иғҢжҷҜ
еүҚйқўдёҖзҜҮжҲ‘们иҜҙеҲ°пјҢ2020е№ҙ5жңҲд»ҪпјҢRedisе®ҳж–№жҺЁеҮәдәҶд»Өдәәзһ©зӣ®зҡ„ Redis 6.0пјҢжҸҗеҮәеҫҲеӨҡж–°зү№жҖ§пјҢеҢ…жӢ¬дәҶе®ўжҲ·з«Ҝзј“еӯҳ (Client side caching)гҖҒACLгҖҒThreaded I/O е’Ң Redis Cluster Proxy зӯүиҜёеӨҡж–°зү№жҖ§гҖӮеҰӮдёӢпјҡ

жҲ‘们д№ҹдё“й—ЁеҜ№ Redis 6.0зҡ„ Threaded I/OпјҲеӨҡзәҝзЁӢзҪ‘з»ңI/O жЁЎејҸпјүеҒҡдәҶеҫҲиҜҰз»Ҷзҡ„иҜҙжҳҺпјҢжңүе…ҙи¶Јзҡ„зҝ»еҲ°еүҚйқўдёҖзҜҮгҖӮ
иҝҷдёҖзҜҮе’ұ们е°ұжқҘиҒҠдёӢиҝҷдёӘClient side cachingпјҲе®ўжҲ·з«Ҝзј“еӯҳпјүпјҢзңӢзңӢRedisдёәд»Җд№ҲйңҖиҰҒе®ўжҲ·з«Ҝзј“еӯҳгҖҒжҳҜеҹәдәҺд»Җд№ҲеҺҹзҗҶе®һзҺ°зҡ„пјҢд»ҘеҸҠе…·дҪ“еә”иҜҘжҖҺд№ҲдҪҝз”ЁгҖӮ
1 дёәд»Җд№ҲйңҖиҰҒе®ўжҲ·з«Ҝзј“еӯҳ
1.1 зј“еӯҳжңҚеҠЎзҡ„зӣ®зҡ„
еӣһйЎҫдёҖдёӢжҲ‘们 еңЁзҜҮ гҖҠж·ұеҲ»зҗҶи§Јй«ҳжҖ§иғҪRedisзҡ„жң¬иҙЁгҖӢдёӯиҜҙиҝҮзҡ„пјҢRedisзҡ„иҜ»еҶҷж“ҚдҪңйғҪжҳҜеңЁеҶ…еӯҳдёӯе®һзҺ°дәҶпјҢзӣёеҜ№е…¶д»–зҡ„жҢҒд№…еҢ–еӯҳеӮЁпјҲеҰӮMySQLгҖҒFileзӯүпјҢж•°жҚ®жҢҒд№…еҢ–еңЁзЈҒзӣҳдёҠпјүпјҢжҖ§иғҪдјҡй«ҳеҫҲеӨҡгҖӮеӣ дёәжҲ‘们еңЁж“ҚдҪңж•°жҚ®зҡ„ж—¶еҖҷпјҢйңҖиҰҒйҖҡиҝҮ IO ж“ҚдҪңе…Ҳе°Ҷж•°жҚ®иҜ»еҸ–еҲ°еҶ…еӯҳйҮҢпјҢеўһеҠ е·ҘдҪңжҲҗжң¬гҖӮ

