Kubernetes已经成为企业容器平台的标配,在大部分企业,小规模容器平台已经试用了一段时间,然而当容器平台规模大了之后,尤其是用于生产,可能会遇到各种各样的问题,这里我们总结十大问题。
第零节,Kubernetes的架构优势
在讲述生产落地实践之前,我们先概述一下Kubernetes的设计原理,因为后面的很多实践,都是基于对于这些原理的理解。
为什么在众多容器平台中,Kubernetes能够脱颖而出,我个人认为有以下几点。
0.1 Kubernetes的接口和概念设计是完全站在应用角度而非运维角度的
如果站在传统运维人员的角度看 Kubernetes,会觉得他是个奇葩所在,容器还没创建出来,概念先来一大堆,文档先读一大把,编排文件也复杂,组件也多,让很多人望而却步。
但是如果开发人员的角度,尤其是从微服务应用的架构的角度来看Kubernetes,则会发现,他对于微服务的运行生命周期和相应的资源管控,做了非常好的抽象。
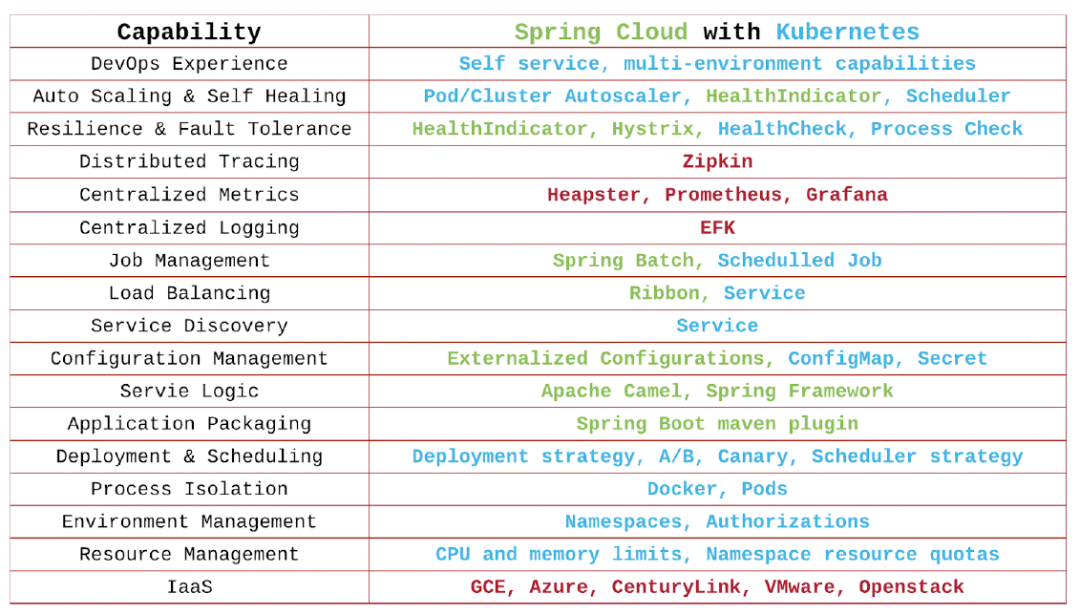
如图中所示,和虚拟机运行传统应用,只需要创建出资源来,并且保证网络畅通即可的方式不同,微服务的运行,需要完成左面的一系列工具链。
为什么要使用这些工具链,以及如何使用这些工具链,请参考我的另外两篇文章以业务为核心的云原生体系建设和从1到2000个微服务,史上落地的实践云原生25个步骤。
你会发现,Kubernetes都有相应的工具链可以匹配。
微服务设计重要的一点就是区分无状态和有状态,在 K8S 中,无状态对应 deployment,有状态对应 StatefulSet。
deployment 主要通过副本数,解决横向扩展的问题。
而 StatefulSet 通过一致的网络 ID,一致的存储,顺序的升级,扩展,回滚等机制,保证有状态应用,很好地利用自己的高可用机制。因为大多数集群的高可用机制,都是可以容忍一个节点暂时挂掉的,但是不能容忍大多数节点同时挂掉。而且高可用机制虽然可以保证一个节点挂掉后回来,有一定的修复机制,但是需要知道刚才挂掉的到底是哪个节点,StatefulSet 的机制可以让容器里面的脚本有足够的信息,处理这些情况,实现哪怕是有状态,也能尽快修复。
微服务少不了服务发现,除了应用层可以使用 SpringCloud 或者 Dubbo 进行服务发现,在容器平台层当然是用 Service了,可以实现负载均衡,自修复,自动关联。
服务编排,本来 K8S 就是编排的标准,可以将 yml 文件放到代码仓库中进行管理,而通过 deployment 的副本数,可以实现弹性伸缩。
对于配置中心,K8S 提供了 configMap,可以在容器启动的时候,将配置注入到环境变量或者 Volume 里面。但是的缺点是,注入到环境变量中的配置不能动态改变了,好在 Volume 里面的可以,只要容器中的进程有 reload 机制,就可以实现配置的动态下发了。
统一日志中心,监控中心,APM往往需要在 Node 上部署 Agent,来对日志和指标进行收集,当然每个 Node 上都有,daemonset 的设计,使得更容易实现。
Kubernetes本身能力比较弱的就是服务的治理能力,这一点 Service Mesh,可以实现更加精细化的服务治理,进行熔断,路由,降级等策略。Service Mesh 的实现往往通过 sidecar 的方式,拦截服务的流量,进行治理。这也得力于 Pod 的理念,一个 Pod 可以有多个容器,如果当初的设计没有 Pod,直接启动的就是容器,会非常的不方便。
0.2 Kubernete本身的架构就是微服务架构,使其易管理和易定制
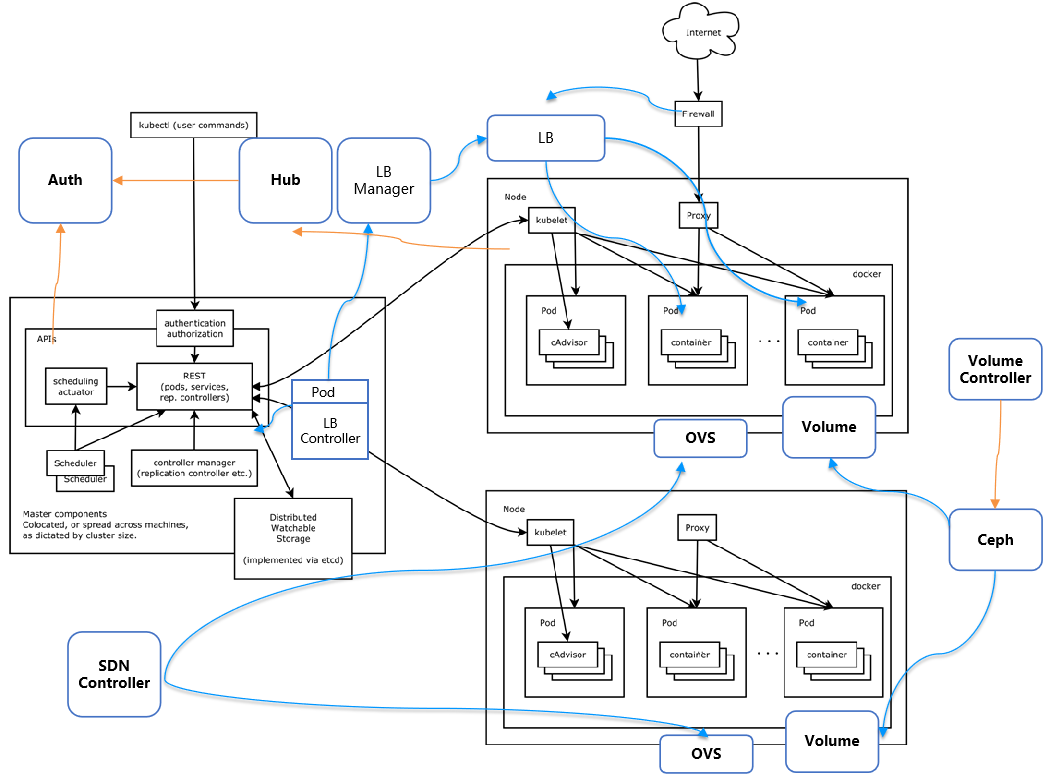
Kubernetes 本身就是微服务的架构,虽然看起来复杂,但是容易定制化,容易横向扩展。
Kubernetes 的 API Server 更像网关,提供统一的鉴权和访问接口。
在 Kubernetes 中几乎所有的组件都是无状态化的,状态都保存在统一的 etcd 里面,这使得扩展性非常好,组件之间异步完成自己的任务,将结果放在 etcd 里面,互相不耦合。
有了 API Server 做 API 网关,所有其他服务的协作都是基于事件的,因而对于其他服务进行定制化,对于 client 和 kubelet 是透明的。
Kubernetes提供了插件化和组件,例如网络,存储,负载均衡等,可以灵活配置。
例如下图展示了创建一个Pod的时候,各个组件的协作情况。
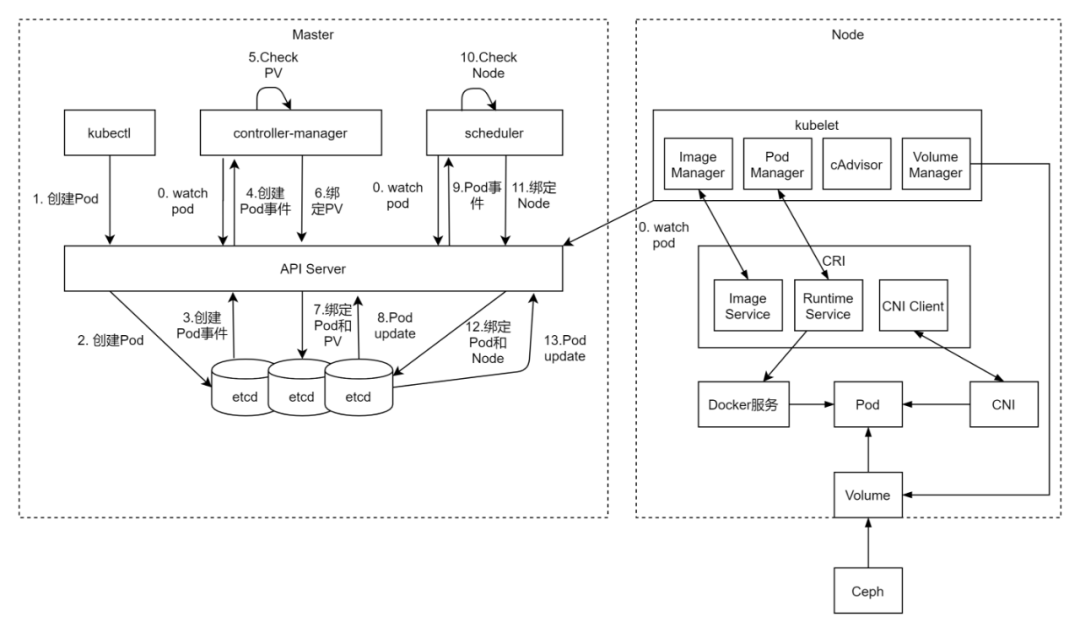
(0)所有的Kubernetes组件Controller, Scheduler, Kubelet都使用Watch机制来监听API Server,来获取对象变化的事件
(1)用户通过Kubectl提交Pod Spec给API Server;
(2)API Server将Pod对象的信息存入Etcd中
(3)Pod的创建会生成一个事件,返回给API Server
(4)Controller监听到这个事件
(5)Controller知道这个Pod要mount一个盘,于是查看是否有能够满足条件的PV
(6)假设有满足条件的PV,就将Pod和PV绑定在一起,将绑定关系告知API Server
(7)API Server将绑定信息写入Etcd中
(8)生成一个Pod Update事件
(9)Scheduler监听到了这个事件
(10)Scheduler需要为Pod选择一个Node
(11)假设有满足条件的Node,就讲Pod和Node绑定在一起,将绑定关系告知API Server
(12)API Server将绑定信息写入Etcd中
(13)生成一个Pod Update事件
(14)Kubelet监听到了这个事件,开始创建Pod
(15)Kubelet告知CRI去下载镜像
(16)Kubelet告知CRI去运行容器
(17)CRI调用Docker运行容器
(18)Kubelet告知Volume Manager,将盘挂在到Node上,然后mount到Pod中
(19)CRI调用CNI给容器配置网络
好了,基本原理解释清楚了,接下来我们看十大实践。
节,历史兼容性设计:将应用程序平滑迁移到容器
构建容器平台要考虑的件事情就是应用如何迁移到容器中,这是很多公司往往忽略的问题,这会造成容器平台虽然建设了,但是应用不愿意改造,或者改造成本过大,从而不愿意迁移到容器上来。
影响到容器迁移的一个重要的问题就是网络连通性问题,因为原来很多的应用之间都是相互调用,关系复杂,难以理清,有的通过注册发现机制才能找到对方,但是应用迁移的时候,往往不敢贸然一次全量迁移,而是部分迁移,一旦出现部分迁移,就会出现容器内应用和容器外应用如何通信,如何发现的问题,因为容器会有自己的私有网络,和原来机房和云的网络模式不同,如果通信需要代理或者NAT,问题就会变得比较的复杂。
1.1 容器网络基本原理介绍
在解决问题之前,我们先看一下主流的容器网络的基本原理,目前大部分公司部署的容器都是使用Calico作为网络方案,他的网络模式如下图所示。
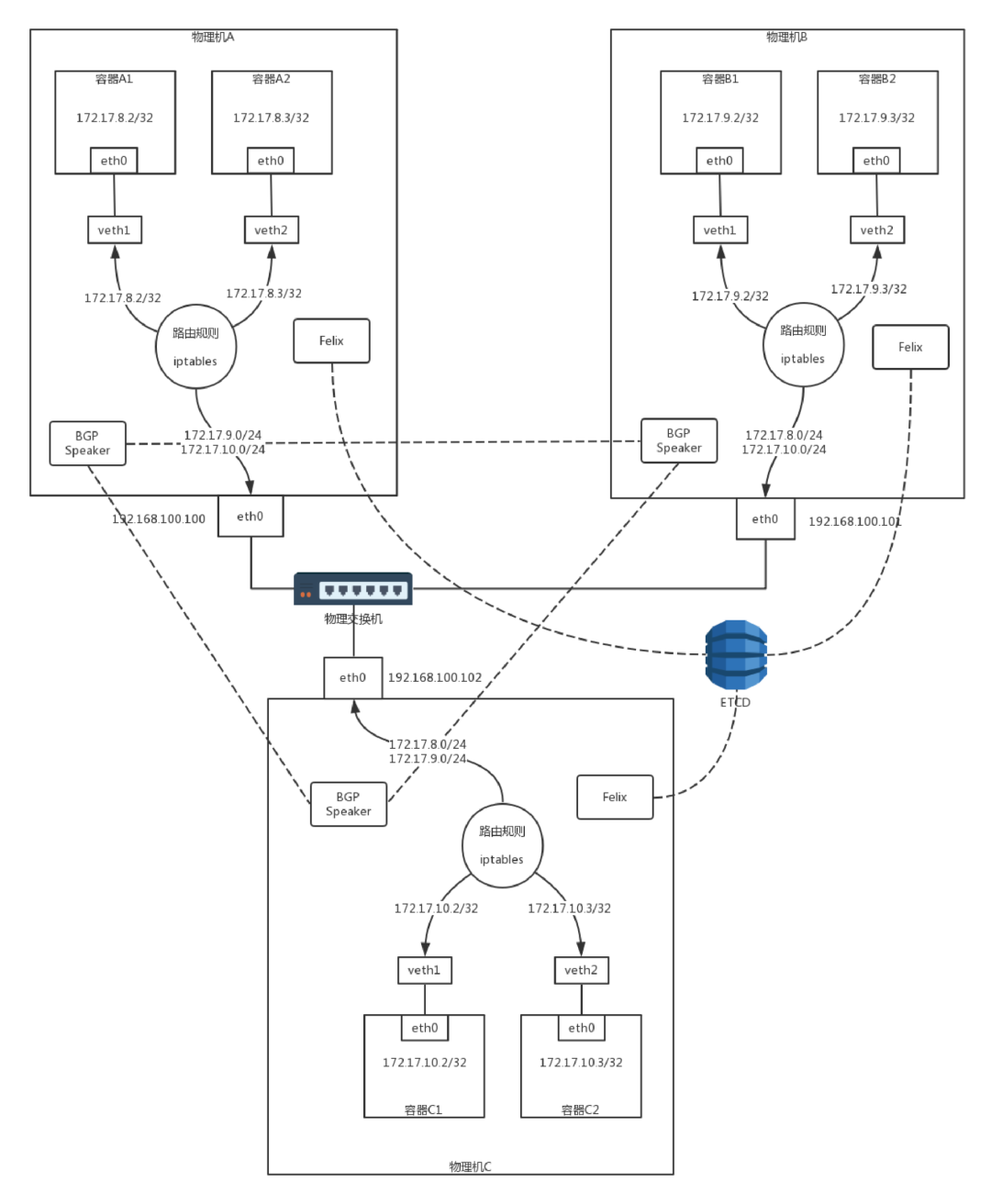
Calico网络的大概思路,即不走Overlay网络,不引入另外的网络性能损耗,而是将转发全部用三层网络的路由转发来实现。
其实现细节如下:
容器A1的IP地址为172.17.8.2/32,这里注意,不是/24,而是/32,将容器A1作为一个单点的局域网了。
容器A1里面的默认路由,Calico配置得比较有技巧。
default via 169.254.1.1 dev eth0169.254.1.1 dev eth0 scope link
这个IP地址169.254.1.1是默认的网关,但是整个拓扑图中没有一张网卡是这个地址。那如何到达这个地址呢?
因为当一台机器要访问网关的时候,首先会通过ARP获得网关的MAC地址,然后将目标MAC变为网关的MAC,而网关的IP地址不会在任何网络包头里面出现,也就是说,没有人在乎这个地址具体是什么,只要能找到对应的MAC,响应ARP就可以了。
ARP本地有缓存,通过ip neigh命令可以查看。
169.254.1.1 dev eth0 lladdr ee:ee:ee:ee:ee:ee STALE这个MAC地址是Calico硬塞进去的,但是没有关系,它能响应ARP,于是发出的包的目标MAC就是这个MAC地址。
在物理机A上查看所有网卡的MAC地址的时候,我们会发现veth1就是这个MAC地址。所以容器A1里发出的网络包,跳就是这个veth1这个网卡,也就到达了物理机A这个路由器。
在物理机A上有多条路由规则,分别是去两个本机的容器的路由,以及去172.17.9.0/24下一跳为物理机B,去172.17.10.0/24下一跳为物理机C。
172.17.8.2 dev veth1 scope link172.17.8.3 dev veth2 scope link172.17.9.0/24 via 192.168.100.101 dev eth0 proto bird onlink172.17.10.0/24 via 192.168.100.102 dev eth0 proto bird onlink
同理,物理机B上也有多条路由规则,分别是去两个本机的容器的路由,以及去172.17.8.0/24的下一跳为物理机A,去172.17.10.0/24下一跳为物理机C。
172.17.9.2 dev veth1 scope link172.17.9.3 dev veth2 scope link172.17.8.0/24 via 192.168.100.100 dev eth0 proto bird onlink172.17.10.0/24 via 192.168.100.102 dev eth0 proto bird onlink
在这里,物理机化身为路由器,通过路由器上的路由规则,将包转发到目的地。在这个过程中,没有隧道封装解封装,仅仅是单纯的路由转发,性能会好很多。
当机器数目比较多的时候,这些路由不能手动配置,需要每台物理机上有一个agent,当创建和删除容器的时候,自动做这件事情,这个agent在Calico中称为Felix。
当Felix配置了路由之后,接下来的问题就是,如何将路由信息广播出去。在Calico中,每个Node上运行一个软件BIRD,作为BGP的客户端,或者叫作BGP Speaker,将路由信息广播出去。所有Node上的BGP Speaker 都互相建立连接,就形成了全互连的情况,这样每当路由有所变化的时候,所有节点就都能够收到了。
Calico模式要求底层网络必须能够支持BGP,另外就是跨网段问题,也即接入Calico网络的物理机必须在同一个网段下面,中间不能再跨路由器,否则中间的路由器如果不配合将Calico的BGP网络信息进行转发,则网络就会割裂。
但是往往中间的路由器不在Kubernetes和Calico的控制之下,一种折中的办法是物理机A和物理机B之间打一个隧道,这个隧道有两个端点,在端点上进行封装,将容器的IP作为乘客协议放在隧道里面,而物理主机的IP放在外面作为承载协议。这样不管外层的IP通过传统的物理网络,走多少跳到达目标物理机,从隧道两端看起来,物理机A的下一跳就是物理机B,这样前面的逻辑才能成立。这就是Calico的IPIP模式。由此可见,Calico的IPIP模式也是Overlay的,也是存在性能损耗的。
1.2. 模式一,构建统一的SDN网络
理想的方式就是整个数据中心的规划构建了统一的SDN网络,不管是硬件的SDN还是软件的SDN,都可以让不同的运行环境接入这个统一的SDN网络,从而可以通过管控统一下发网络策略,实现不同运行环境的统一互通,而对应用层透明。
这一点在以业务为核心的云原生体系建设中有这样的图。
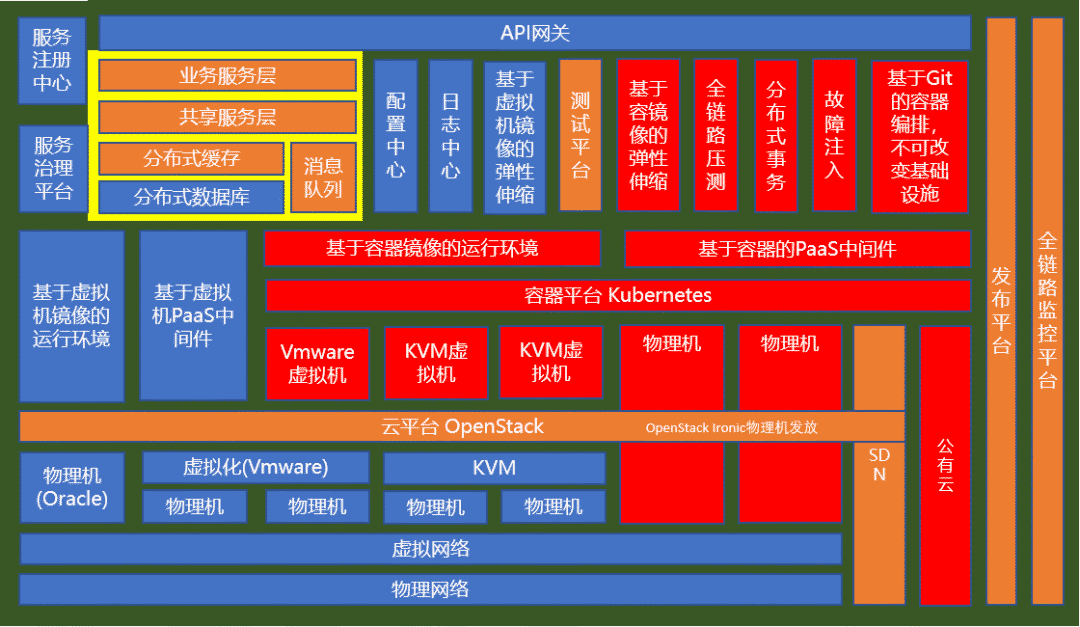
在这里面,你会发现OpenStack将所有的Vmware虚拟化,KVM虚拟化,以及物理机统一管理起来的时候,旁边有一个竖条就是SDN,这在上层Kubernetes将Vmware虚拟机,KVM虚拟机,物理机统一编排的时候,起到了这个作用。
我们先从OpenStack网络模型说起。
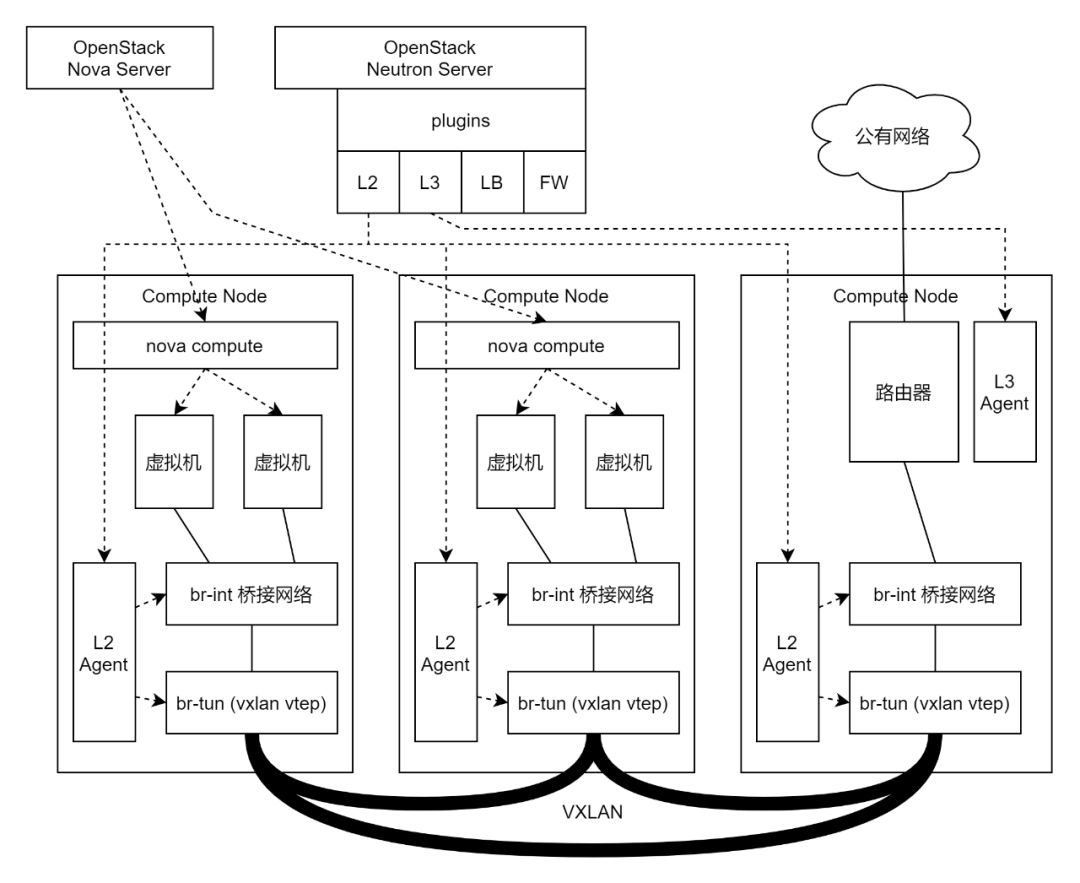
OpenStack分管控面和数据面,Nova负责创建虚拟机,Neutron可以有L2和L3的插件下发管控网络策略。
在计算节点和网络节点上,nova-compute负责和nova管控交互,启动虚拟机,L2 Agent和L3 Agent负责和neutron插件交互来下发网络策略,从而实现了简单的软件SDN。
对于每一个节点,虚拟网络设备分为两层,一层是桥接网络,用于区分相同物理机上不同租户的虚拟机,基于VLAN,另一层是VXLAN的VTEP,也即VXLAN的封包和解封包的虚拟网络设备。
这在仅有OpenStack的时候,没有任何问题。
如果有Vmware需要纳入OpenStack的管理怎么办呢?管控端好说,Nova对接Vcenter就可以了。网络层面就比较难打通了。
如果用Vmware NSX,Vmware有自己的虚拟交换机的实现,和OpenStack用的Openvswitch完全两回事儿,因而Neutron根本无法纳管。
那怎么办呢?我们可以将OpenStack的两层虚拟网络设备分开来看,上层的VLAN是统一的,无论是OpenStack还是Vmware,相同的租户使用相同的VLAN即可,下层的VXLAN VTEP是Vmware虚拟交换机和Openvswitch没办法互通的,可以通过硬件SDN下沉到出物理机后的TOR交换机上做VXLAN的终结。
我们以某硬件厂商的SDN为例子,如下图。
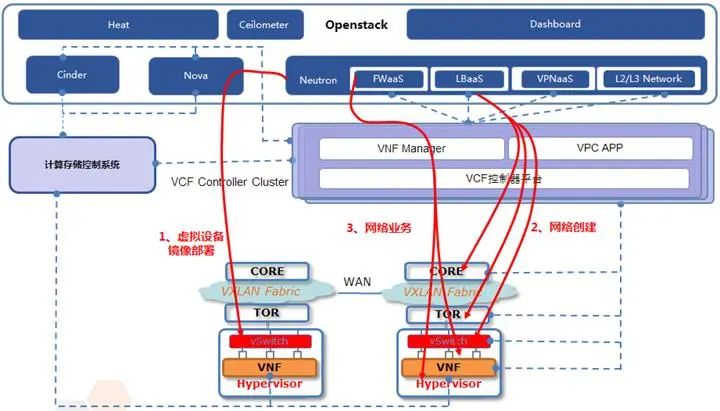
与标准的Openstack对接:采用在Neutron Server中安装SDN Controller插件的方式,接管Openstack网络控制。Openstack定义的插件如下表所示:
可对接Neutron插件举例 |
可对接对象举例 |
ml2 |
network |
subnet | |
port | |
l3 |
router |
floatingip | |
vpnaas |
Vpnservice/ikepolicy |
fwaas |
Firewall/firewall_policy |
lbaas |
memberpool |
Openstack插件类似于一个硬件driver,以网络组件Neutron为例,Neutron本身实现抽象的虚拟网络功能,Neutron先调用插件把虚拟网络下发到SDN Controller,然后由SDN Controller下发到具体的设备上。插件可以是核心组件也可以是一项服务:核心插件实现“核心”的Neutron API——二层网络和IP地址管理。服务插件提供“额外”的服务,例如三层路由、负载均衡、VPN、防火墙和计费等。
SDN Controller实现了上述插件,在插件里通过REST API把Nuetron的配置传递给SDN Controller,SDN Controller进行网络业务编排通过Openflow流表等手段下发到硬件交换机、NFV以及vSwitch上,以实现相应的网络和服务功能。

