大家好!我是木荣。
今天给大家聊一聊Linux中文本操作的三剑客:awk、grep、sed,因其功能强大、使用频繁,且是Linux下文本处理的得力利器,常被称之为文本三剑客。grep常用于查找,sed常用于取行和替换,而awk常用于运算。
有句玩笑话常说:做Linux技术不识三剑客,玩遍Linux也枉然,虽然是玩笑语,但也不得不说他们的重要性。
为什么聊起这个话题呢?
近这几天有点忙,可能是快到了毕业季了,近来公司的面试的应届生突然多了起来。在对应届生的面试过程中,往往会涉及一些基本的技术知识,主要看重的是对基础知识的掌握和对新知识的学习能力。而Linux下常用的基本命令
awk、grep、sed也是常常被问及,来反映对Linux操作熟悉的程度。
问题:如何在Linux下查找包含某个函数的文件及所在的行?
熟悉Linux操作的肯定会说so easy! 此处先不给出具体答案,我们详细介绍一下
三剑客命令,如果不知道,看完后你肯定会知道答案!
1、grep命令
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。它是Linux系统中一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
shell脚本中也经常使用grep,因为grep通过返回一个状态值来说明搜索的结果。如果搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
grep家族包括grep、egrep和fgrep。egrep和fgrep的命令跟grep区别不大。egrep是grep的扩展,支持更多的re元字符,fgrep是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示其自身的字面意义。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
格式:grep [option] pattern file
参数
-a 不要忽略二进制数据。
-A <显示行数> 除了显示符合范本样式的行之外,并显示该行之后的指定几行内容。
-B<显示行数> 除了显示符合范本样式的行之外,并显示该行之前的指定几行内容。
-C<显示行数> 除了显示符合范本样式的那一行之外,并显示该行前后指定几行的内容。
-b 在显示符合范本样式的那一行之外,并显示字节偏移量。-c 只计算显示符合范本样式的行数,不显示详细内容
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着能使用扩展正则表达式。
-f <范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列,标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同,表明查找路径为目录
-s 不显示错误信息。
-v 反转查找,显示不符合模式的所有信息
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
--color=auto 把匹配部分标记出来,要想当前终端后续使用都要标记匹配部分,可用alias命令重新封装grep。
示例:

正则表达式
正则表达式应用广泛,在绝大多数的编程语言都可以应用,在Linux中,也有着很大的用处。使用正则表达式,可以有效的筛选出需要的文本,然后结合相应的支持的工具或语言,完成我们的需求。
格式
.匹配任意单个字符,不能匹配空行
[] 匹配指定范围内的任意单个字符
[^] 取反
[:alnum:] 或 [0-9a-zA-Z]
[:alpha:] 或 [a-zA-Z]
[:upper:] 或 [A-Z]
[:lower:] 或 [a-z]
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 或[0-9]
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意长度的任意字符,不包括0次
? 匹配其前面的字符0 或 1次
+ 匹配其前面的字符至少1次
{n} 匹配前面的字符n次
{m,n} 匹配前面的字符至少m 次,至多n次
{,n} 匹配前面的字符至多n次
{n,} 匹配前面的字符至少n次
我们可以根据grep命令任意组合正则表达式
2、sed命令
主要用来自动编辑一个或多个文件, 简化对文件的反复操作
