1 简介
为了更好地满足各种不同的业务场景,DorisDB支持多种数据模型,DorisDB中存储的数据需要按照特定的模型进行组织。数据导入功能是将原始数据按照相应的模型进行清洗转换并加载到DorisDB中,方便查询使用。
DorisDB提供了多种导入方式,用户可以根据数据量大小、导入频率等要求选择适合自己业务需求的导入方式。本节介绍数据导入的基本概念、基本原理、系统配置、不同导入方式的适用场景,以及一些佳实践案例和常见问题。
导入作业:导入作业读取用户提交的源数据并进行清洗转换后,将数据导入到DorisDB系统中。导入完成后,数据即可被用户查询到。
Label:所有导入作业都有一个Label,用于标识一个导入作业。Label可由用户指定或系统自动生成。Label在一个数据库内是的,一个Label仅可用于一个成功的导入作业。当一个Label对应的导入作业成功后,不可再重复使用该Label提交导入作业。如果某Label对应的导入作业失败,则该Label可以被再使用。该机制可以保证Label对应的数据多被导入一次,即At-Most-Once语义。
原子性:DorisDB中所有导入方式都提供原子性保证,即同一个导入作业内的所有有效数据要么全部生效,要么全部不生效,不会出现仅导入部分数据的情况。这里的有效数据不包括由于类型转换错误等数据质量问题而被过滤的数据。具体见常见问题小节里所列出的数据质量问题。
MySQL协议/HTTP协议:DorisDB提供两种访问协议接口:MySQL协议和HTTP协议。部分导入方式使用MySQL协议接口提交作业,部分导入方式使用HTTP协议接口提交作业。
Broker Load:Broker导入,即通过部署的Broker程序读取外部数据源(如HDFS)中的数据,并导入到DorisDB。Broker进程利用自身的计算资源对数据进行预处理导入。
Spark Load:Spark导入,即通过外部资源如Spark对数据进行预处理生成中间文件,DorisDB读取中间文件导入。这是一种异步的导入方式,用户需要通过MySQL协议创建导入,并通过查看导入命令检查导入结果。
FE:Frontend,DorisDB系统的元数据和调度节点。在导入流程中主要负责导入执行计划的生成和导入任务的调度工作。
BE:Backend,DorisDB系统的计算和存储节点。在导入流程中主要负责数据的 ETL 和存储。
Tablet:DorisDB表的逻辑分片,一个表按照分区、分桶规则可以划分为多个分片。
2 基本原理
导入执行流程:
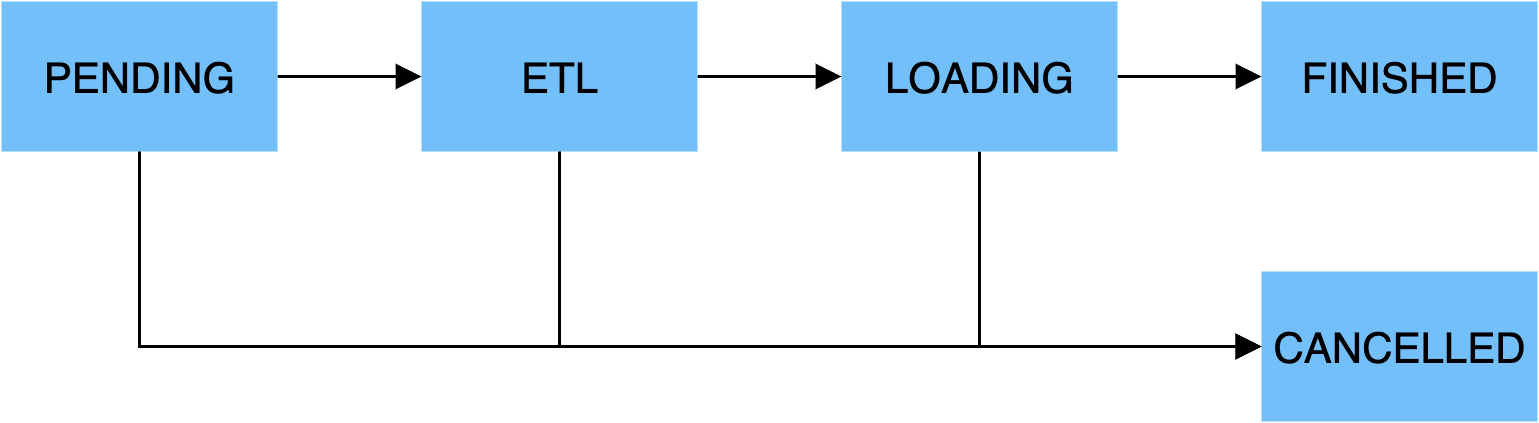
一个导入作业主要分为5个阶段:
PENDING
非必须。该阶段是指用户提交导入作业后,等待FE调度执行。
Broker Load和将来的Spark Load包括该步骤。
ETL
非必须。该阶段执行数据的预处理,包括清洗、分区、排序、聚合等。
Spark Load包括该步骤,它使用外部计算资源Spark完成ETL。
LOADING
该阶段先对数据进行清洗和转换,然后将数据发送给BE处理。当数据全部导入后,进入等待生效过程,此时导入作业状态依旧是LOADING。
FINISHED
在导入作业涉及的所有数据均生效后,作业的状态变成 FINISHED,FINISHED后导入的数据均可查询。FINISHED是导入作业的终状态。
CANCELLED
在导入作业状态变为FINISHED之前,作业随时可能被取消并进入CANCELLED状态,如用户手动取消或导入出现错误等。CANCELLED也是导入作业的一种终状态。
数据导入格式:
整型类(TINYINT,SMALLINT,INT,BIGINT,LARGEINT):1, 1000, 1234
浮点类(FLOAT,DOUBLE,DECIMAL):1.1, 0.23, .356
日期类(DATE,DATETIME):2017-10-03, 2017-06-13 12:34:03
字符串类(CHAR,VARCHAR):I am a student, a
NULL值:\N
3 导入方式简介
为适配不同的数据导入需求,DorisDB 系统提供了5种不同的导入方式,以支持不同的数据源(如HDFS、Kafka、本地文件等),或者按不同的方式(异步或同步)导入数据。
所有导入方式都支持 CSV 数据格式。其中 Broker Load 还支持 Parquet 和 ORC 数据格式。
Broker Load
Broker Load 通过 Broker 进程访问并读取外部数据源,然后采用 MySQL 协议向 DorisDB 创建导入作业。提交的作业将异步执行,用户可通过 SHOW LOAD 命令查看导入结果。
Broker Load适用于源数据在Broker进程可访问的存储系统(如HDFS)中,数据量为几十GB到上百GB。