有了统一的SDN的能力,当有了容器平台的时候,接入就容易的多,而且下层的VXLAN对于容器内的应用不可见,对于容器来讲,他就像和Vmware虚拟机里面的应用以及KVM里面的应用在同一个二层网络里面一样,十分平滑。
如果我们有了容器平台,无论是物理机部署,还是虚拟机部署,都可以通过桥接的方式,连接到外面的网络中,不同的租户可以使用不同的VLAN,通过硬件SDN的VXLAN封装实现互通。
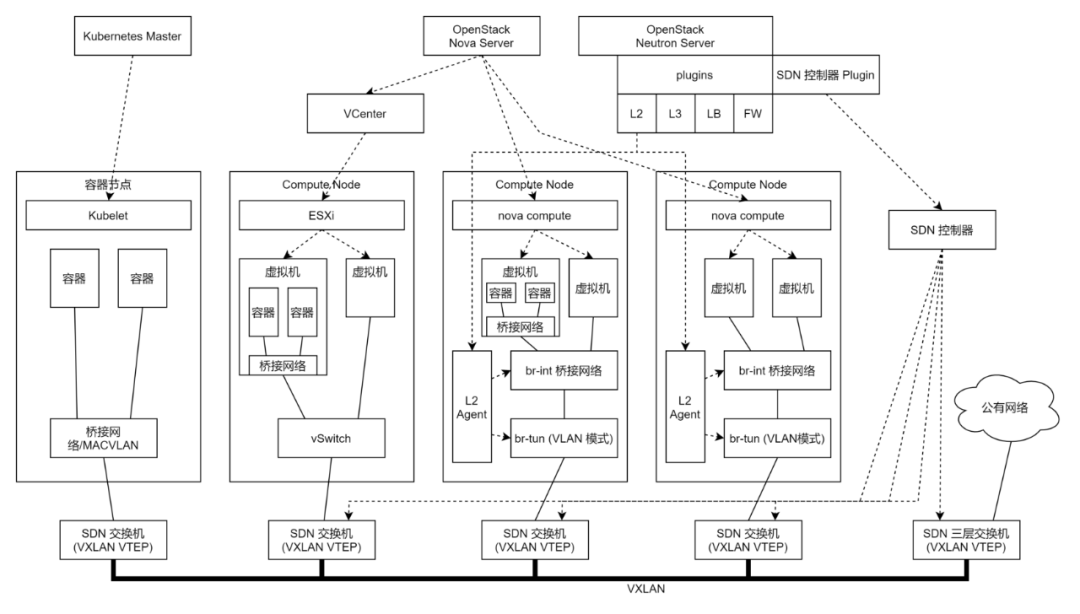
如果没有VMware,或者选择Vmware不统一纳管,还可以实现基于Openvwitch的统一软件SDN方案,统一管理容器网络,虚拟机网络。

当然,使用统一的软件或者硬件SDN,需要对于整个运维部和机房有统一的规划,这在很多企业是没有做到的,从而环境被割裂称为了一块一块的,接下来我们就来讨论一下这些场景。
1.3. 模式二:原来的应用部署在Vmware或者物理机上,直接使用机房网络,需要和K8S中的容器互通。
如图所示,使用Vmware可以不用虚拟交换机,而是直接用桥接方式使用机房网,这也是很多传统企业的使用模式,使用物理机,更是使用机房网。
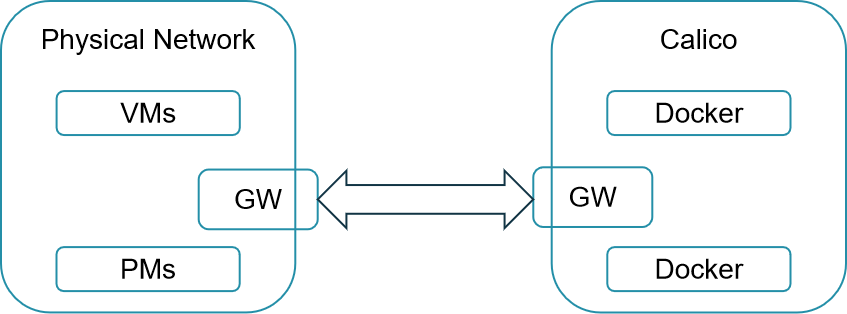
这个时候,我们可以划分出一部分物理机来,分配一个网段给K8S集群,使用Calico网络,由于基于物理网络,Calico网络可以使用BGP模式,这样没有虚拟化,性能也比较好。
接下来就是如何通过机房网络和传统应用互通的问题,由于传统应用也使用机房网络,并且也有规划的网段,因而只要传统物理网络的路由器和容器所在的物理网络的路由器做一个路由配置就可以,也即在图中右面的Gateway上配置到达Calico每一个节点的路由,同时告知Calico的每一个节点,要想访问传统应用的网段,应该经过右面的GW,转发给左面的GW,然后在左面的Gateway上配置,如果要访问容器网络,应该经过左面的GW,转发给右面的GW,其实相当于做了一个peering。
1.4. 模式三:原来已经采购云平台,传统应用使用云平台的VPC网络,而云平台本身提供托管的K8S集群,K8S里面的容器也能够直接使用VPC网络。
这就是Fargate模式,也即完全托管的容器平台,这个时候容器平台的网络被云完全托管,大部分托管的容器平台会直接使用云的VPC网络,而不会在VPC网络之上再虚拟化一层容器网络,这种模式和我们上面提到的软件SDN的方式一样,这样两面的互通是十分平滑的。
1.5. 模式四:原来已有云平台,传统应用使用云平台的VPC网络,新建的K8S部署在物理机上。
这也是常规的建设方式,云是云,容器是容器,互不干扰。
在云平台的VPC里面,有一个重要的概念就是网关,网关可以在不同的VPC之间,以及VPC和物理网络之间建立VPN,或者对等连接VPC peering。使得无论是VPC内的网络,还是云外的网络,都可以感觉是可以无缝通信的。
方式如下图所示。

