【技术分享】Apache Trafodion事务和分析一体化引擎的挑战
 2022-04-13 14:26:02
2022-04-13 14:26:02
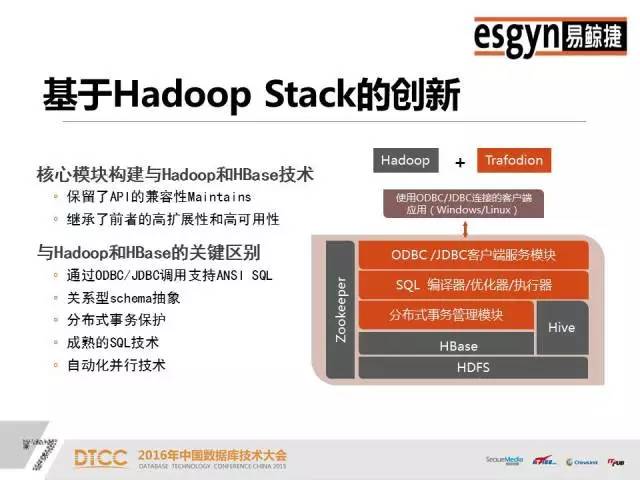
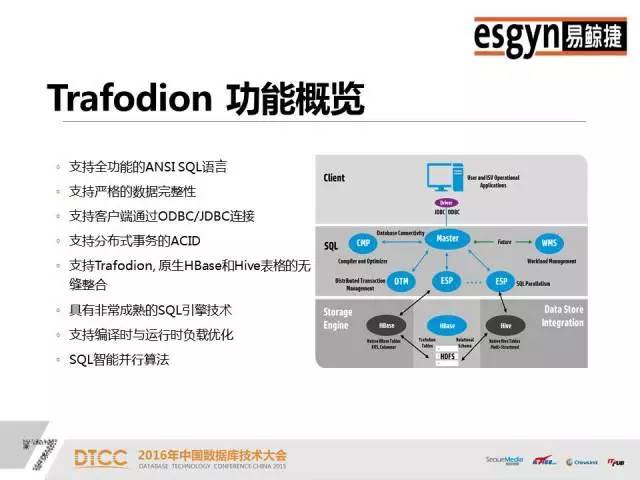
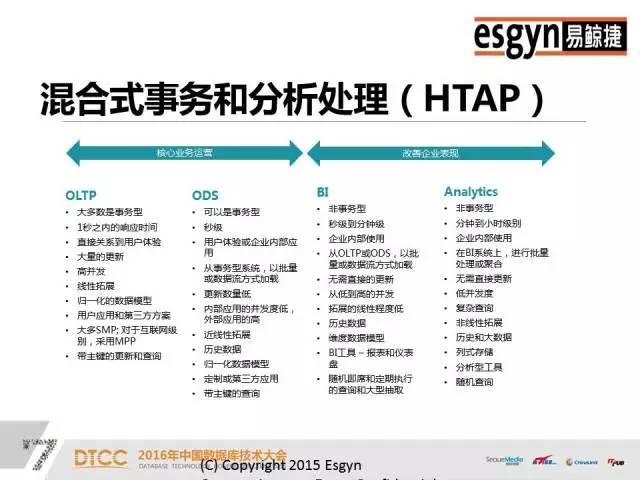
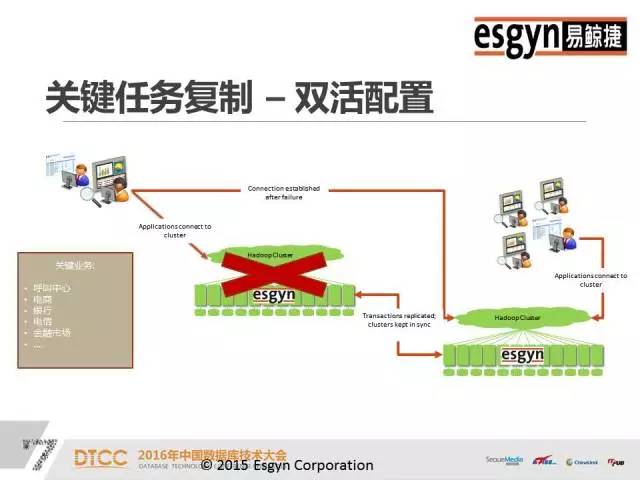
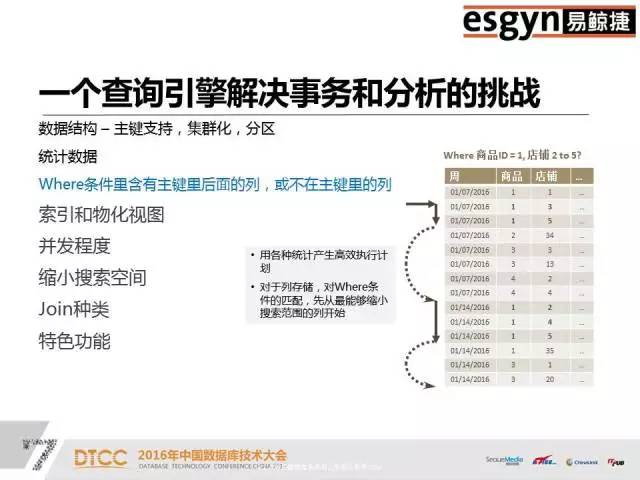
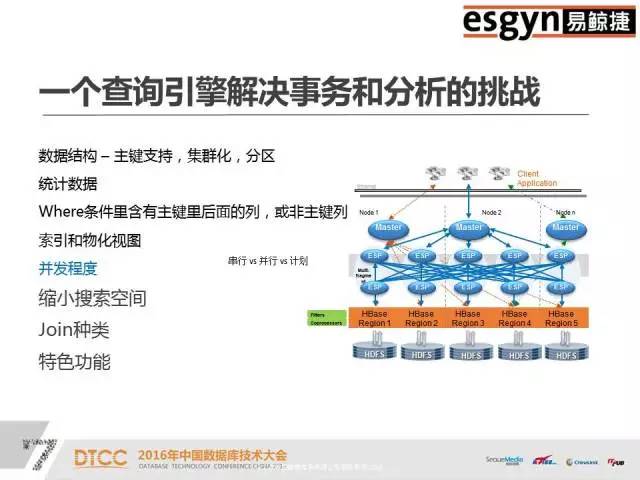
本文整理自DTCC2016主题演讲内容,录音整理及文字编辑IT168@田晓旭@老鱼。如需转载,请先联系本公众号获取授权!领导EsgynDB和Apache Trafodion的行业应用方案的架构、开发和部署,有丰富的分布式海量并发和SQL-On-Hadoop的部署和调优经验,包括互联网、在线娱乐、银行、电信、车联网等。非常荣幸可以在这么大的一个舞台演讲,之前百度的前辈讲了很多业界对于数据处理的一些基本常识,这对我们是非常有帮助的。我们现在所做的事情和DTCC大会以及其他一些大数据会议的整体方向是一致的,收集数据、分享数据和分析数据。我今天给大家讲的是一个开源项目——Apache Trafodion。早的关系型数据库例如Oracle,它们典型的特点是SQL非常厉害,存储引擎一般固定在特定的硬件上。后来出现了Hadoop,使用通用的硬件去扩展分布式。传统关系型数据库的特点是又小又快,Hadoop的特点是又大又慢,这其中的小和慢都是相对来说的,小是指传统数据库不能有Hadoop那么大的数据量,而MapReduce批处理方案的速度也无法和传统数据库的处理速度相比。我们开发产品的着眼点就是设计一款产品让它可以做到又大又快。这个产品是基于惠普研发了二十年的分布式存储引擎开发的。假设S1等于A减B,S2等于B减C,现在求S1加S2。如果存储引擎不够聪明,那就只能先算S1、S2,然后再去求解S。数据库做报表的时候一般要做join。但是join对于大多数的引擎都是难点。但是我们这个引擎一条query语句可以支持多达64个join,如果做不好会出现多重循环;另外我们能够支持多达64个嵌套查询。一般来说,Impala做三个表的join就已经很吃力了,会出现占内存、不稳定等等问题。但是我们很擅长这样的操作,我们将前面的predict逻辑往下推,基层的问题基层解决,绝不麻烦中央。首先利用HBase、HIVE做存储引擎,默认情况是HBase。之后,数据的操作和Oracle基本一致,我们95%的语言和Oracle是相似的,只是我们不支持PLSQL(我们支持Java版的SPJ)。 支持ODBC、JDBC,支持关系型Schema,支持二级索引、多级索引、复合索引,支持SQL技术,支持自动化并行技术。