ElasticSearch的性能
下面通过一个es的查询,来展示并行异步代码的实用价值。
下面是真实环境中部署的服务的测试截图:
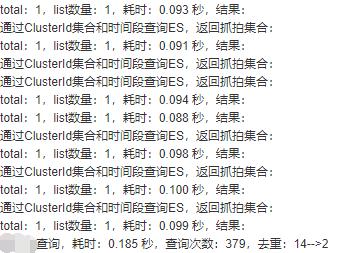
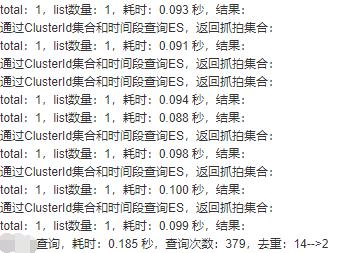
379次es查询,仅需0.185秒(当然耗时会有波动,零点几秒都是正常的)。
es怕的是什么?是慢查询,是条件复杂的大范围模糊查询。
我的策略是多次查询,这样可以利用es极高的吞吐能力。
有多快?
- 上述截图只是其中一个测试,查询分析的时间范围较小(一个多月的数据量)
- 另一个服务接口,分析半年的数据量,大约72亿+18亿=90亿,通过几千次es请求,从这些数据中分析出结果,仅需几秒。
为什么这么快?
- es集群的服务器较多,内存很大(300G,当然服务器上不只有es),集群本身的吞吐量很高。
- 并行异步性能高且吞吐量大!而C#语法糖使得并行异步容易编写。
为什么要使用并行异步?
既然查询次数多,单线程或同步方式肯定是不行的,必须并行查询。
并行代码,python、java也能写。
但前同事写的在双层循环体中多次查询es的python代码,就是同步方式。为什么不并行查询呢?并行肯定可以写,但是能不写就不写,为什么?因为写起来复杂,不好写,不好调试,还容易写出BUG。
重点是什么?不仅要写并行代码,还要写的简单,不破坏代码原有逻辑结构。
普通的异步方法
普通的异步方法大家都会写,用async await就行了,很简单。下面是我自己写的,主要是在双循环中多次异步请求(由于是实际代码,不是Demo,所以代码有点长,可以大致看一下,主要看await xxx是怎样写的):
/// <summary>
/// xxx查询
/// </summary>
public async Task<List<AccompanyInfo>> Query2(string strStartTime, string strEndTime, int kpCountThreshold, int countThreshold, int distanceThreshold, int timeThreshold, List<PeopleCluster> peopleClusterList)
{
List<AccompanyInfo> resultList = new List<AccompanyInfo>();
Stopwatch sw = Stopwatch.StartNew();
//创建字典
Dictionary<string, PeopleCluster> clusterIdPeopleDict = new Dictionary<string, PeopleCluster>();
foreach (PeopleCluster peopleCluster in peopleClusterList)
{
foreach (string clusterId in peopleCluster.ClusterIds)
{
if (!clusterIdPeopleDict.ContainsKey(clusterId))
{
clusterIdPeopleDict.Add(clusterId, peopleCluster);
}
}
}
int queryCount = ;
Dictionary<string, AccompanyInfo> dict = new Dictionary<string, AccompanyInfo>();
foreach (PeopleCluster people1 in peopleClusterList)
{
List<PeopleFeatureInfo> peopleFeatureList = await ServiceFactory.Get<PeopleFeatureQueryService>().Query(strStartTime, strEndTime, people1);
queryCount++;
foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList)
{
DateTime capturedTime = DateTime.ParseExact(peopleFeatureInfo1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture);
string strStartTime2 = capturedTime.AddSeconds(-timeThreshold).ToString("yyyyMMddHHmmss");
string strEndTime2 = capturedTime.AddSeconds(timeThreshold).ToString("yyyyMMddHHmmss");
List<PeopleFeatureInfo> peopleFeatureList2 = await ServiceFactory.Get<PeopleFeatureQueryService>().QueryExcludeSelf(strStartTime2, strEndTime2, people1);
queryCount++;
if (peopleFeatureList2.Count > )
{
foreach (PeopleFeatureInfo peopleFeatureInfo2 in peopleFeatureList2)
{
string key = null;
PeopleCluster people2 = null;
string people2ClusterId = null;
if (clusterIdPeopleDict.ContainsKey(peopleFeatureInfo2.cluster_id.ToString()))
{
people2 = clusterIdPeopleDict[peopleFeatureInfo2.cluster_id.ToString()];
key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2.ClusterIds)}";
}
else
{
people2ClusterId = peopleFeatureInfo2.cluster_id.ToString();
key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2ClusterId)}";
}
double distance = LngLatUtil.CalcDistance(peopleFeatureInfo1.Longitude, peopleFeatureInfo1.Latitude, peopleFeatureInfo2.Longitude, peopleFeatureInfo2.Latitude);
