分布式数据库中事务的原子性和隔离性问题是分布式事务实现的难点,在GoldenDB分布式数据库中引入了binlog自动补偿机制以保证原子性、GTM全局事务管理器以保证事务的隔离性,实现一致性读和一致性写。本文简要介绍了分布式数据库的理论以及GoldenDB中分布式事务的实现。
1、分布式数据库理论
1.1 CAP理论
分布式数据库的设计遵循CAP理论,即一个分布式系统不能同时满足Consistency(一致性)、Availability(可用性)和Partition Tolerance(分区容忍性)这三个基本需求。
一致性Consistency
一致性指的是更新操作成功并返回客户端后,分布式集群中每个节点都返回相同的、新的数据。对于一致性,可以从客户端和服务端两个不同的视角来看:从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题;从服务端来看,则是更新如何复制到整个分布式系统,以保证数据的终一致性。在多进程并发访问时,根据获取更新过的数据的不同策略,一致性又分为强一致性、弱一致性和终一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是终一致性。
可用性Availability
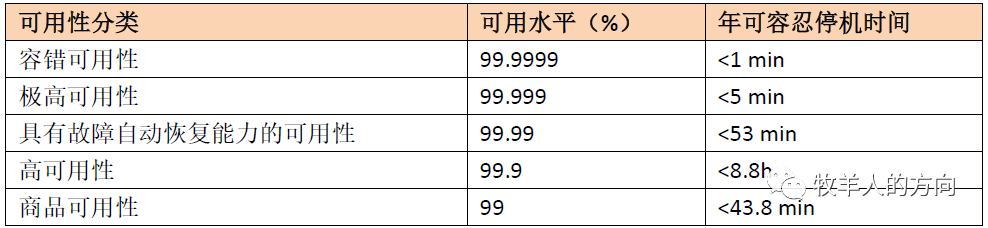
通常说金融核心业务系统的可用性水平达到5个9,即即全年停机时间不超过 (1-0.99999)36524*60 = 5.256 min,这是一个极高的要求。
分区容忍性Partition Tolerance
分区容忍性指的是分布式系统在网络分区出现故障时,仍然能够对外提供满足一致性和可用性的服务。在分布式数据库系统中,分区容忍性和扩展性紧密关联,一个好的分区容忍性能够保证当其中几台机器故障或者网络异常后,能够快速的进行故障隔离不影响其它机器的正常运行;也能够保证系统扩展性,节点的新增和删除做到对业务无感知。
CAP的权衡
CP without A:分布式系统容许系统停机或者长时间无响应,一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。传统的分布式数据库事务都属于这种模式,对于金融行业的分布式数据库产品而言,优先保证数据的一致性。
