1. 概述
每个 Presto 服务都会提供一个 Web 界面,通常称为 Presto Web UI。可以使用与 Presto 服务器相同地址和 HTTP 端口号来访问 Presto Web UI。默认情况下,端口为 8080。例如,http://presto.example.com:8080。Presto Web UI 可在每个 Presto 的 Coordinator 上访问,并可用于检查和监控 Presto 集群以及已处理的查询。
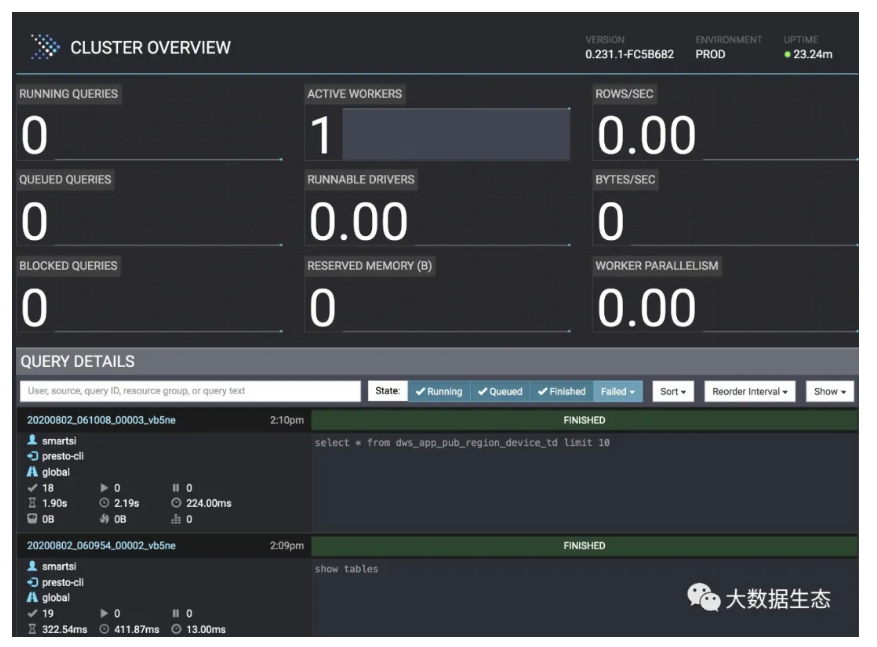
当你次使用 Presto Web UI 时,你会看到如下图所示的页面。顶部展示了 Presto 的集群信息,底部展示了查询列表。这些信息对于操作 Presto 以及管理正在运行的查询都具有巨大的价值:
2. 集群详情(Cluster-Level Details)
我们首先看一下 Presto 的集群信息:
Running Queries:当前集群中正在运行的查询个数,包含了所有用户的查询。例如,如果 Alice 运行了两个查询,Bob 运行了5个查询,那么展示查询总个数为7。
Queued Queries:当前集群中排队等待的查询个数,同样也是包含所有用户的查询。排队等待的查询等待 Coordinator 根据 Resource Group 配置进行调度。
Blocked Queries:当前集群中被阻塞的查询个数。阻塞的查询因为缺少可用的 Split 或者资源,所以无法进行处理。
Active Workers:当前集群中活跃的 Worker 节点个数。添加或删除 Worker 节点,无论是手动还是自动,都会注册到 Discovery 服务中,并更新在这展示的数字。
Runnable Drivers:当前集群中可运行 Drivers 的平均数量。
Reserved Memory:当前集群中 Reserved Memory 的大小,单位字节。
Rows/Sec:当前集群中所有正在运行的查询每秒钟平均处理的输入行数。
Bytes/Sec:当前集群中所有正在运行的查询每秒钟平均处理的输入字节数。
Worker Parallelism:Worker 的并发总数,即集群中所有 Worker 上所有正在运行查询的线程 CPU 时间总和。
3. 查询列表(Query List)
