摘要
在这篇文章中,我会先介绍一下什么是索引,索引有什么作用。
之后会介绍一下索引的数据结构是什么样的,有什么优点,又会带来什么样的问题。
在分析完数据结构后,我们可以根据这个数据结构,研究索引的用法,以及如何设计更高效的缓存。
后,我会对上一篇的内容进行补充,介绍change buffer的作用以及分析change buffer对性能的影响。
1 目的
在我们学习索引之前,我们要先了解它是什么,以及有什么作用。
官方对于索引的定义是这样的:
Indexes are used to find rows with specific column values quickly. Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows.
也就是说,索引是用来快速查找具有特定值的一行数据(的一种数据结构)。如果没有索引,MySQL必须得从行开始逐行扫描数据。
尤其是当我们的数据量越来越大的时候,恰当的索引是可以帮助我们拥有更的性能的。
这句话的另外一层含义在于:如果索引设计的不好,可能会使得我们的数据库性能变得更加的糟糕。
那么,索引到底是什么呢?我们接着往下看。
2 模型
在讲索引具体的数据结构之前,我们来想象一下我们在英文词典里面找一个单词。
如果我们需要找一个单词:"awesome"!
我们会在目录里面找到以字母 A 开头的一系列单词,然后从以字母 A 开头的一系列单词中找到 W ,然后是 E …
就这样不断的往下查找,不断缩小我们的查找范围。如果我们不适用目录,直接在正文里面找这个单词,可能需要花费更多的时间。
况且,这个词典里面的单词是排好序的,如果我们找 Z 开头的字母,可能得找好几百页,才能终找到。
这个例子不能说特别的准确,但是反映了索引的核心:减少查找的次数。
我们都知道,MySQL的数据保存在了磁盘中。而磁盘的IO是慢的。所以,减少磁盘的读写是提高性能必不可少的做法。虽然现在大多数计算机已经使用了SSD,不再需要寻道等,但是索引的原则还是成立的。
这里我们来看看InnoDB的B+树是怎么实现的(图来自于《高性能MySQL》):

可以看出,这是一颗N叉树,树中的每一个结点,都是MySQL中的一个数据页。
其实说白了这里的N叉树,和二叉查找树查找逻辑是一样的。只不过不同的地方在于这里的每一个结点,包含了比二叉查找树更多的数据与指针。这样做的目的是使得在数据量相同的情况下,B+树可以使得树的高度更低。
而又因为所有的数据页都是持久化保存在磁盘中的,所以更低的高度意味着查找一个数据需要进行磁盘IO的次数越少,效率变得更高。
注意,因为N叉树的N越大,对应的树的高度就会越低。而每一个结点(每一个数据页)的大小是固定的(默认是16K,可以使用innodb_page_size参数修改),所以当设置为索引的key越小的时候,N就会越大。
3 分类
在经过上面的介绍之后,我想你应该能理解索引的查找方法了。下面我们再来说说索引的分类:
主键索引和非主键索引。
主键索引,就是非叶子结点中存储的值都是主键的值,在查找的时候通过主键查找。直到查找到后的叶子节点。在后的叶子节点中保存了这个主键对应的整行数据。
非主键索引,就是非叶子结点中存储的值都是索引的值,查找的时候通过这一个数值进行查找。查找到后的叶子节点,保存了对应的主键ID。然后,MySQL会根据查到的主键,再查找主键索引对应的B+树,直到找到这一行的所有数据。而这个通过查找到主键,然后再利用主键来再次查找,或者这一行数据的过程,称为回表。
注意,我们在新建一张表的时候,一定会有一颗以主键为索引的B+树。哪怕你没有设置主键,MySQL都会选一个不包含NULL的个索引列作为主键列,并把它用作一个主键索引。如果没有这样的索引就会使用行号生成一个聚集索引,把它当做主键。
此外,每增加一个索引,MySQL就会多维护一颗B+树。维护B+树的过程也是很复杂的,涉及到了页的分裂等,我想在以后的文章进行介绍。
另外之前也提到了,影响MySQL性能的一个很重要的因素就是磁盘IO。而回表这个操作,无异于增加了很多的IO次数。
那么有什么办法可以减少这一部分的开销吗,我们接着往下看。
4 联合索引
我们在上面提到的索引,都是单个的数据进行查找。
这样的话,我们每次对其中一个列建立一个索引,就得多维护一颗B+树,同样对性能和空间造成了浪费。
那么我们有没有可能同时对多个数据进行排序,然后再进行查找呢?答案是可以的,我们可以采用联合索引。
4.1 左前缀
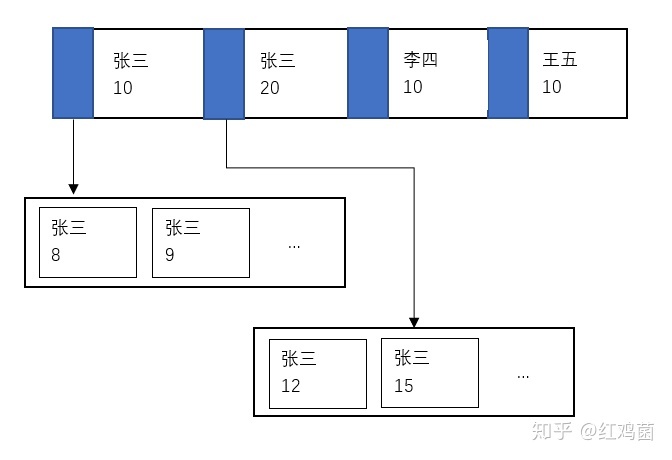
以上面这张图为例:
我们建立了一个(姓名,年龄)的联合索引。
如果我们需要找一个15岁的法外狂徒(误)张三:
select * from user where name = "张三" and age = 15;
因为此时我们的查找条件完全匹配了我们定义的索引,所以MySQL会先从查找的个条件开始,找到名为“张三”的数据,然后此时会继续判断第二个年龄为15岁的条件,因为此时大于个数据项中的10岁,且小于第二个数据项中的20岁,所以会从第二个指针往下寻找,查找大于10岁且小于20岁的“张三”。