AP without C:分布式系统中允许数据不一致,一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
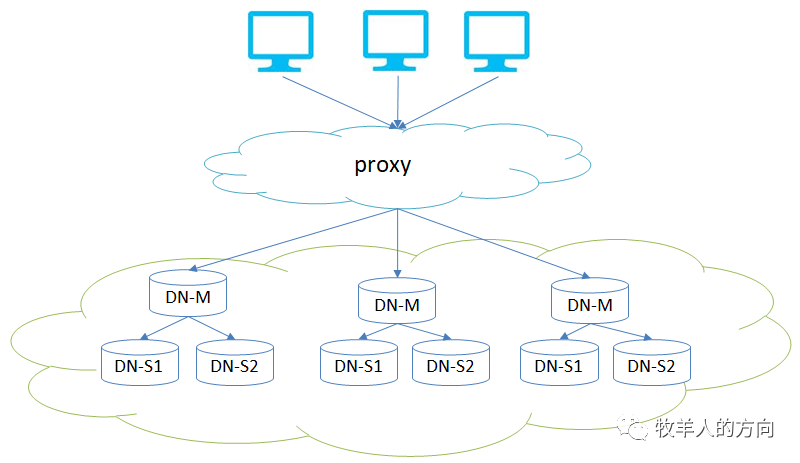
在实际的分布式数据库系统中,基于分片解决扩展性问题并可以实现负载均衡,当某个分片服务不可用时,只会影响部分业务,即服务降级。同时基于多副本构成集群架构,提升系统的高可用。
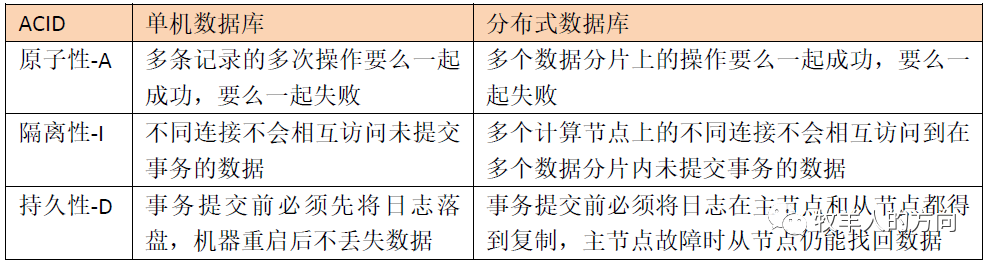
1.2 ACID原则
原子性:一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性限制没有被破坏。
隔离性:当两个或者多个事务并发访问数据库的同一数据时所表现出的相互关系。
持久性:在事务完成以后,该事务对数据库所作的更改便持久地保存在数据库之中,并且是完全的。
1.3 分布式事务一致性算法
在分布式系统中,每一个机器节点虽然都能够明确地知道自己在进行事务操作过程中的结果是成功或失败,但却无法直接获取到其他分布式节点的操作结果。因此,当一个事务操作需要跨越多个分布式节点的时候,为了保持事务处理的ACID特性,就需要引入一个称为"协调者"的组件来统一调度所有分布式节点的执行逻辑,这些被调度的分布式节点则被称为"参与者"。协调者负责调度参与者的行为,并终决定这些参与者是否要把事务真正进行提交。基于以上原则,分布式事务一致性算法主要包括2PC、3PC、Paxos和Raft。
1.3.1 2PC(two-phase commit)
阶段1:请求阶段
在请求阶段,协调者将通知事务参与者准备提交或取消事务,然后进入表决过程。在表决过程中,参与者将告知协调者自己的决策:同意(事务参与者本地作业执行成功)或取消(本地作业执行故障)。
阶段2:提交阶段
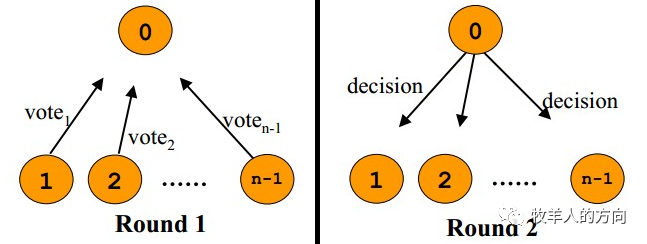
同步阻塞:在二阶段提交的执行过程中,所有参与该事务操作的逻辑都处于阻塞状态,也就是说,各个参与者在等待其他参与者响应的过程中,将无法进行其他任何操作。
单点问题:协调者的角色在整个二阶段提交协议中起到了非常重要的作用。一旦协调者出现问题,那么整个二阶段提交流程将无法运转,更为严重的是,如果协调者是在阶段二中出现问题的话,那么其他参与者将会一直处于锁定事务资源的状态中,而无法继续完成事务操作。