Presto Web UI 页面底部展现了近运行的查询,如下图所示:
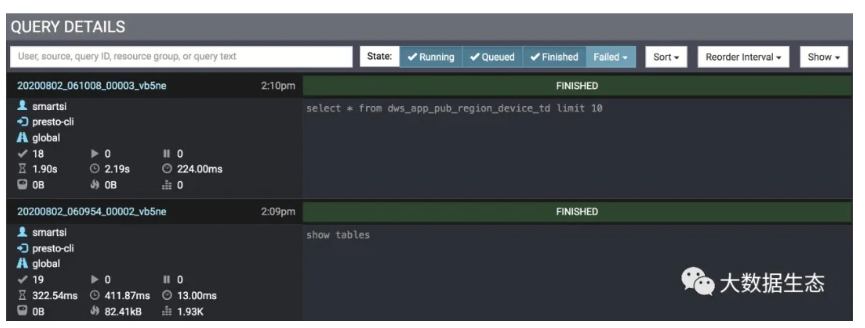
查询列表中展示的查询个数取决于 Presto 集群配置。如上图所示我们可以通过查询控件来搜索我们要展示的查询。毕竟在集群非常繁忙时,数十或数百个查询会同时运行。可以在查询控件中键入我们要搜索查询的条件,可以是查询启动器的用户名,查询来源,查询ID,资源组,或者查询 SQL 文本以及查询状态。
查询控件旁边的 State 过滤器可以让我们基于查询状态:Running(运行中)、Queued(排队中)、Finished(已完成)、Failed(失败)来选择或排除某些查询。Failed 状态还可以再细分为具体失败原因:内部错误,外部错误,资源错误,或者用户错误。左边的控件可以让我们决定查询的排序顺序、重新排序的时间以及要展示查询大数量。查询控件下面每一行都代表一个查询。每行的左列展示查询有关信息。右列展示查询 SQL 文本以及查询状态,如下图所示查询摘要示例:
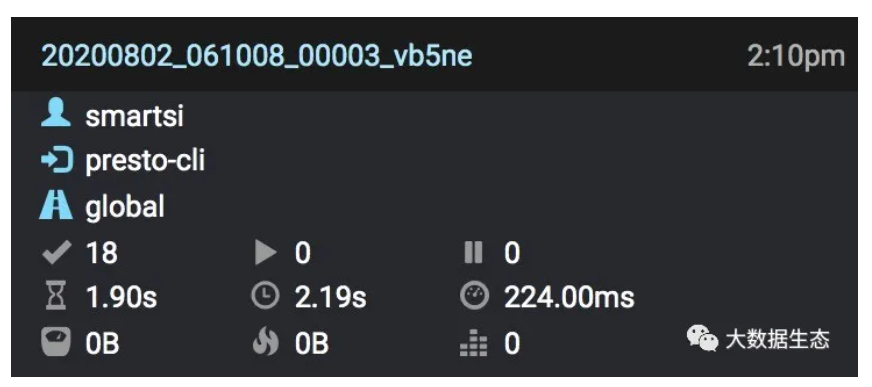
我们来看一下每个查询的详细信息。上面一行左侧内容是查询ID。在这个示例中,查询ID为 20200802_061008_00003_tccrc。我们可能会注意到查询ID的开头由日期和时间(UTC)组成,并使用 YYYYMMDD_HHMMSS 的时间格式。后半部分是查询的增量计数器,计数器 00003 表示这是自 Coordinator 启动以来运行的第3个查询。后一部分 tccrc 是 Coordinator 的随机标识符。如果重新启动 Coordinator,随机标识符和计数器也都会重置。右上角的时间是运行查询的本地时间。
下面三个值 smartsi,presto-cli 以及 global 分别表示运行查询的用户,查询来源以及运行查询的资源组。在此示例中,用户默认为 smartsi,我们通过 presto-cli 来提交查询。如果在运行 Presto CLI 时指定 –user 标志,那么显示的用户将更改为我们指定的值。提交查询来源也可以不是 presto-cli,例如,当应用程序使用 JDBC 驱动程序连接到 Presto 时,提交查询来源会显示为 presto-jdbc。客户端还可以使用 Presto CLI 的 –source 标志以及 JDBC 连接字符串属性将其设置为任何所需的值。
