用完之后感觉,还是neo4j比较香,对于我这样仅使用工具进行分析的人来说,速度不是慢到离谱的话其实都可以接受,不能接受的就是:
1、可视化功能差;
2、图算法组件严重不足
这是个人在选择graph database的时候看重的两点,一方面根据以往的经验,通过可视化的方式可以非常直观的了解不同类型节点的网络行为模式,从而人工分析和总结出一些特定的行为规律,然后再对症下药,使用适当的图算法,将这些抽象的行为规律进行量化,从而更好的挖掘出特定的节点。那么这方面就需要保证开箱即用的图算法的丰富性了。
ArangoDB相对于neo4j的缺点如上,可视化功能差强人意,图算法组件很缺,而优点,在我来看:
1、据说速度很快,因为neo4j我是在单机上使用的开源社区版,而arangodb则是在集群上使用的,所以速度上不是很好比较,只不过看了一些评估的方法说是arangodb更快balabala;
2、UI界面简单方便干净无比,neo4j 4.X版本引入了bloom和其它的一些组件之后,界面功能,要素太多,看起来略杂乱无章;
3、关于开源的问题,实际上arangodb中的smartgraph功能也是只有企业版能够提供的,只不过相对于neo4j来说,开源的arangodb支持分布式部署;
前置知识:
arangodb是一个多模式数据库,可以存放文档,key-value pair和图数据,它将三者的存储进行了统一使得通过一套api来进行操作。
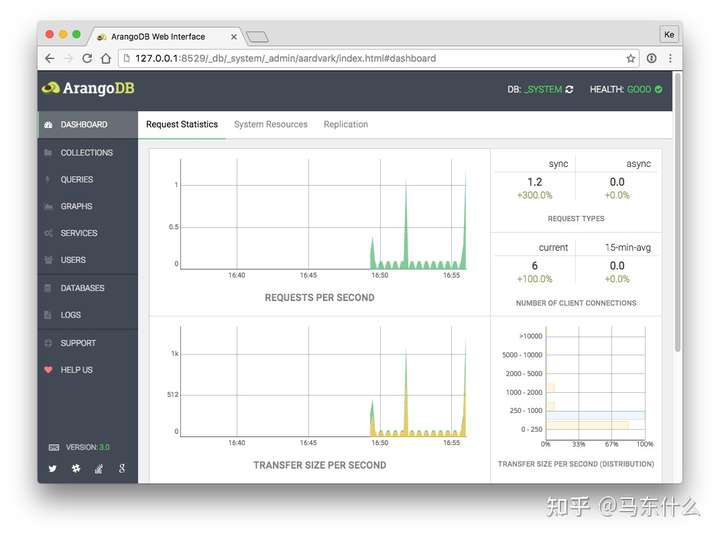
和hadoop类似,arangodb生态圈也有很多的功能组键,
就分析而言,主要使用web interface进行可视化,使用shell进行命令行界面的图计算(这也是arangodb不方便的一点,图计算无法实时返回,必须先计算结果,保存,然后再可视化,略麻烦)
核心部分,collections永远存放数据,所有的节点、边、文本数据等均存在在collectios中,以json的形式保存:
[
{ "_key": "key1", ... },
{ "_key": "key2", ... },
...
]
大概是这样的。
坑1:
目前,arangodb的graph data的导入有两种方式:
1、类似于neo4j-import,我们需要在arangodbsh,即arangodb的shell界面执行arangoimp 来导入图数据,arangodb是支持csv、tsv和json格式的文件进行import的。
导入命令大概是这样的:
arangoimport --file-path-to-airports.csv on your machine
--collection airports --create-collection true --type csv--file-path-to-airports.csv on your machine表示导入节点文件,除了csv,也可以支持tsv,txt此时也可以支持,设置sep参数就可以。
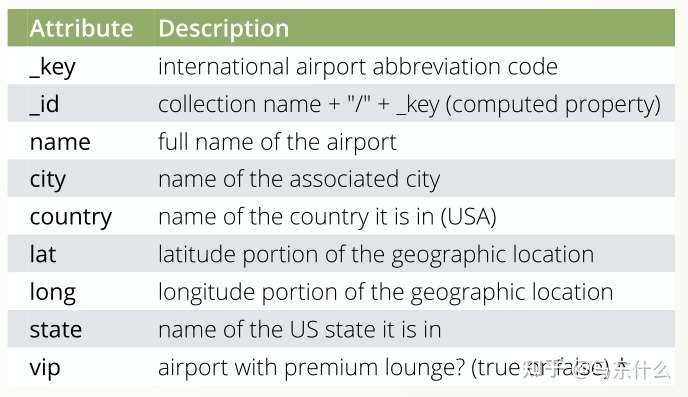
这里,如果原始airports节点文件中没有设定_key和_id,则导入的过程中会自动设定,_key是性标识符和索引,id就是上传后对应的collection的名字加上 key。
