长期以来,Lucene在搜索领域的垄断地位无人能及,基于Lucene之上的Elastic Search与Solr 也是家喻户晓的产品;录信数据库初的版本也是基于Lucene来实现的,在设计之初经常会遇到跟solr、es同样的问题。如面对几十亿的数据就遇到内存爆掉的问题,此时CPU与IO都飙到系统极限;100亿的数据就需要100多台512G的大内存与SSD盘的硬件支撑,内存参数略微调不好就出现节点掉片,内存OOM的情况。
其次Lucene倒排索引的实现是基于FST的BLOCK TREE,这个数据结构官方给的描述是为了节省内存,实则只是相对而言,因每次打开索引就需要将tip文件全部加载到内存里,在万亿规模下,一个表会有很多个数据列,这种加载方式非常的慢,而且内存使用量也非常高;另外在检索的时候FST这种类型需要申请大量的数组,虽然是临时使用,但没有采用对象池,每次垃圾回收,会造成非常大的GC压力,GC停顿时间很长。而录信数据库需要在一百台128G内存的硬件上支撑上万亿的数据,内存使用规模上行不通。
Lucene进行分组统计时就需要依赖Lucene的docvalue;docvalue不是有序存储,需将ord文件加载到内存里,做ord映射;这种设计只要数据规模一大,效率就很差,就会出现爆内存的问题;而且因为是随机读,磁盘IO会飙的非常的高;ES经常遇到的频繁掉片和崩掉的问题都跟docvalue自身的设计有很大的关系。
Lucene的倒排表虽然也可以做单列统计,但归根结底是为了用于实现检索功能,其本身的设计并不是为了大范围扫描(Scan)与统计而设计的;
首先倒排表的TermStat因为要引用doc,pos,pay等一系列文件,没有任何的压缩,如果数据的值太多(Term太多),TermStat本身的IO会高于原始数据很多倍,在统计的时候会变得更慢,如果出现大范围的扫描将会出现致命的问题(如扫描一个大范围的手机号139*)。
后Lucene还有另外一个功能,可以用来实现数据统计加速,即payload。这个设计非常巧妙,但缺点是数据没有经过任何压缩,会导致一旦使用了payload,数据膨胀率很高,虽然在某些程度上能构造一些顺序读取,但是文件体积过大,一般不适合存储太大的数据。
面对海量数据的OLAP需求,为了减少存储费用、提高统计性能,数据库系统采用压缩和列存储的方法来保存数据。
传统的列存储是针对单列存储,多列之间并未建立关联,数据也没有按照顺序排列,数据库压缩比不高;
因数据存储不连续,存在大量的跳跃访问和随机访问,严重影响查询性能。统计的时候,也会因数据不连续、同组数据不相邻,需每条数据一条一条的计算,效率较差。
因此需对数据进行存储干预,并支持多列联合索引,数据经过多列排序干预后,查询可以变为连续读取,这样压缩比会非常高;在统计计算的时候可以一批一批的算;且由于数据之间存在关联,在多条件检索与关系分析上也可以节省很多IO。
鉴于上述原因,我们重新实现了Lucene的索引部分,以解决上面存在的问题。
加快统计与检索场景的速度。
实现多层次关系分析。
提升Top N排序速度。
加快数据导出的速度。
每列之间采用列存储,会根据数据特点自动选择合适的压缩算法。
预先干预数据的排序分布,让列存储的压缩更有效。
依据查询构造顺序读取。
多个列之间存在层次关系。
结合分块存储,可以随机访问。
使用极少的内存。
对象内存重用,减少GC压力。
可以压缩的payloads。
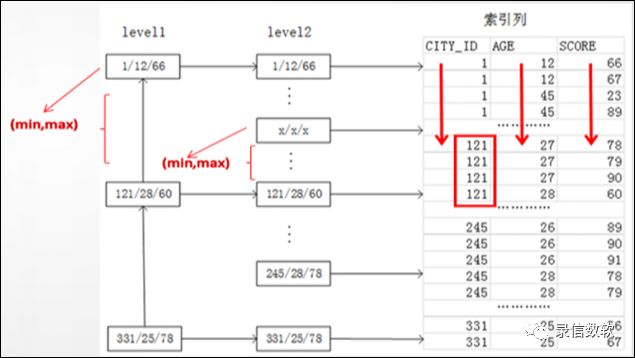
1. 基本概念
(1) olap_key:
1) 按照olap_key预先干预数据的分布
2) olap_key的每一列均是列存储
3) olap_key的每一列采用多种不同的压缩算法
4) 尽量将识别率高的列排在前面
① 如用来过滤筛选的手机号,虽然压缩比一般,可以有效利用索引先过滤;
② 或者那些重复值很高的列,如性别,省份,协议等 可以有非常高的压缩比。
(2) olap_value:
1) 跟随着olap_key后面存储,连续存储
2) 可以存储多个值,但并非按列存储,压缩方法采用lz4
3) 一般用来存储一些长文本数据
4) 不可以进行scan过滤
2. 建表方法
create table olap_test( s_high y_string_is, s_middle y_string_is, s_low y_string_is,
l_high y_long_is, l_middle y_long_is, l_low y_int_is,
d_high y_double_is, d_middle y_double_is, d_low y_double_is,
hlll_1 y_ldrill_imp 'olap_key@s_high,s_low,l_low,d_low' 'olap_value@l_high,d_high', hmll_2 y_ldrill_imp 'olap_key@l_high,l_middle,l_low,s_low' , mlll_1 y_ldrill_imp 'olap_key@s_middle,s_low,l_low,d_low' 'olap_value@l_high,d_high', mmll_2 y_ldrill_imp 'olap_key@d_middle,l_middle,l_low,s_low' ,