下面我将介绍后几行标示的具体含义,它们包含了查询的一些重要信息:
Completed Splits:每个查询已完成的 Split 数。该示例显示已完成 18 个 Split。在运行查询之前,该值为0。在查询执行期间,每完成一个 Split 时,该值都会加1。
Running Splits:每个查询正在运行的 Split 数。查询完成后,该值变为0。但是,在执行过程中,这个数字会随着 Split 的执行以及完成而改变。
Queued Splits:每个查询排队等待的 Split 数。查询完成后,该值变为0。但是,在执行期间,这个数字会随着 Split 在排队状态和运行状态之间切换而改变。
Wall Time:执行查询所花费的总时间,不包含排队等待的时间。即使正在分页展示结果,该值仍会继续增长。
Total Wall Time:该值与 Wall Time 相同,但是包含排队等待时间。Wall Time 不包含查询排队时间。从提交查询开始到完成接收结果所需要的总时间。
CPU Time:处理查询所花费的总CPU时间。这个值通常大于 Wall Time,因为在不同 Works 以及线程之间的并行执行会分开计算并进行累加。例如,如果四个CPU每个都花费1秒来处理查询,那么终的总CPU时间为4秒。
Current Total Reserved Memory:查询执行时当前使用的总保留内存大小。对于完成的查询,此值为0。
Peak Total Memory:查询执行期间的总内存使用峰值。查询执行期间某些操作可能需要大量内存,因此知道峰值是什么是很有用。
Cumulative User Memory:在整个查询处理中使用的累积用户内存。这并不意味着所有内存都被同时使用。这是累积的内存量。
接下来,我们了解一下有关查询处理的不同状态,这些状态显示在查询语句上方,如下图所示:

常见的状态有:RUNNING(运行中),FINISHED(完成),USER CANCELLED(用户已取消)或 USER ERROR(用户错误)。USER CANCELED 表示查询已被用户杀死,USER ERROR 表示用户提交的 SQL 查询语句包含语法或语义错误。