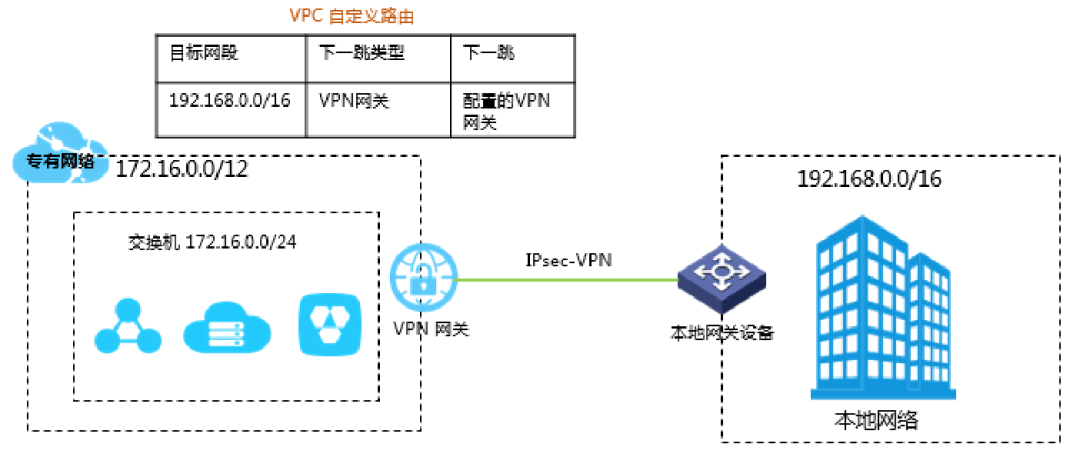
同理,对于Calico,有一个网关可以将流量转发到Calico的BGP网络中,然后这个GW和云内VPC的GW做对等连接,即可。

1.6. 模式五:在云平台内部自行搭建K8S集群
很多企业担心被云厂商绑定,因而要跨云进行部署,并且不愿意使用云平台提供的托管K8S,而是通过类似多容器部署管理平台,自行在多个云上搭建K8S集群。
这就面临一个问题,就是云内的VPC是不支持BGP网络的,因而在云内搭建K8S集群,就需要使用Calico的IPIP模式,也即在云的网络虚拟化之上,又多了一层虚拟化,这样使得性能有所损耗。
另一个问题就是,Calico的IPIP模式的网络是Overlay网络,和其他虚拟机上的应用天然不通,必须要经过代理或者NAT才能通信,要求业务做一定的适配,影响比较大。
这个时候,有两种替代方案。
,在大多数的云平台上,一个虚拟机是可以创建多个网卡的,我们可以将一个网卡用于管控通信,其他的网卡在创建容器的时候,用命令行将其中一个虚拟机网卡塞到容器网络的namespace里面,这样容器就能够使用VPC网络和其他虚拟机上的应用进行平滑通信了,而且没有了二次虚拟化。
当然云平台对于一个虚拟机上的网卡数目有限制,这就要求我们创建的虚拟机规格不能太大,因为上面能够跑的容器的数量受到网卡数目限制。
另外我们在调度容器的时候,需要考虑一个节点还有没有剩余的网卡。Kubernetes有一个概念叫Extended Resources,官方文档举了这样一个例子。
curl --header "Content-Type: application/json-patch+json" \--request PATCH \--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \http://localhost:8001/api/v1/nodes/<your-node-name>/status
同理可以将网卡作为Extended Resources放到每个Node上,然后创建Pod的时候,指定网卡资源。
apiVersion: v1kind: Podmetadata:name: extended-resource-demospec:containers:name: extended-resource-demo-ctrimage: nginxresources:requests:: 3limits:: 3
同时要配合开发CNI插件,通过nsenter,ip netns等命令将网卡放入namespace中。
第二,就是使用hostnetwork,也即容器共享虚拟机网络,这样使得每个容器没有单独的网络命名空间,因而端口会冲突,需要随机分配应用的端口,由于应用的端口事先不可知,需要通过服务发现机制,给注册中心注册随机的端口。
1.7. 模式六:乖乖使用Cailco网络,使用Ingress进行容器内外的访问
第二节,容器运行时与隔离性设计
好了,上一节,容器迁移的兼容性问题解决了,接下来是常遇到的问题是,容器的隔离性不好,如何提升容器的隔离性的问题。
2.1. 容器隔离性设计
我们应该增强哪些容器运行的隔离性呢?
我们都知道容器是通过cgroup技术来限制资源的使用的,cgroup定义了很多的子系统,常用的用于限制资源的有以下的几个:
cpu子系统,主要限制进程的CPU使用率。
cpuset 子系统,可以为 cgroup 中的进程分配单独的CPU节点或者内存节点。
memory 子系统,可以限制进程的 Memory 使用量。
blkio 子系统,可以限制进程的块设备IO。
-
net_cls 子系统,可以标记 cgroup 中进程的网络数据包,然后可以使用 TC模块(Traffic Control)对数据包进行控制。
其中对于CPU和内存的cgroup的限制可通过下面的图对应。
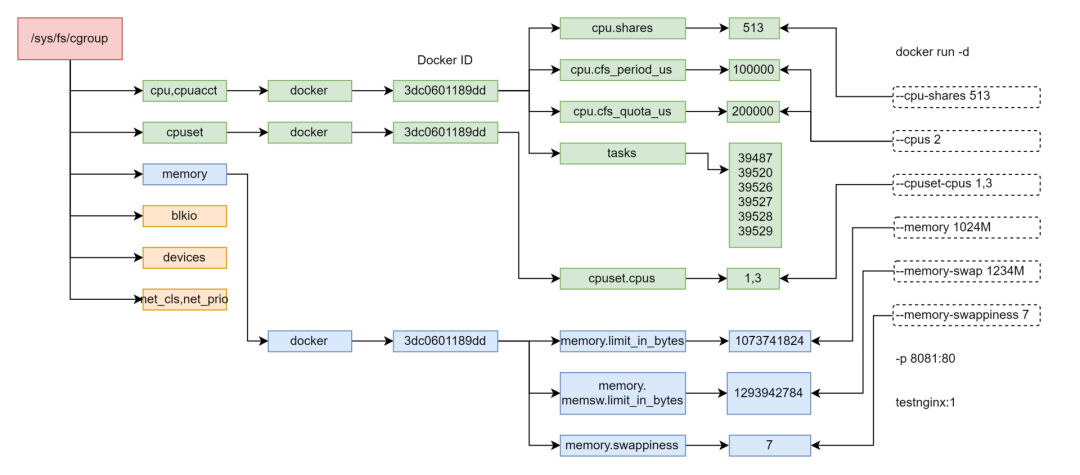
对于需要高性能运行的程序,我们常会设置CPU Set,也即绑核的参数,减少程序运行过程中的上下文切换。
在内核中,对于CPU Cgroup的配置会影响一个进程的task_struct作为调度单元的scheduled_entity,并影响在CPU上的调度。
对于内存的限制,除了上面限制内存使用总量之外,Intel CPU还有MBA(memory bandwidth available)和MBM(memory bandwidth monitoring)可以限制CPU对于内存的访问带宽。
在内核中,对于内存 Cgroup的配置起作用在进程申请内存的时候,也即当出现缺页,调用handle_pte_fault进而调用do_anonymous_page的时候,会查看是否超过了配置,超过了就分配失败,OOM。
对于网络带宽QoS的限制,需要TC和cgroup联合起来使用。
TC可以构建一个HTB(Hierarchical Token Bucket)分层令牌桶规则树。

使用TC可以为某个网卡eth0创建一个HTB的排队规则,需要付给它一个句柄(1:)。
这是整棵树的根节点,接下来会有分支。例如图中有三个分支,句柄分别为(:10)、(:11)、(:12)。后的参数default 12表示默认发送给1:12,也即发送给第三个分支。
通过下面的命令,可以创建HTB树的根节点。
tc qdisc add dev eth0 root handle 1: htb default 12对于这个网卡,需要规定发送的速度。一般有两个速度可以配置,一个是rate,表示一般情况下的速度;一个是ceil,表示高的速度。对于根节点来讲,这两个速度是一样的,于是创建一个root class,速度为(rate=100kbps,ceil=100kbps)。
通过下面的命令,创建HTB根节点下面的root class,并限制速度为100kbps。
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps接下来要创建分支,也即创建几个child class。每个child class统一有两个速度。三个分支分别为(rate=30kbps,ceil=100kbps)、(rate=10kbps,ceil=100kbps)和(rate=60kbps,ceil=100kbps)。
通过下面的命令,在root class下面创建了三个child class,并给每个child class限制了速度。
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbpstc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
你会发现三个child class的rate加起来,是整个网卡允许的大速度。
HTB有个很好的特性,同一个root class下的child class可以相互借流量,如果直接不在排队规则下面创建一个root class,而是直接创建三个class,它们之间是不能相互借流量的。借流量的策略,可以使得当前不使用这个分支的流量的时候,可以借给另一个分支,从而不浪费带宽,使带宽发挥大的作用。
后,创建叶子排队规则,分别为fifo和sfq,代码如下所示。
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 5tc qdisc add dev eth0 parent 1:11 handle 30: pfifo limit 5tc qdisc add dev eth0 parent 1:12 handle 40: sfq perturb 10
基于这个排队规则,我们还可以通过TC设定发送规则:从1.2.3.4来的、发送给port 80的包,从个分支1:10走;其他从1.2.3.4发送来的包从第二个分支1:11走;剩余的包走默认分支。代码如下所示。
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 match ip dport 80 0xffff flowid 1:10tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 flowid 1:11
有了cgroup,我们按照cgroup再来设定规则。代码如下所示。
tc filter add dev eth0 protocol ip parent 1:0 prio 1 handle 1: cgroup
假设我们有两个用户a和b,要对它们进行带宽限制。
首先,我们要创建两个net_cls,代码如下所示。
mkdir /sys/fs/cgroup/net_cls/amkdir /sys/fs/cgroup/net_cls/b
假设用户a启动的进程ID为12345,把它放在net_cls/a/tasks文件中。同样假设用户b启动的进程ID为12346,把它放在net_cls/b/tasks文件中。
net_cls/a目录下面,还有一个文件net_cls.classid,放flowid 1:10。net_cls/b目录下面,也创建一个文件net_cls.classid,放flowid 1:11。
这个数字怎么放呢?要转换成一个0×AAAABBBB的值,AAAA对应class中冒号前面的数字,BBBB对应后面的数字。代码如下所示。
echo 0x00010010 > /sys/fs/cgroup/net_cls/a/net_cls.classidecho 0x00010011 > /sys/fs/cgroup/net_cls/b/net_cls.classid
这样用户a的进程发的包,会打上1:10这个标签;用户b的进程发的包,会打上1:11这个标签。然后tc根据这两个标签,让用户a的进程的包走左边的分支,用户b的进程的包走右边的分支。
Docker本身对于proc的隔离性做的不够,在容器内部proc文件系统中可以看到Host宿主机上的proc信息(如:meminfo, cpuinfo,stat, uptime等)。
lxcfs是一个开源的FUSE(用户态文件系统)实现来支持LXC容器。
LXCFS通过用户态文件系统,在容器中提供下列 procfs 的文件:
/proc/cpuinfo
/proc/diskstats
/proc/meminfo
/proc/stat
/proc/swaps
/proc/uptime
比如,把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到Docker容器的/proc/meminfo位置后。容器中进程读取相应文件内容时,LXCFS的FUSE实现会从容器对应的Cgroup中 读取正确的内存限制。从而使得应用获得正确的资源约束设定,增强容器的隔离性。
接下来我们看对于硬盘的资源隔离。
其中对于磁盘资源配额,通过xfs_quota实现:
使用者、群组、目录 :XFS文件系统的quota限制中,主要是针对群组、个人或单独的目录进行磁盘使用率的限制。
容量、数量 :限制inode或block用量。
柔性、硬性 :限制soft和hard,通常hard的限制值比soft的限制值要高。
其中对于I/O的限制,对于直接I/O的限制,可以通过下面的参数控制:
--device-read-bps:磁盘每秒多可以读多少比特(bytes)
--device-write-bps:磁盘每秒多可以写多少比特(bytes)
--device-read-iops:磁盘每秒多可以执行多少 IO 读操作
--device-write-iops:磁盘每秒多可以执行多少 IO 写操作
比较困难的是对于Buffered-IO带宽的限制。cgroup v1不支持buffer write io 限制,cgroup v2由于采用unified 层级设计,mem子系统和blk子系统联动,可以准确追踪buffer write时page 的cgroup属主,因而可以实现buffer write io 限制。如果目前使用cgroup v1,就需要内核团队进行定制化了。
2.2. 容器运行时原理及设计
CRI(Container Runtime Interface)是 Kubernetes 定义的与 contianer runtime 进行交互的接口,将 Kubernetes 与特定的容器解耦。
CRI实现了两个GRPC协议的API,提供两种服务ImageService和RuntimeService。
// grpcServices are all the grpc services provided by cri containerd.type grpcServices interface {runtime.RuntimeServiceServerruntime.ImageServiceServer}// CRIService is the interface implement CRI remote service server.type CRIService interface {Run() error// io.Closer is used by containerd to gracefully stop cri service.io.Closerplugin.ServicegrpcServices}
这两个GRPC负责和kubelet进行通信。
CRI的实现CRIService中包含了很多重要的组件:
// criService implements CRIService.type criService struct {// config contains all configurations.config criconfig.Config// imageFSPath is the path to image filesystem.imageFSPath string// os is an interface for all required os operations.os osinterface.OS// sandboxStore stores all resources associated with sandboxes.sandboxStore *sandboxstore.Store// sandboxNameIndex stores all sandbox names and make sure each name// is unique.sandboxNameIndex *registrar.Registrar// containerStore stores all resources associated with containers.containerStore *containerstore.Store// containerNameIndex stores all container names and make sure each// name is unique.containerNameIndex *registrar.Registrar// imageStore stores all resources associated with images.imageStore *imagestore.Store// snapshotStore stores information of all snapshots.snapshotStore *snapshotstore.Store// netPlugin is used to setup and teardown network when run/stop pod sandbox.netPlugin cni.CNI// client is an instance of the containerd clientclient *containerd.Client......}
其中重要的是cni.CNI,用于配置容器网络。还有containerd.Client,用于连接containerd来创建容器。

