0.前言
OpenTSDB 是StumbleUpon在2010年开源的基于HBase的分布式的、可扩展的时间序列数据库 (time series database, 简称TSDB) 。源码仓库地址为:https://github.com/OpenTSDB/opentsdb。本文结合OpenTSDB v2.4.0的源码和相关资料对OpenTSDB的存储机制进行浅析, 如有不对的地方,欢迎批评指正。
1.整体架构
OpenTSDB的整体架构如下所示,由运行在HBase之上的一个或者多个时间序列守护程序TSD (Time Series Daemon) 组成,每个TSDB都是无状态的独立节点,因此可以根据系统负载情况进行任意节点的横向扩展。
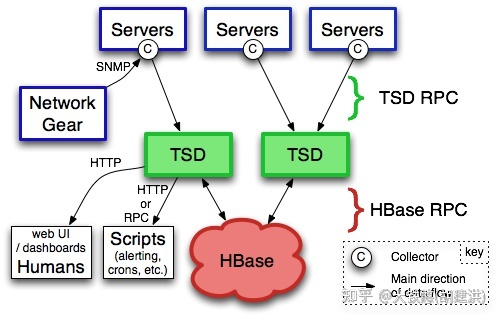
OpenTSDB支持telnet协议、HTTP协议进行数据的写入,所有通信都发生在同一个端口上,TSD 通过查看它接收的前几个字节来确定客户端的协议。另外,OpenTSDB 提供了一个内置的、简单的WebUI用户界面,用于将选择的一个或多个指标和标签的数据进行可视化展示。另外,也可以使用 HTTP API 将 OpenTSDB 绑定到外部系统,例如监控框架、仪表板(Grafana)等。
2.数据模型
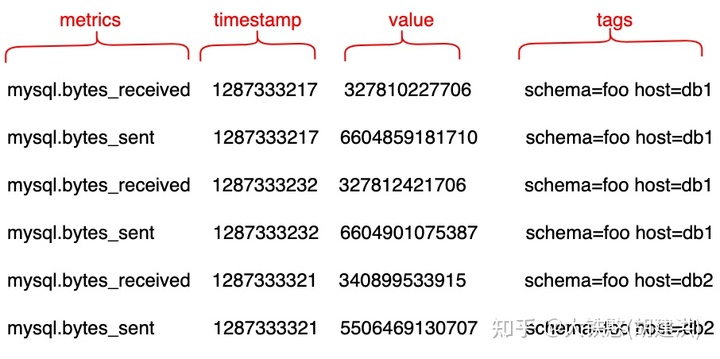
OpenTSDB的数据模型是基于tag的单值模型,即写入的每行记录(数据点)中只有一个指标值,如下所示。

其中,metric为指标名称;timestamp为UNIX时间戳,单位为秒或者毫秒;value为指标值,支持整数、浮点数以及JSON格式表示的事件或者直方图;tags为标签,主要用于区分不同的数据来源,一般作为维度值,支持在不同维度上做聚合运算(如sum、count、avg等算子)。
下图是OpenTSDB的写入数据示例,其中指标和标签的组合确定一个时间序列(时间线),因此这个示例中共计有4个时间序列6个数据点。
其中,对于机器类的监控指标,为了方便将这些指标写入OpenTSDB,StumbleUpon编写了一个名为的 Python 框架 tcollector ,支持从 Linux 2.6、Apache 的 HTTPd、MySQL、HBase、memcached、Varnish 等处收集数千个指标写入到OpenTSDB中。同时,支持写入 OpenTSDB的指标采集器,还包括 Collectd、Statsd 和 Coda Hale等。
3.存储机制
OpenTSDB是构建在HBase之上的时序数据库,HBase是一个KV宽表存储系统,因此OpenTSDB的存储机制是围绕HBase的KV宽表模型展开的。通过OpenTSDB源码目录下脚本src/create_table.sh,可以得知OpenTSDB需要在HBase上创建以下4张表。