дёҠйқўйӮЈеј еӣҫжқҘжәҗдәҺзҪ‘з»ңпјҢеҸҜд»ҘзңӢзңӢд»–зҡ„йҮ‘еӯ—еЎ”жЁЎеһӢпјҢи¶ҠеҫҖдёҠжү§иЎҢж•ҲзҺҮи¶Ҡй«ҳпјҢд»·ж јд№ҹе°ұи¶ҠиҙөгҖӮдёӢйқўз»ҷеҮәжҜҸдёҖеұӮзҡ„жү§иЎҢиҖ—ж—¶еҜ№жҜ”пјҡ
- еҜ„еӯҳеҷЁпјҡ0.3 ns
- L1й«ҳйҖҹзј“еӯҳпјҡ0.9 ns
- L2й«ҳйҖҹзј“еӯҳпјҡ2.8 ns
- L3й«ҳйҖҹзј“еӯҳпјҡ12.9 ns
- дё»еӯҳпјҡ120 ns
- жң¬ең°дәҢзә§еӯҳеӮЁпјҲSSDпјүпјҡ50~150 us
- иҝңзЁӢдәҢзә§еӯҳеӮЁпјҡ30 ms
жҲ‘们дёҫдёӘL1е’ҢSSDзҡ„зӣҙи§ӮеҜ№жҜ”пјҢеҰӮжһңL1иҖ—ж—¶1sзҡ„иҜқпјҢSSDдёӯе·®дёҚеӨҡиҰҒ15~45е°Ҹж—¶пјҢжүҖд»ҘеҶ…еӯҳеұӮйқўзҡ„и®ҝй—®ж•ҲзҺҮиҝңиҝңжҜ”зЈҒзӣҳеұӮйқўзҡ„и®ҝй—®ж•ҲзҺҮй«ҳеҫҲеӨҡгҖӮ
жҖ»д№ӢпјҢзј“еӯҳзҡ„зӣ®зҡ„жҳҜеҹәдәҺеҜ№жҢҒд№…еҢ–еңЁзЈҒзӣҳзҡ„ж•°жҚ®пјҲжҜ”еҰӮMySQLж•°жҚ®гҖҒж–Ү件数жҚ®зӯүпјүзҡ„й«ҳж•Ҳи®ҝй—®пјҢдёәдәҶжҸҗеҚҮж•ҲзҺҮиҖҢе®һзҺ°зҡ„гҖӮгҖҠRedis in ActionгҖӢдёӯд№ҹжҸҗеҲ°пјҢ Redis иғҪеӨҹжҸҗеҚҮжҷ®йҖҡе…ізі»еһӢж•°жҚ®еә“зҡ„ 10 ~ 100 еҖҚзҡ„жҖ§иғҪгҖӮ
ж•°жҚ®и®ҝй—®иҝҮзЁӢеҰӮдёӢеӣҫпјҢRedis еӯҳеӮЁдәҶзғӯзӮ№ж•°жҚ®пјҢеҪ“еӨ©жҲ‘们иҜ·жұӮдёҖдёӘж•°жҚ®ж—¶пјҢе…ҲеҺ»и®ҝй—®зј“еӯҳеұӮпјҢеҰӮжһңдёҚеӯҳеңЁеҶҚеҺ»и®ҝй—®ж•°жҚ®еә“пјҢиҝҷж ·еҸҜд»Ҙи§ЈеҶіеӨ§йғЁеҲҶй«ҳж•ҲиҜ»еҸ–ж•°жҚ®зҡ„дёҡеҠЎеңәжҷҜпјҢжҖ§иғҪжҳҜзј“еӯҳйҮҚиҰҒзҡ„д»·еҖјд№ӢдёҖгҖӮ
