我曾经对自己的小弟说,如果你实在搞不清楚什么时候用HashMap,什么时候用ConcurrentHashMap,那么就用后者,你的代码bug会很少。
他问我:ConcurrentHashMap是什么? -.-
编程不是炫技。大多数情况下,怎么把代码写简单,才是能力。
多线程生来就是复杂的,也是容易出错的。一些难以理解的概念,要规避。本文不讲基础知识,因为你手里就有jdk的源码。
线程
Thread
类就是Thread类。大家都知道有两种实现方式。可以继承Thread覆盖它的run方法;第二种是实现Runnable接口,实现它的run方法;而第三种创建线程的方法,就是通过线程池。
我们的具体代码实现,就放在run方法中。
我们关注两种情况。一个是线程退出条件,一个是异常处理情况。
线程退出
有的run方法执行完成后,线程就会退出。但有的run方法是永远不会结束的。结束一个线程肯定不是通过Thread.stop()方法,这个方法已经在java1.2版本就废弃了。所以我们大体有两种方式控制线程。
定义退出标志放在while中
代码一般长这样。
private volatile boolean flag= true;
public void run() {
while (flag) {
}
}
复制代码标志一般使用volatile进行修饰,使其读可见,然后通过设置这个值来控制线程的运行,这已经成了约定俗成的套路。
使用interrupt方法终止线程
类似这种。
while(!isInterrupted()){……}
复制代码对于InterruptedException,比如Thread.sleep所抛出的,我们一般是补获它,然后静悄悄的忽略。中断允许一个可取消任务来清理正在进行的工作,然后通知其他任务它要被取消,后才终止,在这种情况下,此类异常需要被仔细处理。
interrupt方法不一定会真正”中断”线程,它只是一种协作机制。interrupt方法通常不能中断一些处于阻塞状态的I/O操作。比如写文件,或者socket传输等。这种情况,需要同时调用正在阻塞操作的close方法,才能够正常退出。
interrupt系列使用时候一定要注意,会引入bug,甚至死锁。
异常处理
java中会抛出两种异常。一种是必须要捕获的,比如InterruptedException,否则无法通过编译;另外一种是可以处理也可以不处理的,比如NullPointerException等。
在我们的任务运行中,很有可能抛出这两种异常。对于种异常,是必须放在try,catch中的。但第二种异常如果不去处理的话,会影响任务的正常运行。
有很多同学在处理循环的任务时,没有捕获一些隐式的异常,造成任务在遇到异常的情况下,并不能继续执行下去。如果不能确定异常的种类,可以直接捕获Exception或者更通用的Throwable。
while(!isInterrupted()){
try{
……
}catch(Exception ex){
……
}
}
复制代码同步方式
java中实现同步的方式有很多,大体分为以下几种。
-
synchronized关键字 - wait、notify等
- Concurrent包中的
ReentrantLock -
volatile关键字 - ThreadLocal局部变量
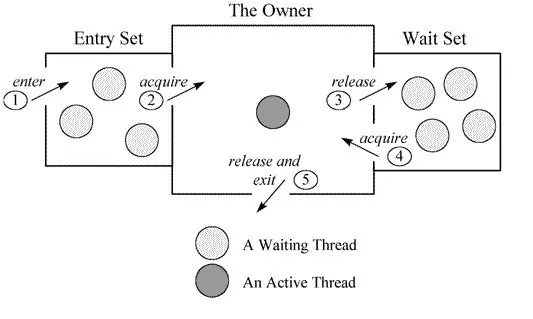
生产者、消费者是wait、notify典型的应用场景,这些函数的调用,是必须要放在synchronized代码块里才能够正常运行的。它们同信号量一样,大多数情况下属于炫技,对代码的可读性影响较大,不推荐。关于ObjectMonitor相关的几个函数,只要搞懂下面的图,就基本ok了。
使用ReentrantLock容易发生错误的就是忘记在finally代码块里关闭锁。大多数同步场景下,使用Lock就足够了,而且它还有读写锁的概念进行粒度上的控制。我们一般都使用非公平锁,让任务自由竞争。非公平锁性能高于公平锁性能,非公平锁能更充分的利用cpu的时间片,尽量的减少cpu空闲的状态时间。非公平锁还会造成饿死现象:有些任务一直获取不到锁。
synchronized通过锁升级机制,速度不见得就比lock慢。而且,通过jstack,能够方便的看到其堆栈,使用还是比较广泛。
volatile总是能保证变量的读可见,但它的目标是基本类型和它锁的基本对象。假如是它修饰的是集合类,比如Map,那么它保证的读可见是map的引用,而不是map对象,这点一定要注意。
synchronized和volatile都体现在字节码上(monitorenter、monitorexit),主要是加入了内存屏障。而Lock,是纯粹的java api。
ThreadLocal很方便,每个线程一份数据,也很安全,但要注意内存泄露。假如线程存活时间长,我们要保证每次使用完ThreadLocal,都调用它的remove()方法(具体来说是expungeStaleEntry),来清除数据。
关于Concurrent包
concurrent包是在AQS的基础上搭建起来的,AQS提供了一种实现阻塞锁和一系列依赖FIFO等待队列的同步器的框架。
线程池
全的线程池大概有7个参数,想要合理使用线程池,肯定不会不会放过这些参数的优化。
线程池参数
concurrent包常用的就是线程池,平常工作建议直接使用线程池,Thread类就可以降低优先级了。我们常用的主要有newSingleThreadExecutor、newFixedThreadPool、newCachedThreadPool、调度等,使用Executors工厂类创建。
newSingleThreadExecutor可以用于快速创建一个异步线程,非常方便。而newCachedThreadPool永远不要用在高并发的线上环境,它用的是无界队列对任务进行缓冲,可能会挤爆你的内存。
我习惯性自定义ThreadPoolExecutor,也就是参数全的那个。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