- UID_TABLE:字典表,存储name和id的相互映射关系;即将metric和tags做字典化,降低重复字符串的存储空间;
- TSDB_TABLE:数据表,存储原始写入的数据点;
- TREE_TABLE:树形表,用于将时间序列组织成类似文件系统的树形结构;
- META_TABLE:元数据表,用于记录时间线总数等记录;

需要注意的是,虽然OpenTSDB在脚本中会创建4张表,但如果没有开启元数据功能和预汇总(RollUp)功能,那么实际上只需要UID_TABLE和TSDB_TABLE两张表就可以工作了。预汇总和预聚合功能是OpenTSDB 2.40中新加的特性,在存储这部分数据时,需要根据业务聚合需求,额外创建数据表来进行存储,以便和原始数据点分开。
HBase的逻辑数据模型如下图所示,包含行健rowKey, 列簇columnFamily,列限定符columnQualifier,值cell等,因此OpenTSDB的存储实现机制就是将写入的时序数据点映射到HBase的逻辑数据模型上。其中,需要注意的是,HBase的物理存储是KeyValue,其中Key由行健rowKey, 列簇columnFamily,列限定符columnQualifier、版本Timestamp等组成,Value由Cell组成;因此OpenTSDB为了降低存储开销,将列簇columnFamily的长度尽可能设计为一个字节,比如数据表的列簇设计为“t”。
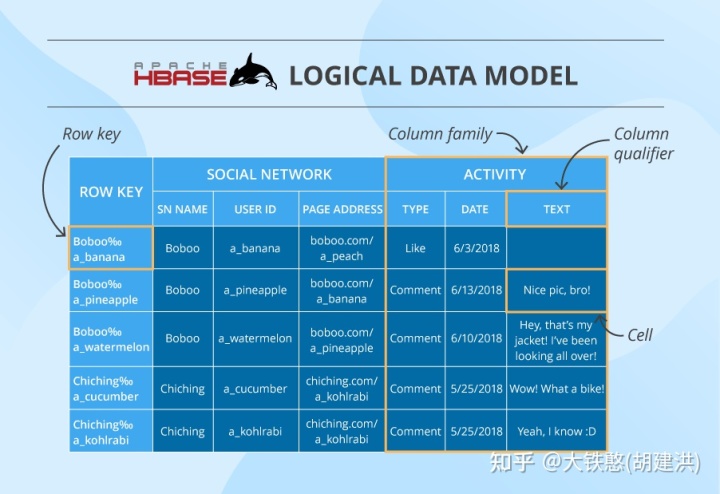
3.1 字典表设计
字典表uid,整体上分成name和id两个列簇,每个列簇下都有metrics、tagk、tagv等三个固定列限定符。name列簇存储id到name的映射关系,id列簇存储name到id的映射关系,如下图所示。比如名为“dp0”的metric,映射出来的id为宽度为3个字节的“051”。在OpenTSDB的默认配置中,根据name映射出来的id的宽度为3个字节。

前面提到OpenTSDB的TSD节点是无状态的,那么OpenTSDB字典表中的id是如何生成的,并保证多个TSD节点并发创建同一个name对应id的一致性的?这个主要借助于HBase的atomicIncrement和compareAndSet两个方法实现的。在id列族中有一个单字节键为\x00的行,并有metrics、tagk、tagv等3个列,每个列维护一个8字节有符号整数,用于表示每个列的当前已经分配的大UID。因此,在进行UID分配时,主要分成如下两步:
第1步:OpenTSDB 在对应的列上调用 HBase的原子增量命令atomicIncrement以获取新的 UID;