数据不一致:在阶段二时,当协调者向所有的参与者发送Commit请求之后,发生了局部网络异常或者是协调者尚未发送完Commit请求之前自身发生了崩溃,导致终只有部分参与者收到了Commit请求。于是,这部分收到了Commit请求的参与者就会进行事务的提交,而其他没有收到Commit请求的参与者则无法进行事务提交,于是整个分布式系统便出现了数据不一致现象。
太过保守:二阶段提交协议没有设计较为完善的容错机制,任何一个节点的失败都会导致整个事务的失败。
1.3.2 3PC(three-phase commit)
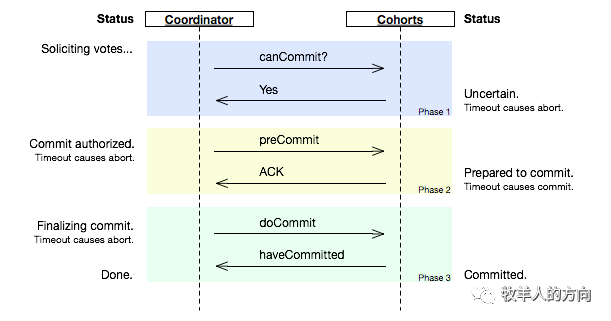
1)CanCommit阶段
3PC的CanCommit阶段和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
2)PreCommit阶段
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会进行事务的预执行:
发送预提交请求。协调者向参与者发送PreCommit请求,并进入Prepared阶段。
事务预提交。参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
响应反馈。如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待终指令。
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就中断事务:
发送中断请求。协调者向所有参与者发送abort请求。
中断事务。参与者收到来自协调者的abort请求之后(或超时之后,仍未收到Cohort的请求),执行事务的中断。
3)DoCommit阶段
执行提交
发送提交请求。协调者接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
事务提交。参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
响应反馈。事务提交完之后,向协调者发送ACK响应。
