在扩展集群前,需要对DolphinDB集群有基本的概念。DolphinDB集群由3个角色组成:控制节点(Controller)、代理节点(Agent)和数据节点(Data Node)。每个角色任务分配如下:
- 控制节点负责管理元数据,提供Web集群管理工具。
- 代理节点负责节点的启动和停止,每台服务器上必须有一个代理节点。
- 数据节点负责计算和存储。
与集群相关的配置文件,一般位于config目录下:
controller.cfg:位于控制节点所在的服务器,负责定义控制节点的相关配置,如IP、端口号、控制节点连接数上限等。
cluster.cfg:位于控制节点所在的服务器,负责定义集群内每一个节点的个性化配置,如存储路径、连接数、内存限制等。
cluster.nodes:位于控制节点所在的服务器,集群的成员配置文件,包含节点的IP、端口、节点别名和角色。
agent.cfg:包含代理节点的IP、端口和控制节点的IP和端口。每个物理服务器必须有一个代理节点。
如果是水平扩展集群,需要修改集群的成员配置文件(cluster.nodes),如果数据节点位于新的物理服务器上,那么还需要部署一个新的代理节点(agent.cfg)来负责新物理机上节点的启停,然后重启控制节点来加载新的数据节点。当新的数据节点启动后,节点的计算能力会即时纳入集群的计算资源统筹,但是已经存储在集群中的数据不会调整到新的数据节点,系统会将后续新进入的数据按策略分配到各个数据节点。
如果是垂直扩展集群,只需要修改数据节点的配置文件(cluster.cfg),为指定节点的volumes参数增加路径。
下面将详细介绍扩展集群的步骤。
1. 集群配置说明
集群部署可以参考教程多物理服务器集群部署。
示例集群有3个数据节点,每个数据节点位于一台物理服务器上,控制节点位于另外一台物理服务器上:
控制节点:172.18.0.10
数据节点1:172.18.0.11
数据节点2:172.18.0.12
数据节点3:172.18.0.13
各个配置文件的信息如下:
controller.cfg
localSite=172.18.0.10:8990:ctl8990cluster.nodes
localSite,mode
172.18.0.11:8701:agent1,agent
172.18.0.12:8701:agent2,agent
172.18.0.13:8701:agent3,agent
172.18.0.11:8801:node1,datanode
172.18.0.12:8802:node2,datanode
172.18.0.13:8803:node3,datanode数据节点1所在物理服务器上的agent.cfg
localSite=172.18.0.11:8701:agent1
controllerSite=172.18.0.10:ctl8900为了体现扩展后的效果,我们首先在集
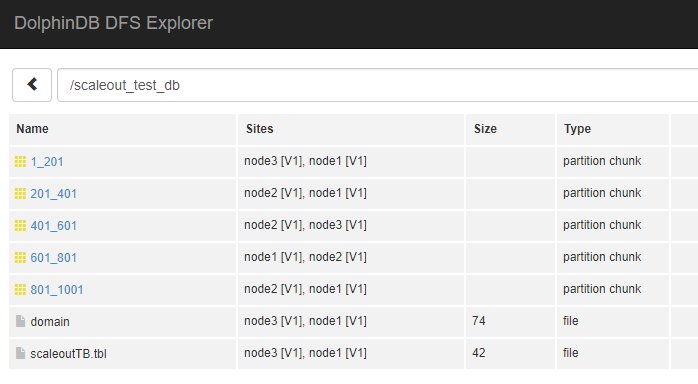
群中创建一个分布式数据库,并写入数据:
data = table(1..1000 as id,rand(`A`B`C,1000) as name)
//分区时预留了1000的余量,预备后续写入测试用
db = database("dfs://scaleout_test_db",RANGE,cutPoints(1..2000,10))
tb = db.createPartitionedTable(data,"scaleoutTB",`id)
tb.append!(data)执行完后通过Web的DFS Explorer观察数据的分布情况:
扩展集群后,我们可以通过追加新的数据来观察新的节点或存储是否启用。
2. 水平扩展
由于业务数据量增大,集群的存储和计算能力不能满足要求,现新增一台服务器,并把它加入原来的集群作为一个新的节点。新增的服务器IP地址为172.18.0.14,采用8804端口号,别名为node4。新增服务器需要部署代理节点,采用8701端口,别名为agent4.