第2步:使用compareAndSet方法,在name列簇上使用期望值为空数据的CAS设置rowKey=UID,value=name;如果已经存在rowKey=UID,value=name的数据,则CAS失败,表明已经有其他节点字典映射成功了,该节点只需回退调用get获取映射关系即可;
因此,从这里可以看出OpenTSDB分配的UID方式还是比较简单的,但若第2步失败,则第1步分配的UID就被浪费了,因此有可能存在分配出来的UID不是连续的;另外,由于UID的分配是依赖HBase的atomicIncrement和compareAndSet实现的,因此UID的分配速度在同时写入大量新的时间线时,是写入吞吐的一个瓶颈。
关于UID的生成和缓存的实现,在OpenTSDB源码的net.opentsdb.uid包下,主要实现为UniqueId类。其中,值得一提的是,OpentTSDB提供一个TSD节点单独随机生成UID的实现RandomUniqueId,以提高UID的分配效率,不过这个存在冲突的可能,不建议使用。
3.2 数据表设计
OpenTSDB的数据点默认情况都存储在TSDB_TABLE这张默认表中,包括秒级/毫秒数值数据点、注释以及直方图等数据点。数据表的整体设计,如下所示,只有一个名为"t"的列簇。数据表的写入接口主要是net.opentsdb.tsd.PutDataPointRpc类,读取接口主要是net.opentsdb.tsd.QueryRpc类。

3.2.1 行键RowKey
行键是由可选的salt、度量 UID、基本时间戳和 tagk/v 对的 UID 组成的字节数组, [salt][...]。默认情况下,UID 以 3 个字节编码。从 OpenTSDB 2.2 开始,为了更好的避免数据写入的热点问题,行键加上了一个可选的salt。

基本时间戳base_timestamp是一个以秒为单位的Unix时间戳,以 4 个字节编码。假设写入数据点的时间戳为timestamp,则base_timestamp = timestamp / 3600,其中timestamp需要转换为秒级时间戳。这样做的好处是,避免在一行中填充太多数据点,同时可以支持在查询时支持按照metric和时间范围扫描数据点,提高数据查询的效率。其中,在生成行键前,需要对tagk/v 对的UID进行字典排序,即按照tagk的字典序从小到大排序, 保证相同的metric和tags在相同的基本时间戳下生成的行键是的。
3.2.2 数据点列
OpenTSDB关于数据点列限定符qualifier的设计还是非常巧妙的,通过列限定符的字节数,很巧妙的在同一张表中同时存储数值类型的数据点、注释以及直方图等对象数据点。Qualifier保存了一个或多个DataPoint中的时间戳、数据类型、数据长度等信息。
3.2.2.1 数值数据点
数值数据点的qualifier的长度为2个字节或者4个字节,2字节为存储的是秒级时间戳数据点,4字节存储的是毫秒时间戳数据点,如下所示。