完成事务。协调者接收到所有参与者的ACK响应之后,完成事务。
中断事务
协调者没有接收到参与者发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
3PC协议降低了参与者阻塞范围,并能够在出现单点故障后继续达成一致。缺点是引入 preCommit阶段,在这个阶段如果出现网络分区,协调者无法与参与者正常通信,参与者依然会进行事务提交,造成数据不一致。
1.3.3 Paxos和Raft
Paxos算法属于多数派算法,主要解决数据分片的单点问题,目的是让整个集群对某个值的变更达成一致。集群中的任何一个节点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的节点同意,所以Paxos算法建议集群中的节点为奇数。
Raft算法是简化版的Paxos, Raft划分成三个子问题:一是Leader Election;二是Log Replication;三是Safety。Raft 定义了三种角色Leader、Follower、Candidate,开始大家都是Follower,当Follower监听不到Leader,就可以自己成为Candidate,发起投票,选出新的leader。
1.3.4 1PC一阶段提交
1PC协议阶段就是从应用程序向数据库发出提交请求到数据库完成提交或回滚之后,将结果返回给应用程序的过程。一阶段提交不需要“协调者”角色,各结点之间不存在协调操作,因此其事务执行时间比两阶段提交要短,但是提交的“危险期”是每一个事务的实际提交时间,相比于两阶段提交,一阶段提交出现在“不一致”的概率就变大了。
在分布式系统中如果存在跨分片的分布式事务,1PC提交并不能保证数据的一致性。像GoldenDB分布式数据库就是通过1PC协议+全局活跃事务ID(GTID)来实现分布式事务,在接下去的章节中将会详细介绍。
2、GoldenDB中分布式事务实现
2.1 隔离级别
1)事务隔离级别

不同的隔离级别有不同的现象,并有不同的锁和并发机制。隔离级别越高,数据库的并发性能就越差。
2)GoldenDB中事务隔离级别
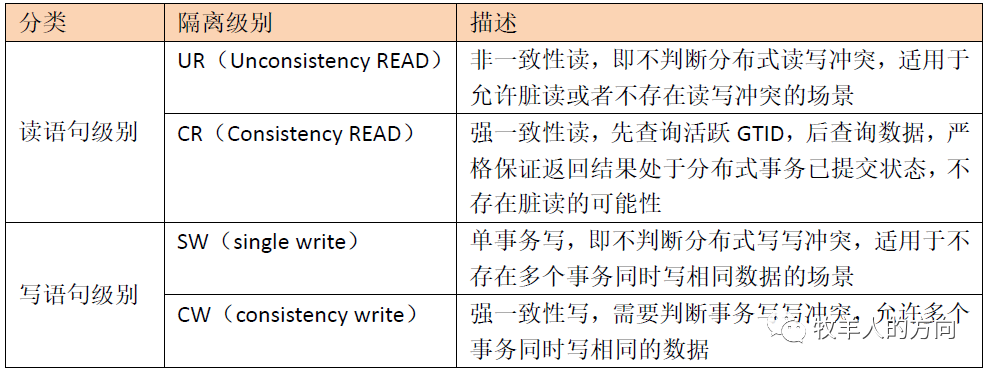
事务执行的时候会先经过计算节点根据隔离级别判断并改写语句,然后下发到数据节点执行,具体见以下相关内容的介绍。