我们这里画了一个图列举一下CRI插件的代码工作逻辑。

如果你觉得默认的CRI不足以满足需求,可以实现自己的CRI插件。
另外,很多企业觉得容器没有内核,隔离性不好,因而可以是要轻量级虚拟化程序HyperContainer。
HyperContainer是一款基于虚拟化技术的容器方案,它允许大家利用现有标准虚拟化管理程序(包括KVM与Xen等)来启动Docker镜像。作为开源项目,HyperContainer由一套名为runV的OCI标准容器运行时和一个名为hyperd的守护程序共同构成。(https://github.com/hyperhq/hyperd)
因而有一个特殊的CRI叫做frakti,他可以使用runV通过轻量级的虚拟化方式运行Pod,他可以调用hyperd来运行HyperContainer。(https://github.com/kubernetes/frakti)
第三节,Kubernetes控制面设计与集群规模限制
接下来,我们讨论控制面,当容器集群规模比较小的时候,控制面压力不大,随着集群规模越大,控制面开始感受到压力,因而需要进行一定的优化。
控制面的三大组件分别是API Server,Controller Manager,Scheduler,我们一一解析他们的原理,可能遭遇到的瓶颈和优化方式。
3.1. API Server的原理及优化设计
API Server是Kubernetes的对外入口,他的主要功能是请求的路由和处理,简单说就是监听一个端口,把接收到的请求正确地转到相应的处理逻辑上。
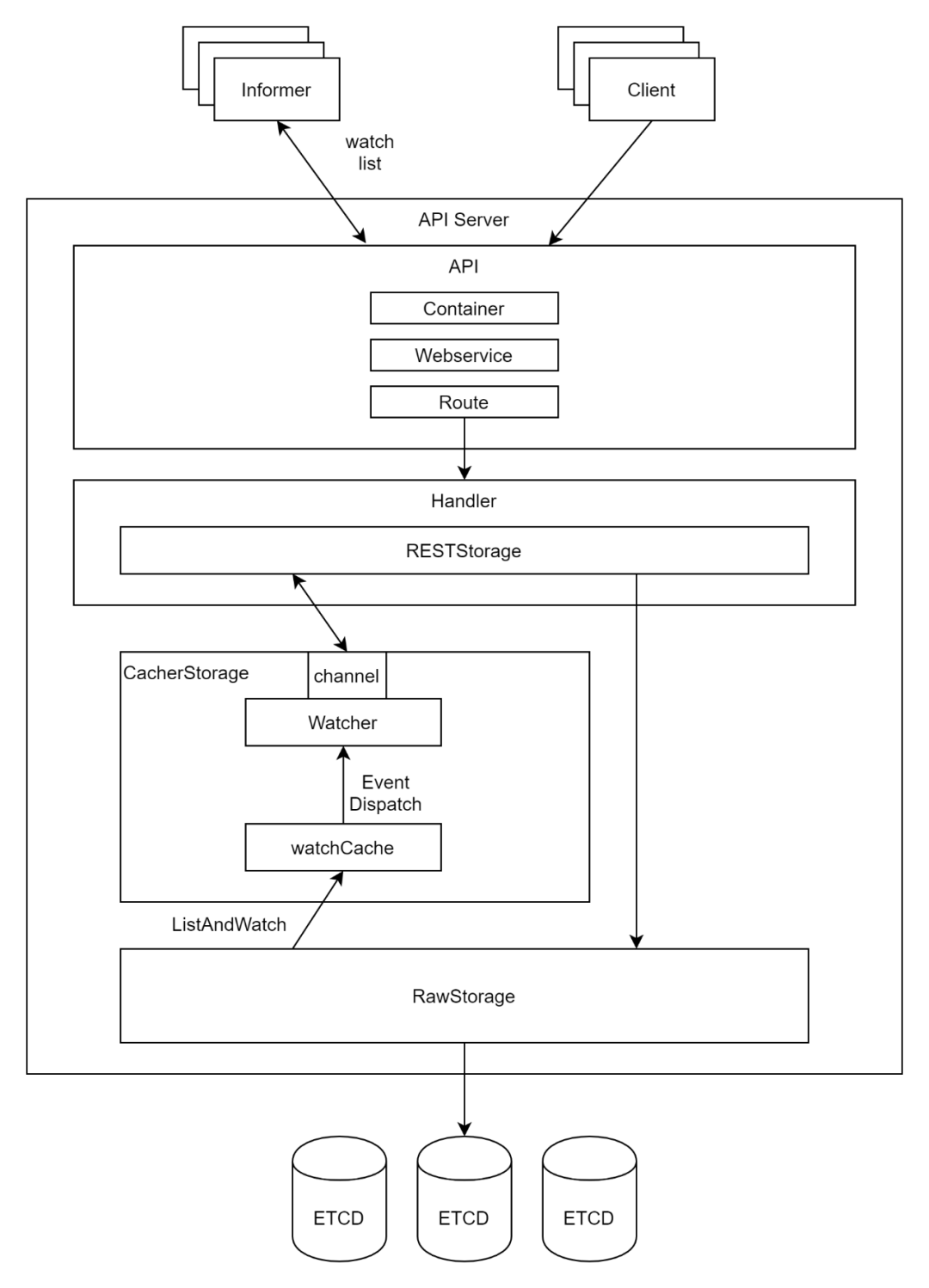
API Server使用了go-restful框架,按照go-restful的原理,包含以下的组件
Container: 一个Container包含多个WebService
WebService: 一个WebService包含多条route
-
Route: 一条route包含一个method(GET、POST、DELETE,
WATCHLIST等),一条具体的path以及一个响应的handler
在API Server中会通过InstallAPIs 和 InstallLegacyAPI来注册API接口,并关联到相应的处理对象RESTStorage。
例如在InstallLegacyAPI中,重要的两个操作是NewLegacyRESTStorage和InstallLegacyAPIGroup。
其中NewLegacyRESTStorage就是生成处理对象RESTStorage,它里面有如下重要的逻辑。
restStorage := LegacyRESTStorage{}......podTemplateStorage, err := podtemplatestore.NewREST(restOptionsGetter)......nodeStorage, err := nodestore.NewStorage(restOptionsGetter, c.KubeletClientConfig, c.ProxyTransport)......podStorage, err := podstore.NewStorage(restOptionsGetter,nodeStorage.KubeletConnectionInfo,c.ProxyTransport,podDisruptionClient,)......restStorageMap := map[string]rest.Storage{"pods": podStorage.Pod,......"podTemplates": podTemplateStorage,......"services": serviceRest,......"endpoints": endpointsStorage,......"nodes": nodeStorage.Node,......}
可以看出,这就是API路径和对应的处理对象RESTStorage的对应关系。
接下来InstallLegacyAPIGroup调用installAPIResources主要也是通过go-restful将API暴露。
installAPIResources遍历安装每个资源的API,对于每个API,调用InstallREST将自定义资源的API处理器注册到restful容器中。
注册处理器的操作在函数registerResourceHandlers中完成,包含不同的操作类型:POST、PUT、DELETE,WATCHLIST等。
对于其他的操作,处理对象会直接写入RawStorage,也即背后的ETCD集群,这里比较特殊的是WATCHLIST,从节的原理我们可以看出,Kubernetes组件之间的协作是严重依赖WATCHLIST的,也即当ETCD中对象发生变化的时候,需要及时通知其他组件,并且让其他组件得到变化,这对ETCD的压力非常大。
API Server采取的方式就是在RawStorage之上,封装了一层CacherStorage,CacherStorage有一个成员是watchCache *watchCache,它应该是实现了一个资源对象信息的缓存。将通过和 etcd 通信而获取到的资源对象的信息缓存在内存中。当资源对象长时间未发生变化的时候,如果再有 List 或者 Watch 请求该资源对象的信息,可以直接返回给它缓存中的内容,而不再去和 etcd 通信,从而减轻etcd的压力。
CacherStorage还有一个成员是reflector *cache.Reflector,他会监听并处理ETCD发来的事件,交给CacherStorage,CacherStorage的dispatchEvents 函数会读取这个事件,分发给Watcher,Watcher为每一个请求启动一个 goroutine 不断的监听资源对象信息的变化,如果有新的消息过来就返回给客户端,从而实现了从ETCD层层通知,层层缓存,到达客户端的作用。
通过这里的原理解析我们知道,ETCD作为Kubernetes的持久化存储组件,不但承载了对象的存储功能,还有对象的变化通知功能,压力是非常大的。
因而这里对于ETCD的配置,一定要用SSD盘,这对整个集群的响应时延非常关键,另外ETCD对于存储量有限制,可以配置quota-backend-bytes。
目前存储在ETCD里面的数据比较多,除了主流的Pod,Service这些,event和ConfigMap也会占用很大的量,Event主要用来保存各个组件的运行状态,可以通过他发现异常,Event数据写入比较频繁,带来压力比较大,又不是特别关键的数据,可以分ETCD集群存储。按照官方文档,可以如下配置。
--etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381另外ConfigMap如果存储的配置项比较多,也会比较大,建议使用Apollo配置中心,而不要直接使用容器的配置中心。
很多大规模容器平台到了后期,会对ETCD做类似分库分表的操作,以减轻压力,增加扩展性,例如如果一个Kubernetes集群给多个租户使用,可以讲不通租户的数据存放在不同的ETCD分片中,按照上面的原理分析,可以通过修改RawStorage这一层的方式实现。
不过由于Kubernetes本身社区更新速度较快,不建议自己修改Kubernetes核心代码,因为一旦修改了,再合并到社区就很难做到,因而宁可采取多Kubernetes集群的方式,也不太建议做ETCD的分库分表。
3.2. Controller Manager的原理及优化设计
controller-manager作为集群的管理控制中心,维护集群中的所有控制器,对维持集群的稳定和自我修复,实现高可用,副本控制等起关键作用。
controller-manager里面集成了多种多样的控制器,在
NewControllerInitializers中是这样定义的
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {controllers := map[string]InitFunc{}controllers["endpoint"] = startEndpointControllercontrollers["replicationcontroller"] = startReplicationController......controllers["daemonset"] = startDaemonSetController......controllers["deployment"] = startDeploymentControllercontrollers["replicaset"] = startReplicaSetControllercontrollers["horizontalpodautoscaling"] = startHPAController......controllers["statefulset"] = startStatefulSetController......controllers["service"] = startServiceController......return controllers}
这里面对每一个Controller都设置了启动函数,每个Controller的架构如图所示:

例如对于replicaset,启动controller的时候调用的就是startReplicaSetController。
在startReplicaSetController中,会调用
NewReplicaSetController创建控制器
go replicaset.NewReplicaSetController(ctx.InformerFactory.Apps().V1().ReplicaSets(),ctx.InformerFactory.Core().V1().Pods(),ctx.ClientBuilder.ClientOrDie("replicaset-controller"),replicaset.BurstReplicas,).Run(int(ctx.ComponentConfig.ReplicaSetController.ConcurrentRSSyncs), ctx.Stop)
在这里InformerFactory会生成Informer,对于ReplicaSet来讲,需要监听自己和Pod的变化,因而又这两个Informer就够了。
Informer 是 Client-go 中的一个核心工具包。如需要 List/Get Kubernetes 中的 Object(包括pod,service等等),可以直接使用 Informer 实例中的 Lister()方法(包含 Get 和 List 方法)。Informer 基本的功能就是 List/Get Kubernetes 中的 Object,还可以监听事件并触发回调函数等。
Informer 的 Lister() 方法(List/Get)不会去请求 API Server,而是查找缓存在Informer本地内存中的数据,可以减少对 API Server的压力。
Informer 会调用 API Server的List 和 Watch 的 API。Informer 在初始化的时,先调用 List API 获得资源的全部 ,缓存在内存中,然后调用 Watch API 去 watch 这种 resource,维护这份缓存保持一致性。
Informer 还可以自定义回调函数ResourceEventHandler,可以实现 OnAdd,OnUpdate,OnDelete 方法,分别对应 informer 监听创建、更新和删除事件类型。
我们重点看Pod的Informer,他的定义和创建过程如下
type PodInformer interface {Informer() cache.SharedIndexInformerLister() v1.PodLister}func (f *podInformer) Informer() cache.SharedIndexInformer {return f.factory.InformerFor(&corev1.Pod{}, f.defaultInformer)}func (f *podInformer) defaultInformer(client kubernetes.Interface, resyncPeriod time.Duration) cache.SharedIndexInformer {return NewFilteredPodInformer(client, f.namespace, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}, f.tweakListOptions)}func NewFilteredPodInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {return cache.NewSharedIndexInformer(&cache.ListWatch{ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {return client.CoreV1().Pods(namespace).List(context.TODO(), options)},WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {return client.CoreV1().Pods(namespace).Watch(context.TODO(), options)},},&corev1.Pod{},resyncPeriod,indexers,)}func NewSharedIndexInformer(lw ListerWatcher, exampleObject runtime.Object, defaultEventHandlerResyncPeriod time.Duration, indexers Indexers) SharedIndexInformer {realClock := &clock.RealClock{}sharedIndexInformer := &sharedIndexInformer{processor: &sharedProcessor{clock: realClock},indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),listerWatcher: lw,objectType: exampleObject,resyncCheckPeriod: defaultEventHandlerResyncPeriod,defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", exampleObject)),clock: realClock,}return sharedIndexInformer}
创建的是sharedIndexInformer,他有几个个重要的成员:
ListerWatcher:定义了两个函数List和Watch,通过API Server的客户端发现对象的变化
Indexer:是本地的缓存,被索引方便查找
Controller:从ListerWatcher监听到对象的变化,然后放入DeltaFIFO队列中
有了Informer之后,我们回到NewReplicaSetController,他会创建ReplicaSetController
:= &ReplicaSetController{GroupVersionKind: gvk,kubeClient: kubeClient,podControl: podControl,burstReplicas: burstReplicas,expectations: controller.NewUIDTrackingControllerExpectations(controller.NewControllerExpectations()),queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), queueName),}rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: rsc.addRS,UpdateFunc: rsc.updateRS,DeleteFunc: rsc.deleteRS,})podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: rsc.addPod,This invokes the ReplicaSet for every pod change, eg: host assignment. Though this might seem likeoverkill the most frequent pod update is status, and the associated ReplicaSet will only list fromlocal storage, so it should be ok.UpdateFunc: rsc.updatePod,DeleteFunc: rsc.deletePod,})= rsc.syncReplicaSet
这里面定义了workqueue,以及podInformer当监听到事件后的处理函数,还有syncHandler,这个函数后面会用。
例如当一个Pod被删除的时候,rsc.deletePod会被调用。
// When a pod is deleted, enqueue the replica set that manages the pod and update its expectations.// obj could be an *v1.Pod, or a DeletionFinalStateUnknown marker item.func (rsc *ReplicaSetController) deletePod(obj interface{}) {pod, ok := obj.(*v1.Pod)......controllerRef := metav1.GetControllerOf(pod)......rs := rsc.resolveControllerRef(pod.Namespace, controllerRef)......rsKey, err := controller.KeyFunc(rs)......rsc.expectations.DeletionObserved(rsKey, controller.PodKey(pod))rsc.queue.Add(rsKey)}
在rsc.deletePod中,找到这个pod属于的ReplicaSet,然后放到workqueue中等待处理。
我们再回到NewReplicaSetController,在创建了ReplicaSetController之后,会调用他的Run函数。
// Run begins watching and syncing.func (rsc *ReplicaSetController) Run(workers int, stopCh <-chan struct{}) {......for i := ; i < workers; i++ {go wait.Until(rsc.worker, time.Second, stopCh)}......}func (rsc *ReplicaSetController) worker() {for rsc.processNextWorkItem() {}}func (rsc *ReplicaSetController) processNextWorkItem() bool {key, quit := rsc.queue.Get()......err := rsc.syncHandler(key.(string))......return true}
Run会创建线程,运行rsc.worker函数,worker里面调用processNextWorkItem,从队列中取出任务,调用syncHandler进行处理。
前面设置过syncHandler就是syncReplicaSet函数,下面列出了主要逻辑
func (rsc *ReplicaSetController) syncReplicaSet(key string) error {namespace, name, err := cache.SplitMetaNamespaceKey(key)rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())filteredPods := controller.FilterActivePods(allPods)filteredPods, err = rsc.claimPods(rs, selector, filteredPods)manageReplicasErr = rsc.manageReplicas(filteredPods, rs)newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)updatedRS, err := updateReplicaSetStatus(rsc.kubeClient.AppsV1().ReplicaSets(rs.Namespace), rs, newStatus)}
里面的逻辑也很容易理解,列出符合selector的Pod,和replica set做一定的匹配,manageReplicas函数根据Pod的数量多退少补,终updateReplicaSetStatus更新状态。
为什么我们要解析controller的工作机制呢,是因为我们可能会写自己的controller来控制自己的资源。
从这里的解析我们可以看出,controller-manager里面集合了太多的controller在一个进程里面,如果我们创建和删除某种资源特别的频繁,就会使得这种controller占用大量的资源,因而我们可以选择将controller-manager里面的一些核心的controller独立进程进行部署。
3.3. Scheduler的原理及优化设计
kube-scheduler是以插件形式存在的组件,正因为以插件形式存在,所以其具有可扩展可定制的特性。kube-scheduler相当于整个集群的调度决策者,其通过预选和优选两个过程决定容器的佳调度位置。
创建Scheduler的代码如下
sched, err := scheduler.New(cc.Client,cc.InformerFactory,cc.PodInformer,recorderFactory,ctx.Done(),scheduler.WithProfiles(cc.ComponentConfig.Profiles...),scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),scheduler.WithPreemptionDisabled(cc.ComponentConfig.DisablePreemption),scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),scheduler.WithBindTimeoutSeconds(cc.ComponentConfig.BindTimeoutSeconds),scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),scheduler.WithExtenders(cc.ComponentConfig.Extenders...),)
看过Controller的代码后,再看Scheduler就通顺多了,这里有PodInformer,也即Scheduler需要不断监听Pod的状态,并根据状态进行调度。
在创建Scheduler的New函数里面,做了以下几件事情:
,创建SchedulerCache,这里面有podStates保存Pod的状态,有nodes保存节点的状态,整个调度任务是完成两者的匹配。
schedulerCache := internalcache.New(30*time.Second, stopEverything)第二,创建volumeBinder,因为调度很大程度上和Volume是相关的,有可能因为要求某个Pod需要满足一定大小或者条件的Volume,而这些Volume只能在某些节点上才能被挂载。
volumeBinder := scheduling.NewVolumeBinder(client,informerFactory.Core().V1().Nodes(),informerFactory.Storage().V1().CSINodes(),informerFactory.Core().V1().PersistentVolumeClaims(),informerFactory.Core().V1().PersistentVolumes(),informerFactory.Storage().V1().StorageClasses(),time.Duration(options.bindTimeoutSeconds)*time.Second,)
在这里面有node,CSI,PVC,PV,StorageClass的Inoformer都会创建来监听变化。
第三,创建调度队列,将来尚未调度的Pod都会放在这个队列里面
podQueue := internalqueue.NewSchedulingQueue(lessFn,internalqueue.WithPodInitialBackoffDuration(time.Duration(c.podInitialBackoffSeconds)*time.Second),internalqueue.WithPodMaxBackoffDuration(time.Duration(c.podMaxBackoffSeconds)*time.Second),)
第四,创建调度算法,将来这个对象的Schedule函数会被调用进行调度
algo := core.NewGenericScheduler(c.schedulerCache,podQueue,c.nodeInfoSnapshot,extenders,c.informerFactory.Core().V1().PersistentVolumeClaims().Lister(),GetPodDisruptionBudgetLister(c.informerFactory),c.disablePreemption,c.percentageOfNodesToScore,c.enableNonPreempting,)
第五,创建调度器,组合上面所有的对象
return &Scheduler{SchedulerCache: c.schedulerCache,Algorithm: algo,Profiles: profiles,NextPod: internalqueue.MakeNextPodFunc(podQueue),Error: MakeDefaultErrorFunc(c.client, podQueue, c.schedulerCache),StopEverything: c.StopEverything,VolumeBinder: c.volumeBinder,SchedulingQueue: podQueue,}
第六,addAllEventHandlers,添加事件处理器。
func addAllEventHandlers(sched *Scheduler,informerFactory informers.SharedInformerFactory,podInformer coreinformers.PodInformer,) {// scheduled pod cachepodInformer.Informer().AddEventHandler(cache.FilteringResourceEventHandler{FilterFunc: func(obj interface{}) bool {switch t := obj.(type) {case *v1.Pod:return assignedPod(t)}},Handler: cache.ResourceEventHandlerFuncs{AddFunc: sched.addPodToCache,UpdateFunc: sched.updatePodInCache,DeleteFunc: sched.deletePodFromCache,},},)// unscheduled pod queuepodInformer.Informer().AddEventHandler(cache.FilteringResourceEventHandler{FilterFunc: func(obj interface{}) bool {switch t := obj.(type) {case *v1.Pod:return !assignedPod(t) && responsibleForPod(t, sched.Profiles)}},Handler: cache.ResourceEventHandlerFuncs{AddFunc: sched.addPodToSchedulingQueue,UpdateFunc: sched.updatePodInSchedulingQueue,DeleteFunc: sched.deletePodFromSchedulingQueue,},},)informerFactory.Core().V1().Nodes().Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: sched.addNodeToCache,UpdateFunc: sched.updateNodeInCache,DeleteFunc: sched.deleteNodeFromCache,},)// On add and delete of PVs, it will affect equivalence cache items// related to persistent volumeinformerFactory.Core().V1().PersistentVolumes().Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{// MaxPDVolumeCountPredicate: since it relies on the counts of PV.AddFunc: sched.onPvAdd,UpdateFunc: sched.onPvUpdate,},)// This is for MaxPDVolumeCountPredicate: add/delete PVC will affect counts of PV when it is bound.informerFactory.Core().V1().PersistentVolumeClaims().Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: sched.onPvcAdd,UpdateFunc: sched.onPvcUpdate,},)......}
如果Pod已经调度过,发生变化则更新Cache,如果Node发生变化更新Cache,如果Pod没有调度过,则放入队列中等待调度,PV和PVC发生变化也会做相应的处理。
创建了Scheduler之后,接下来是调用Scheduler的Run函数,运行scheduleOne进行调度。
func (sched *Scheduler) Run(ctx context.Context) {if !cache.WaitForCacheSync(ctx.Done(), sched.scheduledPodsHasSynced) {return}sched.SchedulingQueue.Run()wait.UntilWithContext(ctx, sched.scheduleOne, )sched.SchedulingQueue.Close()}
scheduleOne中的调度逻辑如下:
,从队列中获取下一个要调度的Pod
podInfo := sched.NextPod()第二,根据调度算法,选择出合适的Node,放在scheduleResult中
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, prof, state, pod)第三,在本地缓存中,先绑定Volume,真正的绑定要调用API Server将绑定信息放在ETCD里面,但是因为调度器不能等写入ETCD后再调度下一个,这样太慢了,因而在本地缓存中绑定后,同一个Volume,其他的Pod调度的时候就不会使用了。
allBound, err := sched.VolumeBinder.AssumePodVolumes(assumedPod, scheduleResult.SuggestedHost)第四,在本地缓存中,绑定Node,原因类似
// assume modifies `assumedPod` by setting NodeName=scheduleResult.SuggestedHosterr = sched.assume(assumedPod, scheduleResult.SuggestedHost)
第五,通过API Server的客户端做真正的绑定,是异步操作
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).go func() {......err := sched.bindVolumes(assumedPod)......err := sched.bind(bindingCycleCtx, prof, assumedPod, scheduleResult.SuggestedHost, state)}
接下来我们来看调度算法的Schedule函数
// Schedule tries to schedule the given pod to one of the nodes in the node list.// If it succeeds, it will return the name of the node.// If it fails, it will return a FitError error with reasons.func (g *genericScheduler) Schedule(ctx context.Context, prof *profile.Profile, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {......filteredNodes, filteredNodesStatuses, err := g.findNodesThatFitPod(ctx, prof, state, pod)......priorityList, err := g.prioritizeNodes(ctx, prof, state, pod, filteredNodes)......host, err := g.selectHost(priorityList)......return ScheduleResult{SuggestedHost: host,EvaluatedNodes: len(filteredNodes) + len(filteredNodesStatuses),FeasibleNodes: len(filteredNodes),}, err}
Schedule算法做了以下的事情:
findNodesThatFitPod:根据所有预选算法过滤符合的node列表
prioritizeNodes: 对符合的节点进行优选评分,一个排序的列表
selectHost:对优选的 node 列表选择一个优的节点
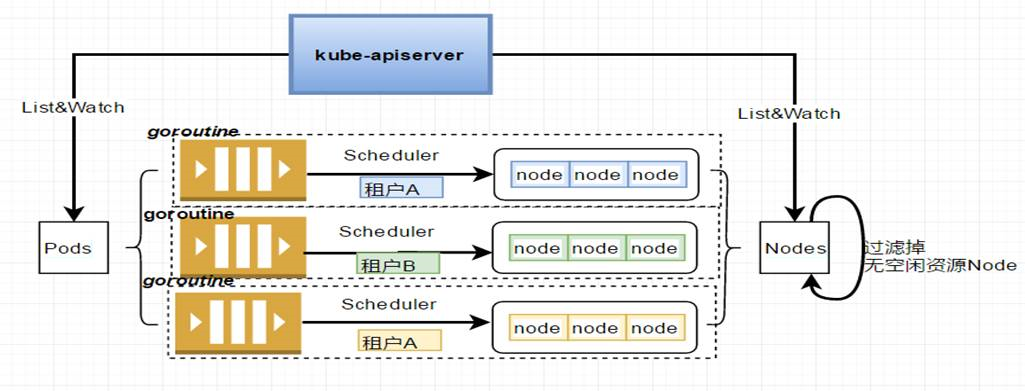
对于大的资源池的调度是一个很大的问题,因为同样一个资源只能被一个任务使用,如果串行调度,可能会调度比较慢。如果并行调度,则存在两个并行的调度器同时认为某个资源空闲,于是同时将两个任务调度到同一台机器,结果出现竞争的情况。
Kubernetes有这样一个参数percentageOfNodesToScore,也即每次选择节点的时候,只从一部分节点中选择,这样可以改进调度效率。
为了租户隔离,不同的租户是不共享虚拟机的,这样不同的租户是可以并行调度的。因为不同的租户即便进行并行调度,也不会出现冲突的现象,每个租户不是在几万个节点中进行调度,而仅仅在属于这个租户的有限的节点中进行调度,大大提高了调度策略。
第四节,Kubernetes CNI原理与网络设计
控制面看完了,我们接着看数据面,先来看网络数据面。
数据面的解析分为两个部分,一个是CNI,一个是ingress
4.1. CNI原理与定制化设计
就像上面兼容性那一节讲的一样,如果你不想用默认的网络组建,可以自己开发CNI来对接公司的SDN。
我们这里就来解析一下CNI的原理。
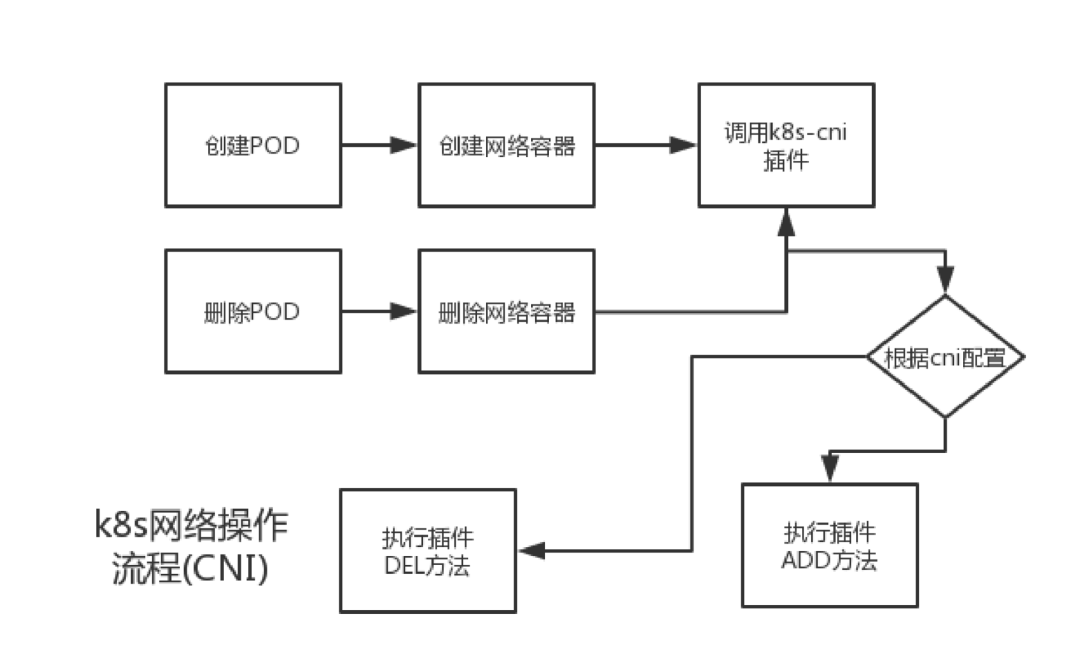
CNI是Container Network Interface的是一个标准的,通用的接口,用于连接容器管理系统和网络插件。
CNI插件是可执行文件,会被kubelet调用。启动kubelet --network-plugin=cni,--cni-conf-dir 指定networkconfig配置,默认路径是:/etc/cni/net.d,并且,--cni-bin-dir 指定plugin可执行文件路径,默认路径是:/opt/cni/bin。
CNI plugin 只需要通过 CNI 库实现两类方法, 分别是创建容器时调用, 以及删除容器时调用.
三种类型的插件:main,meta和ipam:
main插件:提供某种网络功能,比如使用的brdige,以及loopback,ipvlan,macvlan等等
meta插件:不能作为独立的插件使用,需要调用其他插件,例如flannel,或者配合其他插件使用,例如portmap
ipam插件:对所有CNI插件共有的IP管理部分的抽象,从而减少插件编写过程中的重复工作,官方提供的有dhcp和host-local两种类型
在这里面有一些CNI插件的实现:
(https://github.com/containernetworking/plugins)
每一种K8S网络方案也要有自己的CNI插件,例如上面我们讲的Calico,我们这里解析一下他的插件实现。
(https://github.com/projectcalico/cni-plugin)
calico 解决不同物理机上容器之间的通信,而 calico-plugin 是在 k8s 创建 Pod 时为 Pod 设置虚拟网卡(容器中的 eth0和 lo 网卡),calico-plugin 是由两个静态的二进制文件组成,由 kubelet 以命令行的形式调用,这两个二进制的作用如下:
calico-ipam:分配维护IP,依赖etcd
calico:系统调用API来修改namespace中的网卡信息
在Calico插件里面,会注册两个函数cmdAdd和cmdDel,用于对应添加网卡和删除网卡两个操作。
我们这里重点分析cmdAdd。
,获取Calico的配置,节点的名称,Calico客户端,是为了生成这个Pod的WEP(Workload Endpoint)名称,也即网卡的名称。
// Unmarshal the network config, and perform validationconf := *.NetConf{}// Determine which node name to use.nodename := utils.DetermineNodename(conf)// Extract WEP identifiers such as pod name, pod namespace (for k8s), containerID, IfName.wepIDs, err := utils.GetIdentifiers(args, nodename)calicoClient, err := utils.CreateClient(conf)// Calculate the workload name prefix from the WEP specific identifiers// for the given orchestrator.wepPrefix, err := wepIDs.CalculateWorkloadEndpointName(true)// Check if there's an existing endpoint by listing the existing endpoints based on the WEP name prefix.endpoints, err := calicoClient.WorkloadEndpoints().List(ctx, options.ListOptions{Name: wepPrefix, Namespace: wepIDs.Namespace, Prefix: true})var endpoint *api.WorkloadEndpointfor _, ep := range endpoints.Items {match, err := wepIDs.WorkloadEndpointIdentifiers.NameMatches(ep.Name)if match {endpoint = &ep// Assign the WEP name to wepIDs' WEPName field.wepIDs.WEPName = endpoint.Name// Put the endpoint name from the matched WEP in the identifiers.wepIDs.Endpoint = ep.Spec.Endpointbreak}}// If we don't find a match from the existing WorkloadEndpoints then we calculate// the WEP name with the IfName passed in so we can create the WorkloadEndpoint later in the process.if endpoint == nil {wepIDs.Endpoint = args.IfNamewepIDs.WEPName, err = wepIDs.CalculateWorkloadEndpointName(false)}
第二,就是将这个网卡和Pod关联起来
先是调用IPAM插件,获得一个IP地址
// 1) Run the IPAM plugin and make sure there's an IP address returned.ipamResult, err := ipam.ExecAdd(conf.IPAM.Type, args.StdinData)
然后是创建endpoint对象
// 2) Create the endpoint objectendpoint = api.NewWorkloadEndpoint()endpoint.Name = wepIDs.WEPNameendpoint.Namespace = wepIDs.Namespaceendpoint.Spec.Endpoint = wepIDs.Endpointendpoint.Spec.Node = wepIDs.Nodeendpoint.Spec.Orchestrator = wepIDs.Orchestratorendpoint.Spec.ContainerID = wepIDs.ContainerIDendpoint.Labels = labelsendpoint.Spec.Profiles = []string{profileID}
然后是对于网络的配置
// 3) Set up the vethd, err := dataplane.GetDataplane(conf, logger)// Select the first 11 characters of the containerID for the host veth.desiredVethName := "cali" + args.ContainerID[:utils.Min(11, len(args.ContainerID))]hostVethName, contVethMac, err := d.DoNetworking(args, result, desiredVethName, utils.DefaultRoutes, endpoint, map[string]string{})endpoint.Spec.MAC = contVethMacendpoint.Spec.InterfaceName = hostVethName
在DoNetworking里面,我们看到的是对于网络的配置命令。
先是建立veth pair,一边是contVethName,将来是容器内的,另一边是hostVethName,将来是容器外的。
veth := &netlink.Veth{LinkAttrs: netlink.LinkAttrs{Name: contVethName,Flags: net.FlagUp,MTU: d.mtu,},PeerName: hostVethName,}netlink.LinkAdd(veth)
然后给容器外的网卡设置MAC地址,状态设置为UP
hostVeth, err := netlink.LinkByName(hostVethName)netlink.LinkSetHardwareAddr(hostVeth, mac)netlink.LinkSetUp(hostVeth)
然后给容器内的网卡设置MAC地址,IP地址,路由等
// Fetch the MAC from the container Veth. This is needed by Calico.contVethMAC = contVeth.Attrs().HardwareAddr.String()// Add a connected route to a dummy next hop so that a default route can be setgw := net.IPv4(169, 254, 1, 1)gwNet := &net.IPNet{IP: gw, Mask: net.CIDRMask(32, 32)}err := netlink.RouteAdd(&netlink.Route{LinkIndex: contVeth.Attrs().Index,Scope: netlink.SCOPE_LINK,Dst: gwNet,},)for _, r := range routes {ip.AddRoute(r, gw, contVeth)}// Now add the IPs to the container side of the veth.for _, addr := range result.IPs {netlink.AddrAdd(contVeth, &netlink.Addr{IPNet: &addr.Address})}d.configureContainerSysctls(hasIPv4, hasIPv6)
然后将host端的网卡从容器移出去,配置路由
// Now that the everything has been successfully set up in the container, move the "host" end of the// veth into the host namespace.netlink.LinkSetNsFd(hostVeth, int(hostNS.Fd()))d.configureSysctls(hostVethName, hasIPv4, hasIPv6)// Moving a veth between namespaces always leaves it in the "DOWN" state. Set it back to "UP" now that we're// back in the host namespace.hostVeth, err := netlink.LinkByName(hostVethName)netlink.LinkSetUp(hostVeth)// Now that the host side of the veth is moved, state set to UP, and configured with sysctls, we can add the routes to it in the host namespace.SetupRoutes(hostVeth, result)
理解了CNI的工作原理,我们也可以开发自己的插件,和自己原来的网络环境相融合。
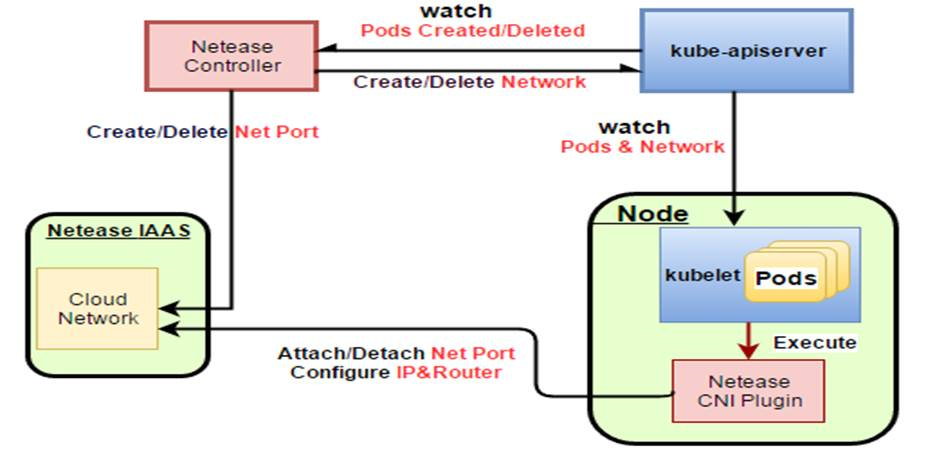
容器的网卡是直接连接到虚拟私有网络的OVS上的,和虚拟机是一个平的二层网络,在OVS来看,容器和虚拟机是在同一个网络里面的。
这样一方面没有了二次虚拟化,只有OVS一层虚拟化。另外容器和虚拟机网络打平的好处是,当部分应用部署容器,部分应用部署虚拟机的时候,对应用没有侵入,应用原来如何相互访问,现在还是如何访问,有利于应用逐步容器化。