1.2 еӯҳеңЁзҡ„й—®йўҳ
иҷҪ然жҲ‘们дҪҝз”ЁRedisжҸҗеҚҮдәҶж•°жҚ®зҡ„и®ҝй—®ж•ҲзҺҮпјҢдҪҶжҳҜдҫқ然еӯҳеңЁдёҖдәӣй—®йўҳгҖӮеҹәдәҺеҲҶеёғејҸи®ҝй—®зҡ„зј“еӯҳжңҚеҠЎжҳҜдёҖдёӘзӢ¬з«Ӣзҡ„жңҚеҠЎеӯҳеңЁпјҢдёҖиҲ¬жғ…еҶөдёӢи®ҝй—®е®ғйңҖиҰҒз»ҸиҝҮиҝҷеҮ дёӘжӯҘйӘӨпјҡ
- иҝһжҺҘзј“еӯҳжңҚеҠЎпјҲдёҖиҲ¬дёҚдјҡи·ҹи®Ўз®—жңҚеҠЎеңЁдёҖдёӘе®һдҫӢдёҠпјү
- жҹҘжүҫ并иҜ»еҸ–ж•°жҚ®пјҲI/Oж“ҚдҪңпјү
- зҪ‘з»ңдј иҫ“
- ж•°жҚ®еәҸеҲ—еҢ–еҸҚеәҸеҲ—еҢ–
иҝҷдәӣж“ҚдҪңдёҖж ·зҡ„жҳҜеҜ№жҖ§иғҪжңүеҪұе“Қзҡ„пјҢйҡҸзқҖдә’иҒ”зҪ‘зҡ„еҸ‘еұ•пјҢжөҒйҮҸдёҚж–ӯзҡ„иҶЁиғҖпјҢеҫҲе®№жҳ“иҫҫеҲ° Redis зҡ„жҖ§иғҪдёҠйҷҗгҖӮ
жүҖд»ҘпјҢжҲ‘们з»ҸеёёдјҡдҪҝз”ЁиҝӣзЁӢзј“еӯҳпјҲжң¬ең°зј“еӯҳпјүпјҢжқҘиҫ…еҠ©еӨ„зҗҶпјҢе°ҶдёҖдәӣй«ҳйў‘иҜ»дҪҺйў‘еҶҷзҡ„ж•°жҚ®жҡӮеӯҳеңЁжң¬ең°пјҢиҜ»еҸ–ж•°жҚ®зҡ„ж—¶еҖҷпјҢе…ҲжЈҖжҹҘжң¬ең°зј“еӯҳжҳҜеҗҰеӯҳеңЁпјҢдёҚеӯҳеңЁеҶҚи®ҝй—®иҝңз«Ҝзј“еӯҳжңҚеҠЎзҡ„ж•°жҚ®пјҢиҝӣдёҖжӯҘжҸҗй«ҳи®ҝй—®ж•ҲзҺҮгҖӮ
еҰӮжһңRedisд№ҹдёҚеӯҳеңЁпјҢе°ұеҸӘиғҪеҺ» ж•°жҚ®еә“ дёӯжҹҘиҜўпјҢжҹҘеҲ°зҡ„ж•°жҚ®еҶҚи®ҫзҪ®еҲ° Redis е’Ң жң¬ең°зј“еӯҳдёӯпјҢиҝҷж ·еҗҺз»ӯзҡ„иҜ·жұӮе°ұдёҚз”ЁеҶҚиө°еҲ°ж•°жҚ®еә“дёӯдәҶгҖӮ