步骤如下:
(1)部署新的代理节点
把DolphinDB的安装包拷贝至新的服务器,并解压。在server文件夹下新增config文件夹,并创建agent.cfg,增加以下内容:
#指定Agent本身的ip和端口
localSite=172.18.0.14:8701:agent4
#告诉Agent本集群的controller位置
controllerSite=172.18.0.10:8990:ctl8990
mode=agent(2)修改集群成员配置
到控制节点所在的物理服务器,修改config/cluster.nodes,新增集群成员信息。修改后的文件内容为:
localSite,mode
172.18.0.11:8701:agent1,agent
172.18.0.12:8701:agent2,agent
172.18.0.13:8701:agent3,agent
172.18.0.14:8701:agent4,agent
172.18.0.11:8801:node1,datanode
172.18.0.12:8802:node2,datanode
172.18.0.13:8803:node3,datanode
172.18.0.14:8804:node4,datanode(3)重启集群
Linux环境下,使用命令pkill dolphindb,关闭集群。等待端口资源释放后,重新启动controller和各个agent,命令如下:
启动controller:
nohup ./dolphindb -console 0 -mode controller -script dolphindb.dos -config config/controller.cfg -logFile log/controller.log -nodesFile config/cluster.nodes &启动agent:
./dolphindb -mode agent -home data -script dolphindb.dos -config config/agent.cfg -logFile log/agent.log在浏览器地址栏中输入控制节点的IP和端口号,如172.18.0.10:8990,来访问Web,我们可以看到新增加的代理节点agent4已经启动,数据节点node4处于关停状态。
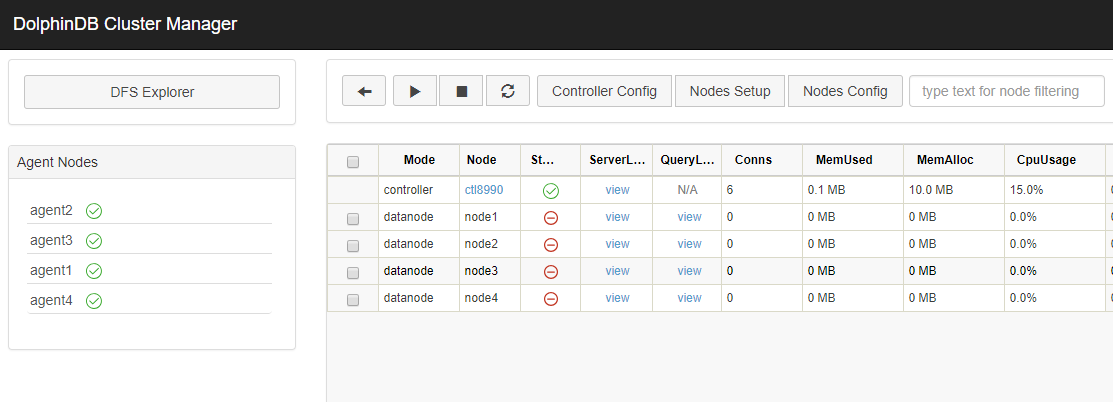
启动各个节点,集群即可正常使用。
下面我们往集群上的数据库dfs://scaleout_test_db写入一些数据,验证新的数据节点是否已经启用。
tb = database("dfs://scaleout_test_db").loadTable("scaleoutTB")
tb.append!(table(1001..1500 as id,rand(`A`B`C,500) as name))观察DFS Explorer,可以看到有数据分布到新的节点node4上。
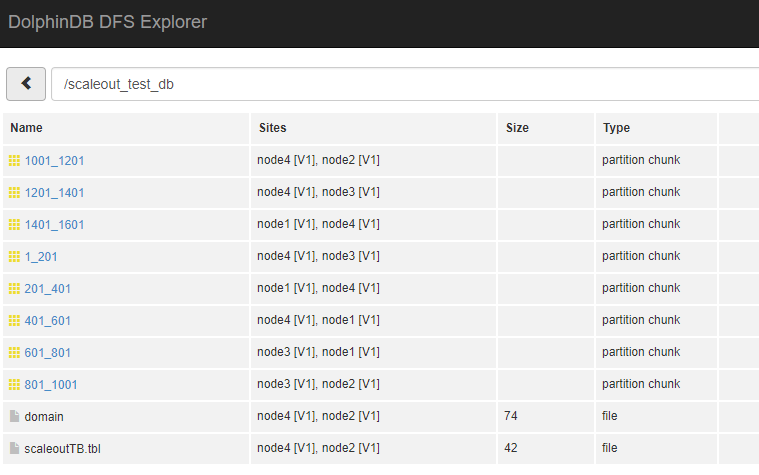