复制代码假如我的任务可以预估,corePoolSize,maximumPoolSize一般都设成一样大的,然后存活时间设的特别的长。可以避免线程频繁创建、关闭的开销。I/O密集型和CPU密集型的应用线程开的大小是不一样的,一般I/O密集型的应用线程就可以开的多一些。
threadFactory我一般也会定义一个,主要是给线程们起一个名字。这样,在使用jstack等一些工具的时候,能够直观的看到我所创建的线程。
监控
高并发下的线程池,好能够监控起来。可以使用日志、存储等方式保存下来,对后续的问题排查帮助很大。
通常,可以通过继承ThreadPoolExecutor,覆盖beforeExecute、afterExecute、terminated方法,达到对线程行为的控制和监控。
线程池饱和策略
容易被遗忘的可能就是线程的饱和策略了。也就是线程和缓冲队列的空间全部用完了,新加入的任务将如何处置。jdk默认实现了4种策略,默认实现的是AbortPolicy,也就是直接抛出异常。下面介绍其他几种。
DiscardPolicy 比abort更加激进,直接丢掉任务,连异常信息都没有。
CallerRunsPolicy 由调用的线程来处理这个任务。比如一个web应用中,线程池资源占满后,新进的任务将会在tomcat线程中运行。这种方式能够延缓部分任务的执行压力,但在更多情况下,会直接阻塞主线程的运行。
DiscardOldestPolicy 丢弃队列前面的任务,然后重新尝试执行任务(重复此过程)。
很多情况下,这些饱和策略可能并不能满足你的需求,你可以自定义自己的策略,比如将任务持久化到一些存储中。
阻塞队列
阻塞队列会对当前的线程进行阻塞。当队列中有元素后,被阻塞的线程会自动被唤醒,这极大的提高的编码的灵活性,非常方便。在并发编程中,一般推荐使用阻塞队列,这样实现可以尽量地避免程序出现意外的错误。阻塞队列使用经典的场景就是socket数据的读取、解析,读数据的线程不断将数据放入队列,解析线程不断从队列取数据进行处理。
ArrayBlockingQueue对访问者的调用默认是不公平的,我们可以通过设置构造方法参数将其改成公平阻塞队列。
LinkedBlockingQueue队列的默认大长度为Integer.MAX_VALUE,这在用做线程池队列的时候,会比较危险。
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。队列本身不存储任何元素,吞吐量非常高。对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务”。它更像是一个管道,在一些通讯框架中(比如rpc),通常用来快速处理某个请求,应用较为广泛。
DelayQueue是一个支持延时获取元素的无界阻塞队列。放入DelayQueue的对象需要实现Delayed接口,主要是提供一个延迟的时间,以及用于延迟队列内部比较排序。这种方式通常能够比大多数非阻塞的while循环更加节省cpu资源。
另外还有PriorityBlockingQueue和LinkedTransferQueue等,根据字面意思就能猜测它的用途。在线程池的构造参数中,我们使用的队列,一定要注意其特性和边界。比如,即使是简单的newFixedThreadPool,在某些场景下,也是不安全的,因为它使用了无界队列。
CountDownLatch
假如有一堆接口A-Y,每个接口的耗时大是200ms,小是100ms。
我的一个服务,需要提供一个接口Z,调用A-Y接口对结果进行聚合。接口的调用没有顺序需求,接口Z如何在300ms内返回这些数据?
此类问题典型的还有赛马问题,只有通过并行计算才能完成问题。归结起来可以分为两类:
- 实现任务的并行性
- 开始执行前等待n个线程完成任务
在concurrent包出现之前,需要手工的编写这些同步过程,非常复杂。现在就可以使用CountDownLatch和CyclicBarrier进行便捷的编码。
CountDownLatch是通过一个计数器来实现的,计数器的初始值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就会减1。当计数器值到达0时,它表示所有的线程已经完成了任务,然后在闭锁上等待的线程就可以恢复执行任务。 CyclicBarrier与其类似,可以实现同样的功能。不过在日常的工作中,使用CountDownLatch会更频繁一些。
信号量
Semaphore虽然有一些应用场景,但大部分属于炫技,在编码中应该尽量少用。
信号量可以实现限流的功能,但它只是常用限流方式的一种。其他两种是漏桶算法、令牌桶算法。
hystrix的熔断功能,也有使用信号量进行资源的控制。
Lock && Condition
在Java中,对于Lock和Condition可以理解为对传统的synchronized和wait/notify机制的替代。concurrent包中的许多阻塞队列,就是使用Condition实现的。
但这些类和函数对于初码农来说,难以理解,容易产生bug,应该在业务代码中严格禁止。但在网络编程、或者一些框架类工程中,这些功能是必须的,万不可将这部分的工作随便分配给某个小弟。
End
不管是wait、notify,还是同步关键字或者锁,能不用就不用,因为它们会引发程序的复杂性。好的方式,是直接使用concurrent包所提供的机制,来规避一些编码方面的问题。
concurrent包中的CAS概念,在一定程度上算是无锁的一种实现。更专业的有类似disruptor的无锁队列框架,但它依然是建立在CAS的编程模型上的。近些年,类似AKKA这样的事件驱动模型正在走红,但编程模型简单,不代表实现简单,背后的工作依然需要多线程去协调。
golang引入协程(coroutine)概念以后,对多线程加入了更加轻量级的补充。java中可以通过javaagent技术加载quasar补充一些功能,但我觉得你不会为了这丁点效率去牺牲编码的可读性。