дёҖиҲ¬жҲ‘们дјҡдҪҝз”ЁMemcachcedгҖҒGuava Cache зӯүжқҘеҒҡзә§еҲ«зј“еӯҳпјҲжң¬ең°зј“еӯҳпјүпјҢдҪҝз”ЁRedisдҪңдёә第дәҢзә§зј“еӯҳпјҲзј“еӯҳжңҚеҠЎпјүпјҢжң¬ең°еҶ…еӯҳйҒҝе…ҚдәҶ иҝһжҺҘгҖҒжҹҘиҜўгҖҒзҪ‘з»ңдј иҫ“гҖҒеәҸеҲ—еҢ–зӯүж“ҚдҪңпјҢжҖ§иғҪжҜ”зј“еӯҳжңҚеҠЎеҝ«еҫҲеӨҡпјҢиҝҷз§ҚжЁЎејҸеӨ§еӨ§еҮҸе°‘ж•°жҚ®е»¶иҝҹгҖӮ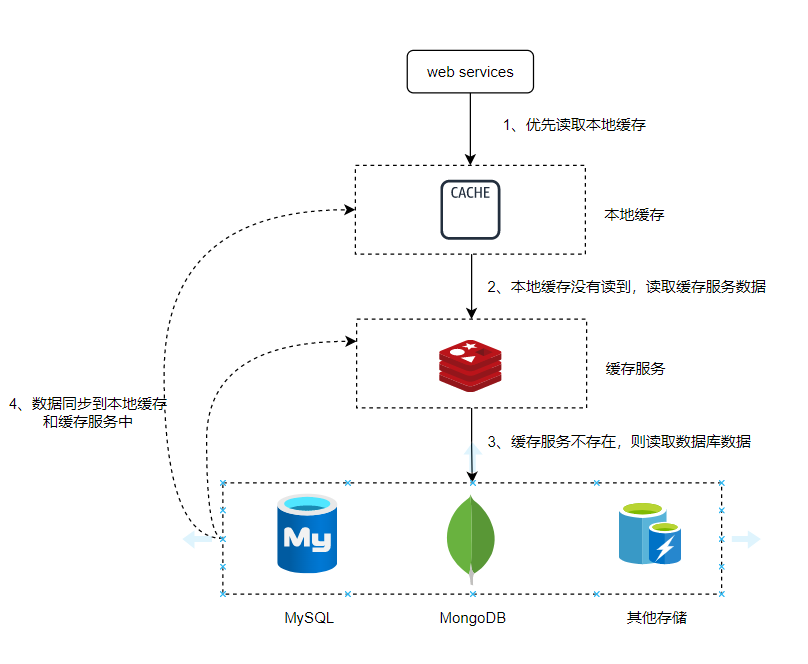
2 е®ўжҲ·з«Ҝзј“еӯҳе®һзҺ°еҺҹзҗҶ
RedisиҮӘе·ұе®һзҺ°дәҶдёҖдёӘе®ўжҲ·з«Ҝзј“еӯҳпјҢз”Ёд»ҘеҚҸеҠ©жңҚеҠЎз«ҜRedisзҡ„ж“ҚдҪңпјҢеҸ«еҒҡtrackingгҖӮ
жҲ‘们еҸҜд»ҘйҖҡиҝҮе‘Ҫд»ӨжқҘй…ҚзҪ®е®ғпјҡ
CLIENT TRACKING ON|OFF [REDIRECT client-id] [PREFIX prefix] [BCAST] [OPTIN] [OPTOUT] [NOLOOP]
е®ўжҲ·з«Ҝзј“еӯҳж ёеҝғзҡ„й—®йўҳе°ұжҳҜеҪ“Redisдёӯзҡ„зј“еӯҳеҸҳжӣҙжҲ–иҖ…еӨұж•ҲдәҶд№ӢеҗҺпјҢеҰӮжһңиғҪеӨҹеҸҠж—¶жңүж•Ҳзҡ„йҖҡзҹҘеҲ°е®ўжҲ·з«Ҝзј“еӯҳпјҢжқҘдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§гҖӮ
Redis 6.0 е®һзҺ° Tracking еҠҹиғҪпјҢиҝҷдёӘеҠҹиғҪжҸҗдҫӣдәҶдёӨз§Қж–№жЎҲжқҘе®һзҺ°ж•°жҚ®зҡ„дёҖиҮҙжҖ§дҝқиҜҒпјҡ
- RESP2 еҚҸи®®зүҲжң¬зҡ„иҪ¬еҸ‘жЁЎејҸ