if (distance > distanceThreshold) continue;
AccompanyInfo accompanyInfo;
if (dict.ContainsKey(key))
{
accompanyInfo = dict[key];
}
else
{
accompanyInfo = new AccompanyInfo();
dict.Add(key, accompanyInfo);
}
accompanyInfo.People1 = people1;
if (people2 != null)
{
accompanyInfo.People2 = people2;
}
else
{
accompanyInfo.ClusterId2 = people2ClusterId;
}
AccompanyItem accompanyItem = new AccompanyItem();
accompanyItem.Info1 = peopleFeatureInfo1;
accompanyItem.Info2 = peopleFeatureInfo2;
accompanyInfo.List.Add(accompanyItem);
accompanyInfo.Count++;
resultList.Add(accompanyInfo);
}
}
}
}
resultList = resultList.FindAll(a => (a.People2 != null && a.Count >= kpCountThreshold) || a.Count >= countThreshold);
//去重
int beforeDistinctCount = resultList.Count;
resultList = resultList.DistinctBy(a =>
{
string str1 = string.Join(",", a.People1.ClusterIds);
string str2 = a.People2 != null ? string.Join(",", a.People2.ClusterIds) : string.Empty;
string str3 = a.ClusterId2 ?? string.Empty;
StringBuilder sb = new StringBuilder();
foreach (AccompanyItem item in a.List)
{
var info2 = item.Info2;
sb.Append($"{info2.camera_id},{info2.captured_time},{info2.cluster_id}");
}
return $"{str1}_{str2}_{str3}_{sb}";
}).ToList();
sw.Stop();
string msg = $"xxx查询,耗时:{sw.Elapsed.TotalSeconds:0.000} 秒,查询次数:{queryCount},去重:{beforeDistinctCount}-->{resultList.Count}";
Console.WriteLine(msg);
LogUtil.Info(msg);
return resultList;
}
异步方法的并行化
上述代码逻辑上是没有问题的,但性能上有问题。在双循环中多次请求,虽然用了async await异步,但不是并行,耗时会很长,如何优化?下面是并行异步的写法(由于是实际代码,不是Demo,所以代码有点长,可以大致看一下,主要看tasks1和tasks2怎样组织,怎样await,以及返回值怎么获取):
/// <summary>
/// xxx查询
/// </summary>
public async Task<List<AccompanyInfo>> Query(string strStartTime, string strEndTime, int kpCountThreshold, int countThreshold, int distanceThreshold, int timeThreshold, List<PeopleCluster> peopleClusterList)
{
List<AccompanyInfo> resultList = new List<AccompanyInfo>();
Stopwatch sw = Stopwatch.StartNew();
//创建字典
Dictionary<string, PeopleCluster> clusterIdPeopleDict = new Dictionary<string, PeopleCluster>();
foreach (PeopleCluster peopleCluster in peopleClusterList)
{
foreach (string clusterId in peopleCluster.ClusterIds)
{
if (!clusterIdPeopleDict.ContainsKey(clusterId))
{
clusterIdPeopleDict.Add(clusterId, peopleCluster);
}
}
}
//组织层循环task
Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>> tasks1 = new Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>>();
foreach (PeopleCluster people1 in peopleClusterList)
{
var task1 = ServiceFactory.Get<PeopleFeatureQueryService>().Query(strStartTime, strEndTime, people1);
tasks1.Add(people1, task1);
}
//计算层循环task并缓存结果,组织第二层循环task
Dictionary<string, Task<List<PeopleFeatureInfo>>> tasks2 = new Dictionary<string, Task<List<PeopleFeatureInfo>>>();
Dictionary<PeopleCluster, List<PeopleFeatureInfo>> cache1 = new Dictionary<PeopleCluster, List<PeopleFeatureInfo>>();