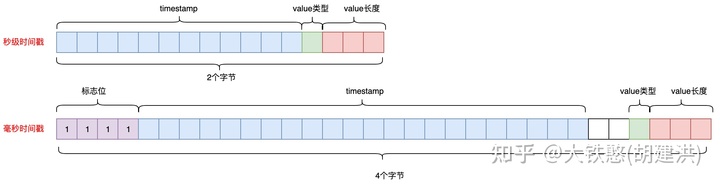
对于秒级时间戳的限定符qualifier,前 12 位代表一个整数,它是行键中时间戳的增量。例如,如果行键被归一化为1292148000,并且数据点时间戳为1292148123,则记录的增量将为123。对于毫秒时间戳的限定符qualifier,前4位将始终设置为1或F十六进制,接下来的 22 位将以毫秒为单位的偏移量编码为无符号整数,接下来的 2 位是保留的。
秒级时间戳和毫秒时间戳的qualifier后的4位都是格式位,用于描述存储的数据。位是一个标志,指示该值是整数还是浮点数。值 0 表示整数,1 表示浮点数。后 3 位表示数据的长度,偏移 1。值000表示 1 字节值,而010表示 2 字节值。value的长度必须为 1、2、4 或 8。
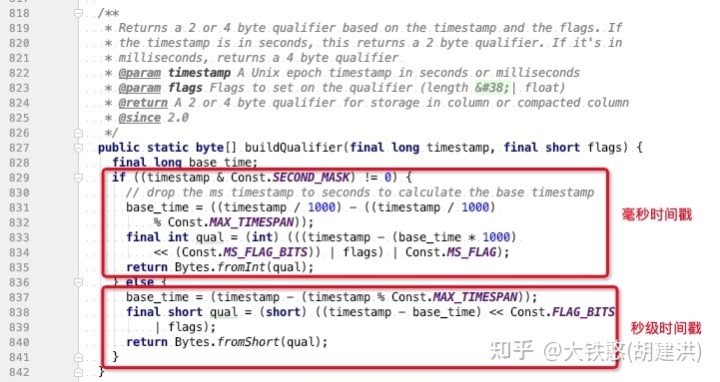
其中,关于qualifier的构造实现,在net.opentsdb.core.Internal类的buildQualifier方法中,如下图所示。
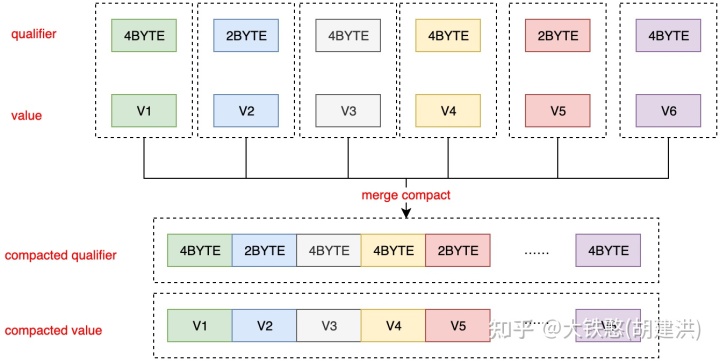
其中,对于数值数据点,OpenTSDB支持compaction(为一个配置项,默认是关闭的), 即将一行的多个列合并为一列,以减少存储空间和读取数据点时的IO开销。数据初写入单个列以提高速度,然后compaction以提高存储效率。compaction一行后,将删除单个数据点。数据可能会被写回该行并稍后再次compaction。
OpenTSDB的compaction后的限定符qualifier始终是偶数字节,并且只是该行中每个数据点的列限定符的串联(拼接);compaction后的列值value,是所有单个数据点的串联。在读取解析时,限定符首先被拆分,每个数据点的标志决定解析器是读取 4 字节还是 8 字节。 compaction列的结构如下图所示。
3.2.2.2 注释数据点
注释数据点的qualifier, 长度为3个字节或5个字节,3字节为秒级时间戳,5字节为毫秒时间戳。注释数据点annotation用于描述某个时间点发生的事件,是与数值数据点关联的时间序列的注释。注释的qualifier相对简单,只有标志位(固定为一个字节的0x1)和相对于base_timestamp的时间戳增量,如下图所示。
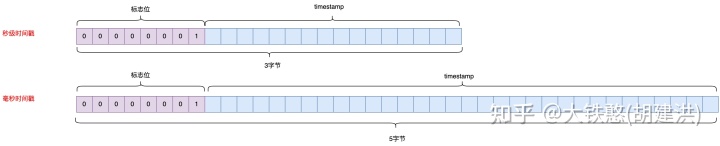
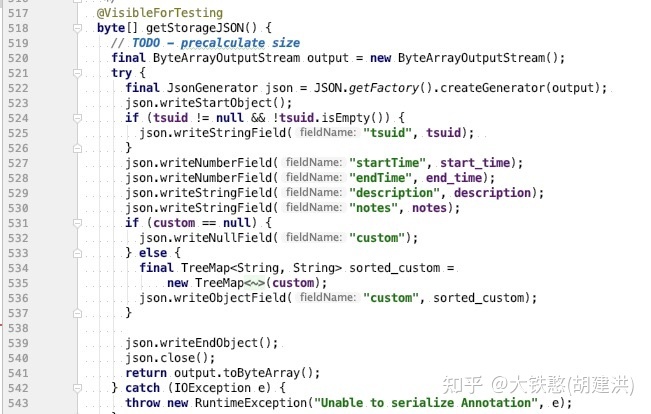
注释数据点中的value保存是JSON格式的字符串数据,其构造源码在net.opentsdb.meta.Annotation类的getStorageJSON方法中,如下所示。