传统关系型数据库的数据是存在本地磁盘上,没有网络RPC协议的问题,但是分布式数据库必须明确哪些数据存储在哪个盘上,否则Cost-Based的代价算法会非常难做。只有数据均匀分散在所有的节点和磁盘上,并行技术才能被充分利用。就像十个能力相当的人做技术,那么大家应该是几乎同时完成,但是如果其中有一个人是小孩子,那么其他9个人完成之后,还需等待小孩子完成。我们的并行技术是自动化的,可以根据当前CPU的特点,比如核心的数量、内存的大小、磁盘的个数等等来自动决定。如果是一个短query,它可能一个线程就搞定,如果是长query话,也会自动分成多个线程。上图是一个具体的结构,从上面客户端的角度看几乎完全是Oracle,只要有IP端口号、用户名、密码,默认的schema和表就可以直接访问了,我们兼容全部的JDBC、ODBC标准。从下面看,利用了HBase和HIVE做存储引擎,对于用户和运维人员来讲都是非常熟悉的。我们和HBase的关系是有一个RegionServer就有一个节点,我们没有中心节点、没有热点,也没有管理节点,大家连过来的时候是JDBC Connect,相当于门口保安发号。JDBC有一个二次握手,次是保安给你号,第二次是拿着你的号到相应的窗口,这个窗口按照某种算法排序一定是当前优的。我们的SQL引擎技术在兼容性、通用性和易用性方面都非常好。Compiler是基于成本的优化器,它会根据历史查询和时空分布特点去制订执行计划。一旦你有索引或者key介入,那么执行计划就会产生变化,Compiler会自动重新为你设置执行计划。假设现在有四列,建立A、B、C、D四个索引,如果你用A做引导列的时候才能用到,但是常规数据库如果你用D甚至C加D都用不到。如果采用我们的引擎,你仅仅只有C跟D做条件的时候仍然可以利用这个Index。大数据有很多脏数据,一列数据里可能有30%是null,这样的数据去建索引会有很大的问题。但是,这对我们来说完全没有压力,我们不仅可以成功地建立索引,而且还可以利用到索引的速度,同时也不用手工清理。所以大数据的技术结合原有的存储引擎能力,才是我们的目标。这是一个多级SQL架构,其中浅绿色的是DCS,相当于发号的保安。在你连接节点之前,你的IP和谁相连是无法得知的,只有在运行的时候才能知道的。假设你在10.10.10.1集群上配一个IP,DCS可能在第三个节点,有一个Leader,两个Follower,如果其中一个发生宕机,那么马上会有新的Leader产生,这样保证DCS Server始终是可用的。如果query语句太长,可以使用Ctrl+C,后台会帮助你终止,而且不会损坏元数据(不过一般仍然不建议直接kill)。ESP是并行执行的服务,如果是简单的查询语句,例如 select * from table,那么直接去HBase中取数据就可以了,内存里面有账本,我们可以通过账本知道它存在HBase的哪个位置,然后通过二级帐本直接取到数据,不需经过ESP。如果是长query,是子查询,那么它就会启多层。