foreach (PeopleCluster people1 in peopleClusterList)
{
List<PeopleFeatureInfo> peopleFeatureList = await tasks1[people1];
cache1.Add(people1, peopleFeatureList);
foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList)
{
DateTime capturedTime = DateTime.ParseExact(peopleFeatureInfo1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture);
string strStartTime2 = capturedTime.AddSeconds(-timeThreshold).ToString("yyyyMMddHHmmss");
string strEndTime2 = capturedTime.AddSeconds(timeThreshold).ToString("yyyyMMddHHmmss");
var task2 = ServiceFactory.Get<PeopleFeatureQueryService>().QueryExcludeSelf(strStartTime2, strEndTime2, people1);
string task2Key = $"{strStartTime2}_{strEndTime2}_{string.Join(",", people1.ClusterIds)}";
tasks2.TryAdd(task2Key, task2);
}
}
//读取层循环task缓存结果,计算第二层循环task
Dictionary<string, AccompanyInfo> dict = new Dictionary<string, AccompanyInfo>();
foreach (PeopleCluster people1 in peopleClusterList)
{
List<PeopleFeatureInfo> peopleFeatureList = cache1[people1];
foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList)
{
DateTime capturedTime = DateTime.ParseExact(peopleFeatureInfo1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture);
string strStartTime2 = capturedTime.AddSeconds(-timeThreshold).ToString("yyyyMMddHHmmss");
string strEndTime2 = capturedTime.AddSeconds(timeThreshold).ToString("yyyyMMddHHmmss");
string task2Key = $"{strStartTime2}_{strEndTime2}_{string.Join(",", people1.ClusterIds)}";
List<PeopleFeatureInfo> peopleFeatureList2 = await tasks2[task2Key];
if (peopleFeatureList2.Count > )
{
foreach (PeopleFeatureInfo peopleFeatureInfo2 in peopleFeatureList2)
{
string key = null;
PeopleCluster people2 = null;
string people2ClusterId = null;
if (clusterIdPeopleDict.ContainsKey(peopleFeatureInfo2.cluster_id.ToString()))
{
people2 = clusterIdPeopleDict[peopleFeatureInfo2.cluster_id.ToString()];
key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2.ClusterIds)}";
}
else
{
people2ClusterId = peopleFeatureInfo2.cluster_id.ToString();
key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2ClusterId)}";
}
double distance = LngLatUtil.CalcDistance(peopleFeatureInfo1.Longitude, peopleFeatureInfo1.Latitude, peopleFeatureInfo2.Longitude, peopleFeatureInfo2.Latitude);
if (distance > distanceThreshold) continue;
AccompanyInfo accompanyInfo;
if (dict.ContainsKey(key))
{
accompanyInfo = dict[key];
}
else
{
accompanyInfo = new AccompanyInfo();
dict.Add(key, accompanyInfo);
}
accompanyInfo.People1 = people1;
if (people2 != null)
{
accompanyInfo.People2 = people2;
}
else
{
accompanyInfo.ClusterId2 = people2ClusterId;
}
AccompanyItem accompanyItem = new AccompanyItem();
accompanyItem.Info1 = peopleFeatureInfo1;
accompanyItem.Info2 = peopleFeatureInfo2;
accompanyInfo.List.Add(accompanyItem);
accompanyInfo.Count++;
resultList.Add(accompanyInfo);
}
}
}
}
resultList = resultList.FindAll(a => (a.People2 != null && a.Count >= kpCountThreshold) || a.Count >= countThreshold);
