作者:coredumped,数据库从业者,熟悉 MySQL 及分布式架构,为多家大型国有企业提供过技术支持、咨询、架构设计及培训工作。
OceanBase开源后,也让更多的人能上手尝试一把,那OB与传统的分库分表方案都有哪些区别呢?OB做了哪些增强的地方呢?本文通过从数据安全、资源投入、业务改造、生态等方面做对比。
首先明确的是,这里的对比都是拿商业的分库分表方案与OB做对比,开源的MyCAT由于功能缺失太多,无可比性
个人觉得OB比分库分表方法是有一定优势,但并不是完全的碾压,请看下面这些内容:
架构介绍
分库分表
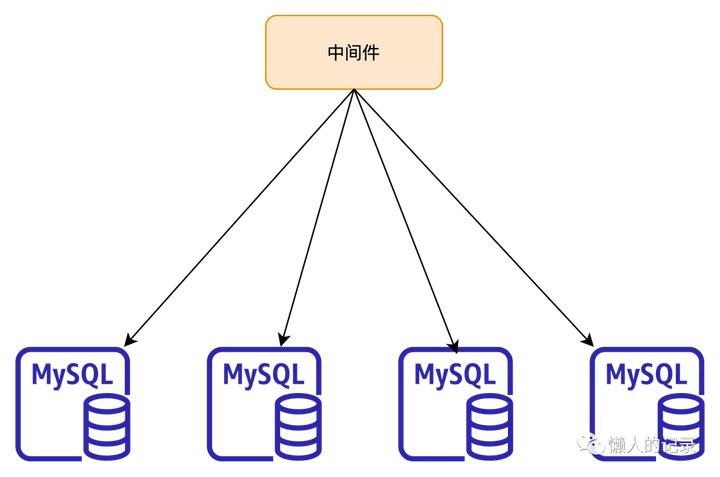
上图是一个典型分库分表方案的示意图,中间件层和数据节点层。
中间件主要作用是做数据的路由,根据分片键将数据打散到不同的数据节点。
数据节点通常就是原生的MySQL(或者PG)数据库,数据库的高可用方案也都是用原生的主从复制实现。
当然分库分表还有一种方式是客户端分库分表,但基本原理和中间件方式相同,这里就不展开说明。
OceanBase
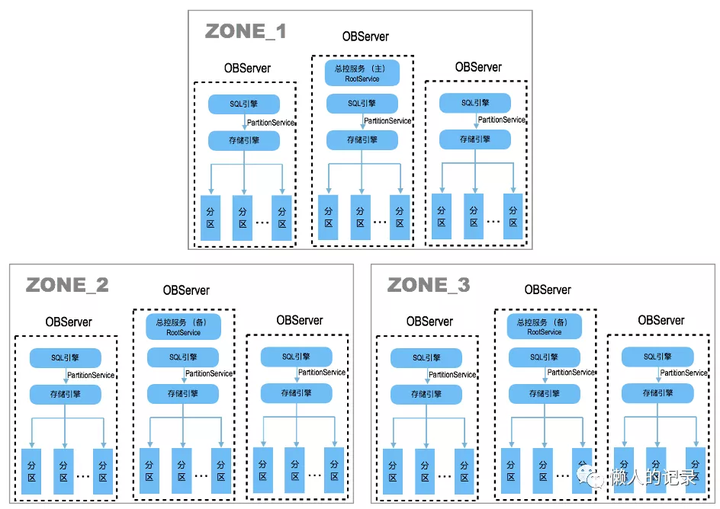
OB架构则与分库分表不同,并没有中间件节点,分布式相关能力都是在数据库中实现。OB的一个集群有多个zone组成,每个zone内可为1-N个OBServer。每个zone都有一份完整的数据副本,zone可以在不同的城市,或者不同的机房,也可以是在同一个机房
OB是原生分布式数据库,从架构上能看出从数据库出发点就是为了分布式而生,这点与分库分表有极大的不同。OB在内核层面实现了分布式能力,例如:数据一致性、全局一致性读、分布式计算、全局索引等,除了这些OB也有一些技术创新
数据安全
单机数据库中ACID中的A与D可以保证事务的原子性与数据的持久性,但在分布式场景下,跨节点的原子性与各节点的数据一致性变得比较复杂,高可用切换后如何保证RPO=0对于金融场景非常重要
数据可靠
数据一致性
分库分表方案底层还是MySQL数据库本身,高可用方案通常也采取的是主备方案,MySQL主备方案中如要保证切换后的数据一致性,通常会遇到以下两种场景:
- 一主多从+半同步 当主库写入数据时,会等待至少有一个从库返回ack信号后,主库才会给引用返回成功,切换时保证了至少有一台从库有和主库一样的数据。在实现起来有两点需要注意:性能、极端情况下的数据回滚
- 由于采用了半同步这种方式,肯定对性能会有一定影响,商业方案中例如TDSQL对复制这块做了修改
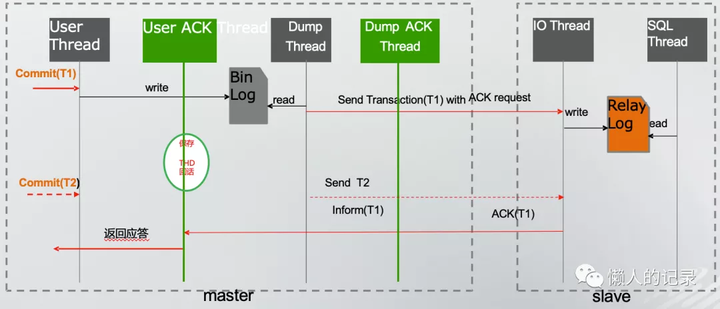
- TDSQL对复制做了优化,增加了线程池和定义了用户线程和工作线程,当日志发送到从库后,工作线程不会向原生半同步一直等待ACK返回,而是将用户线程会话缓存起来,工作线程继续处理别的请求,但这时也不会直接给用户返回commit成功,而是等待ACK返回后再次唤醒之前的线程后,才回给用户返回成功
- 这样做的好处就是提高了系统的处理能力,将之前的同步方式做了异步化。
- 极端情况下数据一致性保障
- MySQL内部有两阶段提交过程,先写binlog并fsync到磁盘上,然后才在innodb redo日志中添加commit标记。在主备环境中会存在下面的问题
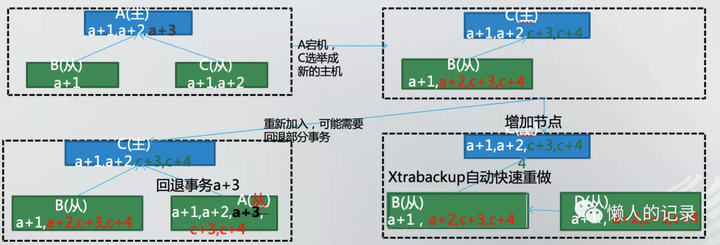
- A作为主时a+3这条记录并没有复制到B,C两台从库上,当A发生故障时选择C作为新主库,这时会在C上产生新的数据c+3,c+4并复制到了B上。
- 当A修复后要加入到集群中时,由于启动时会做Crash Recover发现binlog中有a+3这条记录,所以会把这条记录前滚恢复,这时就出现了不一致现象。
- TDSQL中会将a+3这条记录进行回滚,保证一致性。
再看下OB中数据一致性保障,OB分布式的实现用的是分区表,将不同的分区放置不同zone的OBServer上
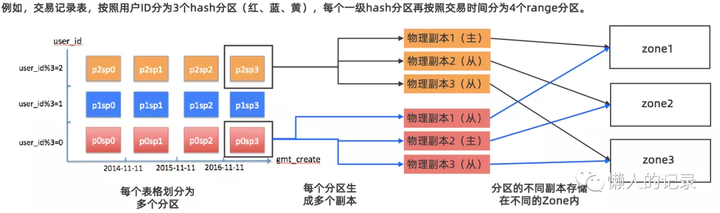
每个分区都有一个主副本,和若干从副本(根据zone的个数决定)
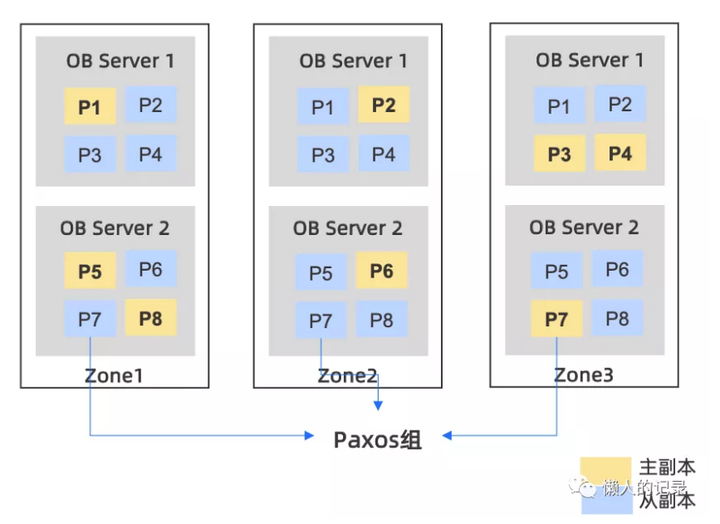
如上图有3个zone,8个分区,每个zone中有两个OBServer,每个分区都有三个副本,分布在不同zone中的OBServer上,OB以分区为小单位组成Paxos组,通过Paxos保证了多副本之间的数据一致性,但Paxos需要多数派提交性能上不一定会比分库分表好。
分布式事务