lllh_1 y_ldrill_imp 'olap_key@s_low,l_low,d_low,s_high' 'olap_value@s_low,d_high', llmh_2 y_ldrill_imp 'olap_key@l_low,s_low,l_middle,l_high' , lllm_1 y_ldrill_imp 'olap_key@s_low,l_low,d_low,s_middle' 'olap_value@s_low,d_high', llmm_2 y_ldrill_imp 'olap_key@l_low,s_low,d_middle,l_middle' ,
hl_1 y_ldrill_imp 'olap_key@s_high,s_low' 'olap_value@l_high,d_high', hm_2 y_ldrill_imp 'olap_key@l_high,l_middle' , ml_1 y_ldrill_imp 'olap_key@s_middle,s_low' 'olap_value@l_high,d_high', mm_2 y_ldrill_imp 'olap_key@d_middle,l_middle' ,
ll_1 y_ldrill_imp 'olap_key@s_low,l_low' 'olap_value@d_low', ll_2 y_ldrill_imp 'olap_key@l_low,s_low'
);
也可以结合列簇,将不同的列分开,存储到不同的存储介质中:
create columnfamily olap_test ( default at 'index@true' 'store@false' ,hlll_1 at 'fields@hlll_1' 'index@true' 'store@false' ,hmll_2 at 'fields@hmll_2' 'index@true' 'store@false' ,mlll_1 at 'fields@mlll_1' 'index@true' 'store@false' ,mmll_2 at 'fields@mmll_2' 'index@true' 'store@false' ,lllh_1 at 'fields@lllh_1' 'index@true' 'store@false' ,llmh_2 at 'fields@llmh_2' 'index@true' 'store@false' ,lllm_1 at 'fields@lllm_1' 'index@true' 'store@false' ,llmm_2 at 'fields@llmm_2' 'index@true' 'store@false' ,hl_1 at 'fields@llmm_2' 'index@true' 'store@false' ,hm_2 at 'fields@llmm_2' 'index@true' 'store@false' ,ml_1 at 'fields@llmm_2' 'index@true' 'store@false' ,mm_2 at 'fields@llmm_2' 'index@true' 'store@false' ,ll_1 at 'fields@llmm_2' 'index@true' 'store@false' ,ll_2 at 'fields@llmm_2' 'index@true' 'store@false' );
3. 查询使用方法
(1) 测试数据如下:
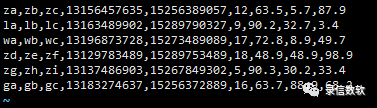
(2) 导入语句如下:
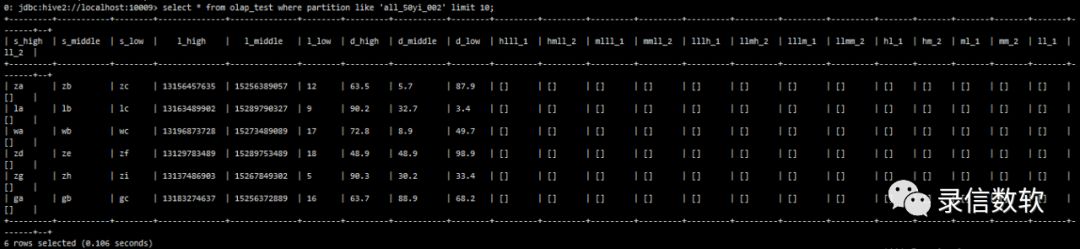
sh load.sh -t olap_test -p all_50yi_002 -tp txt -local -f /wyh/ldrill.log -sp , -fl s_high,s_middle,s_low,l_high,l_middle,l_low,d_high,d_middle,d_low(3) 查看表数据:
(4) 仅扫描olap_key(按列存储,不需要的列不扫描)
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' limit 20;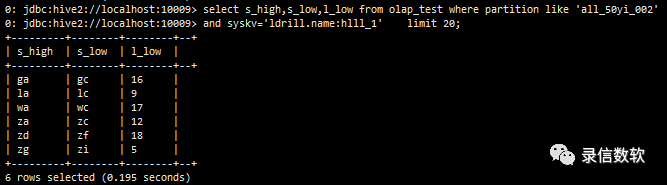
(5) 同时扫描olap_key与olap_value
注:olap_value不同的是整体压缩,查一个列与查询所有的列,IO是一样的,且Olap_value里面的列不能参与过滤,他也会加载doclist文件,速度略慢,但因为是顺序读,且有lz4压缩,性能一般也比docvalues快。