4.2. Ingress原理与定制化设计
容器内外互通常用的方式就是Ingress,默认的是ingress-nginx。
创建ingress-nginx的流程如下
apiVersion: v1kind: Servicemetadata:labels:: ingress-nginx-2.4.0: ingress-nginx: ingress-nginx: 0.33.0: Helm: controllername: ingress-nginx-controllernamespace: ingress-nginxspec:type: NodePortports:name: httpport: 80protocol: TCPtargetPort: httpname: httpsport: 443protocol: TCPtargetPort: httpsselector:: ingress-nginx: ingress-nginx: controller---apiVersion: apps/v1kind: Deploymentmetadata:labels:: ingress-nginx-2.4.0: ingress-nginx: ingress-nginx: 0.33.0: Helm: controllername: ingress-nginx-controllernamespace: ingress-nginxspec:selector:matchLabels:: ingress-nginx: ingress-nginx: controllerrevisionHistoryLimit: 10minReadySeconds:template:metadata:labels:: ingress-nginx: ingress-nginx: controllerspec:dnsPolicy: ClusterFirstcontainers:name: controllerimage: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.33.0imagePullPolicy: IfNotPresent:/nginx-ingress-controller--election-id=ingress-controller-leader--ingress-class=nginx--configmap=ingress-nginx/ingress-nginx-controller--validating-webhook=:8443--validating-webhook-certificate=/usr/local/certificates/cert--validating-webhook-key=/usr/local/certificates/key: 101allowPrivilegeEscalation: trueenv:name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.namename: POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace:name: httpcontainerPort: 80protocol: TCPname: httpscontainerPort: 443protocol: TCPname: webhookcontainerPort: 8443protocol: TCPvolumeMounts:name: webhook-certmountPath: /usr/local/certificates/readOnly: trueresources:requests:cpu: 100mmemory: 90Mi---
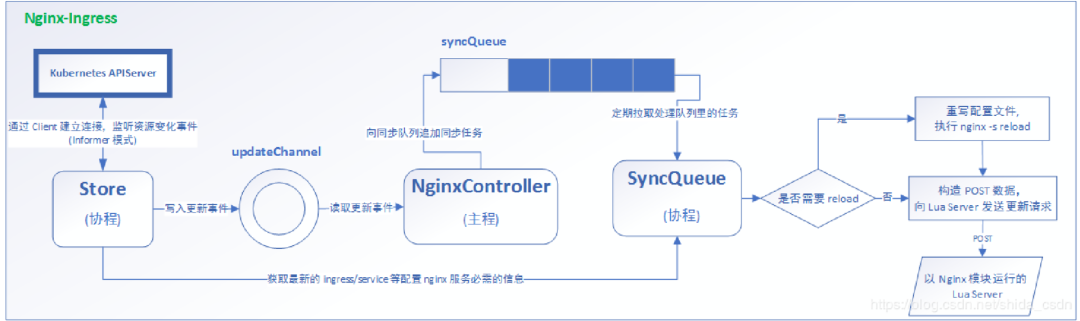
借用网上的一张图说明工作原理,外部负载均衡器请求调至到 nodeport 里面service服务,Service转发到Ingress Controller所在的Pod,这里面Ingress Controller就像其他的Controller一样和API Server进行通信,另外还有nginx做反向代理。
如果客户改变ingress规则,Ingress Controller 通过与 Kubernetes API 交互,动态的去感知集群中 Ingress 规则变化,然后读取他,按照他自己模板生成一段 Nginx 配置,再写到 Nginx Pod 里,后 reload 一下。
在Ngnix的配置中,后端是一个Service,可以在多个Pod之间做负载均衡。

下面我们看一下Ingress Controller的实现,这里面的很多概念和controller-manager里面非常像
(https://github.com/kubernetes/ingress-nginx)
在nginx controller里面,先创建连接API Server的客户端,然后创建NGINXController,然后启动他。
kubeClient, err := createApiserverClient(conf.APIServerHost, conf.RootCAFile, conf.KubeConfigFile)conf.Client = kubeClientngx := controller.NewNGINXController(conf, mc)go ngx.Start()
在NewNGINXController中,做了下面几件事情
,创建NGINXController对象
n := &NGINXController{: ing_net.IsIPv6Enabled(),resolver: h,cfg: config,: flowcontrol.NewTokenBucketRateLimiter(config.SyncRateLimit, 1),recorder: eventBroadcaster.NewRecorder(scheme.Scheme, apiv1.EventSource{Component: "nginx-ingress-controller",}),stopCh: make(chan struct{}),: channels.NewRingChannel(1024),: make(chan error),: &sync.Mutex{},: new(ingress.Configuration),: &TCPProxy{},: mc,command: NewNginxCommand(),}
第二,创建store对象
n.store = store.New(config.Namespace,config.ConfigMapName,config.TCPConfigMapName,config.UDPConfigMapName,config.DefaultSSLCertificate,config.ResyncPeriod,config.Client,n.updateCh,pod,config.DisableCatchAll)
这个对象非常的重要,从定义可以看出,这里面有Informer,Lister可以监控API Server中的变化。
store := &k8sStore{informers: &Informer{},listers: &Lister{},sslStore: NewSSLCertTracker(),updateCh: updateCh,backendConfig: ngx_config.NewDefault(),syncSecretMu: &sync.Mutex{},backendConfigMu: &sync.RWMutex{},secretIngressMap: NewObjectRefMap(),defaultSSLCertificate: defaultSSLCertificate,pod: pod,}
接下来就是创建informer了
// create informers factory, enable and assign required informersinfFactory := informers.NewSharedInformerFactoryWithOptions(client, resyncPeriod,informers.WithNamespace(namespace),informers.WithTweakListOptions(tweakListOptionsFunc))store.informers.Ingress = infFactory.Networking().V1beta1().Ingresses().Informer()store.informers.Endpoint = infFactory.Core().V1().Endpoints().Informer()store.informers.Service = infFactory.Core().V1().Services().Informer()
接下来就是创建当接收到变化事件后的处理函数
ingEventHandler := cache.ResourceEventHandlerFuncs{AddFunc: func(obj interface{}) {ing, _ := toIngress(obj)store.syncIngress(ing)store.updateSecretIngressMap(ing)store.syncSecrets(ing)updateCh.In() <- Event{Type: CreateEvent,Obj: obj,}},DeleteFunc: ingDeleteHandler,UpdateFunc: func(old, cur interface{}) {......},}
当有变化,创建Ingress的时候,会放一个Event到updateCh中。
我们回到NewNGINXController函数中
第三,创建Ingress的syncQueue,每往syncQueue插入一个Ingress对象,就会调用syncIngress
n.syncQueue = task.NewTaskQueue(n.syncIngress)创建完NewNGINXController之后,接着是启动他
// Start starts a new NGINX master process running in the foreground.func (n *NGINXController) Start() {klog.Info("Starting NGINX Ingress controller")n.store.Run(n.stopCh)......cmd := n.command.ExecCommand()......klog.Info("Starting NGINX process")n.start(cmd)go n.syncQueue.Run(time.Second, n.stopCh)......for {select {......case event := <-n.updateCh.Out():if evt, ok := event.(store.Event); ok {klog.V(3).Infof("Event %v received - object %v", evt.Type, evt.Obj)n.syncQueue.EnqueueSkippableTask(evt.Obj)} else {klog.Warningf("Unexpected event type received %T", event)}......}}
在这里面运行Store监听变化的事件,事件Event会放入updateCh,然后NGINXController会从updateCh中取出后,放入syncQueue,从而触发syncIngress函数,在这里面会调用OnUpdate函数。
// OnUpdate is called by the synchronization loop whenever configuration// changes were detected. The received backend Configuration is merged with the// configuration ConfigMap before generating the final configuration file.// Returns nil in case the backend was successfully reloaded.func (n *NGINXController) OnUpdate(ingressCfg ingress.Configuration) error {cfg := n.store.GetBackendConfiguration()cfg.Resolver = n.resolvercontent, err := n.generateTemplate(cfg, ingressCfg)......err = n.testTemplate(content)......err = ioutil.WriteFile(cfgPath, content, file.ReadWriteByUser)......o, err := n.command.ExecCommand("-s", "reload").CombinedOutput()......}
在这里面修改了nginx的配置,并且重新reload,使得新的ingress配置生效。
讲明白了Ingress Controller的原理之后,其实我们也可以实现自己的Ingress Controller,在这里面实现更加丰富的API网关的功能,例如和分流,路由,限流等节后起来。
例如业内知名的API网关Kong就有对应的Kong Ingress Controller,Kong有大量丰富的插件,可以实现很多的功能。
第五节,Kubernetes CSI原理与存储设计
讲完了网络数据面,接下来,我们来解析存储。
我们在数据中心能够碰到的存储设备有以下的类型:
对象存储:公有云的S3,私有云OpenStack的Swift
本地盘
开源文件系统:Ceph FS,GlusterFS
开源块存储:Ceph RBD
商业化存储:NAS,SAN
公有云块存储:awsElasticBlockStore,azureDisk,gcePersistentDisk
如果我们使用K8S,如何将这些存储统一的管理起来呢?
对于对象存储比较简单,使用标准的S3接口进行访问即可,不涉及到卷的挂载,也不需要K8S进行管理。
K8S作为一个主流的开源容器平台,有很多主流的存储是默认支持的,例如本地盘,Ceph,以及主流公有云平台的块存储等。支持这些存储的代码逻辑都是在K8S代码中运行的,我们称为In-Tree方式。
但是作为很多企业讲K8S做为私有云平台进行部署,会有一些商业化的NAS和SAN需要进行对接,这就要用到CSI接口。
5.1. CSI设计原理与实践
CSI全称Container Storage Interface,主要目标是将任意存储系统都可以通过标准的接口暴露给容器化的应用。
他的架构如下:

要实现一个CSI,需要两部分组件,一部分由Kubernetes提供,一部分需要接入的第三方存储要自己进行开发。
这些组件又分为两个维度,一个和Kubernetes Master节点通信,提供存储对象的生命周期管理,一个和Kubernetes Node节点通信,提供卷的挂载等操作。
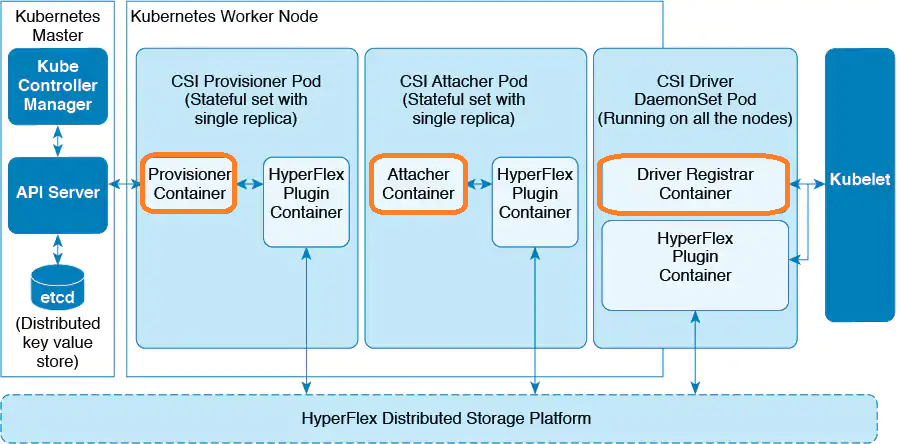
我们以一个商业化存储的图为例子,并结合一个Volume的生命周期,解析一下这些组件。