有时候我们会发现,某些数据会迁移到其他节点。这与DolphinDB的recovery机制有关。DolphinDB集群支持数据自动recovery。当系统检测到集群部分节点长时间没有心跳时,判定为宕机,将从其他副本中自动恢复数据并且保持整个集群的副本数稳定。这是当某个节点长时间未启动,数据会发生迁移的原因。DolphinDB的recovery机制和控制节点的以下配置参数有关:
#集群内每个数据副本数,默认2
dfsReplicationFactor=2
#副本安全策略,0 多个副本允许存在一个节点 1 多个副本必须分存到不同节点,默认0
dfsReplicaReliabilityLevel=1
#节点心跳停止多久开启Recovery,默认不启用,单位ms
dfsRecoveryWaitTime=30000dfsRecoveryWaitTime控制recovery的启动,如果没有设置该参数,则关闭recovery功能,默认是关闭状态。等待时间的设置主要是为了避免一些计划内的停机维护导致不必要的recovery,需要用户根据运维的实际情况来设置。
从稳定性上来讲,副本数越多数据越不容易因意外丢失,但是副本数过多也会导致系统保存数据时性能低下,所以dfsReplicationFactor的值不建议低于2,但是具体设置多高需要用户根据整体集群的节点数、数据稳定性需求、系统写入性能需求来综合考虑。
dfsReplicaReliabilityLevel在生产环境下建议设置为1,即多个副本位于不同的服务器上。
3. 垂直扩展
假设node3所在的服务器本身的磁盘空间不足,现增加了一块磁盘,路径为/dev/disk2,需要把它纳入node3的存储。数据节点的存储路径是由配置文件中的volumes参数指定,如果初始集群没有指定volumes参数,那么默认的存储路径为[HomeDir]/DataNodeAlias]/storage,即node3的默认存储路径为data/node3/storage。
在控制节点的cluster.cfg文件中加上以下内容:
node3.volumes=data/node3/storage,/dev/disk2/node3注意,如果需要在默认路径后面添加存储路径,需要显式设置默认路径,否则会造成默认路径下的元数据丢失。
修改配置后,只需要重启数据节点,无需重启控制节点。
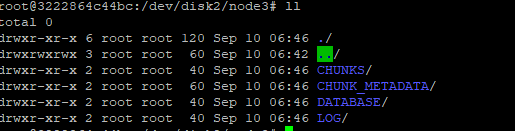
下面往集群写入新的数据,查看数据是否被写入新的磁盘。
tb = database("dfs://scaleout_test_db").loadTable("scaleoutTB")
tb.append!(table(1501..2000 as id,rand(`A`B`C,500) as name))到磁盘上观察数据是否被写入:
DolphinDB能支持的数据规模没有明确的上限,完全取决于投入资源的多少。
欢迎访问官网下载试用
联系邮箱:info@dolphindb.com
来源 https://zhuanlan.zhihu.com/p/51053743
