
在HBase1.1.0发布之前,HBase同一集群上的用户、表都是平等的,大家平等共用集群资源。容易碰到两个问题:
一是某些业务较其他业务重要,需要在资源有限的情况下优先保证核心重要业务的正常运行
二是有些业务QPS常常很高,占用大量系统资源,导致其他业务无法正常运转。
这是典型的多租户问题。因此,我们需要通过资源隔离来解决多租户问题,同时,需要考虑计算型业务与存储型业务混合部署来提高集群的资源利用率。
1.基本概念
1.1 namespace逻辑隔离
HBase命名空间 namespace 与关系数据库系统中的数据库database类似,方便对表在业务上进行划分,实现逻辑隔离。
Apache HBase从0.98.0, 0.95.2两个版本开始支持namespace级别的授权操作,管理员可以创建、修改和回收namespace的授权。
这种抽象为即将出现的多租户隔离相关功能奠定了基础。
1.2. 配额管理(Quotas)
资源限制,主要针对用户、namespace以及表的QPS和请求大小进行限制。
相关jira见:
https://issues.apache.org/jira/browse/HBASE-8410、https://issues.apache.org/jira/browse/HBASE-11598
一般可以对热点表进行限制,或者在高峰期,对非核心业务表进行限制。
常用语句:
hbase> set_quota TYPE => THROTTLE, TABLE => 't1', LIMIT => '1000req/sec'
hbase> set_quota TYPE => THROTTLE, THROTTLE_TYPE => WRITE, USER => 'u1', LIMIT => '10M/sec'
注意事项:
1)set_quota 的限制都是针对单个region server来说的,并不是针对整个集群,是一种分布式的限制
2)set_quota 默认执行后并不会立刻生效,需要等待一段时间才会生效,等待时间默认为5min。可以通过参数 hbase.quota.refresh.period 进行设置,比如可以通过设置
hbase.quota.refresh.period = 60000将生效时间缩短为1min
3)可以通过命令list_quotas查看当前所有执行的set_quota命令
4)本质上是一种限流手段,无法充分隔离资源
1.3 RS隔离 RegionServer Group
一般情况下,为了保证核心业务的隔离性,会为每个业务搭建一个集群,但是这样可能会导致资源使率过低,比如有些业务重计算轻存储,有些业务重存储轻计算,完全的物理隔离势必带来资源的不协调,有些集群资源过剩,有些集群资源不足。
对此,得益于HBase的共享存储、计算分离的架构,Hbase提供了多租户隔离技术RegionServer Group。
相关jira见:
https://issues.apache.org/jira/browse/HBASE-6721
RegionServer Group 技术是通过对 RegionServer 进行分组,不同的 RegionServer 分到不同的组。每个组可以按需挂载不同的表,并且当组内的表发生异常后,Region 不会迁移到其他的组。这样,每个组就相当于一个逻辑上的子集群,通过这种方式达到存储资源共享、计算资源隔离的效果,提高资源利用率,降低管理成本,不必为每个高 SLA 的业务线单独搭集群。
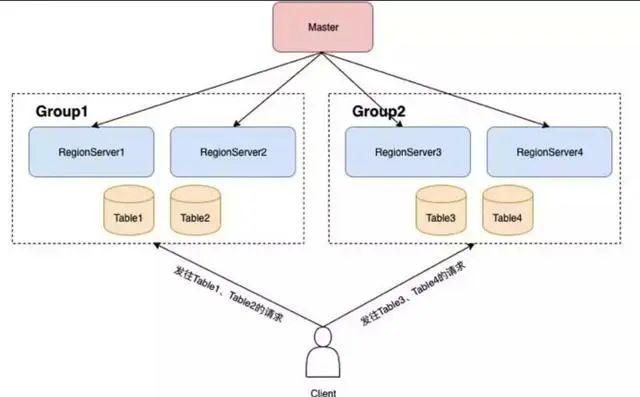