select s_high,s_low,l_high from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' limit 20;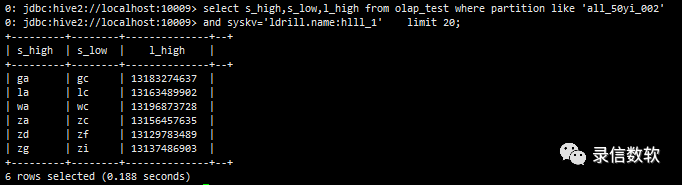
(6) 带检索条件 from to,如果from==to相当于等值查询,尽量将需要过滤的列放在位,适合http协议那种根据key直接导出一批大的结果
--等值查询select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' and syskv='ldrill.form:SYS_URL_ENCODE@['za']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['za']@SYS_URL_ENCODE' limit 20; 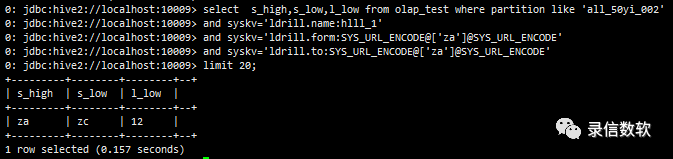
--范围查询select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' and syskv='ldrill.form:SYS_URL_ENCODE@['za']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['zd']@SYS_URL_ENCODE' limit 20;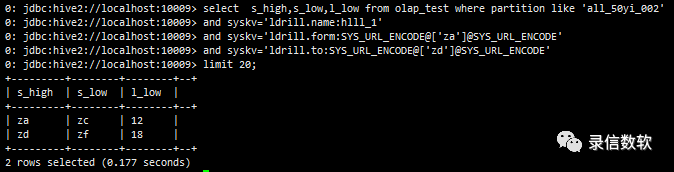
(7) 通配符*的使用
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' and syskv='ldrill.form:SYS_URL_ENCODE@['*','zc']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['*','zc']@SYS_URL_ENCODE' limit 20;
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' and syskv='ldrill.form:SYS_URL_ENCODE@['*','*','9']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_UR L_ENCODE@['*','*','16']@SYS_URL_ENCODE' limit 20; 
(8) 也可以与其他检索条件组合使用,但是要借助doclist进行bitset比对,会有doclist的额外开销,性能相对于纯粹的from to会差一些。
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' and syskv='ldrill.form:SYS_URL_ENCODE@['*','*','9']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['*','*','16']@SYS_URL_ENCODE' and s_low='zc' limit 20; 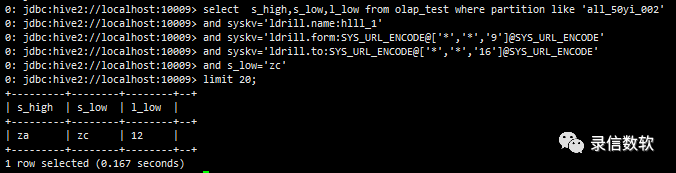
(9) 统计
select l_low,count(*) from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:ll_1' group by l_low limit 20; 
(10) ldrill的统计是可以多列的,这是它的特点
select s_low,l_low,count(*) from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:ll_1' group by s_low,l_low limit 20;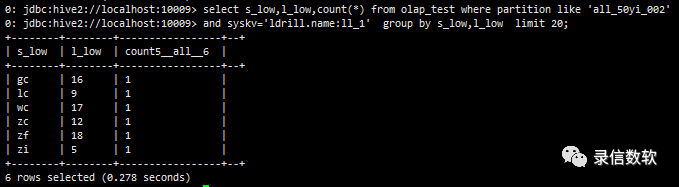
(11) 对于某一个筛选值下面的统计,如筛选某一手机号,统计某一局部数据,这样筛选范围数据量就少了,而且这些数据还是连续存储
select d_middle,l_middle,count(*) from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:mm_2' and syskv='ldrill.form:SYS_URL_ENCODE@['30.']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['50.']@SYS_URL_ENCODE' group by d_middle,l_middle limit 20;