Spark Load
Spark Load 通过外部的 Spark 资源实现对导入数据的预处理,提高 DorisDB 大数据量的导入性能并且节省 DorisDB 集群的计算资源。Spark load 是一种异步导入方式,需要通过 MySQL 协议创建导入作业,并通过 SHOW LOAD 查看导入结果。
Spark Load适用于初次迁移大数据量(可到TB级别)到DorisDB的场景,且源数据在Spark可访问存储系统(如HDFS)中。
Stream Load
Stream Load是一种同步执行的导入方式。用户通过 HTTP 协议发送请求将本地文件或数据流导入到 DorisDB中,并等待系统返回导入的结果状态,从而判断导入是否成功。
Stream Load适用于导入本地文件,或通过程序导入数据流中的数据。
Routine Load
Routine Load(例行导入)提供了一种自动从指定数据源进行数据导入的功能。用户通过 MySQL 协议提交例行导入作业,生成一个常驻线程,不间断的从数据源(如 Kafka)中读取数据并导入到 DorisDB 中。
Insert Into
类似 MySQL 中的 Insert 语句,DorisDB 提供 INSERT INTO tbl SELECT ...; 的方式从 DorisDB 的表中读取数据并导入到另一张表。或者通过 INSERT INTO tbl VALUES(...); 插入单条数据。
4.1.3.2 同步和异步
DorisDB目前的导入方式分为两种:同步和异步。
注意:如果是外部程序接入DorisDB的导入功能,需要先判断使用导入方式是哪类,然后再确定接入逻辑。
同步
同步导入方式即用户创建导入任务,DorisDB 同步执行,执行完成后返回导入结果。用户可通过该结果判断导入是否成功。
同步类型的导入方式有:Stream Load,Insert。
操作步骤:
用户(外部系统)创建导入任务。
DorisDB返回导入结果。
用户(外部系统)判断导入结果。如果导入结果为失败,可以再次创建导入任务。
异步
异步导入方式即用户创建导入任务后,DorisDB直接返回创建成功。创建成功不代表数据已经导入成功。导入任务会被异步执行,用户在创建成功后,需要通过轮询的方式发送查看命令查看导入作业的状态。如果创建失败,则可以根据失败信息,判断是否需要再次创建。
异步类型的导入方式有:Broker Load, Spark Load。
操作步骤:
用户(外部系统)创建导入任务;
DorisDB返回创建任务的结果;
用户(外部系统)判断创建任务的结果,如果成功则进入步骤4;如果失败则可以回到步骤1,重新尝试创建导入任务;
用户(外部系统)轮询查看任务状态,直到状态变为FINISHED或CANCELLED。
4 适用场景
HDFS导入
源数据存储在HDFS中,数据量为几十GB到上百GB时,可采用Broker Load方法向DorisDB导入数据。此时要求部署的Broker进程可以访问HDFS数据源。导入数据的作业异步执行,用户可通过SHOW LOAD命令查看导入结果。
源数据存储在HDSF中,数据量达到TB级别时,可采用Spark Load方法向DorisDB导入数据。此时要求部署的Spark进程可以访问HDFS数据源。导入数据的作业异步执行,用户可通过SHOW LOAD命令查看导入结果。
对于其它外部数据源,只要Broker或Spark进程能读取对应数据源,也可采用Broker Load或Spark Load方法导入数据。
本地文件导入
数据存储在本地文件中,数据量小于10GB,可采用Stream Load方法将数据快速导入DorisDB系统。采用HTTP协议创建导入作业,作业同步执行,用户可通过HTTP请求的返回值判断导入是否成功。
Kafka导入
数据来自于Kafka等流式数据源,需要向DorisDB系统导入实时数据时,可采用Routine Load方法。用户通过MySQL协议创建例行导入作业,DorisDB持续不断地从Kafka中读取并导入数据。
Insert Into导入
手工测试及临时数据处理时可以使用Insert Into方法向DorisDB表中写入数据。其中,INSERT INTO tbl SELECT ...;语句是从 DorisDB 的表中读取数据并导入到另一张表;INSERT INTO tbl VALUES(...);语句向指定表里插入单条数据。
————————————————
版权声明:本文为CSDN博主「白眼黑刺猬」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_37933018/article/details/116120460