DTM是分布式事务管理,集中了很多项专利,早是由惠普做的。我们利用了HBase的协处理器,虽然HBase是不适合做事务的,但是我们有MVCC和SVCC的技术,这些都可以保证分布式事务的执行。上图是混合式事务分析处理。一个企业的需求不会只有上面列举的一个或几个,肯定是全有的。无论是流式数据,Hadoop还是传统数仓,都少会分为三大阵营,流式处理阵营、Hadoop批处理阵营和分析阵营。上面端口、前端、后台以及汇总的数据都需要统一管理。我们实现了在一个平台上不离开Hadoop就把所有的数据都管理好。我们和OLAP列式存储有很大的区别,我们是一个偏行的列式存储,是混合型架构,我们的引擎可以将数据按你的查询习惯进行有组织的存放。混合型处理,为什么我们可以不离开Hadoop管理数据。首先前端的高并发接收是没有问题的,其次我们是乐观锁,不会因为一个死锁而影响其它。大家研究死锁的时候,我们死锁的问题早就解决掉了。我们可以用一条query语句去select三种表,例如Select * from item_table a, tv_table t where a.price <1000 t.resolution>4000 and userLike() = true;使用混合型处理可以立马全部都查询出来。但是如果没有这个方法,要想实现HBase和HIVE表之间的互通是很麻烦的。所以,这是一个结构化、半结构化和非结构化统一处理的平台。由于底层存储引擎的限制,我们在OLAP方面不是很擅长,但是我们底层有HIVE ORC格式的支持,所以列式存储速度会比较快。Oracle由于体量限制搞不定的事,找我们肯定没问题。我们一个节点打不过Oracle,两个节点也打不过Oracle,四个节点就可以和Oracle打平,四个以上节点,我们就可以打赢Oracle。例如,Oracle用二十分钟左右执行的大报表关联,里面嵌入了有十几个表,但是我们只用十分钟就可以完成。我们在联通做过测试实验,前面有大量的用户做查询,后面做总分析,业务办理应该是一个事务,要么全成功要么全失败。我们是一个大数据时代的混合型架构,兼具Hadoop和传统关系型数据库的特点,将结构化、半结构化和非结构化的数据放在统一的平台上做处理。我们和Hadoop上的所有生态不比单项,只论综合,我们是各方面均衡发展。企业级产品,首先是稳定性,其次是通用性。我们试图在大数据领域的版图里做大的一块板,也就是存储板,致力于将企业级业务全部串联起来,开发一个百花齐放的架构。上图是高可用的数据双活中心,主要的业务对象是电商、银行、金融市场等等。只要你的网络足够好,它就可以支持跨机房甚至跨城市。如果A集群切过来,B集群写完之后,才会返回成功,如果失败了,那么也会在应用程序里面配一个列表,秒级切换,不会丢失数据。例如,我在北京和上海各有一个集群,分别为A集群和B集群,它们互相朝对方写,他们两个都写完了,就直接返回。如果中间中断的话,B集群有全部的数据,北京和上海写的一条都不会丢。