导读
背景

TextCNN

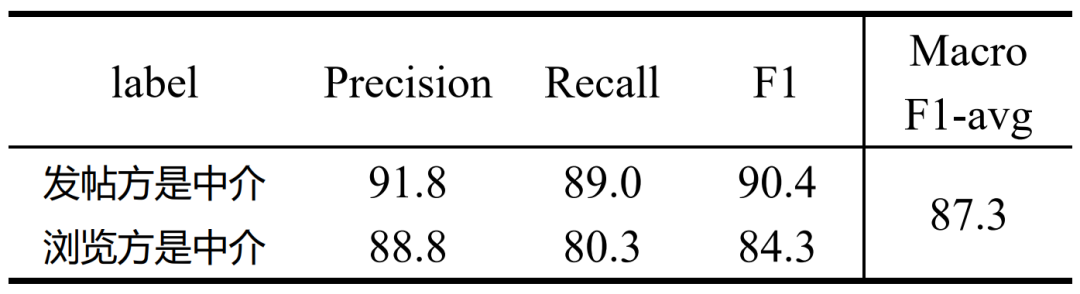



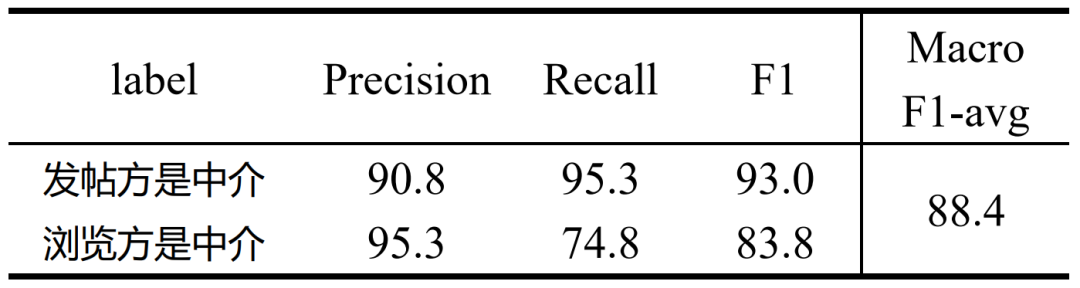
RoBERTa

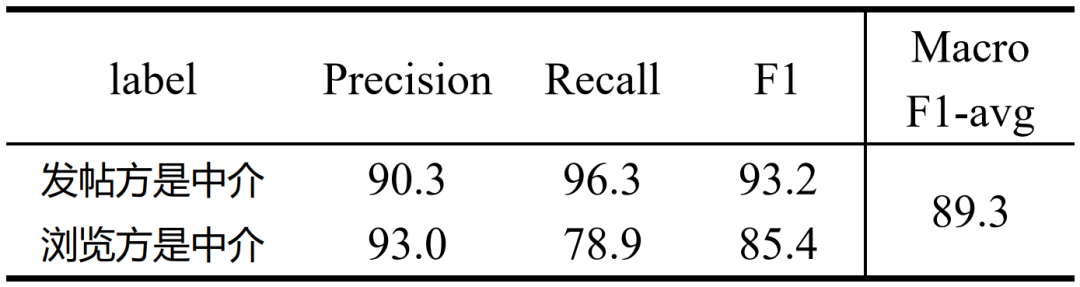
RoBERTa-58Dialog
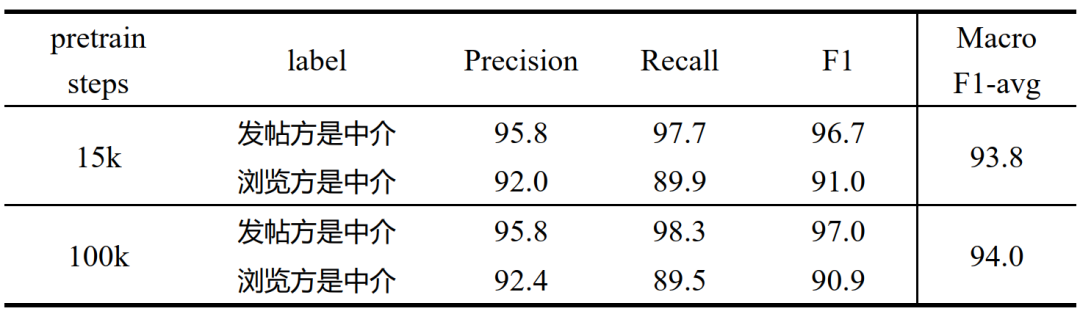
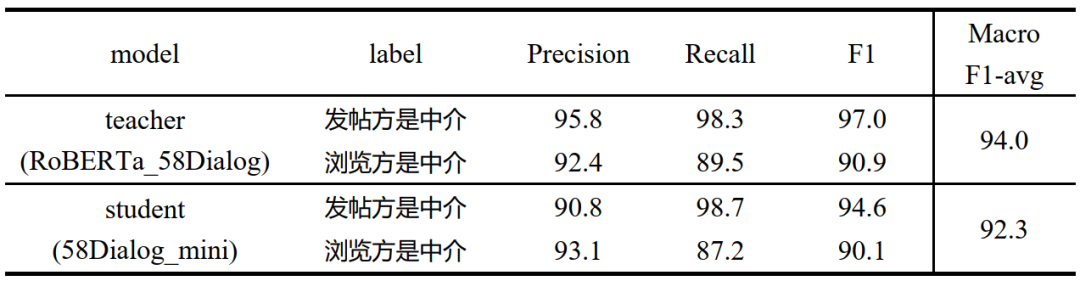
58Dialog-mini
总结与展望

基础模型层面,尝试ALBERT[8]、ELECTRA[9]等更多类型的预训练模型; DAPT+TAPT阶段,尝试添加更多、更高质量的数据,目前来看这部分潜力还未挖掘完全; 知识蒸馏阶段,尝试优化训练目标、调整模型结构、选择多种初始化方式等,尽可能保留模型业务精度的同时加快模型推理速度。
导读
背景
TextCNN
RoBERTa
RoBERTa-58Dialog
58Dialog-mini
总结与展望
分享这个小栈给你的朋友们,一起进步吧。
• 所有用户可根据关注领域订阅专区或所有专区
• 付费订阅:虚拟交易,一经交易不退款;若特殊情况,可3日内客服咨询
• 专区发布评论属默认订阅所评论专区(除付费小栈外)