2.2 分布式事务的难点
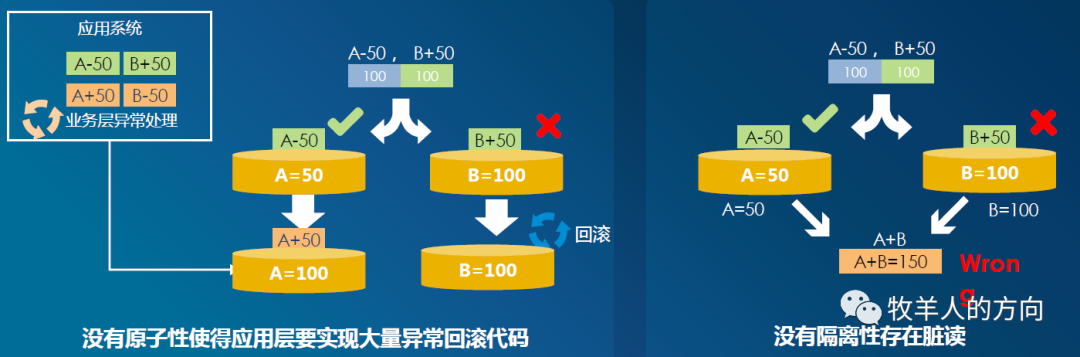
部分DB提交失败,如何保证全局事务的原子性
并发访问时,每个事务都不知道其它事务的状态,如何保证事务之间的隔离性
当有部分DB提交成功,部分DB提交失败时,如何保证回滚期间的隔离性
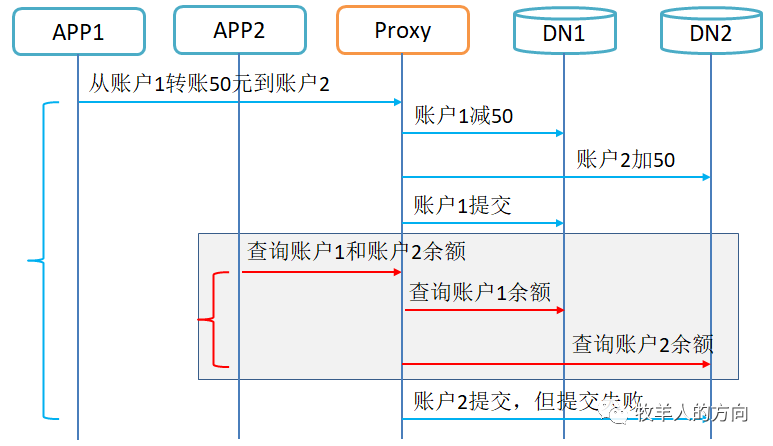
交易前账户1和账户2余额为100元,事务T1从账户1转账50到账户2
在事务T1提交期间,事务T2读取2个账户的余额,发现两个余额之和是50+100=150元。因为事务之间的隔离性问题产生数据读不一致
可能存在事务T1对账户T1扣钱成功,但是给账户2加钱失败的情况。因为事务内部的原子性问题产生数据写不一致
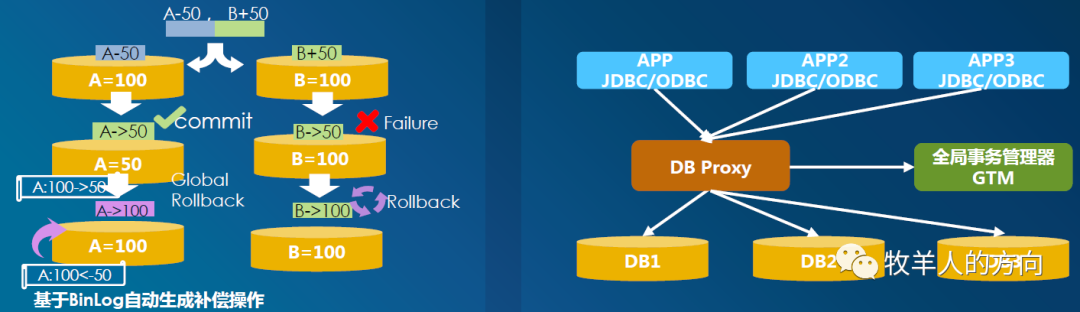
2.3 事务原子性
各分片直接提交:各分片并行在本地执行子事务,并在本地各自记录子事务日志。当每个分片都完成后,提交事务全局状态
自动补偿机制:某个分片执行失败,其它分片会反向解析本地binlog日志,将数据还原到执行前的状态
对于未提交的子事务,单节点数据库自身会进行回滚;而对于已经提交的子事务,会基于binlog日志自动补偿回滚。这样在应用层无需实现补偿逻辑,而失败回滚是少数情况,整体性能较高。
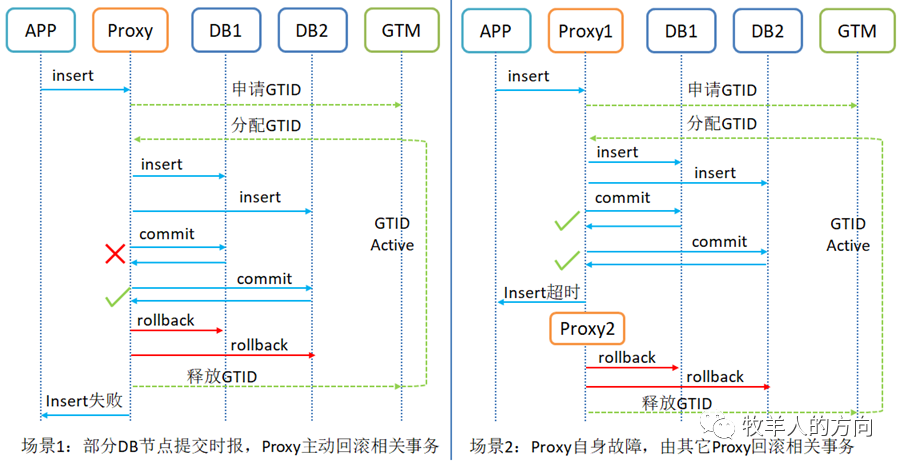
2.3.1 异常事务原子性流程
2.3.2 ROLLBACK流程
在SQL执行阶段,当部分数据节点的SQL执行失败、执行超时或者计算节点异常,此时需要业务根据SQL的执行结果选择rollback或者选择其它分支继续执行其它SQL
在事务提交阶段,当部分数据节点的SQL执行失败、执行超时或者计算节点异常,需要在已经提交的DB上进行已提交事务的回滚
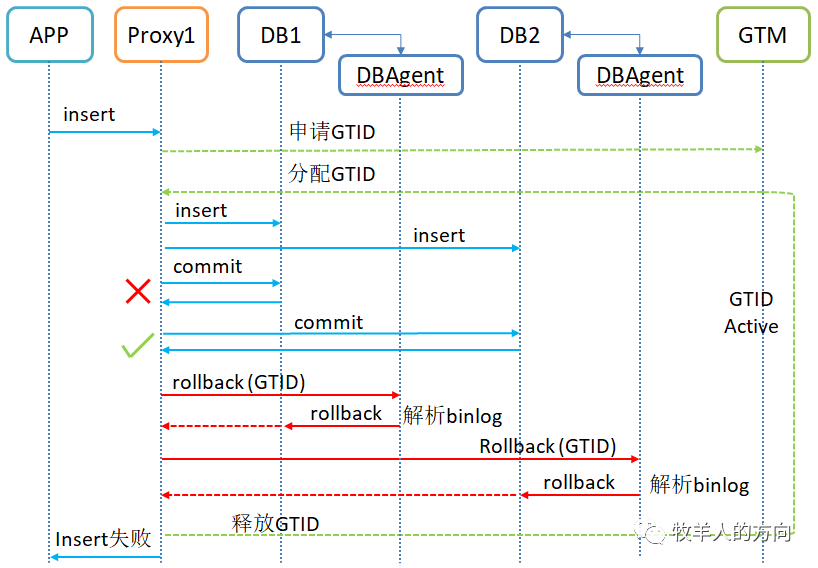
DBProxy将GTID发送给DB节点上部署的事务回滚组件DBagent
DBAgent解析该事务的Binlog,然后对数据进行回滚
当所有DB分片回滚完成后,再释放GTID
定位:根据GTID相关信息定位要进行分析binlog日志文件的列表
遍历:遍历binlog日志文件,找到GTID对应的事务日志块