这样就彻底解决了冷热分离,读写分离,负载均衡的问题,因为我们没有中心点,所以是集群意义上的HA,是一个企业级服务的集群。Trafodion早是由天腾公司的Jim Gray研发的。后来,天腾被康柏并购,康柏又被惠普并购,所以这个技术就随着并购被保存在惠普内部。那么,惠普在卖硬件的时候,是分布式数据库卖的多还是固定卖的多?当然分布式。它的第二代产品叫NonStop SQL,现在美国75%的电信银行还在使用,50%的ATM用的数据库系统也是这个,第二代产品主要是做交易的。这之后的产品是HP NewView SQL,是一个分布式的数仓。2010年之后有一个新的技术叫Seaquest,是用来做SQL on Linux,我们做128个节点的并行执行,每天有800个TB的数据进来,两千多个数据源,然后做ETL清洗全部算出来。第四代产品就是Trafodion,是一个企业级的产品,经历了二十多年的打磨,现在已经是较为成熟的数据库技术。Apache Trafodion是一款开源的SQL引擎技术,大家如果想研究这个数据库技术,可以去http://trafodion.incubator.apache.org 网站查看。目前,Trafodion这个企业级的产品全部开源给了Apache社区,大家如果有兴趣可以去社区下载,Trafodion的所有功能大家都可以去尝试,它的安装复杂度和HBase比较像,基础安装比较容易,但是的东西还是需要大家花一点时间去研究。支持分区,Salt将数据平均分散、消除热点,Division始终把热的数据放在前面。如果把时间作为数据温度的判定标准,那么你的查询结果一定是近的事件。无论你采用哪种划分方式,它都可以保证新的数据在每个结点的上层。统计数据,我们会做类似于人口普查抽样的100万条数据摸底,彻底了解数据分布情况。Where条件查询是我们的强项,传统的查询方法一般是很暴力的,通常是在全盘扫描之后查看Where条件是否符合。但是我们完全不一样,先对Where条件进行匹配,缩小范围。Where条件越多,定位越快。然后,再加上index技术就组成了我们长期优化的技术。缓存管理,查询语句在次执行的时候可能会慢一点,但是到后面,执行速度会越来越快。我们这里缓存的不是结果而是执行计划,它会根据你的结构自动智能判断,然后缓存。多合一引擎是一个艰巨的任务,但是我们现在已经将它做到了企业化,我们对自己的产品是很有信心的,也相信多合一引擎是未来的发展趋势,如果大家有兴趣的话,可以来社区和我们交流,一起贡献力量。中国数据库技术大会(DTCC)是目前国内数据库与大数据领域大规模的技术盛宴,于每年春季召开,迄今已成功举办了七届。大会云集了国内外专家,共同探讨MySQL、NoSQL、Oracle、缓存技术、云端数据库、智能数据平台、大数据安全、数据治理、大数据和开源、大数据创业、大数据深度学习等领域的前瞻性热点话题与技术,吸引IT人士参会5000余名,为数据库人群、大数据从业人员、广大互联网人士及行业相关人士提供了极具价值的交流平台。