导言
从出生的天起,Snowflake 就是一个完全基于云的数据仓库。创始人并没有把已有的数据仓库简单移植到云服务商提供的服务器上,而是充分利用云服务理论上无限水平扩展的特性,实现了存算分离的架构,给用户提供了更好的 workload isolation 以及更灵活的计价方式。这篇文章就想着重讨论了 Snowflake 是如何根据云服务的特性,实现返回结果集 (ResultSet)。
从存算分离说起
下图是 Snowflake 的三层架构:
- 底层的是 storage layer,用来存放用户的数据。Snowflake 并不维护自己 storage engine,而是完全依赖于云厂商的 blob storage service,比如说 AWS 的 S3。
- 中间一层是 compute layer,代表了用户的计算集群,snowflake 称其为 warehouse。Warehouse 的大小用 T-Shirt Size 来标识,小的 XSMALL,集群只有一个节点,到大的 6XL, 由512个计算节点组成。用户可以根据不同的工作负载 (workload) 启用不同的计算集群,防止 workload 之间相互影响。对于同一个 workload,用户也可以增加或者减少集群中的计算节点,来提高运算速度或者节约成本。
- 上层的 service layer,主要负责 sql 的编译/优化,session 的管理,计算资源的调度等等。这一层的服务是 multi-tenant,在不同的用户之间共享。
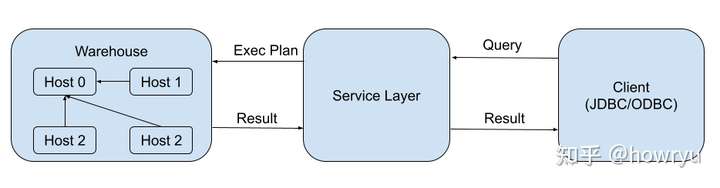
一个 query 的 life cycle 是这样的:
- 客户端通过 JDBC 或者 REST API 提交 query
- Service Layer 编译 query,生成执行计划 ( execution plan )
- 把执行计划分发到 Warehouse 执行查询
- Warehouse 完成查询,并返回结果
那么,Warehouse 到底是如何返回结果集的呢?
简单的实现方法
首先要明确的一点是,snowflake 是为 masive parallel processing (MPP)而设计的,所以query 的运算结果是分散在各个运算节点的内存中的。所以简单的实现是这样的:
- 给各个运算节点分配一个 rankId,集群中的各个运算节点都知道互相的 rankId。
- 所有运算节点都向 rankId 为 0 的节点 (master) 返回计算结果。
- master 节点聚合所有节点的结果,并返回给 Service Layer。
- Service Layer 将结果 stream 回客户端。
事实上,早期的时候 Snowflake 也确实是这么做的。好处就是实现起来相对简单,但是很快就会出现性能瓶颈:
- 前面已经说过了,每个客户都可以为不同的 workload 单独启动 warehouse,可是 service layer 却是 multi-tenant,也就是客户之间共享。
- 随着客户数、 workload 的数量以及结果集数据量的增加,service layer 需要处理大量的 IO traffic,很快就成为了整个系统的瓶颈。
- 这个时候直接的想法就是增加 service layer 的节点数量,或者是额外维护一个 streaming service 专门处理结果集的 IO,但有更好的方法吗?
将结果集写回 Cloud Blob Service
Snowflake 是一个基于云的服务,所以任何新功能的设计都想着充分利用云的优势。于是Snowflake 的设计者就想到了把结果集写回云的 blob storage,并把结果集的 URL 返回给客户端,并让客户端自行下载结果集。具体的流程如下:
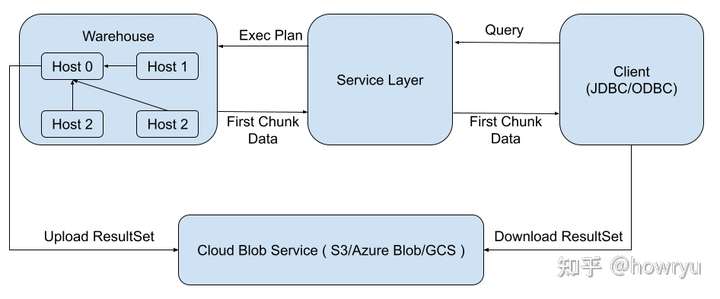
- 给各个运算节点分配一个 rankId,集群中的各个运算节点都知道互相的 rankId。
- 所有运算节点都向 rankId 为 0 的节点 (master) 返回计算结果。
- master 节点聚合所有节点的结果,将 First Chunk Data 返回给 Service Layer。如果整个结果集的数据量大于 First Chunk Size Limit 的时候,把剩下的结果集写回 Cloud Blob。
- Service Layer 将 Result Metadata, First chunk Data 以及剩下 ResultSet 的 URL(如果需要的话)返回给客户端。
- 客户端从 Cloud Blob 下载完整的结果集(如果需要的话)。
值得注意的是:
- 不管结果集的大小,First Chunk Data总会和 ResultSet Metadata 一起返回给客户端,主要是为了降低 Latency。
- 在步骤3中,master 节点会把整个结果集 split 多个 chunk,每个 chunk 会单独写成 cloud storage 上的一个文件。文件大小大概在 16 MB 左右(压缩后)。
Parallel Result Upload
使用上一节的算法后,我们解决了整个系统的瓶颈。但是对于每一个结果集特别大的查询来说,性能瓶颈在于只有 master 节点在上传结果集。我们可以继续优化一下:Warehouse 中每一个计算节点都有对 Cloud Blob Storage 进行读写的能力。所以所有的计算节点可以并行上传结果集。具体算法与上一节类似:
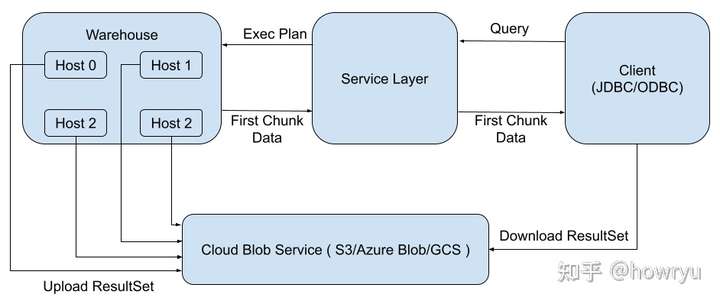
- 给各个运算节点分配一个 rankId,集群中的各个运算节点都知道互相的 rankId。
- 所有运算节点在内存中缓存计算结果,如果任意节点的数据量超过了阈值,那么节点之间就会互相通知。所有节点就会并行向 Cloud Storage 写回结果集 (Parallel Result Upload)。
- 如果没有节点的数据量超过了阈值,所有运算节点都向 rankId 为 0 的节点 (master) 返回计算结果。
- master 节点聚合所有节点的结果,将 First Chunk Data 返回给 Service Layer。如果整个结果集的数据量大于 First Chunk Size Limit 的时候,把剩下的结果集写回 Cloud Blob。
- Service Layer 将 Result Metadata, First chunk Data 以及剩下 ResultSet 的 URL(如果需要的话)返回给客户端。
- 客户端从 Cloud Blob 下载完整的结果集(如果需要的话)。
其实不难发现,和上一节的算法相比,只是多加了步骤2。但是在结果集数据量巨大的情况下,并行处理会极大的提升吞吐量,提高 query 的响应速度。
Result Fetch
对于客户端 (JDBC/ODBC) 来说,当结果集数据量较大的时候,我们就可以多线程并行下载结果集,并由主线程 consume 结果集,是一个简单的 Consumer-Producer 模型:
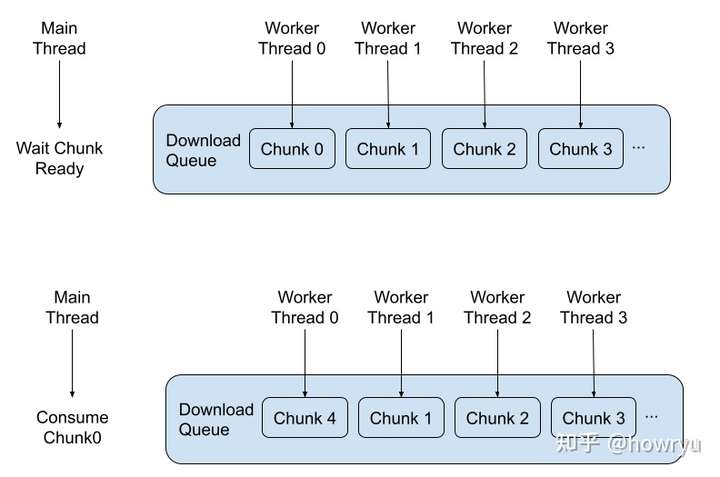
主线程只有当下一个 chunk 没有被下载完成的时候才会被 block 住,其他时候就会一直 consume 结果集。worker thread 会尽可能的提前下载 result chunk。当内存中 buffer 的结果集达到了大的阈值时,worker thread 会被 block住,只有当主线程 consume 完 chunk 的时候,worker thread 才有可能继续下载。
Parallel Result Fetch
上传结果集的另一个好处就是,为多进程并行读取结果集提供了可能性。尤其是读取结果集的 consumer 是一个分布式系统,spark 就是好的例子:Snowflake 提供的 Spark Connector 可以让 spark 从 Snowflake 读取数据集并且在 Spark 中进行下一步的数据处理。Spark Connector 会利用 JDBC 从 master 节点提交 query,拿回结果集的 URL 后,把 URL 分发至所有 spark 的 worker 进程,并行下载结果集。
同样的,Snowflake PythonConnector 也支持在类似 Dask 这样的系统中并行读取结果集。
Result Scan
因为结果集被持久化在 Blob Storage 上,所以 Snowflake 支持在 SQL 中使用内置的 Table Function 查询之前的结果集,并且对结果集的 data 进行 projection、aggregation 和 join 等操作:
-- suppose query id is abc123
select c1, c2
from orders
;
-- result scan
select c1, c2
from table(result_scan('abc123'))
;
-- result scan with projection and join
select c1, to_number(c2) as c2 number
from table(result_scan('abc123')) as r
join lineitem as l
on r.c1 = l.c1
where c2 > 100
;来源 https://zhuanlan.zhihu.com/p/340520316
