本文来自有才网友
引言
阿里巴巴在刚刚结束的国际存储行业会议 FAST 2020 贡献三篇论文:
- 《POLARDB结合可计算存储: 高效支持云原生关系数据库的复杂查询操作》
- 《FPGA加速Compactions操作,基于 LSM-tree的键值存储》
- 《HotRing:热点感知的无锁内存键值系统》
再结合阿里云数据库李飞飞教授的《如何看待数据库的未来》中提到的
新硬件 : 软硬件一体化设计
无不透露着业界领头羊正在定义云原生数据库的业界标准,数据库不仅是运行在CPU和内存中的二进制代码,也不再是高端硬件的简单堆叠,关键硬件必须在设计阶段就要针对数据库特性做深度定制和优化,借用Alan Kay的名言:
People who are really serious about software should make their own hardware.
以下的文字只当是”囫囵吞枣“后的一些粗浅思考。受本人能力所限,未尽之处,实属应当。
”随风潜入夜,润物细无声“,其实数据库软硬件一体化的进程早在十几年前就以不易察觉的方式拉开序幕。
拿来主义
在2010年,笔者次在生产环境接触Infiniband技术,当时Oracle RAC (real application cluster)就通过超算领域(HPC)的Infiniband网络技术优化集群实例之间的内存数据(Cache Fusion)交互。相比万兆网络,Infiniband不仅提供更高带宽和更低延时,基于RDMA 提供 Zero Copy 和 Asynchronous I/O特性进一步提升通讯协议效率,同时极大减少对CPU资源的消耗。
同年,也开始在电商数据库生产环境应用固态盘(SSD)技术。要说明白SSD的价值,先简单赘述关系型数据库中的预写式日志(Write-ahead Logging,简称WAL)机制,WAL是为关系数据库系统(RDBMS)提供原子性和持久性(ACID属性中的两个)的关键技术,我们常用的关系型数据库Oracle,MySQL(Innodb Engine)和SQL Server都基于WAL实现(具体实现各有不同)。Oracle中又叫Online redo log(后面简称log),log持久化延时直接影响到TPS(Transaction per Second),在OLTP(在线交易)场景中TPS是度量数据库性能的关键指标。相信所有Oracle DBA都对“log file sync”和“log parallel wirte”两个等待事件极为熟悉,基于实践“log file sync”延时超过3ms,访问数据库的应用就会觉得”慢“。固态盘(SSD)简单粗暴的大幅度降低log写入延时。当时写入放大(Write Amplification,简称WA)和垃圾回收(Garbage Collection,简称GC)的问题还比较明显,甚至连SSD写入寿命的监控接口都还没有,但是大家都意识到对于数据库而言这是革命性的技术变革。也有人早早做出判断SSD是近10年数据库(当时多指关系型数据库)领域大的技术革命。