这种条件和索引完全匹配的查找过程,称为全值匹配查询。
但是,假设我们没有设置多个查找条件,只搜索名字为“张三”的人。
select * from user where name = "张三";
那么此时的查找过程不会去匹配年龄这一列,只会比较姓名这一列。所以,会从这颗B+树左边的结点,8岁的张三开始,不断的向后遍历,直到这个数据的姓名不叫“张三”为止。
这样的查找过程,称为左前缀查找。简单的来解释,就是查找的条件只要是符合这个联合索引,或者符合这个联合索引的左边几项,索引就会生效,也就实现了“剪枝”的目的,加速了查找的速度。只有剩下的那些不符合左前缀的条件,才会依次遍历来进行匹配。
也就是说,只要满足左前缀,就可以利用索引来加速检索。这个左前缀可以是联合索引的左N个字段,也可以是字符串索引的左M个字符。
那么,什么时候左前缀不会生效呢?
假设有这么一个联合索引(a, b, c, d, e, f)。那么查找条件是(a)、(a, b)、(a, b, c)等都是称为符合左前缀的。也就是说,一定要从索引的左边开始,任意N个字段或者M个字符。
但是如果我们使用了(a, c, d)这样的查找条件,那么只会对(a)起作用,(c, d)是不会生效的。因为左前缀被中断了。
而如果是(e, f)这样的查找条件,也同样不会生效,因为也不符合左边的N个字段的规则,不属于左前缀。
所以,索引的复用能力是我们在建立联合索引时候的一个评估标准。因为可以支持左前缀,所以当已经有了(a,b)这个联合索引后,一般就不需要单独在a上建立索引了。因此,原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
但是,联合索引也不是越长越好。我们在前面提到过,要尽可能的让N叉树的N比较大,这样树的高度会比较低,以此来减少磁盘的IO次数。如果联合索引包含的字段比较多,在页面大小固定的情况下,会造成N值的减少,反而会减慢效率。
4.2 索引下推
继续上面的法外狂徒的例子。
假设我们的语句是这样的:
select * from user where name like "张%%" and age = 15;
很好理解,我们会觉得MySQL会从名字以“张”开头的数据开始遍历,然后判断年龄是否为15。
但是左前缀有一个非常重要的原则:MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
也就是说,此时我们的查询,age这个索引是用不上的。
所以,在MySQL5.6之前,只要找到了符合以“张”开头的名字这个条件,就会通过这个数据的主键ID,进行回表的操作,然后查找这个数据的年龄是否为15。
而MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。也就是说,直到找到了以“张”开头的名字并且年龄为15,才会进行回表。
此外,在回表之前,如果使用了Multi-Range Read (MRR)这个策略,在取出主键后,回表之前,会在对所有获取到的主键排序。
4.3 覆盖索引
还记得我们前面说到的吗,如果我们采用的是非主键索引,那么我们查到了这个数据之后,还需要根据叶子节点中的主键,再回表一次。
覆盖索引可以解决这个问题。比如我们前面查找“张三”的时候,我们也可以同时找到他的年龄。比如(a,b)这样的联合索引,在我们使用
select b form table_name where a = xxx;
这么一条语句的时候,找到了符合条件的a,不需要通过主键来进行回表,找到b的值,而是会直接返回记录在这颗B+树中的值。也就是说,在这个查询里面,索引(a,b)已经“覆盖了”我们的查询需求,我们称为覆盖索引。
5 索引与普通索引
- 普通索引:加快对数据的访问速度
- 索引:不允许重复的普通索引
5.1 查询
我们先来分析查询方面的性能。
对于查询来说,如果这个是普通索引,那么在找到了符合条件的数据之后,会往后继续遍历,直到碰到不满足的数据为止。
如果是索引,由于他的性,只要找到了,那就直接返回就行,不需要继续往后遍历。
其实两者的性能差距微乎其微。
为什么呢?你可能会想:普通索引还需要继续遍历,有可能会更慢。但是,我们之前提到过,查询操作是需要把数据读到内存的,并且是以数据页的形式读到内存。而在内存中的遍历操作,速度方面的差距是特别小的。
就算普通索引的后一项还是相同的,需要通过磁盘IO来读取下一页,这个时候可能是比较耗费时间的。不过因为一个数据页包含了特别多的数据,这种可能性是特别低的。
5.2 插入
在我们说到插入之前,我先要跟你介绍一下change buffer这个东西。
我在上一篇文章中提到:在我们需要更新数据的时候,先把数据从磁盘读到内存中,修改这个数据,然后修改redolog,增加binlog,等内存满了之后或者redolog写满了之后,再将脏页刷回磁盘。
那么插入数据呢?