- RESP3 еҚҸи®®зүҲжң¬зҡ„жҷ®йҖҡжЁЎејҸе’Ңе№ҝж’ӯжЁЎејҸ
жҺҘдёӢжқҘжҲ‘们дёҖдёӘдёӘжқҘеҲҶжһҗгҖӮ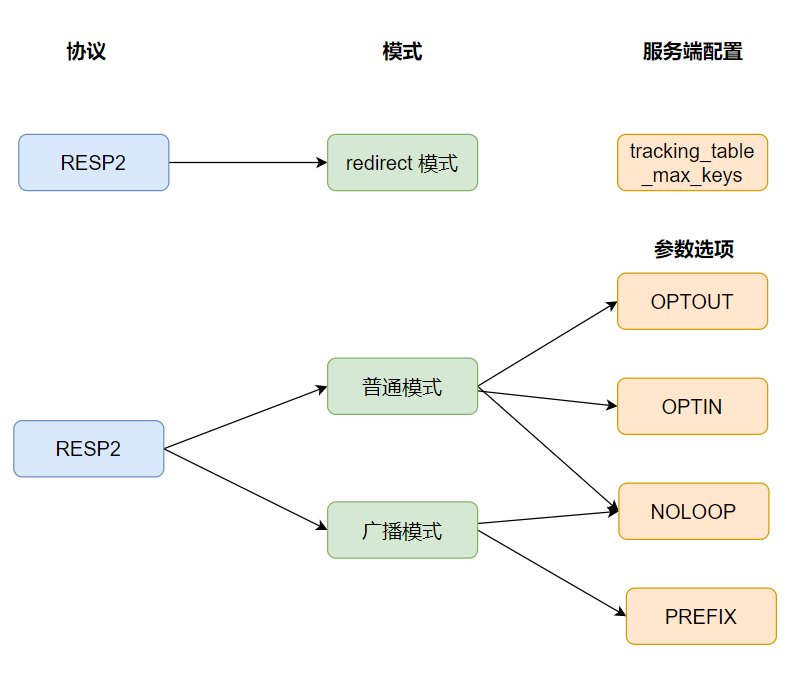
2.1 жҷ®йҖҡжЁЎејҸ
RedisдҪҝз”Ё TrackingTable жқҘеӯҳеӮЁжҷ®йҖҡжЁЎејҸзҡ„е®ўжҲ·з«Ҝж•°жҚ®пјҢе®ғзҡ„ж•°жҚ®зұ»еһӢжҳҜеҹәж•°ж ‘ ( radix tree)гҖӮ
radix treeжҳҜй’ҲеҜ№зЁҖз–Ҹзҡ„й•ҝж•ҙеһӢж•°жҚ®жҹҘжүҫзҡ„еӨҡеҸүжҗңзҙўж ‘пјҢиғҪеҝ«йҖҹдё”иҠӮзңҒз©әй—ҙзҡ„е®Ңжҳ е°„пјҢжғіж·ұе…ҘдәҶи§Јзҡ„еҸҜд»ҘзңӢиҝҷзҜҮд»Ӣз»ҚгҖӮ

еҰӮеӣҫдёӯпјҢе®ўжҲ·з«ҜIDеҲ—иЎЁдёҺRedisеӯҳеӮЁй”®зҡ„жҢҮй’Ҳе…·жңүжҳ е°„е…ізі»гҖӮиҖҢRedisй”®еҜ№иұЎзҡ„жҢҮй’ҲеҜ№еә”зҡ„е°ұжҳҜеҶ…еӯҳең°еқҖпјҢж•°жҚ®з»“жһ„жҳҜLongгҖӮ
еҪ“ејҖеҗҜдәҶtrack еҠҹиғҪд№ӢеҗҺпјҢж“ҚдҪңе…·жңүд»ҘдёӢзү№жҖ§пјҡ
- еҪ“RedisиҺ·еҸ–дёҖдёӘй”®еҖјдҝЎжҒҜж—¶пјҢradix tree дјҡи°ғз”Ё enableTracking ж–№жі•и®°еҪ• key е’Ң clientId зҡ„жҳ е°„е…ізі»пјҢи®°еҪ•еҲ° TrackingTable дёӯгҖӮ
- еҪ“RedisеҲ йҷӨжҲ–иҖ…дҝ®ж”№дёҖдёӘй”®еҖјдҝЎжҒҜж—¶
- radix tree ж №жҚ®keyи°ғз”Ё trackingInvalidateKey ж–№жі•жҹҘжүҫеҜ№еә”зҡ„ Clinet ID
- и°ғз”Ё sendTrackingMessage ж–№жі•жҠҠеӨұж•Ҳзҡ„й”®еҖјдҝЎжҒҜпјҲinvalidate ж¶ҲжҒҜпјү еҸ‘йҖҒз»ҷиҝҷдәӣ Clinet IDгҖӮ