这个阶段的明显特点就是”拿来主义“。Infiniband 和 SSD并不需要针对数据库做优化就可以获得显著收益。
简单定制
任何软件技术都很难脱离硬件技术凭空臆想,关系型数据库理论诞生于60年代末70年代初,其设计思路受限于当时的磁盘技术。
仅以 MySQL 数据持久化中的一个场景展开。MySQL 实例会将内存中的脏数据(被修改过)以数据页为单位写入磁盘持久化。一个数据页的大小是16KB,假设写入2KB时服务器异常掉电,这时数据页的前2KB已被更新,剩下的14KB还未被更新,那么该数据页因为部分写(partial write)问题被写坏。而 MySQL redo log 不能修复此类坏数据页,导致数据丢失。
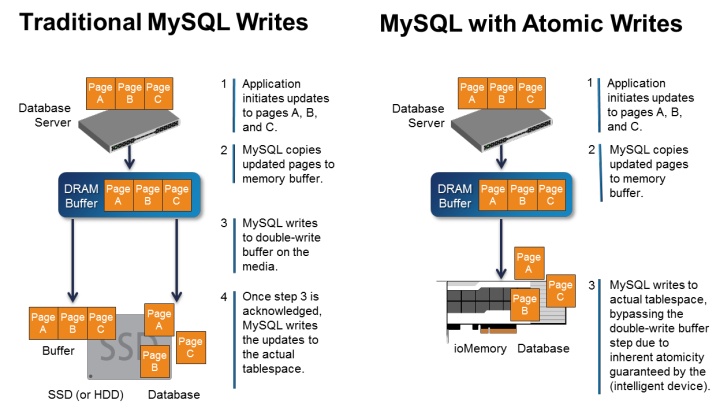
受限于机械磁盘只能提供512B的原子写(Atomic Write),Innodb Engine 通过 Double Write 机制解决该问题,副作用也很明显,不仅增加存储引擎代码复杂度,也引入额外的磁盘写入压力,让宝贵的存储资源(IOPS)更加紧张。
如果MySQL依赖的存储介质可以提供可配置写入大小的原子写(Atomic Write),可以直接关闭Double Write,这会在以下几个方面带来巨大收益:
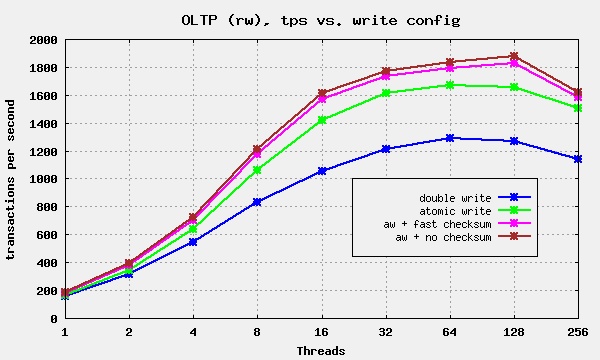
- 直接提升TPS,以 MariaDB(MySQL 分支) 为例.关闭 Double Write 能带来30%左右的提升,如下图所示:
- 简化写入链路也间接优化实例恢复逻辑,如下图所示:
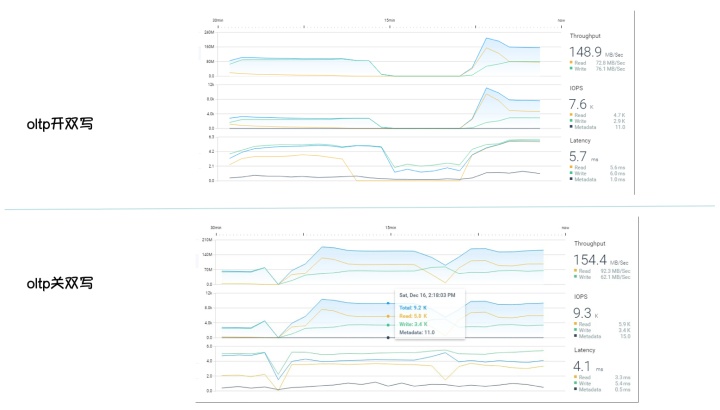
- 在计算存储分离的部署架构下,显著降低计算节点和存储节点的数据交互,在TPS提升11%,QPS提升28%的情况下,网络吞吐仅增加3.6%。(底层存储使用Elasticfile,目前已经被Google收购)
有实力的硬件厂商已经陆续提供大页的原子写(Atomic Write)特性,比如Intel、Sandisk和Scaleflux。留心的读者应该可能已经发现,一些公有云RDS厂商在使用具备该特性的硬件后,已经默认关闭Double Write功能。
相比“拿来”阶段,硬件厂商更懂数据库,不过依然是没有跳出“传统”的存储认知范畴。
摩尔定律失效