当正在运行的查询等待资源或其他 Split 去处理时被阻塞,就会发生 BLOCKED 状态。看到查询反复出现这种状态也是正常的。但是,如果查询卡在这种状态下,这就意味着查询或 Presto 集群有问题。如果发现查询卡在这种状态,首先检查使用的内存以及系统配置。查询可能需要非常高的内存或者计算量很大。此外,如果客户端没有返回结果或无法足够快地读取结果,则这种背压会使查询进入 BLOCKED 状态。
我们可能还会看到查询处于 PLANNING 状态。对于较大,复杂的查询,通常会发生这种情况,这种查询需要生成大量查询计划和优化才能运行查询。如果经常看到这种情况,似乎要花费大量时间为查询生成查询计划,则应调查可能的原因,例如可用内存是否不足或 Coordinator 的处理能力。
4. 查询详情(Query Details View)
到目前为止,我们已经看到有关 Presto 集群的整体信息以及查询的别信息。Web UI 还为每个查询提供了更多的详细信息。只需单击某个查询,即可访问查询详情页面。查询详情页面有几个 Tab 可以供我们查看 Presto 查询的更多详细信息,如下图所示:

4.1 概述(Overview)
概述页面包括如下几个方面:
Session
Execution
Resource Utilizations Summary
Timeline
Query
Prepare Query
Stages
Tasks

如下图所示 Stages 部分展示了查询 Stages 的信息:
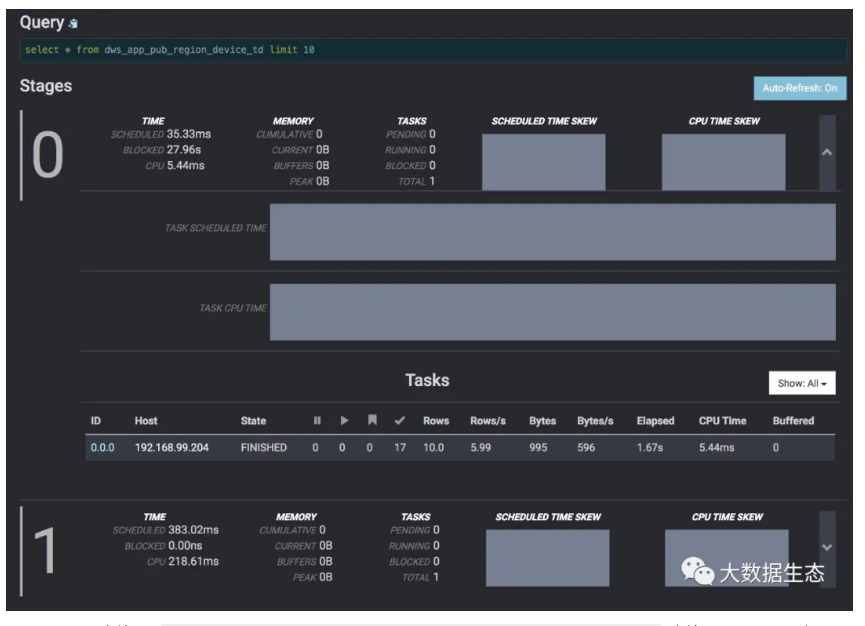
这个特定的查询是 SELECT * FROM dws_app_pub_region_device_td limit 10 查询语句。因为它是一个比较简单的查询,所以只有两个 Stage。Stage 0 是运行在 Coordinator 上的单任务 Stage,负责合并 Stage 1 中任务的结果并执行终聚合。Stage 1 是一个运行在不同 Works 上的分布式 Stage。该 Stage 负责读取数据并计算部分聚合。
下面我们看看 Stage 中一些有用的数值:
TIME—SCHEDULED:Stage 在完成所有 Task 之前需要持续调度的时间。
TIME—BLOCKED:Stage 在等待数据被阻塞的时间。
TIME—CPU:Stage 中所有 Task 花费的 CPU 时间。
MEMORY–CUMULATIVE:在整个 Stage 中使用的总内存。但这并不意味着所有内存是被同时使用的。它是整个处理期间使用的累积内存量。
