖјж•ЈжӯҘзҡ„жҜ”иҫғе№іеқҮ
- жҠҠж•°жҚ®зӯӣйҖүзӯүйҖ»иҫ‘жӢҶеҲҶжҲҗж•°жҚ®жөҒпјҢжҜ”еҰӮжҠҠжңӘеӨ„зҗҶзҡ„дәӨжҳ“дҝЎжҒҜпјҢж”ҫе…ҘеҲ°еҸҰеӨ–дёҖдёӘж•°жҚ®жөҒжҲ–иҖ…ж•°жҚ®иЎЁйҮҢйқўпјҢдёҡеҠЎд»Јз ҒеҺ»жҹҘиҜўиҝҷдёӘж•°жҚ®жөҒжҲ–иҖ…ж•°жҚ®иЎЁпјҲиҖҢдёҚжҳҜжҹҘиҜўеҺҹе§Ӣзҡ„дәӨжҳ“иЎЁпјү
дәҡ马йҖҠзҡ„жңҚеҠЎпјҢзңӢиө·жқҘ蹩и„ҡпјҢеҰӮжһңжҢүз…§ж—ўжңүжҗһд»Јз Ғзҡ„жҖқжғіеҺ»з”ЁпјҢдјҡжӣҙеҠ 蹩и„ҡгҖӮеҰӮжһңпјҢжҚўжҲҗжөҒгҖҒжңҚеҠЎзӯүжҖқи·ҜпјҢеҸҜд»Ҙжү“ејҖж–°зҡ„еұҖйқўгҖӮ