这里跑题说一下摩尔定律,2016年2月9号的全球知名的学术刊物《自然》杂志的《The chips are down for Moore’s law》写到即将出版的国际半导体技术路线图不再以摩尔定律(Moore’s law)为目标,芯片行业50年的神话终被打破。
这意味软件不再享受18个月一次的CPU算力倍增的订阅服务,也意味着CPU算力更加珍贵。
基于异构计算的软硬件一体化设计
2017 年图灵奖获得者John L. Hennessy and David A. Patterson在他们的文章《A New Golden Age for Computer Architecture》中给出答案
As the focus of innovation in architecture shifts from the general-purpose CPU to domain-specific and heterogeneous processors, we will need to achieve major breakthroughs in design time and cost。
比如在机器学习领域使用GPU替代CPU进行大规模的矩阵运算,论文《POLARDB Meets Computational Storage: Efficiently Support Analytical Workloads in Cloud-Native Relational Database》也在数据库领域做出呼应。如论文中所述:
Table scan over row-store data does not fit well to modern CPU architecture and tends to largely under-utilize CPU hardware resources。
OLAP场景中的表扫描(Table scan)对CPU并不友好,POLARDB将表扫描下推(pushdown)到具有计算能力(基于FPGA)的存储介质,论文中又叫近存储计算(Computational Storage),如下图所示:
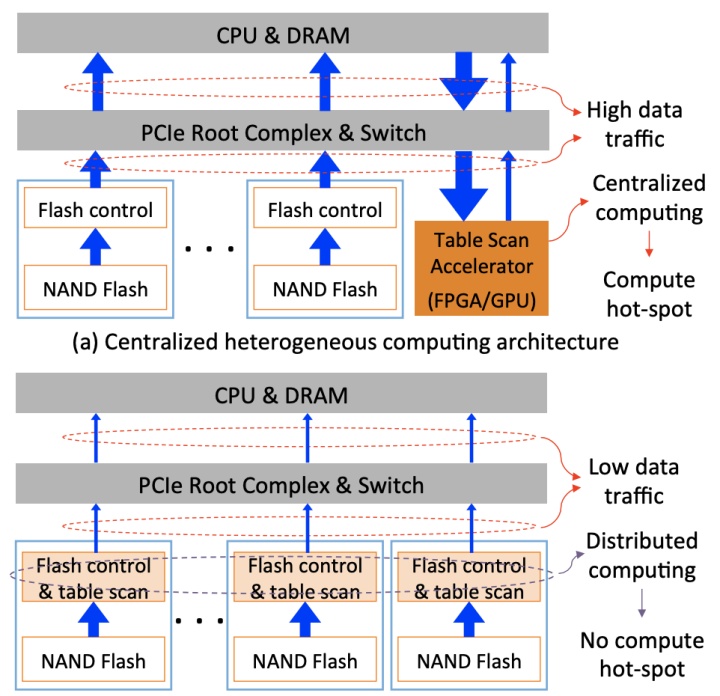
更多细节请移步论文《POLARDB Meets Computational Storage: Efficiently Support Analytical Workloads in Cloud-Native Relational Database》。Scaleflux 首席科学家张彤教授也在FAST 2020上做了专题演讲,感兴趣的读者也应该一并阅读。
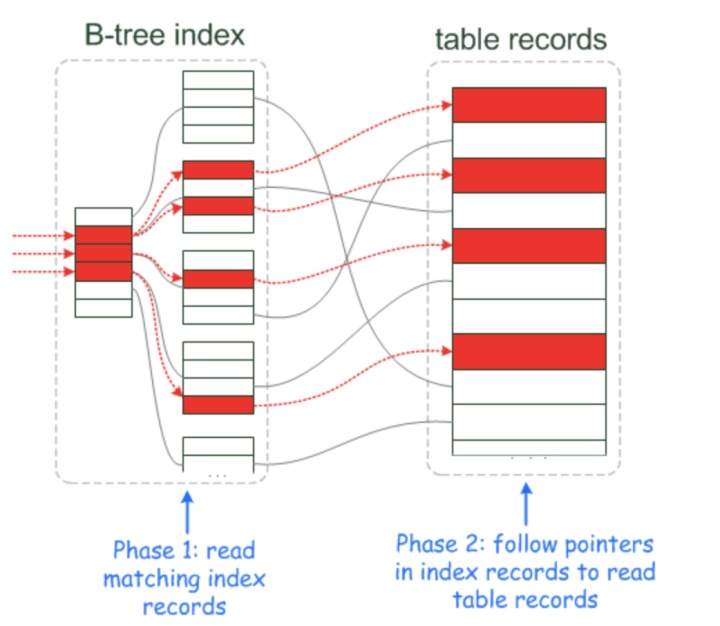
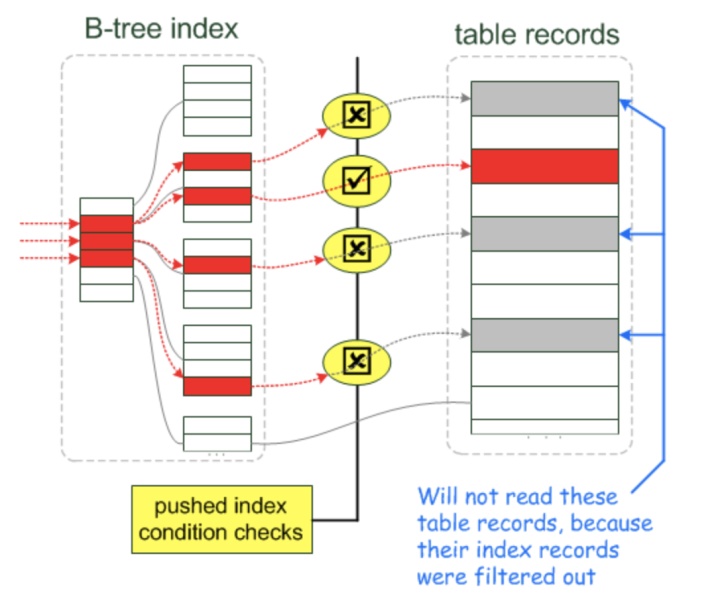