生成:分析日志块,为事务中每条SQL语句生成反向的SQL语句
执行:将所有反向SQL语句逆序执行,并保证在一个事务中
在GoldenDB中还会利用binlog预分析、表定义缓存、key值利用等技术手段提升回滚性能。
2.4 事务隔离性
分布式事务更新:分布式事务更新数据时,Proxy会从GTM申请GTID,同时改写SQL语句,将申请的GTID更新到数据行中
分布式一致性读过程:当事务隔离级别为cr时,查询事务会通过proxy查询GTID中当前的活跃事务列表,并进行活跃状态校验,如果该数据正在被修改则不会返回。
1)实时一致性事务的处理
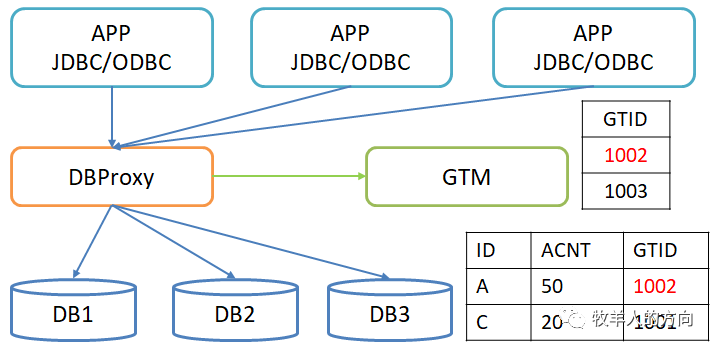
事务开始时申请GTID,事务结束时释放GTID,所有活跃事务由GTM统一管理,称为活跃事务列表
建表时会在表上自动增加GTID列(对应用不可见),更新数据行时同时会更新GTID列。如果数据行的GTID在活跃事务列表中,表明该数据正在被其它事务修改
proxy计算节点会对事务的SQL语句进行修改,将GTID加入到语句中下推到数据节点
GTID单调递增
2)分布式事务更新流程
insert into t1 values(1,’aa’),(2,’bb’);语句会改写为insert into t1 values(1,’aa’,gtid_no),(2,’bb’,gtid_no);
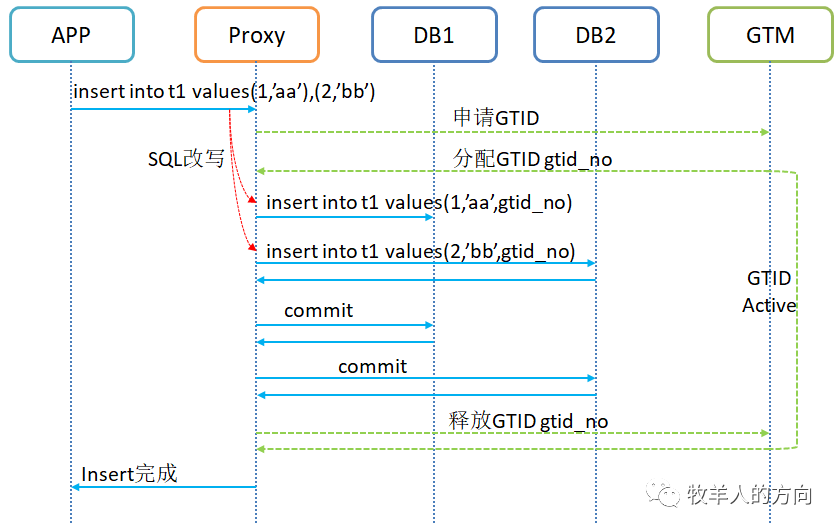
事务一旦提交,GTID就会与数据一起写到DB的binlog日志文件中。
2.4.1 一致性读
当proxy隔离级别定义为cr时候,查询数据时,通过检查数据行GTID列对应的全局状态,来判断该数据行是否正在被其它全局事务修改。如果GTID在全局活跃事务列表中,则表明该数据正在被修改,不能返回给应用。在一致性读的过程中,如果事务已提交即GTID不在活跃事务列表中,则返回的是已提交的数据;如果事务未提交,即GTID在活跃事务列表中,则返回的是事务提交之前的数据,这样即满足了隔离性要求。
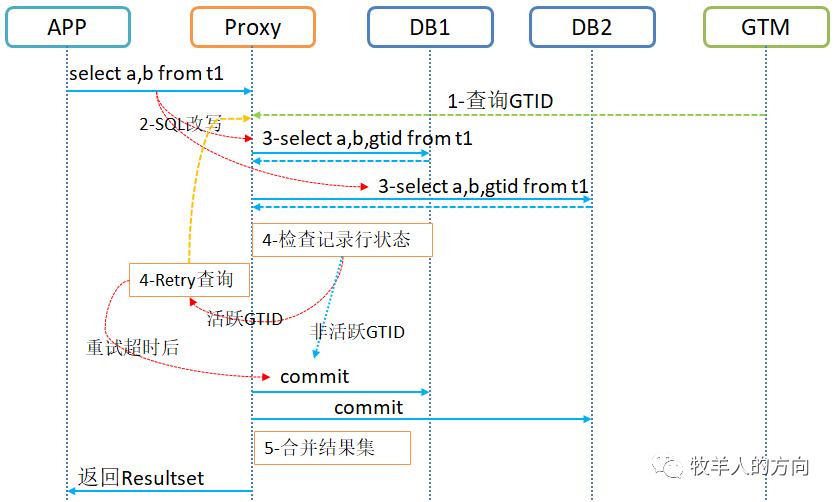
向GTM请求查询当前的活跃事务列表
DBProxy将查询的SQL进行改写