select l_middle,count(*),avg(d_middle),max(d_middle),min(d_middle),sum(d_middle) from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:mm_2' and syskv='ldrill.form:SYS_URL_ENCODE@['*','15256372889']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['*','15289790327']@SYS_URL_ENCODE' group by l_middle limit 20;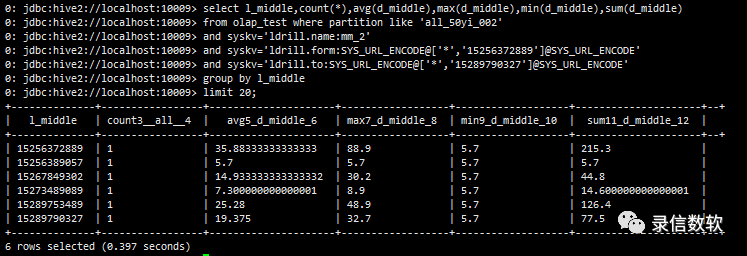
select d_middle,count(*),avg(l_middle),max(l_middle),min(l_middle),sum(l_middle) from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:mm_2' and syskv='ldrill.form:SYS_URL_ENCODE@['30.']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['50.']@SYS_URL_ENCODE' group by d_middle limit 20;
(12) 数据导出,仅导出olap_key
export json overwrite /data/export/test2 select s_middle,s_low,l_low,d_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:mlll_1' and syskv='ldrill.form:SYS_URL_ENCODE@['zb']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['ze']@SYS_URL_ENCODE'; 

注:该处测试所用的LSQL为单机版,故导出后文件存放在本地指定路径(如为集群版,则存放在HDFS上)。导出的文件数量与executor数有关。
(13) 数据导出,很多时候,往往需要将olap_value中的大块的值也导出去,这个时候只能读doclist,但是好在是顺序读取
export json overwrite /wyh/export/test2 select s_middle,s_low,l_low,d_low,l_high,d_high from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:mlll_1' and syskv='ldrill.form:SYS_URL_ENCODE@['zb']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['ze']@SYS_URL_ENCODE'; 
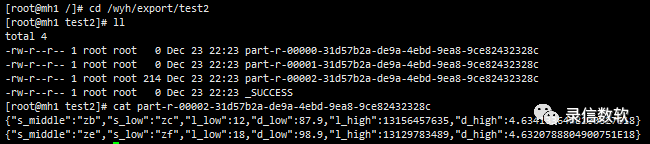
(14) group by只能做一种请求,如果一次请求要返回多种汇总数据,可以借助facet
--不返回数据明细 select * from olap_test where partition like 'all_50yi_002' and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_1','fl':'s_low,l_low','from':['*'],'to':['*']}@SYS_URL_ENCODE' and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_2','fl':'l_low,s_low','from':['*'],'to':['*']}@SYS_URL_ENCODE' limit ;
结合过滤筛选的facet:
select * from olap_test where partition like 'all_50yi_002' and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_1','fl':'s_low,l_low','from':['zc','5'],'to':['zi','12']}@SYS_URL_ENCODE' and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_1','fl':'s_low,l_low','from':['zc','12'],'to':['zf','18']}@SYS_URL_ENCODE' and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_2','fl':'l_low','from':['9'],'to':['17']}@SYS_URL_ENCODE' limit ;

原文链接:https://mp.weixin.qq.com/s/nIJHKCksOOZYsu467pvoiw