//去重
int beforeDistinctCount = resultList.Count;
resultList = resultList.DistinctBy(a =>
{
string str1 = string.Join(",", a.People1.ClusterIds);
string str2 = a.People2 != null ? string.Join(",", a.People2.ClusterIds) : string.Empty;
string str3 = a.ClusterId2 ?? string.Empty;
StringBuilder sb = new StringBuilder();
foreach (AccompanyItem item in a.List)
{
var info2 = item.Info2;
sb.Append($"{info2.camera_id},{info2.captured_time},{info2.cluster_id}");
}
return $"{str1}_{str2}_{str3}_{sb}";
}).ToList();
//排序
foreach (AccompanyInfo item in resultList)
{
item.List.Sort((a, b) => -string.Compare(a.Info1.captured_time, b.Info1.captured_time));
}
sw.Stop();
string msg = $"xxx查询,耗时:{sw.Elapsed.TotalSeconds:0.000} 秒,查询次数:{tasks1.Count + tasks2.Count},去重:{beforeDistinctCount}-->{resultList.Count}";
Console.WriteLine(msg);
LogUtil.Info(msg);
return resultList;
}
上述代码说明
- 为了使异步并行化,业务逻辑的双层循环要写三遍。第三遍双层循环代码结构和前面所述普通的异步方法中的双层循环代码结构是一样的。
- 、二遍双层循环代码是多出来的。遍只有一层循环。第二遍有两层循环(第三层循环是处理数据和请求无关,这里不讨论)。
- 写的时候,可以先写好普通的异步方法,然后再通过复粘贴修改成并行化的异步方法。当然,脑力好的可以直接写。
为什么说.NET圈的大佬没有写过?
- 我觉得还真没有人这样写过!
- 不吹个牛,博客没人看,没人点赞啊?!
- 厉害的是C#,由于C#语法糖,把的代码写简单了,才是真的。
- 我倒是希望有大佬写个更好的实践,把我这种写法淘汰掉,因为这是我能想到的容易控制的写法了。
- 并行代码,很多人都会写,java、python也能写,但问题是,水平一般的普通的业务程序员,如何无脑地写这种并行代码?
- 差的写法,例如java的CompletableFuture,和复杂的业务逻辑结合起来,写法就很复杂了。
- 其次的写法,也是官方文档上有的,大家都能想到的写法,例如:
List<PeopleFeatureInfo>[] listArray = await Task.WhenAll(tasks2.Values);
在双循环体中,怎么拿结果?肯定能拿,但又要思考怎么写了不是?
而我的写法,在双循环体中是可以直接拿结果的:
List<PeopleFeatureInfo> list = await tasks2[task2Key];
并行代码用Python怎么写?
只放C#代码没有说服力,python代码我不太会写,不过,一个同事python写的很6,他写的数据挖掘代码很多都是并行,例如:
def get_es_multiprocess(index_list, people_list, core_percent, rev_clusterid_idcard_dict):
'''
多进程读取es数据,转为整个数据帧,按时间排序
:return: 规模较大的数据帧
'''
col_list = ["cluster_id", "camera_id", "captured_time"]
pool = Pool(processes=int(mp.cpu_count() * core_percent))
input_list = [(i, people_list, col_list) for i in index_list]
res = pool.map(get_es, input_list)
if not res:
return None
pool.close()
pool.join()
df_all = pd.DataFrame(columns=col_list+['longitude', 'latitude'])
for df in res:
df_all = pd.concat([df_all, df])
# 这里强制转换为字符串!
df_all['cluster_id_'] = df_all['cluster_id'].apply(lambda x: rev_clusterid_idcard_dict[str(x)])
del df_all['cluster_id']
df_all.rename(columns={'cluster_id_': 'cluster_id'}, inplace=True)
df_all.sort_values(by='captured_time', inplace=True)
print('=' * 100)
print('整个数据(聚类前):')
print(df_all.info())
cluster_id_list = [(i, df) for i, df in df_all.groupby(['cluster_id'])]
cluster_id_list_split = [j for j in func(cluster_id_list, 1000000)]
# todo 缩小数据集,用于调试!
data_all = df_all.iloc[:, :]
return data_all, cluster_id_list_split
上述python代码解析
- 核心代码:
res = pool.map(get_es, input_list)
...省略
pool.join()
...省略
核心代码说明:其中get_es是查询es的方法,应该不是异步方法,不过这不是重点
2. res是查询结果,通过并行的方式一次性查出来,放到res中,然后把结果再解出来
3. 注意,这只是单层循环,想想双层循环怎么写
4. pool.join()会阻塞当前线程,失去异步的好处,这个不好
5. 同事注释中写的是"多进程",是写错了吗?实际是多线程?还是多进程?