MEMORY—CURRENT:Stage 当前已用的总保留内存。查询完成后,此值变为0。
MEMORY—BUFFERS:当前数据等待被处理所消耗的内存量。
MEMORY—PEAK:Stage 中的总内存峰值。在查询执行期间算子可能需要大量内存,因此知道峰值是多少是很有用。
TASKS—PENDING:Stage 中待处理的 Task 数。查询完成后,此值变为0。
TASKS—RUNNING:Stage 中正在运行的 Task 数。查询完成后,此值变为0。在查询执行期间,此值会随着 Task 的运行和完成而发生变化。
TASKS—BLOCKED:Stage 中被阻塞的 Task 数。查询完成后,此值变为0。在查询执行期间,随着 Task 在阻塞和运行状态之间切换时,此值发生变化。
TASKS—TOTAL:查询已完成的 Task 数。
SCHEDULED TIME SKEW、CPU TIME SKEW、TASK SCHEDULED TIME、TASK CPU TIME:这些直方图展示了不同 Works 上多个任务的计划时间,CPU时间,任务计划时间以及任务CPU时间的分布与变化。这样,我们就可以在运行时间比较长的分布式查询期间诊断 Worker 的利用率。
如下图所示展示了 Task 更多详细信息:

让我们下面看看 Task 列表中:
| 列 | 说明 |
|---|---|
| ID | Task 标识符,格式为 stage-id.task-id。例如,ID:0.0 表示 Stage 0 的 Task 0,ID:1.2 表示 Stage 1 的 Task 2。 |
| Host | Task 运行在 Worker 节点的IP地址。 |
| State | State 的状态,可以是 PENDING,RUNNING, 或者 BLOCKED。 |
| Pending Splits | Task 等待处理的 Split 的个数。 |
| Running Splits | Task 正在处理的 Split 的个数。这个值会随着 Task 的运行而改变。Task 运行完成,此值变为0。 |
| Blocked Splits | Task 被阻塞的 Split 的个数。这个值会随着 Task 的运行而改变。Task 运行完成,此值变为0。 |