sed是一种流编辑器,一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容输出。然后读入下行,执行下一个循环。如果没有使诸如‘D’的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i。
格式:sed [options] 'command' file(s) 常用参数:
-n:不输出内容到屏幕,即不自动打印,只打印匹配到的行 -e:多点编辑,对每行处理时,可以有多个Script -f:把Script写到文件当中,在执行sed时-f指定文件路径,如果是多个Script,换行写 -r:支持扩展的正则表达式 -i:直接将处理的结果写入文件 -i.bak:在将处理的结果写入文件之前备份一份
示例:
sed '=' test.txt #显示行号
sed '3=' test.txt #显示第三行行号
sed "/./=" test.txt #只显示非空白行的行号
sed -n "/./!=" test.txt #只显示空白行行号
sed '$=' test.txt #显示总共有多少行
sed -n '2p' test.txt #要加-n,否则会默认自动打印所有内容
sed -n '2 p' test.txt #要加-n,否则会默认自动打印所有内容
# 输出指定行
sed -n '2,7 p' test.txt
sed -n '2,7p' test.txt
sed -n '2,7 {p}' test.txt
#替换文件中内容
sed -i 's/bck/sh/' test.txt test1.txt #替换test.txt、test1.txt内的bck为sh,每行只替换一个
sed -i 's/bck/sh/g' test.txt #替换test.txt内的bck为sh,每行都进行全面替换
sed -i 's/bck/sh/3g' test.txt #替换test.txt内的bck为sh,从第3个匹配位置开始替换
sed -i 's@bck@sh@g' test.txt #替换test.txt内的bck为sh,每行都进行全面替换
sed -i 's#bck#sh#g' test.txt #替换test.txt内的bck为sh,每行都进行全面替换
#显示查找内容的行
sed -n '/sh/p' test.txt #显示test.txt内的所有包含sh的所有行
sed -n '/sh/ ,$ p' test.txt #显示test.txt里条包含sh的行及以下到末尾的所有行
3、awk命令
awk用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk大的优势。awk其实不仅仅是工具软件,还是一种编程语言。
格式:awk [options] 'program' var=value file… awk [options] -f programfile var=value file… awk [options] 'BEGIN{ action;… } pattern{ action;… } END{ action;… }' file ...
常用命令选项
-F fs:fs指定输入分隔符,fs可以是字符串或正则表达式,如-F: -v var=value:赋值一个用户定义变量,将外部变量传递给awk -f scripfile:从脚本文件中读取awk命令
示例:
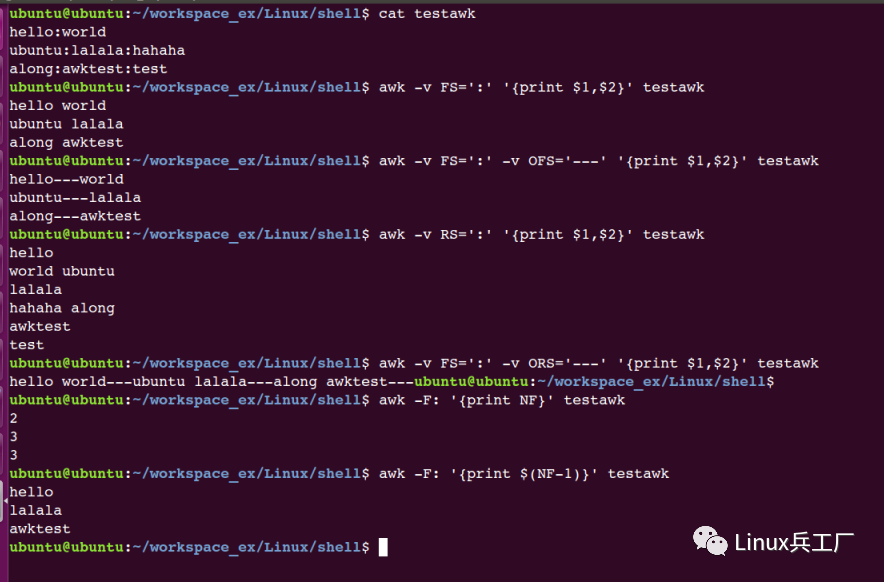
awk -v FS=':' '{print $1,$2}' testawk #FS指定输入分隔符
awk -v FS=':' -v OFS='---' '{print $1,$2}' testawk #OFS指定输出分隔符
awk -v RS=':' '{print $1,$2}' testawk
awk -v FS=':' -v ORS='---' '{print $1,$2}' testawk
awk -F: '{print NF}' testawk
awk -F: '{print $(NF-1)}' testawk #显示倒数第2列
小结
上述三个命令的功能及参数远远不止本文提到的这些,在此只是罗列了一些常用的功能及参数。这三个命令的功能非常强大,用法及参数和功能也非常的多,我们没必要刻意去记忆,也不可能全部记住,记住一些常用的参数及用法即可。只要当我们有需求时知道用哪个命令然后对应的去查找相关参数用法即可。