6. 当然,python是有async await异步写法的,应该不比C#差,只是同事没有使用
7. python代码,字符串太多,字符串是不好维护的。我写的C#代码中的字符串里面都是强类型变量。
把脑力活变成体力活
照葫芦画瓢,把脑力活变成体力活,我又写了一个并行异步方法(业务逻辑依然有点复杂,主要看tasks1和tasks2怎样组织,怎样await,以及返回值怎么获取,注释"比对xxx"下面的代码和并行异步无关,可以略过):
/// <summary>
/// xxx查询
/// </summary>
public async Task<List<SameVehicleInfo>> Query(string strStartTime, string strEndTime, int kpCountThreshold, int timeThreshold, List<PeopleCluster> peopleClusterList)
{
List<SameVehicleInfo> resultList = new List<SameVehicleInfo>();
Stopwatch sw = Stopwatch.StartNew();
//组织层循环task,查xxx
Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>> tasks1 = new Dictionary<PeopleCluster, Task<List<PeopleFeatureInfo>>>();
foreach (PeopleCluster people1 in peopleClusterList)
{
var task1 = ServiceFactory.Get<PeopleFeatureQueryService>().Query(strStartTime, strEndTime, people1);
tasks1.Add(people1, task1);
}
//计算层循环task并缓存结果,组织第二层循环task,搜xxx
Dictionary<string, Task<List<MotorVehicleInfo>>> tasks2 = new Dictionary<string, Task<List<MotorVehicleInfo>>>();
Dictionary<PeopleCluster, List<PeopleFeatureInfo>> cache1 = new Dictionary<PeopleCluster, List<PeopleFeatureInfo>>();
foreach (PeopleCluster people1 in peopleClusterList)
{
List<PeopleFeatureInfo> peopleFeatureList = await tasks1[people1];
cache1.Add(people1, peopleFeatureList);
foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList)
{
string task2Key = $"{peopleFeatureInfo1.camera_id}_{peopleFeatureInfo1.captured_time}";
var task2 = ServiceFactory.Get<MotorVehicleQueryService>().QueryExact(peopleFeatureInfo1.camera_id, peopleFeatureInfo1.captured_time);
tasks2.TryAdd(task2Key, task2);
}
}
//读取层循环task缓存结果,计算第二层循环task
Dictionary<PersonVehicleKey, PersonVehicleInfo> dictPersonVehicle = new Dictionary<PersonVehicleKey, PersonVehicleInfo>();
foreach (PeopleCluster people1 in peopleClusterList)
{
List<PeopleFeatureInfo> peopleFeatureList = cache1[people1];
foreach (PeopleFeatureInfo peopleFeatureInfo1 in peopleFeatureList)
{
string task2Key = $"{peopleFeatureInfo1.camera_id}_{peopleFeatureInfo1.captured_time}";
List<MotorVehicleInfo> motorVehicleList = await tasks2[task2Key];
motorVehicleList = motorVehicleList.DistinctBy(a => a.plate_no).ToList();
foreach (MotorVehicleInfo motorVehicleInfo in motorVehicleList)
{
PersonVehicleKey key = new PersonVehicleKey(people1, motorVehicleInfo.plate_no);
PersonVehicleInfo personVehicleInfo;
if (dictPersonVehicle.ContainsKey(key))
{
personVehicleInfo = dictPersonVehicle[key];
}
else
{
personVehicleInfo = new PersonVehicleInfo()
{
People = people1,
PlateNo = motorVehicleInfo.plate_no,
List = new List<PeopleFeatureInfo>()
};
dictPersonVehicle.Add(key, personVehicleInfo);
}
personVehicleInfo.List.Add(peopleFeatureInfo1);
}
}
}
//比对xxx
List<PersonVehicleKey> keys = dictPersonVehicle.Keys.ToList();
Dictionary<string, SameVehicleInfo> dict = new Dictionary<string, SameVehicleInfo>();