- еҸ‘йҖҒе®ҢжҲҗд№ӢеҗҺд»ҺTrackingTableдёӯеҲ йҷӨжҳ е°„е…ізі»гҖӮ
- Clientе…ій—ӯ track еҠҹиғҪеҗҺпјҢйҒҮеҲ°еӨ§йҮҸеҲ йҷӨж“Қзҡ„ж—¶еҖҷпјҢдёҖиҲ¬жҳҜжҮ’еҲ йҷӨпјҢеҸӘе°Ҷ CLIENT_TRACKING ж Үеҝ—дҪҚеҲ йҷӨгҖӮ
- й»ҳи®Ө track жЁЎејҸжҳҜдёҚејҖеҗҜпјҢйңҖиҰҒйҖҡиҝҮе‘Ҫд»ӨејҖеҗҜпјҢеҸӮиҖғеҰӮдёӢпјҡ
CLIENT TRACKING ON|OFF
+OK
GET test
$7
archite
2.2 е№ҝж’ӯжЁЎејҸ(BCAST)

е№ҝж’ӯжЁЎејҸдёҺжҷ®йҖҡжЁЎејҸзұ»дјјпјҢд№ҹжҳҜйҮҮз”Ёжҳ е°„е…ізі»жқҘеҜ№з…§пјҢдҪҶе®һзҺ°иҝҮзЁӢиҝҳжҳҜжңүеҢәеҲ«зҡ„пјҡ
- еӯҳеӮЁзҡ„еҶ…е®№дёҚдёҖж ·пјҡеҰӮеӣҫпјҢйҮҮз”ЁPrefix Table жқҘеӯҳеӮЁе®ўжҲ·з«Ҝж•°жҚ®пјҢеӯҳеӮЁзҡ„жҳҜ еүҚзјҖеӯ—з¬ҰдёІжҢҮй’Ҳ е’Ң е®ўжҲ·з«Ҝж•°жҚ®пјҲе®ўжҲ·з«ҜIDеҲ—иЎЁ + йңҖйҖҡзҹҘзҡ„keyеҖјеҲ—иЎЁпјү зҡ„жҳ е°„е…ізі»гҖӮ
- еҲ йҷӨй”®еҖјзҡ„ж—¶жңәдёҚдёҖж ·пјҡ
- radix tree ж №жҚ®keyи°ғз”Ё trackingInvalidateKey ж–№жі•жҹҘжүҫPrefixTableгҖӮ
- еҲӨж–ӯжҳҜеҗҰдёәз©әпјҢдёҚдёәз©әеҲҷ и°ғз”Ё trackingRememberKeyToBroadcast еҜ№й”®еҲ—иЎЁиҝӣиЎҢиҝӣиЎҢйҒҚеҺҶпјҢжүҫеҲ°з¬ҰеҗҲеүҚзјҖеҢ№й…Қ规еҲҷзҡ„пјҢ并记еҪ•дҪҚзҪ®гҖӮ