需要注意的是,注释数据点读写是通过TSUID读写的, TSUID = [Metric UID + n * ( tagKey UID /tagValue UID) ], 即读写注释数据前,需要通过meta接口获取到时间序列的TSUID,然后才能进行读写操作;具体读写细节可以参考源码net.opentsdb.tsd.AnnotationRpc类。
3.2.2.3 直方图数据点
直方图数据点的qualifier长度为3个字节或5个字节,3字节为秒级时间戳,5字节为毫秒时间戳。只有标志位(固定为一个字节的0x6)和相对于base_timestamp的时间戳增量,如下图所示。
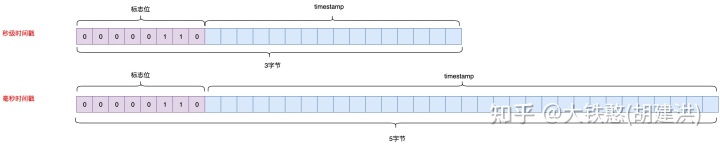
直方图数据点的value为直方图对象序列化为二进制数组,其中简单直方图序列化源码在net.opentsdb.core.SimpleHistogram类的histogram方法中,如下所示。 直方图数据点的写入接口为net.opentsdb.tsd.HistogramDataPointRpc类中。

3.2.2.4 附加数据点
OpenTSDB 2.2 引入了使用append方法将数值数据点写入OpenTSDB的想法,即调用HBase的append方法而不是put方法将数据点写入HBase中,这样在单个列中写入一行的所有数据可以节省 HBase的存储空间,从而实现 TSD 压缩的好处,同时避免将大量数据读回 TSD 并将它们重新写入 HBase 的问题。缺点是模式与常规(数值)数据点不兼容,并且耗费HBase Region Server更多 的CPU,因为它们对每个值执行读取、修改、写入操作。
附加数据点的在同一个行中只有一列,因此qualifier为固定值,由标志位和固定部分组成,长度为3个字节,值固定为0x050000。 对于value而言,附加数据点只是将数值点的qualifier和value拼接在一起形成新的value。即附加数据点是在写入时就进行了compaction的数据点。如下图所示。
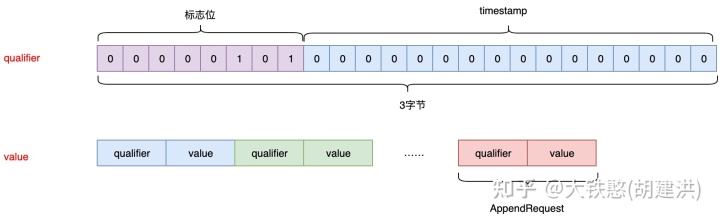
其中,value值可以按任何顺序出现并在查询时排序,当然也可选择将排序结果重新写回 HBase。
3.3 元数据表设计
元数据表meta_table, 是存储OpenTSDB 中的不同时间序列的索引,可以包含每个序列的元数据以及每个序列存储的数据点数。请注意,如果 OpenTSDB 已配置为跟踪元数据或用户通过 API 创建 TSMeta 对象,则数据只会写入此表。只使用了一种列族(name),有两种类型的列(元列和计数器列)。
- 行键,这与没有时间戳的数据点表行键相同。例如[...]。
- TSMeta列,这些列存储类似于 UIDMeta 对象的 UTF-8 编码、JSON 格式的对象,列限定符始终是ts_meta。