for (int i = ; i < keys.Count - 1; i++)
{
for (int j = i + 1; j < keys.Count; j++)
{
var key1 = keys[i];
var key2 = keys[j];
var personVehicle1 = dictPersonVehicle[key1];
var personVehicle2 = dictPersonVehicle[key2];
if (key1.PlateNo == key2.PlateNo)
{
foreach (PeopleFeatureInfo peopleFeature1 in personVehicle1.List)
{
double minTimeDiff = double.MaxValue;
int minIndex = -1;
for (int k = ; k < personVehicle2.List.Count; k++)
{
PeopleFeatureInfo peopleFeature2 = personVehicle2.List[k];
DateTime capturedTime1 = DateTime.ParseExact(peopleFeature1.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture);
DateTime capturedTime2 = DateTime.ParseExact(peopleFeature2.captured_time, "yyyyMMddHHmmss", CultureInfo.InvariantCulture);
var timeDiff = Math.Abs(capturedTime2.Subtract(capturedTime1).TotalSeconds);
if (timeDiff < minTimeDiff)
{
minTimeDiff = timeDiff;
minIndex = k;
}
}
if (minIndex >= && minTimeDiff <= timeThreshold * 60)
{
PeopleCluster people1 = key1.People;
PeopleCluster people2 = key2.People;
PeopleFeatureInfo peopleFeatureInfo2 = personVehicle2.List[minIndex];
string key = $"{string.Join(",", people1.ClusterIds)}_{string.Join(",", people2.ClusterIds)}"; ;
SameVehicleInfo accompanyInfo;
if (dict.ContainsKey(key))
{
accompanyInfo = dict[key];
}
else
{
accompanyInfo = new SameVehicleInfo();
dict.Add(key, accompanyInfo);
}
accompanyInfo.People1 = people1;
accompanyInfo.People2 = people2;
SameVehicleItem accompanyItem = new SameVehicleItem();
accompanyItem.Info1 = peopleFeature1;
accompanyItem.Info2 = peopleFeatureInfo2;
accompanyInfo.List.Add(accompanyItem);
accompanyInfo.Count++;
resultList.Add(accompanyInfo);
}
}
}
}
}
resultList = resultList.FindAll(a => a.Count >= kpCountThreshold);
//筛选,排除xxx
resultList = resultList.FindAll(a =>
{
if (string.Join(",", a.People1.ClusterIds) == string.Join(",", a.People2.ClusterIds))
{
return false;
}
return true;
});
//去重
int beforeDistinctCount = resultList.Count;
resultList = resultList.DistinctBy(a =>
{
string str1 = string.Join(",", a.People1.ClusterIds);
string str2 = string.Join(",", a.People2.ClusterIds);
StringBuilder sb = new StringBuilder();
foreach (SameVehicleItem item in a.List)
{
var info2 = item.Info2;
sb.Append($"{info2.camera_id},{info2.captured_time},{info2.cluster_id}");
}
return $"{str1}_{str2}_{sb}";
}).ToList();
//排序
foreach (SameVehicleInfo item in resultList)
{
item.List.Sort((a, b) => -string.Compare(a.Info1.captured_time, b.Info1.captured_time));
}
sw.Stop();
string msg = $"xxx查询,耗时:{sw.Elapsed.TotalSeconds:0.000} 秒,查询次数:{tasks1.Count + tasks2.Count},去重:{beforeDistinctCount}-->{resultList.Count}";
Console.WriteLine(msg);
LogUtil.Info(msg);
return resultList;
}
C#的优点
- 有人说:我们开发的低代码平台很。C#:我就是低代码!
- 有人说:我们开发的平台功能很强大,支持写SQL、支持写脚本。C#:我就是脚本语言!
- 有人说:我们用spark、flink分布式。C#:并行异步高性能高吞吐,单机就可以,只要用到的例如kafka和es是集群就行。