CreateVolume方法对应创建卷, ControllerPublishVolume代表attach卷到对应kubelet节点, 而NodePublishVolume对应mount卷到对应目录, NodeUnpublishVolume 代表unmount方法, ControllerUnpublishVolume 代表detach流程. 需要注意的是, attach和detach都是以节点为单位, 并不能具体到pod上.
External Provisioner是Kubernetes 提供的 sidecar 容器,不需要自己开发,它监听 PersistentVolumeClaim 对象的变化情况,并调用自己写的 CSI 插件的 CreateVolume 和 DeleteVolume 等 API 管理 Volume。因而配合External Provisioner,需要针对商业化存储写一个CSI插件,主要调用商业化存储的管控接口来创建Volume,这部分自己实现的CSI插件对应图中的CSI Controller,也需要Identity来提供认证。
External Attacher也是Kubernetes 提供的 sidecar 容器,不需要自己开发,它监听 VolumeAttachment 和 PersistentVolume 对象的变化情况,并调用 自己写的CSI 插件的 ControllerPublishVolume 和 ControllerUnpublishVolume 等 API 将 Volume 挂载或卸载到指定的 Node 上。因而配合External Attacher,需要针对商业化存储写一个CSI插件,主要调用商业化存储的管控接口,让刚才创建的Volume挂载到Node上,这部分自己实现的CSI插件对应图中的CSI Controller,也需要Identity来提供认证。
node-driver-registrar以DaemonSet的方式运行在每一个Node上,负责注册自己开发的 CSI 插件到 kubelet 中,并初始化 NodeId(即给 Node 对象增加一个 Annotation csi.volume.kubernetes.io/nodeid)。因而配合node-driver-registrar,需要针对商业化存储写一个CSI插件,也是以DaemonSet的方式运行在每个Node上,负责NodePublishVolume 挂载和NodeUnpublishVolume
解挂载Volume到容器。这部分自己实现的CSI插件对应图中的CSI Node,也需要Identity来提供认证。
从这里https://kubernetes-csi.github.io/docs/drivers.html我们能找到很多CSI的范例。
大家可能对于Ceph熟一些,可以参考https://github.com/ceph/ceph-csi.git来写自己的CSI。
在Ceph的CSI的实现了IdentityServer,ControllerServer,NodeServer
// NewIdentityServer initialize a identity server for rbd CSI driverfunc NewIdentityServer(d *csicommon.CSIDriver) *IdentityServer {return &IdentityServer{DefaultIdentityServer: csicommon.NewDefaultIdentityServer(d),}}// NewControllerServer initialize a controller server for rbd CSI driverfunc NewControllerServer(d *csicommon.CSIDriver, cachePersister util.CachePersister) *ControllerServer {return &ControllerServer{DefaultControllerServer: csicommon.NewDefaultControllerServer(d),MetadataStore: cachePersister,VolumeLocks: util.NewVolumeLocks(),SnapshotLocks: util.NewVolumeLocks(),}}// NewNodeServer initialize a node server for rbd CSI driver.func NewNodeServer(d *csicommon.CSIDriver, t string, topology map[string]string) (*NodeServer, error) {mounter := mount.New("")return &NodeServer{DefaultNodeServer: csicommon.NewDefaultNodeServer(d, t, topology),mounter: mounter,VolumeLocks: util.NewVolumeLocks(),}, nil}
其中ControllerServer里面有CreateVolume是创建Volume的,里面调用Ceph RBD的接口来创建卷。
// CreateVolume creates the volume in backendfunc (cs *ControllerServer) CreateVolume(ctx context.Context, req *csi.CreateVolumeRequest) (*csi.CreateVolumeResponse, error) {......err = rbdVol.Connect(cr)......rbdSnap, err := cs.checkSnapshotSource(ctx, req, cr)......err = reserveVol(ctx, rbdVol, rbdSnap, cr)......err = createBackingImage(ctx, cr, rbdVol, rbdSnap)......volumeContext := req.GetParameters()volumeContext["pool"] = rbdVol.PoolvolumeContext["journalPool"] = rbdVol.JournalPoolvolumeContext["imageName"] = rbdVol.RbdImageNamevolume := &csi.Volume{VolumeId: rbdVol.VolID,CapacityBytes: rbdVol.VolSize,VolumeContext: volumeContext,ContentSource: req.GetVolumeContentSource(),}return &csi.CreateVolumeResponse{Volume: volume}, nil}
NodeServer里面有NodePublishVolume,就是挂载卷的
// NodePublishVolume mounts the volume mounted to the device path to the target// pathfunc (ns *NodeServer) NodePublishVolume(ctx context.Context, req *csi.NodePublishVolumeRequest) (*csi.NodePublishVolumeResponse, error) {......targetPath := req.GetTargetPath()isBlock := req.GetVolumeCapability().GetBlock() != nilstagingPath := req.GetStagingTargetPath()volID := req.GetVolumeId()stagingPath += "/" + volID......// Check if that target path exists properlynotMnt, err := ns.createTargetMountPath(ctx, targetPath, isBlock)......// Publish Patherr = ns.mountVolume(ctx, stagingPath, req)......return &csi.NodePublishVolumeResponse{}, nil}
5.2. StorageClass原理分析与实践
有了CSI之后,无论是开源的,本来K8S都支持的存储,还是自己采购的商业化存储,都能够统一管理起来了,接下来就要根据不同的场景,使用不同的存储。
例如需要性能特别好的,而且需要有更加可靠的备份容灾策略的,可以使用商业化存储,如数据库之类的应用。
那如何标注不同类型的存储呢?这就是StorageClass。
对于K8S本身就支持的存储类型,例如AWS, Azure, GCEPersistentDisk,RBD,Glusterfs,这些都是Internal Provisioner。
apiVersion: storage.k8s.io/v1kind: StorageClassmetadata:name: standardprovisioner: kubernetes.io/aws-ebsparameters:type: gp2reclaimPolicy: RetainallowVolumeExpansion: truemountOptions:debugvolumeBindingMode: Immediate
对于K8S本身不支持,但是我们自己通过开发CSI插件的存储,称为External provisoner。
kind: StorageClassapiVersion: storage.k8s.io/v1metadata:name: fast-storageprovisioner: csi-driver.example.comparameters:type: pd-ssd: mysecret: mynamespace
5.3. FlexVolume
在没有CSI标准接口的时候,对于其他非原生存储的接入,都是使用FlexVolume。
他的实现比较简单,主要通过exec运行脚本的形式实现,没有对于卷的生命周期管理。
FlexVolume插件放在/usr/libexec/kubernetes/kubelet-plugins/volume/exec/<vendor~driver>/<driver> 目录中。
主要实现下面的接口:
init:kubelet/kube-controller-manager 初始化存储插件时调用,插件需要返回是否需要要 attach 和 detach 操作
attach:将存储卷挂载到 Node 上
detach:将存储卷从 Node 上卸载
waitforattach:等待 attach 操作成功(超时时间为 10 分钟)
isattached:检查存储卷是否已经挂载
mountdevice:将设备挂载到指定目录中以便后续 bind mount 使用
unmountdevice:将设备取消挂载
mount:将存储卷挂载到指定目录中
umount:将存储卷取消挂载
5.4. PV和PVC
PersistentVolume(pv)和PersistentVolumeClaim(pvc)是k8s提供的两种API资源,用于抽象存储细节。
运维人员更多关注于如何通过PV提供存储功能而无需关注用户如何使用。
用户只需要挂载PVC到容器中而不需要关注存储卷采用何种技术实现。
创建PV和PVC的时候,可以根据不同的需求,指定不同的StorageClass。
apiVersion: v1kind: PersistentVolumemetadata:name: pv0003spec:capacity:storage: 5GivolumeMode: FilesystemaccessModes:ReadWriteOncepersistentVolumeReclaimPolicy: RecyclestorageClassName: slowmountOptions:hardnfsvers=4.1nfs:path: /tmpserver: 172.17.0.2
5.5. 本地盘hostpath和local
有的时候,我们需要性能,可能会使用本地盘,目前K8S有两种方式。
hostPath类型则是映射node文件系统中的文件或者目录到pod里。在使用hostPath类型的存储卷时,也可以设置type字段,支持的类型有文件、目录、File、Socket、CharDevice和BlockDevice。
例如当运行的容器需要访问Docker内部结构时,如使用hostPath映射/var/lib/docker到容器。
配置相同的pod(如通过podTemplate创建),可能在不同的Node上表现不同,因为不同节点上映射的文件内容不同。
当Kubernetes增加了资源敏感的调度程序,hostPath使用的资源不会被计算在内。
宿主机下创建的目录只有root有写权限。你需要让你的程序运行在privileged container上,或者修改宿主机上的文件权限。
Local volume 允许用户通过标准PVC接口以简单且可移植的方式访问node节点的本地存储。PV的定义中需要包含描述节点亲和性的信息,k8s系统则使用该信息将容器调度到正确的node节点。
使用local-volume插件时,要求使用到了存储设备名或路径都相对固定,不会随着系统重启或增加、减少磁盘而发生变化。
静态provisioner配置程序仅支持发现和管理挂载点(对于Filesystem模式存储卷)或符号链接(对于块设备模式存储卷)。 对于基于本地目录的存储卷,必须将它们通过bind-mounted的方式绑定到发现目录中。
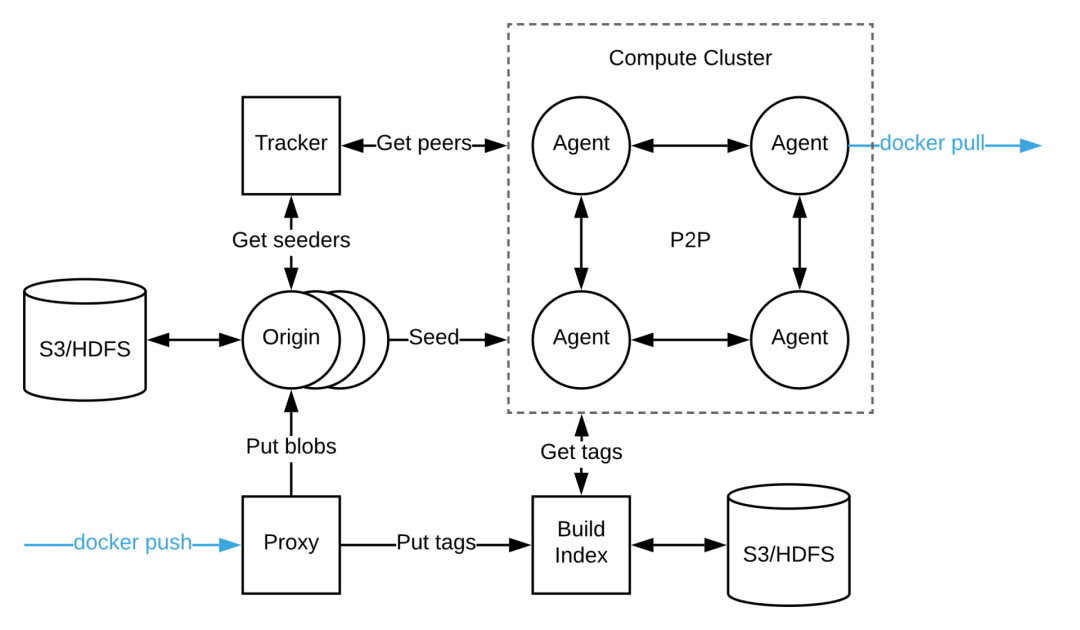
第六节,镜像仓库设计与大规模下载优化
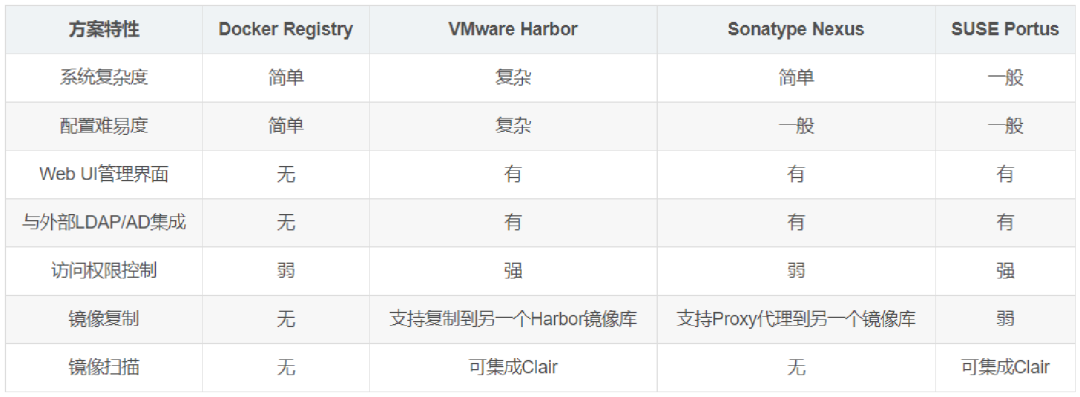
管理一个大规模的容器平台,对于镜像仓库的设计也是很重要的。目前的选型有以下几种。
首先我们来研究一下容器镜像组成,包含以下的信息
Manifest:包含特定平台、os的镜像信息、包含layer\config描述和digest信息
Config:容器运行时需要用到的rootfs的变更和执行参数
layer:包含了文件系统的信息,即该image包含了哪些文件/目录,以及它们的属性和数据。
tar+gzip

那镜像是如何下发的呢?
把tag解析为对应的manifest
获取manifest,查找本地不存在的层
下载层(tar.gz文件)
解压
通过解析镜像的格式以及下发过程,我们可以总结出影响镜像分发速度因素
镜像大小
网络带宽
并发数
有改动的层的大小
那如何加速镜像下发呢?
减少镜像层数,删除非必要文件
尽量使用相同的base image
base镜像预拉取
多阶段构建
使用nginx 缓存
使用工具(如docker-slim)压缩镜像
后端使用对象存储
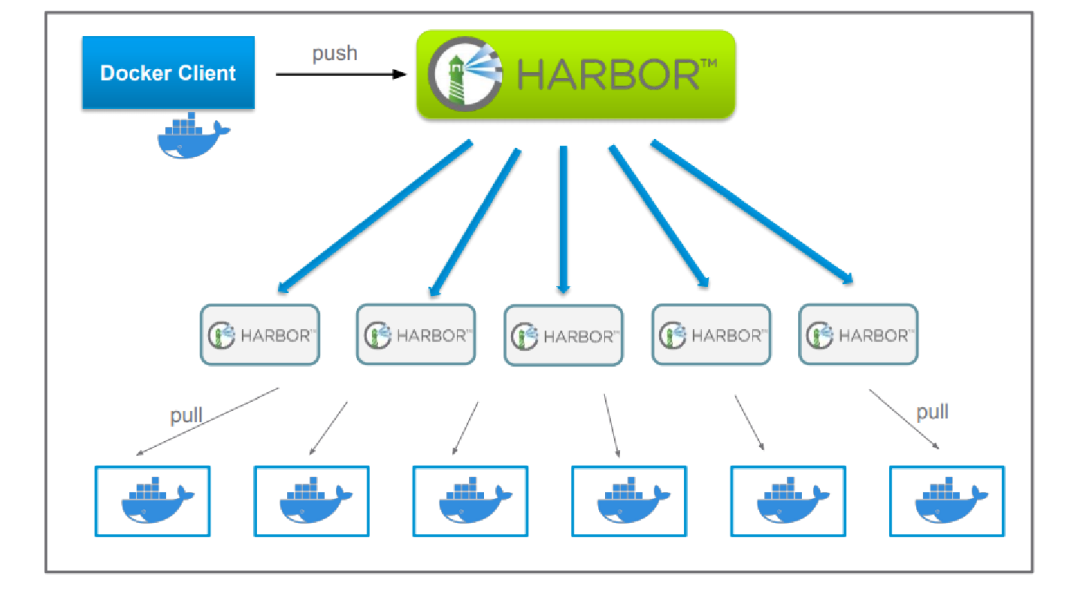
如果这些措施都使用了,还是不能解决性能瓶颈问题,一种方式是Harbor replication,通过复制多个Harbor的方式,分担下载压力。
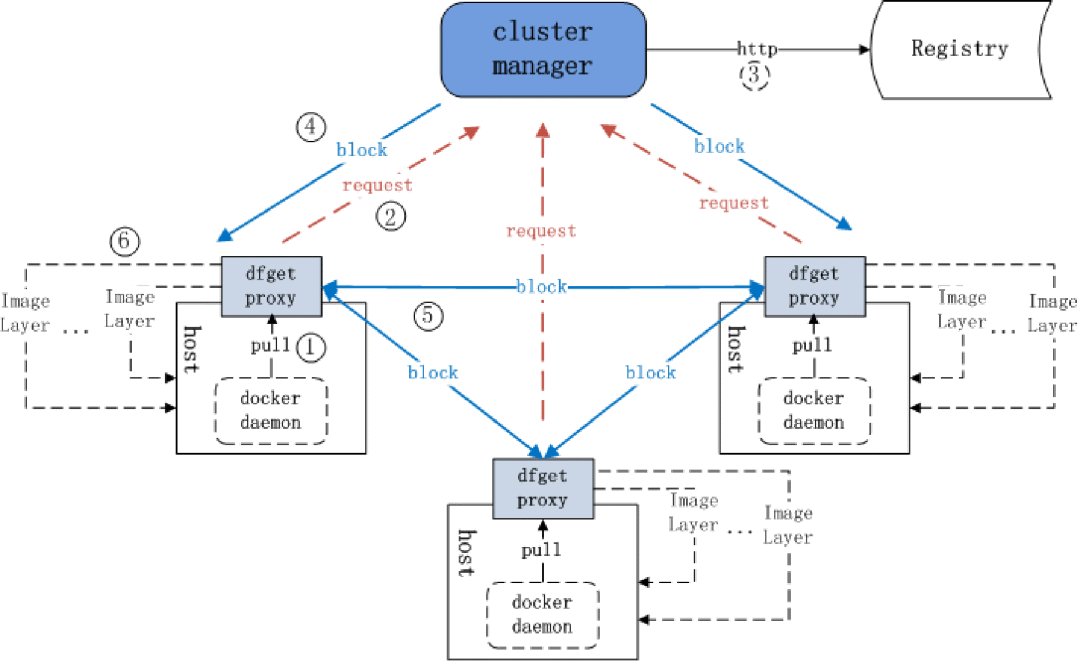
另外就是使用P2P协议,主流的有两种实现方式。
种方式是Dragonfly p2p
基于P2P的分发
主机级别的限速
CDN机制,防止缓存击穿机制
文件一致性保证,通过对piece进行算法摘要
磁盘保护,磁盘空间检查
容错,隔离,节点故障恢复等
节点注册机制,任务管理,bitmap管理。
平均分配piece。优先分发数量少的piece,使piece在peer上的数量近似,从而防止资源拥挤。节点间的负载均衡。平衡节点的上传、下载的piece数量。
还有一种方式是Uber Kraken p2p
相比dragonfly,去除了超级节点的依赖,tracker只负责生成peer的一个随机稀疏图。
Kraken有更好的HA架构,一致性hash ring。
Kraken专为docker image P2P分发而开发,支持kraken集群复制,更好的设计,origin和buildIndex,作为仓库是闭环的。
Kraken具有更好的大对象分发机制,对不超过100G的对象支持更好。
以bitTorrent为基础协议,做了优化,后期有计划兼容
Kraken使用了localDB,localRedis,各种算法,使架构更加复杂。
Kraken没有按照piece的粒度去分发,而是按照blob的方式,如果不从origin推送,就不会提前生成metaInfo文件,会影响性能。
Kraken因为cache的缘故,会导致相同tag的重复推送无法立刻拉取。
第七节,Kubernetes升级,备份,双活
对于Kubernetes的升级,官网有比较完整的文档和步骤,即通过kubeadm进行升级。
https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
需要注意的是,每次只能从一个次版本升级到下一个次版本,或者同样次版本的补丁版。也就是说,升级时无法跳过版本。例如,您只能从 1.y 升级到 1.y+1,而不能从 from 1.y 升级到 1.y+2。
升级后,因为容器 spec 哈希值已更改,所以所有容器都会重新启动。
虽然文档中比较顺利,但是真正升级的时候,可能会遇到各种各样的问题,因为这里升级的是K8S的主要组件,而外围的插件是否还能顺利工作,安装过程中额外需要配置的权限,证书,角色等都会导致升级不成功。
所以需要注意的是,要做好备份工作,好在K8S的所有的状态都在ETCD里面,因而可以通过备份和恢复ETCD的方式,在升级遇到问题的时候,可以进行恢复。
ETCD的备份可通过以下的命令
etcdctl snapshot --endpoints=$ETCD_SERVERS --cacert=/var/lib/etcd/cert/ca.pem --cert=/var/lib/etcd/cert/etcd-client.pem --key=/var/lib/etcd/cert/etcd-client-key.pem save /var/lib/etcd_backup/backup_$(date "+%Y%m%d%H%M%S").db
可以通过cronjob,定时将ETCD的备份数据上传到对象存储上。
ETCD的恢复可以通过以下的命令
set -xexport ETCD_NAME=$(cat /usr/lib/systemd/system/etcd.service|grep ExecStart|grep -Eo "name.*-name-[0-9].*--client"|awk '{print $2}')export ETCD_CLUSTER=$(cat /usr/lib/systemd/system/etcd.service|grep ExecStart|grep -Eo "initial-cluster.*--initial"|awk '{print $2}')export ETCD_INITIAL_CLUSTER_TOKEN=$(cat /usr/lib/systemd/system/etcd.service|grep ExecStart|grep -Eo "initial-cluster-token.*"|awk '{print $2}')export ETCD_INITIAL_ADVERTISE_PEER_URLS=$(cat /usr/lib/systemd/system/etcd.service|grep ExecStart|grep -Eo "initial-advertise-peer-urls.*--listen-peer"|awk '{print $2}')ETCDCTL_API=3 etcdctl snapshot --cacert=/var/lib/etcd/cert/ca.pem --cert=/var/lib/etcd/cert/etcd-client.pem --key=/var/lib/etcd/cert/etcd-client-key.pem restore /var/lib/etcd_backup/backup_xxx.db \--name $ETCD_NAME \--data-dir /var/lib/etcd/data.etcd \--initial-cluster $ETCD_CLUSTER \--initial-cluster-token $ETCD_INITIAL_CLUSTER_TOKEN \--initial-advertise-peer-urls $ETCD_INITIAL_ADVERTISE_PEER_URLSchown -R etcd:etcd /var/lib/etcd/data.etcd
还有一种更加稳妥的方式就是通过多集群,也即下面的总分总模型。