| Completed Splits | Task 已经完成的 Split 的个数。这个值会随着 Task 的运行而改变。Task 运行完成,此值等于总 Split 个数。 |
| Rows | Task 已处理的行数。这个值会随着 Task 的运行而增加。 |
| Rows/s | Task 每秒处理的行数。 |
| Bytes | Task 已处理的字节数。这个值会随着 Task 的运行而增加。 |
| Bytes/s | Task 每秒处理的字节数。 |
| CPU Time | Task 调度花费的总CPU时间。 |
| Buffered | 当前等待处理时缓冲的数据量。 |
4.2 实时计划(Live Plan)
Live Plan 页面中我们可以实时查看查询执行处理过程,如下图所示:
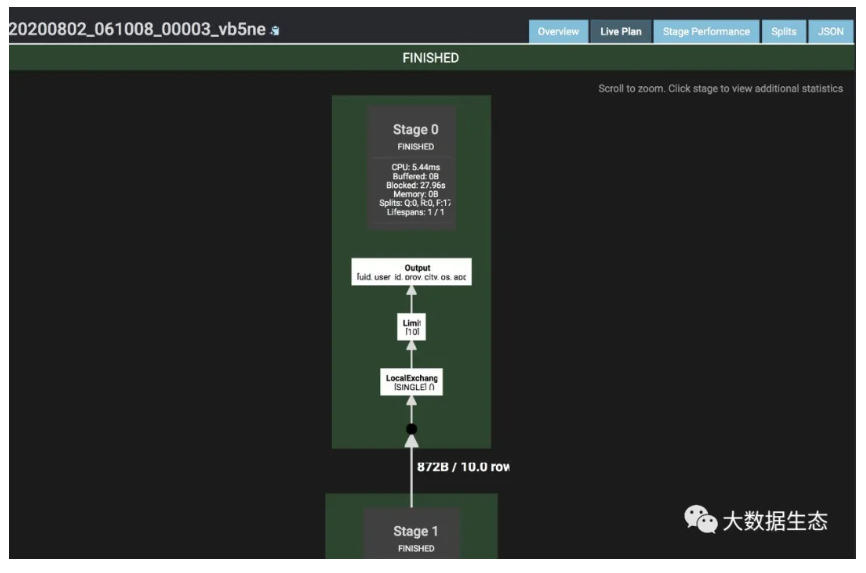
查询执行过程中,Plan 中的计数器会随着查询执行的进度而更新。Plan 中的值与概述(Overview)页面中描述的值相同,不同的是在查询执行计划上实时展现。查看此视图有助于可视化查询卡在哪里或在哪里花费大量时间,以便诊断或改善性能问题。
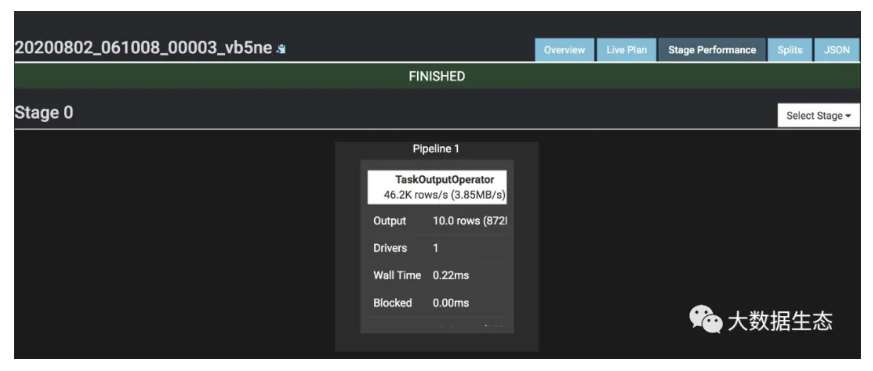
4.3 Stage性能(Stage Performance)
Stage 性能页面在查询处理结束之后会提供 Stage 性能的详细可视化视图,如下图所示。该视图可以认为是 Live Plan 视图的向下钻取,我们可以在其中看到 Stage 中 Task 的算子流水线。Plan 中的值与概述(Overview)页面中描述的值相同。查看此视图有助于查看查询卡在哪里或在哪里花费大量时间,以便诊断或解决性能问题。我们可以单击每个单独的算子来查看详细信息:
4.4 Split
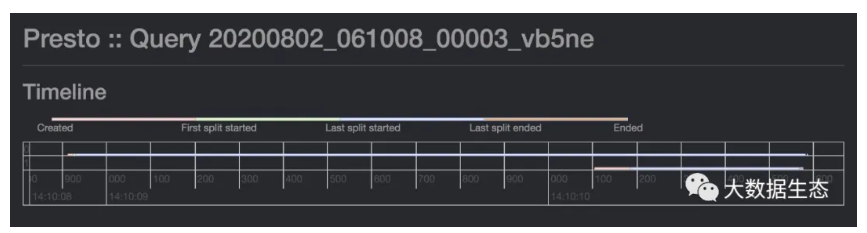
Split 页面展示了在查询执行期间创建和处理 Split 的时间线:
4.5 JSON
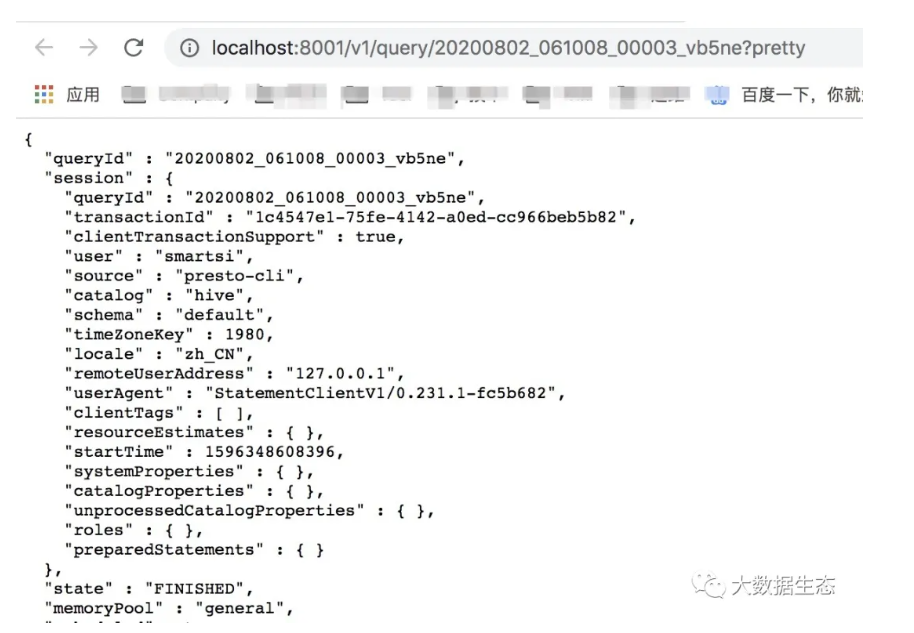
JSON 页面以 JSON 格式提供所有查询的详细信息。这些信息会根据其检索的快照进行更新:
来源 https://mp.weixin.qq.com/s/2zSJ__unwAC3_dZV18qiVg
