来源 | OSCHINA 社区
作者 | 京东云开发者-京东零售 王雷
原文链接:https://my.oschina.net/u/4090830/blog/7091588背景
云原生下的流水线是通过启动容器来运行具体的功能步骤,每次运行流水线可能会被调度到不同的计算节点上。这会导致一个问题:容器运行完是不会保存数据的,每当流水线重新运行时,又会重新拉取代码、编译代码、下载依赖包等等。在云原生场景下,不存在本地宿主机编译代码、构建镜像时缓存的作用,大大延长了流水线运行时间,浪费很多不必要的时间、网络和计算成本。在许多流水线场景中,同一条流水线的多次执行之间是有关联的。如果能够用到上一次的执行结果,则可以大幅缩短执行时间。为了提高用户使用流水线的体验,我们加入支持缓存的功能,挂接远程储存管理构建缓存,可以实现同一个项目的编译依赖复用,在同一条流水线的多次运行中,共享同一份缓存。目标
通过实现云原生流水线的缓存技术,实现代码编译的缓存复用,平均加速流水线 3~5 倍;实现方案
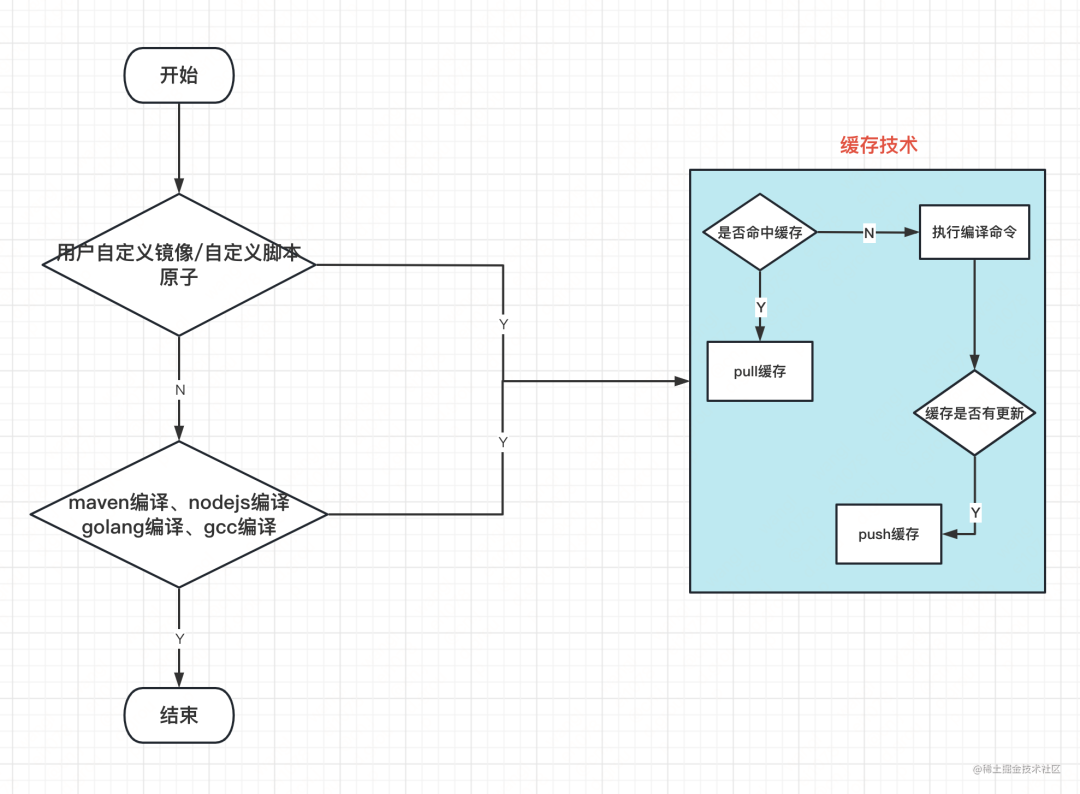
我们将需要进行缓存的文件,使用 zstd 的方式进行压缩,通过远程挂载 cfs,将构建的缓存持久化到 cfs 上的指定位置。当下一次构建开始的时候,判断缓存是否被命中,如果命中缓存,我们从 cfs 上的指定位置 pull 对应的缓存压缩包,解压到相应目录下。所用工具 - cfs+zstd
非用户自定义镜像,将需要的工具打到引擎的基础镜像中,作为所有镜像的基础工具。用户自定义镜像,不和用户镜像进行强绑定,如果需要使用缓存功能,可以使用 Restore 缓存原子和 Save 缓存原子,设置缓存 key 和缓存目录,实现缓存功能。1 cfs 远程挂载
_, err = c.ScriptAction.Sh([]string{
"sh",
"-c",
"modprobe fuse;cd /export/servers/tools/cfs;sudo ./cfs-client-randomwrite -c fuse.json",
})
2 zstd 压缩