个总:统一发布平台对接统一的多K8s管理平台,有统一的灰度发布策略。
第二个分,在一个数据中心或者跨数据中心可部署多套Kubernetes,不建议一个K8S跨多个机房,但要保持网络连通性。
第三个总,应用虽部署在多个Kubernetes中,但应使用统一服务治理中心,形成统一的视图,可通过染色识别当前的kubernetes即可
优势:应用层和容器层界限明确且统一管理,并统一适配租户和环境,有利于控制升级风险
当K8S处于稳态的时候,通过统一发布平台在多个集群实现应用层的灰度发布
当K8S需要升级的时候(社区三个月一个版本,无法跨版本升级),统一应用视图可以在一个集群因升级导致所有副本全挂的情况下,将流量切到另一个集群
第八节,Kubernetes容器跨数据中心分布实践
当一个Kubernetes跨多个AZ的时候,为了实现应用的高可用,需要将容器在多个AZ里面合理分布。
,Pod Topology Spread Constraints
拓扑约束依赖于节点标签来标识每个节点所在的拓扑域。
假设拥有一个具有以下标签的 4 节点集群:
NAME STATUS ROLES AGE VERSION LABELSnode1 Ready <none> 4m26s v1.16. node=node1,zone=zoneAnode2 Ready <none> 3m58s v1.16. node=node2,zone=zoneAnode3 Ready <none> 3m17s v1.16. node=node3,zone=zoneBnode4 Ready <none> 2m43s v1.16. node=node4,zone=zoneB
可以定义一个或多个 topologySpreadConstraint 来指示 kube-scheduler 如何将每个传入的 Pod 根据与现有的 Pod 的关联关系在集群中部署。字段包括:
maxSkew 描述 pod 分布不均的程度。这是给定拓扑类型中任意两个拓扑域中匹配的 pod 之间的大允许差值。它必须大于零。
topologyKey 是节点标签的键。如果两个节点使用此键标记并且具有相同的标签值,则调度器会将这两个节点视为处于同一拓扑中。调度器试图在每个拓扑域中放置数量均衡的 pod。
whenUnsatisfiable 指示如果 pod 不满足扩展约束时如何处理:
DoNotSchedule(默认)告诉调度器不用进行调度。
ScheduleAnyway 告诉调度器在对小化倾斜的节点进行优先级排序时仍对其进行调度。
labelSelector 用于查找匹配的 pod。匹配此标签的 pod 将被统计,以确定相应拓扑域中 pod 的数量。
假设我们将Pod声明如下
kind: PodapiVersion: v1metadata:name: mypodlabels:foo: barspec:topologySpreadConstraints:maxSkew: 1topologyKey: zonewhenUnsatisfiable: DoNotSchedulelabelSelector:matchLabels:foo: barmaxSkew: 1topologyKey: nodewhenUnsatisfiable: DoNotSchedulelabelSelector:matchLabels:foo: barcontainers:name: pauseimage: k8s.gcr.io/pause:3.1
假设在集群中 3 个标记为 foo:bar 的 pod 分别位于 node1,node2 和 node3 上(P 表示 pod):

在这种情况下,为了匹配个约束,传入的 pod 只能放置在 "zoneB" 中;而在第二个约束中,传入的 pod 只能放置在 "node4" 上。然后两个约束的结果加在一起,因此可行的选择是放置在 "node4" 上。
第二,Service Topology
Service 拓扑可以让一个服务基于集群的 Node 拓扑进行流量路由。例如,一个服务可以指定流量是被优先路由到一个和客户端在同一个 Node 或者在同一可用区域的端点。
如果集群启用了 Service 拓扑功能后,就可以在 Service 配置中指定 topologyKeys 字段,从而控制 Service 的流量路由。此字段是 Node 标签的优先顺序字段,将用于在访问这个 Service 时对端点进行排序。流量会被定向到个标签值和源 Node 标签值相匹配的 Node。如果这个 Service 没有匹配的后端 Node,那么第二个标签会被使用做匹配,以此类推,直到没有标签。
如果没有匹配到,流量会被拒绝,就如同这个 Service 根本没有后端。
apiVersion: v1kind: Servicemetadata:name: my-servicespec:selector:app: my-appports:protocol: TCPport: 80targetPort: 9376topologyKeys:"kubernetes.io/hostname""topology.kubernetes.io/zone""topology.kubernetes.io/region""*"
可以设置 Service 的 topologyKeys 的值,像下面的做法一样定向流量了。
只定向到同一个 Node 上的端点,Node 上没有端点存在时就失败:配置 ["kubernetes.io/hostname"]。
偏向定向到同一个 Node 上的端点,回退同一区域的端点上,然后是同一地区,其它情况下就失败:配置 ["kubernetes.io/hostname", "topology.kubernetes.io/zone", "topology.kubernetes.io/region"]。这或许很有用,例如,数据局部性很重要的情况下。
偏向于同一区域,但如果此区域中没有可用的终结点,则回退到任何可用的终结点:配置 ["topology.kubernetes.io/zone", "*"]。
第三,nodeSelector & node Affinity and anti-affinity
nodeSelector:为Node规划标签,然后在创建部署的时候,通过使用nodeSelector标签来指定Pod运行在哪些节点上。
Node affinity:指定一些Pod在Node间调度的约束。支持两种形式:requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution,可以认为前一种是必须满足,如果不满足则不进行调度,后一种是倾向满足,不满足的情况下会调度的不符合条件的Node上。IgnoreDuringExecution表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
第四,Inter-pod affinity and anti-affinity
允许用户通过已经运行的Pod上的标签来决定调度策略,如果Node X上运行了一个或多个满足Y条件的Pod,那么这个Pod在Node应该运行在Pod X。
有两种类型
requiredDuringSchedulingIgnoredDuringExecution,刚性要求,必须匹配
preferredDuringSchedulingIgnoredDuringExecution,软性要求
第五,Taints and Tolerations
Taints 描述节点拒绝一个或一组Pods的策略。其实现原理为首先通过kubectl taint命令为Node定义一些瑕疵,然后在Pod的描述文件中指定它的容忍度,即不能够容忍哪些瑕疵,这样在调度的时候Pod将不会被调度到哪些有瑕疵的Node上。
Taints和tolerations是避免Pods部署到Node,以及从Node中驱离Pod的灵活方法,有一些应用场景:
专用节点 Dedicated Nodes
特殊硬件的节点
节点出问题时进行Pod的驱逐
第九节,Kubernetes Operator原理与PaaS中间件实践
K8S部署无状态应用是非常顺畅的,如果部署有状态应用,就需要通过开发Operator,在操作有状态服务多个节点之间的关系,以及在有节点出现故障的时候,进行修复。
这里我们解析一个例子,就是以etcd Operator为例,通过三步来模拟人工操作:
1. 通过k8s api 观察当前集群状态
2. 判断出当前状态与期望的状态不符
3. 通过调用etcd的api以及k8s api使其达到预期状态
https://github.com/coreos/etcd-operator
在etcd-operator中,首先创建并启动Controller
c := controller.New(cfg)err := c.Start()
启动Controller
func (c *Controller) Start() error {err := c.initResource()......c.run()......}
先是调用K8S的API创建CRD
func (c *Controller) initResource() error {if c.Config.CreateCRD {err := c.initCRD()}return nil}func (c *Controller) initCRD() error {err := k8sutil.CreateCRD(c.KubeExtCli, api.EtcdClusterCRDName, api.EtcdClusterResourceKind, api.EtcdClusterResourcePlural, "etcd")return k8sutil.WaitCRDReady(c.KubeExtCli, api.EtcdClusterCRDName)}
接下来是,运行controller,通过ListAndWatch CRD,在收到Add、Update、Delete事件时,相应进行处理
func (c *Controller) run() {......source := cache.NewListWatchFromClient(c.Config.EtcdCRCli.EtcdV1beta2().RESTClient(),api.EtcdClusterResourcePlural,ns,fields.Everything())......_, informer := cache.NewIndexerInformer(source, &api.EtcdCluster{}, , cache.ResourceEventHandlerFuncs{AddFunc: c.onAddEtcdClus,UpdateFunc: c.onUpdateEtcdClus,DeleteFunc: c.onDeleteEtcdClus,}, cache.Indexers{})......informer.Run(ctx.Done())}
Add及Update调用的是syncEtcdClus函数
而delete终调用的是handleClusterEvent函数
syncEtcdClus函数终调用的是handleClusterEvent函数
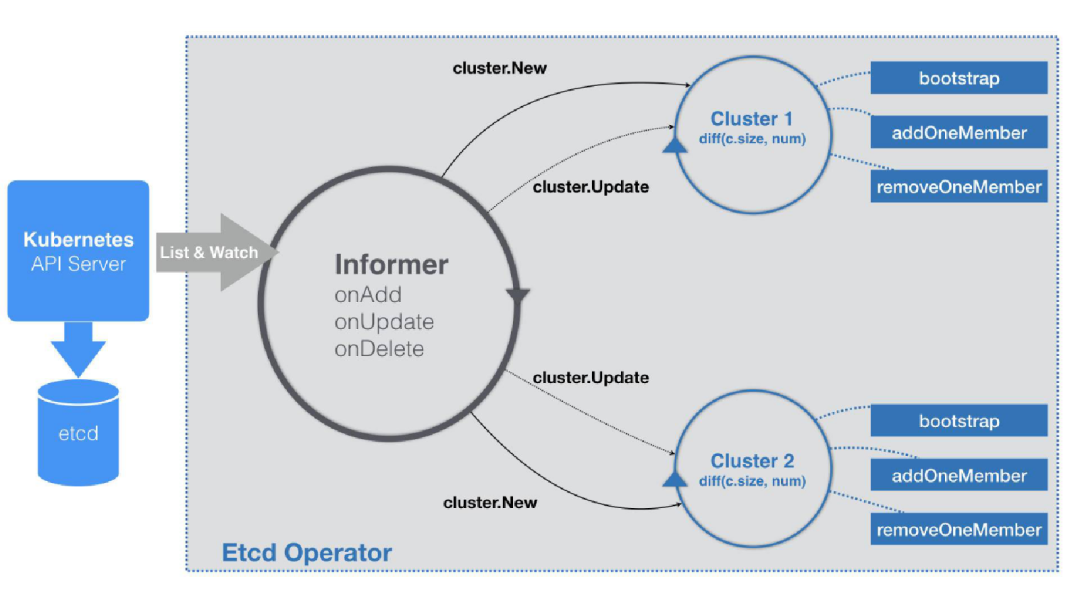
我们来接着看handleClusterEvent
// handleClusterEvent returns true if cluster is ignored (not managed) by this instance.func (c *Controller) handleClusterEvent(event *Event) (bool, error) {clus := event.Object......switch event.Type {case kwatch.Added:......nc := cluster.New(c.makeClusterConfig(), clus)c.clusters[getNamespacedName(clus)] = nc......case kwatch.Modified:......c.clusters[getNamespacedName(clus)].Update(clus)......case kwatch.Deleted:c.clusters[getNamespacedName(clus)].Delete()delete(c.clusters, getNamespacedName(clus))......}}
我们重点看Add,也即调用cluster.New来建一个cluster。
func New(config Config, cl *api.EtcdCluster) *Cluster {c := &Cluster{logger: lg,config: config,cluster: cl,eventCh: make(chan *clusterEvent, 100),stopCh: make(chan struct{}),status: *(cl.Status.DeepCopy()),eventsCli: config.KubeCli.Core().Events(cl.Namespace),}go func() {if err := c.setup(); err != nil {......}c.run()}()return c}
在新建Cluster的时候,先是Setup,然后Run
在Setup中,调用Create。
func (c *Cluster) setup() error {......if shouldCreateCluster {return c.create()}......}func (c *Cluster) create() error {c.status.SetPhase(api.ClusterPhaseCreating)if err := c.updateCRStatus(); err != nil {......}return c.prepareSeedMember()}func (c *Cluster) updateCRStatus() error {if reflect.DeepEqual(c.cluster.Status, c.status) {return nil}newCluster := c.clusternewCluster.Status = c.statusnewCluster, err := c.config.EtcdCRCli.EtcdV1beta2().EtcdClusters(c.cluster.Namespace).Update(c.cluster)if err != nil {return fmt.Errorf("failed to update CR status: %v", err)}c.cluster = newClusterreturn nil}
在Create中,updateCRStatus更新状态,然后prepareSeedMember中创建Pod节点。
func (c *Cluster) prepareSeedMember() error {err := c.bootstrap()......}// bootstrap creates the seed etcd member for a new cluster.func (c *Cluster) bootstrap() error {return c.startSeedMember()}func (c *Cluster) startSeedMember() error {m := &etcdutil.Member{Name: k8sutil.UniqueMemberName(c.cluster.Name),Namespace: c.cluster.Namespace,SecurePeer: c.isSecurePeer(),SecureClient: c.isSecureClient(),}ms := etcdutil.NewMemberSet(m)if err := c.createPod(ms, m, "new"); err != nil {return fmt.Errorf("failed to create seed member (%s): %v", m.Name, err)}c.members = ms_, err := c.eventsCli.Create(k8sutil.NewMemberAddEvent(m.Name, c.cluster))return nil}
我们看完Setup,再来看Run
func (c *Cluster) run() {c.status.ServiceName = k8sutil.ClientServiceName(c.cluster.Name)c.status.ClientPort = k8sutil.EtcdClientPortc.status.SetPhase(api.ClusterPhaseRunning)for {select {......case <-time.After(reconcileInterval):start := time.Now()......running, pending, err := c.pollPods()......// On controller restore, we could have "members == nil"if rerr != nil || c.members == nil {rerr = c.updateMembers(podsToMemberSet(running, c.isSecureClient()))}rerr = c.reconcile(running)......c.updateMemberStatus(running)......}......}}
这里面主要是定时处理,在这里面:
获取running和pending的pod
Pending状态不处理,等其成功或失败
Running目前还没处理
-
reconcile检查当前cluster是否符合预期,不符合就更新,如数量少,创建pod ,加入集群(etcd client)
// reconcile reconciles cluster current state to desired state specified by spec.// - it tries to reconcile the cluster to desired size.// - if the cluster needs for upgrade, it tries to upgrade old member one by one.func (c *Cluster) reconcile(pods []*v1.Pod) error {......sp := c.cluster.Specrunning := podsToMemberSet(pods, c.isSecureClient())if !running.IsEqual(c.members) || c.members.Size() != sp.Size {return c.reconcileMembers(running)}c.status.ClearCondition(api.ClusterConditionScaling)if needUpgrade(pods, sp) {c.status.UpgradeVersionTo(sp.Version)m := pickOneOldMember(pods, sp.Version)return c.upgradeOneMember(m.Name)}c.status.ClearCondition(api.ClusterConditionUpgrading)c.status.SetVersion(sp.Version)c.status.SetReadyCondition()return nil}// reconcileMembers reconciles// - running pods on k8s and cluster membership// - cluster membership and expected size of etcd cluster// Steps:// 1. Remove all pods from running set that does not belong to member set.// 2. L consist of remaining pods of runnings// 3. If L = members, the current state matches the membership state. END.// 4. If len(L) < len(members)/2 + 1, return quorum lost error.// 5. Add one missing member. END.func (c *Cluster) reconcileMembers(running etcdutil.MemberSet) error {unknownMembers := running.Diff(c.members)if unknownMembers.Size() > {c.logger.Infof("removing unexpected pods: %v", unknownMembers)for _, m := range unknownMembers {if err := c.removePod(m.Name); err != nil {return err}}}L := running.Diff(unknownMembers)if L.Size() == c.members.Size() {return c.resize()}if L.Size() < c.members.Size()/2+1 {return ErrLostQuorum}c.logger.Infof("removing one dead member")// remove dead members that doesn't have any running pods before doing resizing.return c.removeDeadMember(c.members.Diff(L).PickOne())}
第十节,Kubernetes应用容器化佳实践
每个容器应该只包含一个应用程序,如果有其他辅助应用程序,请使用pod。
Docker中的应用程序应该支持健康检查和优雅关机,配合readiness和liveness probe使用。
Dockerfile和Docker图像应该用层来组织,以简化开发人员的Dockerfile。
将共享层和命令放在Dockerfile的前面,这样就可以更快地构建docker映像,因为共享。
删除Docker映像中的不需要的工具,这使映像更加安全,如果您想调试,可以使用ephemeral containers
如果你想初始化一些东西,使用 init containers。
构建尽可能小的图像。
在图片上加上规定的标签,不要使用新的
在使用公共镜像之前,先扫描它,常用的镜像扫描工具有Clair,Anchore,OpenSCAP。
不要使用privilidged来创建Docker,可以使用securityContext