- 计数器列,这些列是原子增量器,用于计算为时间序列存储的数据点数。限定符是ts_counter,值是一个 8 字节的有符号整数。
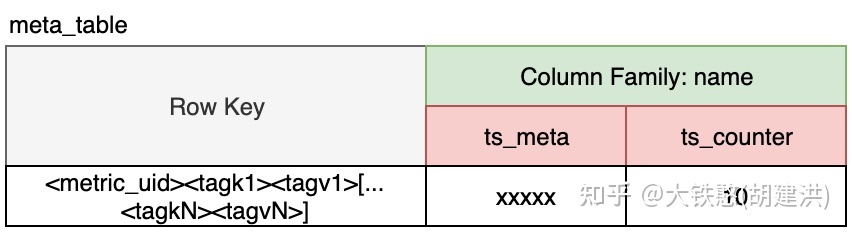
当通过net.opentsdb.tsd.SerachRpc或者net.opentsdb.tsd.UniqueIdRpc接口查询元数据时(比如时间序列TSUID等),将从meta_table中扫描数据。
3.4 树表设计
树表tree_table,将时间序列组织成类似于文件系统的分层结构,以便与 Graphite 或其他仪表板等工具一起使用。树由一组规则定义,这些规则处理 TSMeta 对象以确定在层次结构中的位置(如果有的话)应该出现时间序列。
树表涉及的概念较多,且使用频率较低,这里就先不进行分析了。
3.5 汇总和预聚合表
汇总表和预聚合表是OpenTSDB在2.4版本中设计的,虽然 OpenTSDB 在存储原始值方面做得很好,但当跨很长时间查询大量原始数据时,查询延迟会比较高并可能导致 JVM 出现 OOM。 因此,可以将单个时间序列按时间汇总(或降采样)并存储为单独的值,从而允许以较低的精度查询更长时间跨度的数据。对于具有高基数的指标,可以通过预聚合将多个时间序列的数据按照时间对齐聚合后存储下来,以显着提高查询速度。
3.5.1 预聚合表
对于具有高基数(许多标签值)的指标,如果直接扫描所有时间序列的数据,然后在内存中做聚合计算的话,会有很大的IO和计算开销,查询延迟回非常高。
以system.interface.bytes.out指标为例,假设在5个数据中心共计有10000 台主机。如果通过 'aggregate = sum' 和 'data_center = *'的查询条件,查看数据中心输出的总数据,那么预先计算每个数据中心的总和后,每个时间段只需提取 5 个数据点而不是 10000个数据点。生成的预聚合结果将具有与原始时间序列不同的标签集,假设这个示例中,每个时间序列都有一个host标签和一个data_center标签,那么预聚合后,host标签将被丢弃,只留下data_center标签。
从这里可以看出预聚合后的时间序列和原始时间序列只是标签数量不同,因此预聚合的结果可以直接存储在原始数据点表中,也可以单独存储另外一张表中,以提高查询性能。在 OpenTSDB 的实现中,当启用预聚合时,一个新的、用户可配置的标签被添加到所有时间序列,默认标签键为_aggegate,标签值为raw或聚合函数,该标签用于区分预聚合数据与原始(原始)值。
3.5.2 汇总表
汇总(Rollup),又称为降采样,是单个时间序列跨时间的降采样值,比如一个时间序列每分钟有一个数据点,60分钟有60个数据点,则可以使用sum算子按照1个小时粒度进行汇总,那么就将60个数据点汇总为一个数据点。