在我们新增了一条数据之后,MySQL并不会将这个插入直接写入磁盘中,而是会将这个修改写入change buffer中。
在之后有关于这个数据页的查询请求的时候,才会读取这一个数据页,然后根据change buffer中关于这一页的记录,依次更新到读取到了内存中的数据页中,这个过程称为merge。在更新完毕之后,才把查询结果返回。
但是这样有什么用呢?
假设我们插入的普通索引不在内存中,此时有两个作用:
,因为我们在插入一条数据的时候,不需要通过磁盘的IO把需要写入的数据页调入内存中进行修改,而是会将这个插入行为记录下来,在之后才统一对脏页进行刷回磁盘的操作。也就是说,change buffer避免了每次都需要调入一个数据页进内存中进行修改,造成脏页过多的问题。
第二,也是重要的,change buffer的设计避免了在每一次插入过程中为了寻找数据页而进行的随机IO。并且,在之后对脏页进行刷新的时候,MySQL会尽可能的让脏页可以是以顺序IO的方式刷新回磁盘中。
这个过程对于普通索引来说是提升的非常大的。
简单的来说,change buffer的主要目的就是将记录的变更动作缓存下来。所以在一个数据页做merge之前,change buffer记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。
但是对于索引来说,因为索引的约束是“数据”。所以还是需要找到这个数据页,判断有无冲突,才会进行插入。这样的话,change buffer不起作用。
然后我们来把change buffer与之前提到的redo log联系在一起。
比如我们需要插入两条数据,其中一条数据所在的数据页在内存中,另外一条数据所在的数据页在磁盘中(还未读入内存),且这两条数据所用到的索引是普通索引(不需要验证是否重复)。
此时,对于在数据页在内存中的插入操作,直接修改内存,对于数据页不在内存中的插入操作,将这个插入操作记录在change buffer中。随后,将这两次的操作,记录在了redo log中,然后增加binlog。当这两个日志文件都写好后,返回,操作结束。
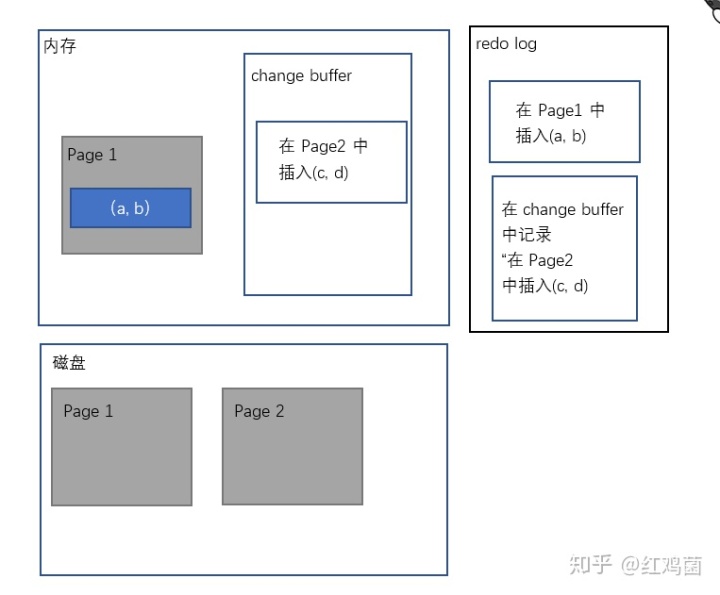
而对于何时将内存中的脏页刷回磁盘,是另外的一个操作。
此外,这里的change buffer也同样可以被持久化,也遵循checkpoint机制,即change buffer会标记哪些记录是已经merge到数据页中,哪些还没有。
在MySQL5.5以后,除了插入操作,更新操作和删除操作,也支持使用change buffer。也就是说,对于更新操作和删除操作,也会被change buffer记录下来,在之后才进行merge。
写到后
首先,谢谢你能看到这里!
此外,也要特别感谢雄哥,在索引这一部分的内容同样给了我特别大的帮助!
关于MySQL索引相关的内容,大概就是这些了。同样的,也在这篇文章中挖了很多坑没有填上。限于篇幅以及文章的连贯性,没有详细介绍。但是会在后面的文章中提到的。
如果在这篇文章中,有什么是我没有解释清楚的,又或者是我的理解出现了错误,还请留言指正,谢谢啦!
PS:如果有其他的问题,也可以在公众号找到作者。并且,所有文章时间会在公众号更新,欢迎来找作者玩~