- еңЁдәӢ件еӨ„зҗҶе‘ЁжңҹеҮҪж•° beforeSleep дёӯ и°ғз”Ё trackingBroadcastInvalidationMessages еҮҪж•°жқҘеҸ‘йҖҒж¶ҲжҒҜгҖӮ
- еҸ‘йҖҒе®ҢжҲҗд№ӢеҗҺд»Һ PrefixTable дёӯеҲ йҷӨжҳ е°„е…ізі»гҖӮ
2.3 иҪ¬еҸ‘жЁЎејҸ
RESP 3 еҚҸи®® жҳҜ Redis 6.0 ж–°еҗҜз”Ёзҡ„еҚҸи®®пјҢдҪҝз”Ёжҷ®йҖҡжЁЎејҸжҲ–иҖ…е№ҝж’ӯжЁЎејҸйңҖиҰҒдҫқиө–иҝҷз§ҚеҚҸи®®пјҢиҝҷж ·еҜ№дәҺRESP 2 еҚҸи®®зҡ„е®ўжҲ·з«ҜжқҘиҜҙе°ұдјҡжңүй—®йўҳгҖӮжүҖд»ҘиЎҚз”ҹйҷӨдәҶеҸҰдёҖз§ҚжЁЎејҸпјҡйҮҚе®ҡеҗ‘пјҲredirectпјүгҖӮ
- RESP 2 ж— жі•зӣҙжҺҘ PUSH еӨұж•Ҳж¶ҲжҒҜпјҢжүҖд»ҘдёҚиғҪзӣҙжҺҘиҺ·еҸ–еҲ°еӨұж•Ҳж•°жҚ®пјҲRedis Client 2пјүгҖӮ
- ж”ҜжҢҒ RESP 3 еҚҸи®®зҡ„е®ўжҲ·з«ҜпјҲRedis Clinet 1пјү е‘ҠиҜү Server е°ҶеӨұж•Ҳж¶ҲжҒҜйҖҡиҝҮ Pus/Sub йҖҡзҹҘз»ҷ RESP 2 е®ўжҲ·з«ҜгҖӮ
- иҖҢRedis Client 2 пјҲRESP 2 пјүжҳҜйҖҡиҝҮи®ўйҳ…е‘Ҫд»Ө SUBSCRIBEпјҢдё“й—Ёи®ўйҳ…з”ЁдәҺеҸ‘йҖҒеӨұж•Ҳж¶ҲжҒҜзҡ„йў‘йҒ“ redis:invalidateгҖӮ
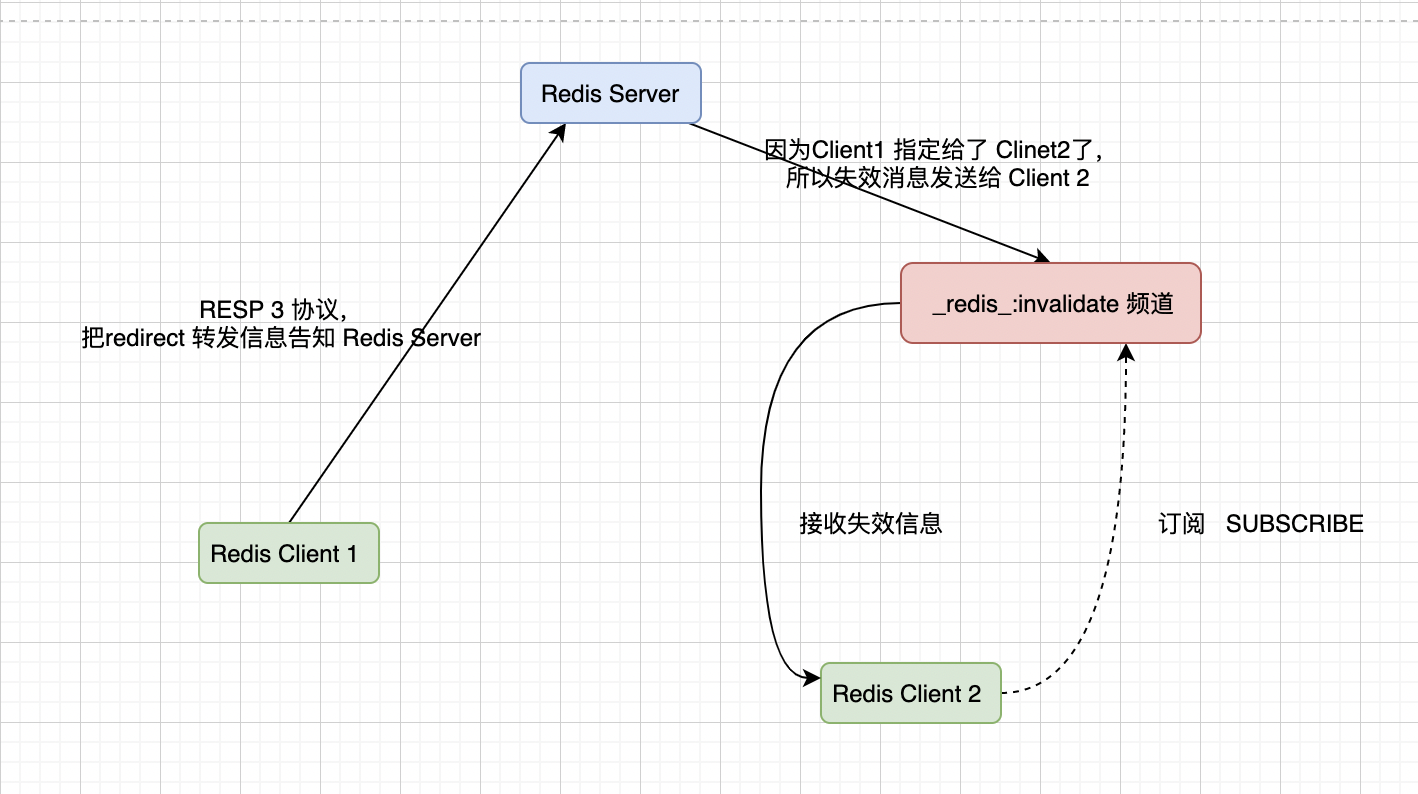
еҰӮдёӢжүҖзӨәпјҡ
# Redis Client 2 пјҲж”ҜжҢҒRESP 2пјүжү§иЎҢи®ўйҳ…
client id : 888
subscribe _redis_:invalidate
# Redis Client 1пјҲж”ҜжҢҒRESP 3пјүпјҢиҪ¬еҸ‘з»ҷ 2
client tracking on bcast redirect 888