2.多租户核心架构图
下面,我们进一步深入多租户的核心架构图,通过架构图能清晰的看到,资源的隔离和共享情况,某一个租户的RS上哪些操作会对其他租户的资源产生影响,具体影响在哪里,影响大小如何量化。
从上图可以看的,group对region server做了隔离,因此,在计算资源上是物理隔离的。
因此,多租户场景下,相互直接的影响是在共享存储层面的。
在共享存储上,发生相互影响的根本原因在于HDFS的数据三副本写入,如下图所示
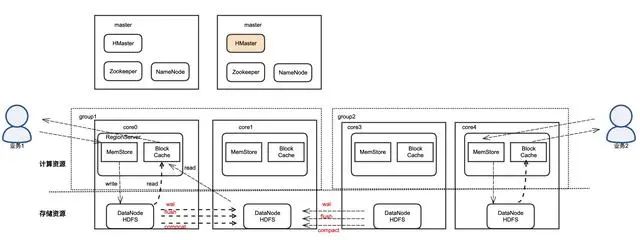
从以上可以看出多租户间可能产生的影响主要来自于其他租户引发的一些写流量,主要包括:
HBase写入产生的WAL同步
MemStore 刷盘导致的数据同步(flush)
StoreFile合并导致的数据同步(MinorCompaction & MajorCompaction)
尤其是大数据量的写入,会对其他group的load造成显著影响
3.容量规划
一个实例(集群)的情况下,压测的结果和性能表现就是该实例(集群)的prod后实际运行的表现,但是针对一个集群多个用户的情况(主要是HBase的存储节点共享),如何来评估容量,分配资源显然更具挑战。
重点解决业务诉求对HBase集群资源的合理科学分配。例如下面这个参考:
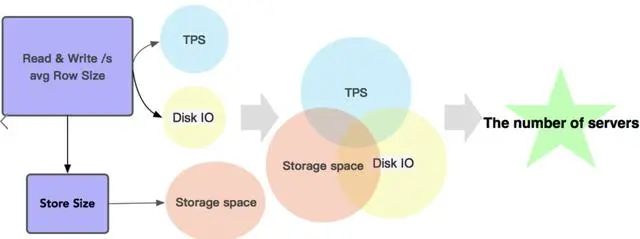
为了方便我们识别某个业务是“存储型”还是“计算型”,我们对当前业务需要的机器做个评估。
定义资源系数m(简化计算,暂时不考虑内存):
m = 核数 * cpu使用率/ (存储容量*容量使用率)
由于我们一般采用8c64g 1788GB(三副本,实际存储为0.6T)作为标准core,根据上文资源系数m的计算公式:
标准core的
m = 8 * 50%%/(0.6*100%%) = 6.67
其中,cpu安全水位为50%%。
如果某个业务的预估m值低于6.67,则认为是存储型,高于6.67则认为是计算型(当然,随着业务的发展,这个偏向可能会发生变化)。
多租户的核心在于提高资源利用率,因此,我们需要将便计算型业务和便存储型业务进行混合部署。
4.告警监控
同集群多租户下的监控告警方案,区别不同集群的监控方案,需要更细粒度的关系映射。
对于多租户集群,采用小租户单位为namespace,记录namespace对应的group name、core-id
1)监控看版
在原本集群监控的基础上,手动记录租户与实例资源的映射关系,然后在目前的看板上进一步筛选core-id进行监控。
2)告警
监控针对core-id进行指标判断,一旦指标到达阈值,根据instanceid、core-id请求hbase-ops获取相关报警联系人
没有按core区分的系统指标只需要instanceid,请求hbase-ops获取该集群所有相关联系人。
5.多租户佳实践
单个集群不能太小,太小没有意义。
单个group内region server也不要太少,至少2个,region server越少,单个region server故障的影响面越大。
如果做了group,那么default的group好空出来,只用来放meta表。
佳模式是按照namespace纬度进行group的划分。
集群中,可以划分一个buffer group,不承担任何流量,如果出现线上的热点,可以临时把这个热点表移动到buffer group上
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
扫描下方二维码可以关注我哦~