针对现有的几种压缩方式进行了性能对比,后选用了 zstd 进行压缩。Zstd,全称 Zstandard,是 Facebook 于 2016 年开源的新无损压缩算法。Zstd 还可以以压缩速度为代价提供更强的压缩比,速度与压缩率的比重可通过增量进行配置。与 zlib、lz4、xz 等当前流行的压缩算法不同,Zstd 寻求一种压缩性能与压缩率通吃的方案,而实际上它也确实做到了。在由官方所列出的表格中,可以看到,Zstd 不仅具备的压缩性能,在压缩率上也有非常亮眼的表现。在过去的两年里,Linux 内核、HTTP 协议、以及一系列的大数据工具(包括 Hadoop 3.0.0,HBase 2.0.0,Spark 2.3.0,Kafka 2.1.0)等都已经加入了对 zstd 的支持。
缓存的实现
我们借鉴了 github cache action,zadig,gitlab 等缓存的处理方式,同时结合服务自身的特点・检查是否命中缓存:根据缓存 key,判断缓存是否命中
|
|
|
根据下载代码的代码库地址自动获取 设置的缓存 key:home_auth/home-auth-center |
|
|
当缓存命中后,根据缓存路径,找到挂载到 cfs 上的缓存压缩包,解压到指定的缓存目录下・push 缓存:将依赖包进行压缩,放到 cfs 的挂载目录下
缓存的使用限制和回收策略
使用限制
目前存储缓存数没有限制,存储库中所有缓存的总大小限制是根据申请的 cfs 的大小限制:20G。回收策略
我们会删除 7 天内未被访问的任何缓存。利用 etcd 的 watch 机制,实现缓存的回收。etcd 可以 Watch 指定的键、前缀目录的更改,并对更改时间进行通知。BASE 引擎中,缓存的清除策略借助 etcd 来实现。缓存过期策略:在编译加速的实现中,每个需要缓存的项目都有对应的缓存 key,通过 etcd 监控 key,并且设置过期时间,例如 7 天,如果在 7 天之内再次命中 key,则通过 lease 进行续约;7 天之内 key 都没有被使用,key 就会过期删除,通过监听对应的前缀,在过期删除的时候,调用删除缓存的方法。storage.Watch("cache/",
func(id string) {
//do nothing
},
func(id string) {
CleanCache(id)
})
我们创建了一个高质量的技术交流群,与的人在一起,自己也会起来,赶紧点击加群,享受一起成长的快乐。
不同技术栈的佳实践
1 Java