3 жҖ»з»“
3.1 й»ҳи®ӨжЁЎејҸпјҲжҷ®йҖҡжЁЎејҸпјү
- жңҚеҠЎз«Ҝи®°еҪ•е®ўжҲ·з«Ҝж“ҚдҪңиҝҮзҡ„ keyпјҢkey еҜ№еә”зҡ„еҖјеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢдјҡеҸ‘йҖҒ Invalidation Messages з»ҷRedis е®ўжҲ·з«ҜгҖӮ
- жңҚеҠЎз«Ҝи®°еҪ•keyдҝЎжҒҜдјҡж¶ҲиҖ—дёҖдәӣеҶ…еӯҳпјҢдҪҶжҳҜеҸ‘йҖҒеӨұж•Ҳж¶ҲжҒҜзҡ„иҢғеӣҙпјҢйҷҗеҲ¶еңЁеӯҳеӮЁзҡ„keyиҢғеӣҙеҶ…пјҢи®Ўз®—е’ҢзҪ‘з»ңдј иҫ“еҸҳзҡ„иҪ»йҮҸгҖӮ
- дјҳзӮ№жҳҜиҠӮзңҒ CPU д»ҘеҸҠжөҒйҮҸеёҰе®ҪпјҢдҪҶжҳҜдјҡеҚ з”ЁдёҖдәӣеҶ…еӯҳгҖӮ
3.2 е№ҝж’ӯжЁЎејҸ
- жңҚеҠЎз«ҜдёҚи®°еҪ• keyпјҢиҖҢжҳҜи®ўйҳ… key зҡ„зү№е®ҡеүҚзјҖпјҢеҪ“еҢ№й…ҚеүҚзјҖзҡ„ key зҡ„еҖјж”№еҸҳж—¶пјҢеҸ‘йҖҒ Invalidation Messages з»ҷ Redisе®ўжҲ·з«ҜгҖӮ
- дјҳзӮ№жҳҜжңҚеҠЎз«Ҝзҡ„еҶ…еӯҳж¶ҲиҖ—е°‘пјҢдҪҶжҳҜдјҡжҚҹиҖ—жӣҙеӨҡзҡ„ CPU еҺ»еҒҡеүҚзјҖеҢ№й…Қзҡ„и®Ўз®—гҖӮ
3.3 иҪ¬еҸ‘жЁЎејҸ
- дёәдәҶе…је®№ resp2 еҚҸи®®зҡ„дёҖз§ҚиҝҮжёЎжЁЎејҸ
- дјҳзӮ№жҳҜеҚ з”ЁеҶ…еӯҳе°‘пјҢCPUеҚ з”ЁеӨҡ
е®ўжҲ·з«Ҝзҡ„зј“еӯҳ
е®ўжҲ·з«Ҝзј“еӯҳпјҢйңҖиҰҒдёҡеҠЎдҫ§иҮӘе·ұе®һзҺ°пјҢRedis жңҚеҠЎз«ҜеҸӘиҙҹиҙЈйҖҡзҹҘдҪ key зҡ„еҸҳеҠЁпјҲеҲ йҷӨгҖҒж–°еўһпјүгҖӮ