原语句select a,b from t1 where改写为select a,b,gtid from t1 where
将改写后的SQL下发到数据节点进行查询
DBproxy根据查询后的表数据行的GTID和GTM查询的GTID进行活跃判断,如果GTID不在活跃事务列表中,则合并结果集返回给应用;如果在GTID活跃事务列表中,会进行尝试重新查询活跃事务列表GTID进行判断,超过重试次数后也会返回结果集,不过返回的是更新前的数据
由于数据节点的隔离级别为rc模式,下发到数据节点的SQL语句返回的是事务更新提交之前的数据
在dbproxy节点进行GTID判活及retry的时候,会有短暂的阻塞读的情况,时间会很短,大概是ms级别
备注:在一致性读过程中,先获取活跃事务列表,再去查询数据行,是因为如果先查询数据行,当查询期间其它事务正在修改数据并且在获取事务列表之前提交了,仍然会返回这些事务未提交的数据。同时要结合GTID单调递增的特性,来判断是否存在活跃事务列表之外更大的活跃事务,也就是看数据行中的GTID是不是比GTM查到的大活跃事务列表还大。
2.4.2 MVCC模式下的一致性读
DB节点使用proxy上收到的active_gtm_gtid_list进行数据活跃判断
如果当前数据行上的GTID判断不活跃,直接返回数据
如果当前数据行上的GTID判断活跃,则通过undo构造全局的镜像数据

DBproxy向GTM请求当前的活跃事务列表
DBProxy将原SQL进行改写,即将活跃事务列表下推到数据节点
将select a,b from t1 where改写为select /*+SET_VAR(active_gtm_gtid_list=活跃事务列表的BASE64编码) SET_VAR(next_gtm_gtid=ulonglong变量)*/ a,b,gtid from t1 where
将改写后的SQL语句和GTID活跃事务列表下发到数据节点
在计算节点判断对应的GTID是否全局可见
如果GTID不活跃,则直接返回数据;如果GTID活跃,则通过undo数据构造全局的前项数据返回
DBproxy将结果集汇总后返回给应用
MVCC模式下的一致性读的好处是通过MVCC多版本并发控制,能够保证读一致性,并且写不阻塞读。同时将GTID的活跃判断检测下推到了数据节点,避免了计算节点获取所有结果集进行活跃判断而导致的Proxy内存开销增大的风险。但是目前GoldenDB的MVCC功能没有经过测试验证,功能和性能上的效果如何有待进一步测试。