分布式事务处理上,OB与分库分表方案都采用了两阶段提交的方式,先说下OB。
OB在原生的两阶段提交上做了一定的优化,传统的两阶段提交方式如下:
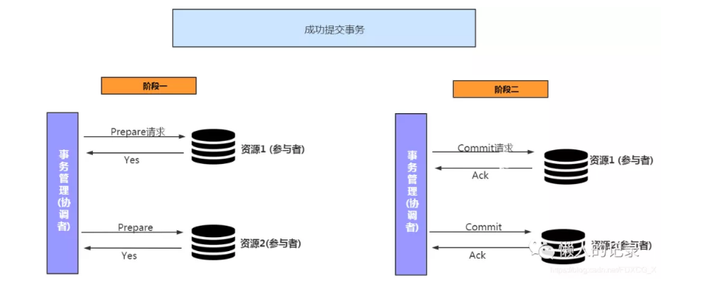
分为两个步骤:
- 协调者向参与者发起prepare请求,参与者执行事务但并不提交
- 协调者根据参与者返回的状态,如果都返回prepare ok,则会发起commit请求
传统两阶段提交方式中,由于协调者会存在宕机情况,会造成事务的阻塞。并且要将协调者信息记录日志,当协调者发生宕机时需要扫描日志中事务状态,决定参与者下一步操作。当然也可以是参与者向新的协调者发送自己的状态,来决定下一步操作。
但还有一个问题就是,协调者发送commit请求后宕机,参与者也同时宕机,这时无法知道事务的终状态,除非参与者有高可用。
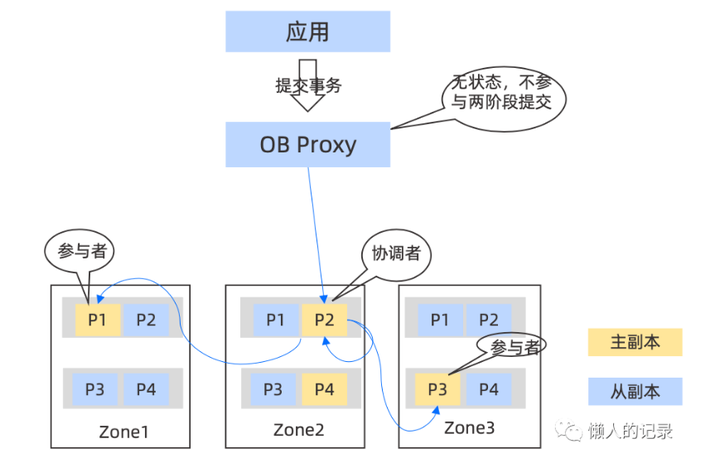
从上图中看到OB中协调者与参与者都是分区并不是Proxy节点,由于所有数据分片都是通过 Paxos 复制日志实现多副本高可用的,当主副本发生宕机后,会由同一数据分片的备副本转换为新的主副本继续提供服务,所以可以认为在 OceanBase 中,参与者和协调者都是保证高可用不宕机的(多数派存活),绕开了协调者宕机的问题。
在参与者高可用的实现前提下,OceanBase 对协调者进行了“无状态”的优化。在标准的两阶段提交中,协调者要通过记录日志的方法持久化自己的状态,否则如果协调者和参与者同时宕机,协调者恢复后可能会导致事务提交状态不一致。但是如果我们认为参与者不会宕机,那么协调者并不需要写日志记录自己的状态。
在协调者不写日志的前提下,协调者如果发生切主或宕机恢复,它并不知道自己之前的状态是什么,参与者发送prepare ok后未收到协调者进一步消息 (commit/abort)时,认为上一条回复消息丢失,会定时 重新发送上一条消息
分库分表方案中协调者是Proxy节点,因为底层还是MySQL如要做到向OB一样参与者能够重新发送消息,需要修改内核代码,所以通常是需要记录日志。通过日志中记录的状态来决定事务的提交和回滚。
容灾方案
其实两种方案都可以做到同城三机房、两地三中心、三地五中心,但OB中对于存储成本做了优化,OB副本集做了三种,分别是:
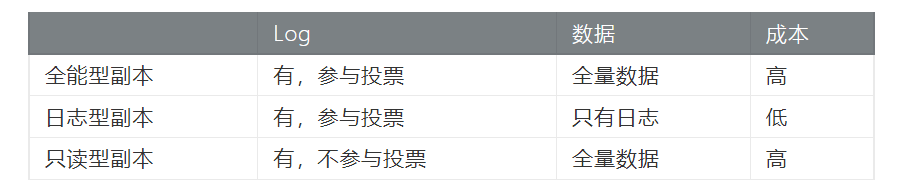
对于三地五中心,其中一个数据中心可以部署日志型副本节省资源
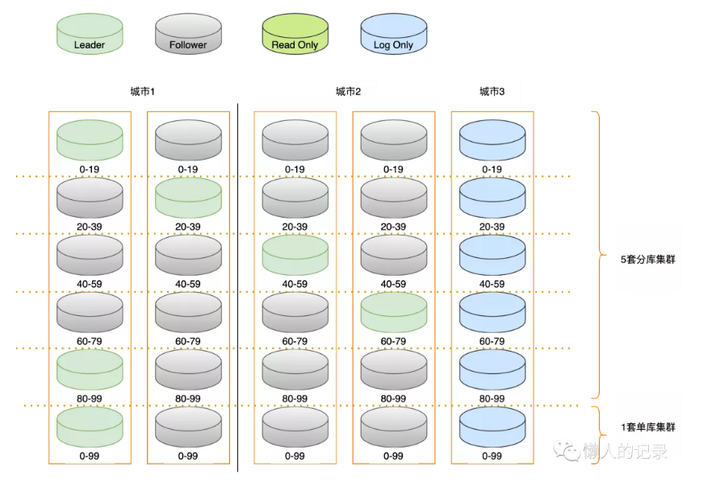
任何一个城市的两个数据中心同时出现故障,集群都可以正常工作,并且城市3使用日志型副本,减少了资源投入
资源投入
- 机器数量:分库分表方案底层多数采用一主两从方式部署,如不考虑单机多实例方式,则需要少6台服务器。OB则可以用3台机器部署一套完整的集群。
- 存储: OB中会有两次压缩,次是 encoding,第二次是通用压缩,通用的压缩算法并不是针对数据库做压缩的,压缩比例有限。encoding能实现更大的压缩比。
业务改造
相对分库分表OB迁移及业务改造会相对较小,其实分库分表与OB都需要考虑分布键的问题:
- 创建表时都需要指定分布键或分区键
- 处于对性能的考虑,查询时尽量都带上分布键或分区键,但OB中有全局索引功能,可在一定程度上加快没带有分区键查询的检索速度
但一些操作需要跨越不同的数据库,比如多表关联的复杂SQL,由于中间件不具备分布式并行计算能力,导致它不能跨 越多台机器协同执行任务。所以,很多分库分表方案会告诉应用开发者一些不支持的 SQL,需要应用通过其他方式解决,影响了应用的迁移和开发,OB的优点在于每个OB Server都是具备分布式查询能力,支持复杂SQL语句。
生态
这点分库分表方案会有一定优势,MySQL市面上技术人员众多,书籍资料都很丰富,配套的工具、自动化都很齐全,并且底层数据库还是MySQL或者PG都是经过长时间的验证的,用户选型时会作为加分项。
OB前几年一直是闭源状态,很少有人能使用上,但OB自从今年开源后推出了一系列培训计划,也是想让更多的人能接触使用到OB,目前看也是加大社区的推广
总结
OB从技术上有自己的创新和相对的先进性,从整体上看OB是原生的分布式数据库架构,从内核设计初始就考虑了分布式当中会遇到的各种问题,并增加了各种技术特性。
OB是完全自主研发、自主可控,无引入开源的存储引擎等模块,不存在开源协议风险等问题。
随着开源和社区的投入现在也有更多的人能接触了解到,未来可期!