表扫描(Table scan)下推对 MySQL DBA并不陌生,MySQL 5.6 推出 Index Condition Pushdown(简称ICP)特性。未启用ICP特性时,会按照个索引条件列到存储引擎查找数据,并把整行数据提取到实例层,实例层再根据Where后其他的条件过滤数据行。启用ICP特性后,如果Where条件中同时包含检索列和过滤列,且这些列上创建了一个多列索引的情况下,那么实例层会把这些过滤列同时下推到存储引擎层,在存储引擎层过滤掉不满足的数据,只读取并返回需要的数据,减少存储引擎层和实例层之间的数据传输和回表请求,通常情况下可以大幅提升查询效率。下图可以很直观的看到ICP启用前后的数据链路:
- 关闭 ICP
- 启用 ICP
试想,如果把类似“Index Condition Pushdown”的工作下推(pushdown)给具备计算能力的存储介质,会不会得到类似POLARDB的收益呢?
在过去,只有Oracle才具备软硬一体化设计的实力。Exadata 无疑是一体化设计的先驱,其吸纳大量”异构“硬件,其在10年前就引入PCIe SSD(又叫Flash),还在 X4 版本推出基于PCIe SSD的”透明“压缩(Exadata Flash Cache Compression),试图在易用、成本和性能三者之中找到完美平衡,功能描述如下:
Flash cache compression dynamically increases the logical capacity of the flash cache by transparently compressing user data as it is loaded into the flash cache. This allows much more data to be kept in flash, and decreases the need to access data on disk drives.
虽然该特性既不足够透明也不便宜,但足见其软硬通吃的野心。
开始的结束
历经50年的发展,海量的公司和研发在关系型数据库上构建无数的关键应用,朝夕相处让他们对数据库的痛点如数家珍,而这些痛点在传递到硬件厂商的过程中严重衰减,即便融合也是极少数巨头秘而不宣的独门秘籍。POLARDB无疑在异构计算和数据库搭建一座更多人可以经过的桥梁,借用丘吉尔的名言,相信这仅仅只是”开始的结束“。
Now this is not the end. it is not even the beginning of the end. but it is perhaps the end of the beginning。