2.4.3 一致性写
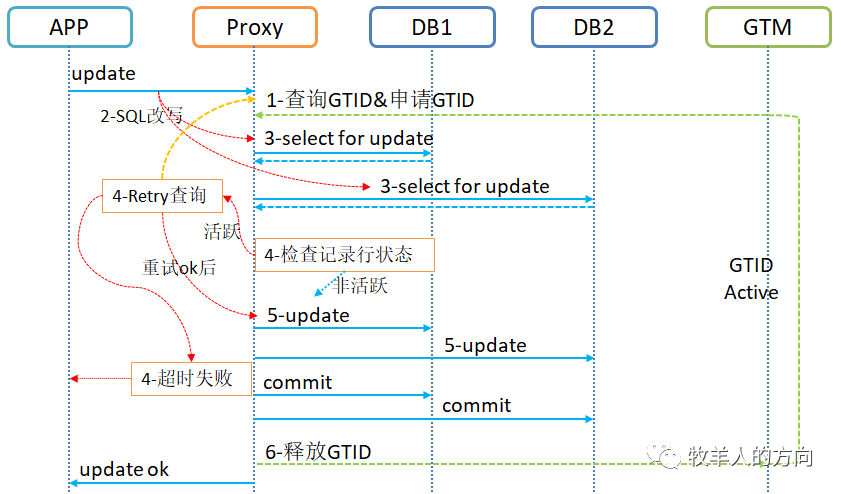
DBProxy计算节点请求活跃事务列表GTID,同时请求创建GTID
DBproxy将update更新语句进行改写
将update set a=’xxx’改写为select pkey,gtid from t1 for update和update t1 set a=’xxx’,gtid=gtid_no
将select for update语句下发到数据节点,并返回结果,select for update会申请加锁,如果出现等锁超时则直接失败
DBProxy对返回的结果进行GTID活跃检查,如果是非活跃GTID,则可以直接下发update语句;如果是活跃GTID,则尝试重新查询活跃GTID列表,检查OK后可以继续update,如果超时则失败
GTID活跃检查OK以后,将update语句下发到数据节点执行,update语句会更新gtid字段,当前时段该数据行的记录是被该事务更新,GTID为活跃状态
所有节点更新完成并提交后,是否GTID
DBProxy再将事务处理的结果返回给应用端
总结GoldenDB中的分布式事务,为了解决分布式数据库中事务的原子性和隔离性问题,引入了binlog自动补偿机制以保证原子性、GTM全局事务管理器以保证事务的隔离性,实现一致性读和一致性写。接下去中,GTM的性能如何保证,MVCC功能下的稳定性和性能,DB故障、DBProxy故障和GTM时候分布式事务的处理机制等,都是分布式事务使用过程中需要考虑的问题。
参考资料:
https://lavorange.blog.csdn.net/article/details/52489998
https://blog.csdn.net/w372426096/article/details/80437198
https://blog.csdn.net/KingCat666/article/details/78296107
https://www.cnblogs.com/winter0730/p/14679768.html
“GoldenDB分布式事务强一致性原理及实践”,墨天轮技术分享