以 Maven 构建工具为例,其默认配置文件位于 conf/settings.xml 文件中,默认指定环境变量 $M2_HOME 来设置缓存目录,这样同一条流水线多次执行可以复用 ${M2_HOME}/.m2 目录 (缓存目录),甚至同一个应用下的多个分支之间都可以使用同一个缓存目录,就像本地构建一样。
2 NodeJs
在 nodejs 编译中,我们的缓存目录是当前用户空间,针对 node_modules 文件进行压缩打包,push 到 cfs;如果缓存命中,从 cfs 上 pull 并且解压到当前用户空间下,恢复缓存。使用举例
3 Golang 编译
Golang 缓存路径通过 $GOCACHE 环境变量控制,将 $GOCACHE 的内容压缩成 zstd 的包,上传到 cfs 的指定路径下。pull 缓存的时候,拉取到对应的 $GOCACHE。
4 GCC 编译
我们使用 ccache 进行缓存实现。ccache(“compilercache” 的缩写)是一个编译器缓存,该工具会高速缓存编译生成的信息,并在编译的特定部分使用高速缓存的信息。ccache 的缓存目录:CCACHE_DIR,我们将这个目录下的文件进行压缩,push 到 cfs,当第二次运行并且命中缓存,从 cfs 上 pull 并解压到 CCACHE_DIR 指定的目录下。总结
在不同语言的编译原子内部,默认开启缓存的设置。次运行流水线的时候,会进行依赖的下载,第二次运行流水线,会命中缓存,无需进行依赖的下载,提高了流水线执行的效率。缓存默认保存 7 天。自定义镜像进行缓存的佳实践
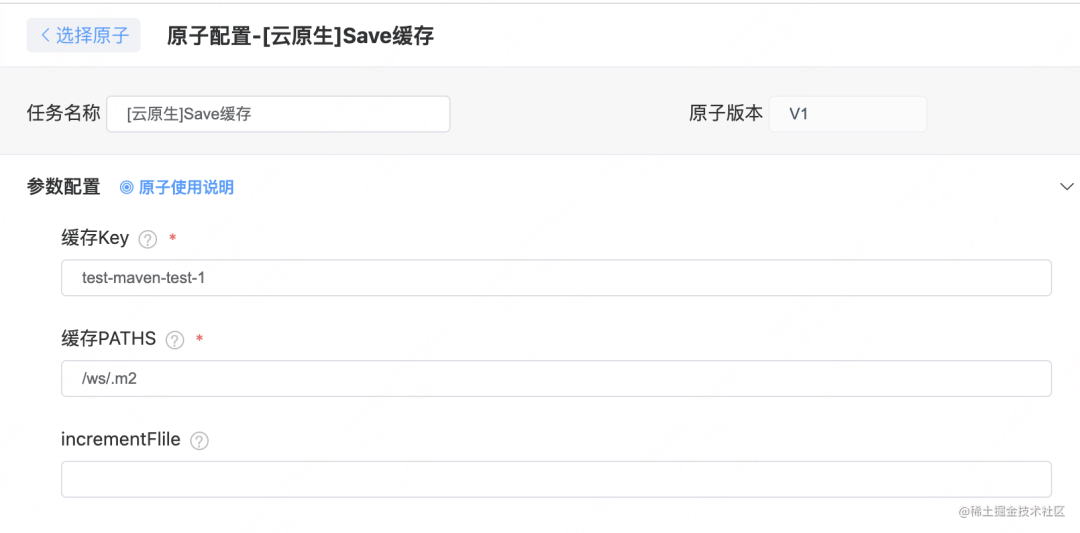
为了满足用户使用自定义镜像的方式触发流水线,我们增加了两个通用的缓存原子。使用举例
在 maven 编译原子中,默认开启了 maven 编译的缓存;同时还有 nodejs 的编译构建,所以我们增加了 restore 原子和 save 原子
|
|
|
平均时间:21min57s 其中 maven: 17min83s nodejs: 4min19s |
|
平均时间:4min20s 其中 maven: 1min10s nodejs: 2min36s |
|
maven:93.7% nodejs:39.8%(nodejs 编译中有包含单元测试) |
|
|
未来规划
・不同编译原子,向用户开放配置,如是否开启缓存,设置缓存 key