汇总数据因为列限定符qualifier与原始数据表不同,因此需要与原始数据分开存储,以避免有数据格式冲突,并允许执行更高性能的查询,汇总表需要用户额外自行创建。 汇总的行键rowKey和值value与原始数据表的格式相同。
汇总表的列限定符qualifier的设计如下所示, 由聚合函数、时间偏移量、类型和长度组成。

- 聚合函数, 是大写的字符串,如函数的名称SUM,COUNT,MAX或MIN;
- 时间偏移,这是基于汇总表配置的偏移,通常为 2 个字节。需要注意的是,汇总表的偏移量不是距行基准时间的特定秒数或分钟数,而是偏移量间隔的索引。例如,如果表配置为以每行 1 小时的分辨率存储 1 天的数据,则行键的基准时间戳将与每日边界对齐,那么该行可能有 24 个偏移量(24小时每小时 1 个偏移量)。
- 类型和长度 - 与原始数据表类似,每个偏移字节数组的后 4 位包含数据值的编码,包括其长度以及它是否为浮点值。
4.总结
OpenTSDB是基于通用存储引擎(HBase)而构建的分布式时序数据库,充分利用了HBase的宽表模型来存储时序数据,优点是借助HBase具备水平横向扩展能力。但OpenTSDB的缺点显而易见,一方面,运维挑战大,不但需要维护TSD节点,还需要同时维护hbase和底层的HDFS;另一方面,OpenTSDB没有针对时间线构建倒排索引等索引,多维检索困难,查询数据时需要硬扫Hbase表。
从对OpenTSDB的实际运维经验来看,OpenTSDB存在以下几个痛点问题:
- 因为OpenTSDB依赖HBase的CAS分配UID,当需要同时写入大量新增时间线时,UID的分配就成为写入吞吐的瓶颈;
- 而且,因为TSD节点在启动时,需要读取HBase的UID表的数据,在TSD节点上维护一个UID缓存,因此重启TSD节点只能滚动重启,否则可能会因为读UID的吞吐较高,把下面的HBase集群打挂;
- 当下面的HBase节点出现抖动或者挂掉后,OpenTSDB的写入吞吐会出现断崖式下降,一般需要重启TSD节点恢复,其中主要原因是OpenTSDB使用的Hbase客户端asynchbase, 存在一个无法感知底层Hbase的RegionServer的变化的Bug;
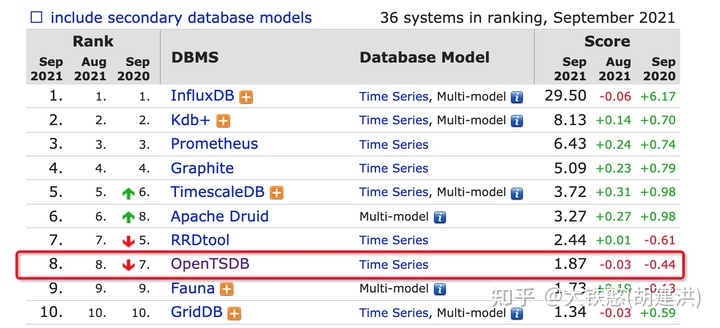
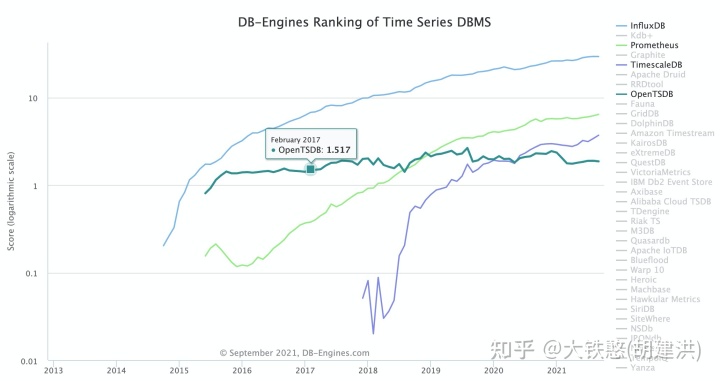
从github上OpenTSDB的源码提交来看,OpenTSDB活跃的事件段为2013年到2016年,2019年后提交就非常少了,说明OpenTSDB的活跃度在不断下降。
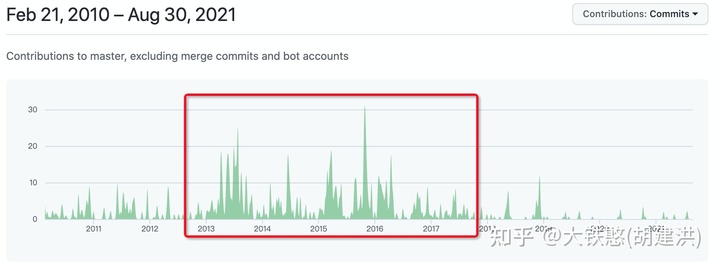
从DB-Engines上时序数据库的排名上看,OpenTSDB在榜单上的排名在不断下降,与此同时,OpenTSDB的得分情况,自2016年到2021年整体上没有变化,说明OpenTSDB的发展已经停滞了。