这里需要注意,建议是自己在csv文件里加入_key,(_id会根据你导入的collection的名字而自动生成),因为我们后面导入edges的时候需要通过 _id来进行edge两端节点的定位:
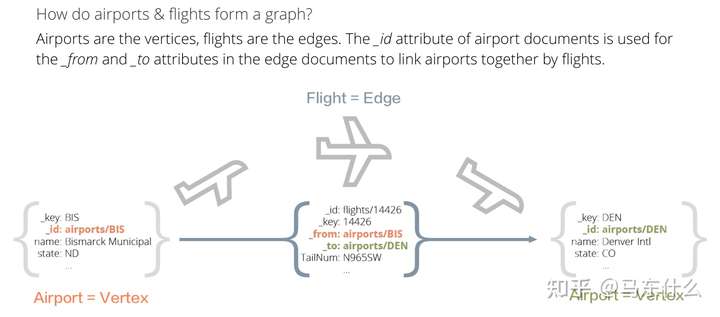
这意味着edges对应的csv要根据nodes的csv的 _key和import的collection,就是终对应的 _id 来确定 _from和_to这两个字段的值,所以好在导入的时候,文件层面处理好,无论是hive还是pyspark,构建一个性标识符都是很简单的,更简单的,我们可以直接用节点名的字符串作为_key。
其它的字段都是节点属性,和neo4j基本上一样的。
导入节点和节点属性之后,大概长这样:
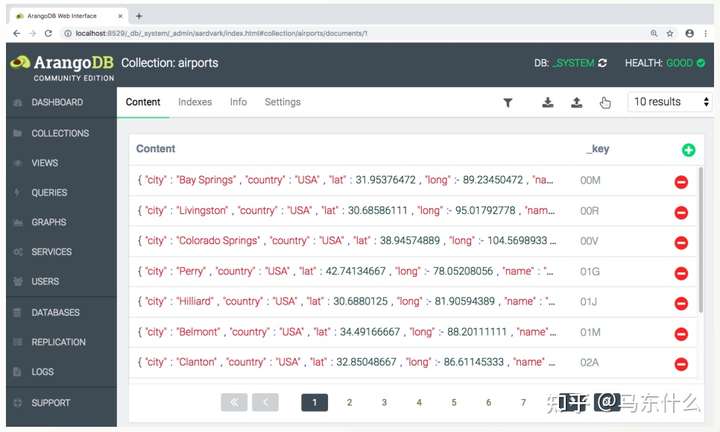
注意,所有的数据都是保存在collections里的,views是视图功能,和sql中的视图功能类似。带"_"符号的字段arangodb认为是内置属性,因此在content中并不显示。
接下来就准备导入edges的csv文件了。
arangoimport --file path to flights.csv on your machine
--collection flights --create-collection true --type csv
--create-collection-type edge导入命令基本类似,只不过需要额外指定导入的edges.csv的 collection-type是一个edge,如果是node则不需要指定,默认是 collection-document(就type和document两种collection类型)
我们的edges.csv要处理成这样,

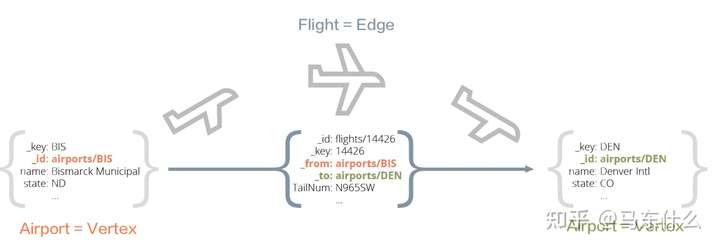
根据这个图我们可以知道,edges.csv的 _from和 _to 属性要和节点文件中的_id对应起来,而edges的id 是自动生成的,edges的key和id在做单边图的时候自动化生成就可以不用考虑太多,主要是from和to这两个内置属性要提前设置好存放到csv里,因此我们需要先导入节点数据,然后根据节点数据的id来定义 edges的from和to的取值是怎么样的。
2、除此之外,如果edges和nodes的数据量不大,可以直接在web interface中上传格式对应的json文件,注意文件格式格式格式,这个是容易错的,也就是id和from,to,key这些的对应关系要搞清楚,搞清楚了,用起来不要太白痴。
后,我们通过
这里的graph部分,按照api的要求添加节点和边的collection就可以构建出图来了。
剩下的部分就是AQL查询了。
AQL的语法非常简单,看下官网的教程半天就能上手写逻辑了。
很可惜的是,AQL目前官方仅仅给了部分路径搜索算法的demo,而中心性算法和社区发现算法需要到arangosh的命令行下调用prgel的图计算框架来实现(关键还不全。。。。)相对于neo4j实现的开箱即用的图算法来说少太多了。。。
