背景

业务飞速发展导致数据规模急速膨胀,单机的数据库已经无法满足互联网业务的发展。
传统的将数据集中存储单一数据结节的方案,在容量、性能、可用性和可维护性方面已经难以满足互联网海量数据的场景。
从容量方面考虑,单机数据库容量有限,难以扩容。
从性能方面来说,由于关系型数据库大多数采用B+树类型索引,在数据量超过一定的阈值后,索引的深度增加导致对磁盘的随机IO次数增加,进而导致性能问题。
从可用性方面来说,服务通常设计成无状态的,这必然导致系统的存储压力都集中在数据库层面,而单一的数据节点,或者简单的主从架构,已经越来越难以承担。
从运维角度来看,当数据都集中在一个节点上时,数据备份和恢复的时间成本也随之数据量上升变得不可控。同时数据丢失导致影响的范围也会被放大。

主从复制

主库将事务操作(除了查询以外的操作)记录到binlog 从库通过relay log同步数据,实现数据的同步

row 记录数据库操作详细记录,包括上线文信息等,文件较大。 statement 记录事务相关的SQL文件。 mixed 混合式, 基于row和statement两种文件格式。
异步复制
2000年,MySQL3.23.15版本引入复制功能,采用异步复制的方式,当网络或者机器故障,会导致数据不一致。

半同步复制
2010年, MySQL 5.5版本引入半同步复制, 半同步复制是指只要一个salve节点返回ack,master节点就可以提交事务了,保证数据库至少有一个节点完成了数据的同步。

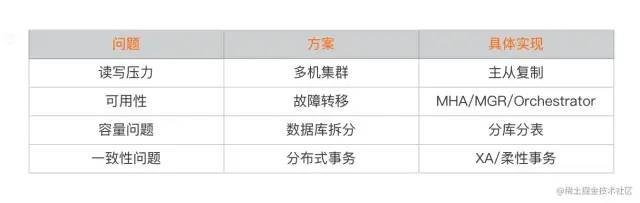
组复制
2016年,MysQL在5.7.17中引入InnoDB Group Replication,该方案基于paxos协议实现组内复制,保证数据一致性,paxos协议核心在于过半选举。
主从复制的问题
主从复制延迟,导致"写完读"数据不一致问题。 从库读取失败,再去主库执行一遍SQL,存在性能问题。 业务层保证系统核心功能可用,将核心功能的CRUD操作都路由到主库,非核心业务功能即使存在短暂数据不一致也影响不大。 路由问题,需要业务层根据SQL路由到不同的数据库,路由到SLAVE节点时,还需要保证系统负载均衡。 业务层通过框架(如sharding-jdbc)或者手动实现,对业务的侵入性较大,已存在的旧系统改造不友好。 通过数据库中间件实现(如mycat、sharding-proxy),需要部署一个中间件(中间件实现SQL标准),规则配置在中间件,执行过程中会多一次网络转发。 不能保证系统高可用 通过一系列高可用的解决方案保证数据库高可用

数据库高可用

什么是高可用?
为什么要做高可用?
容灾恢复:冷备和热备,冷备和热备的区别在于运行期间是否提供服务。 对于主从来说,简单的来说就是Master节点挂了,某一个从节点,自动切换成主。 从集群来看,即便是个别节点挂了,能正常对外提供服务。
多实例部署 跨机房部署 两地三中心容灾高可用方案等。
手动切换
可能数据不一致 需要人工干预 代码和配置的侵入性,需要配置其他节点,修改应用数据源的配置。
MHA
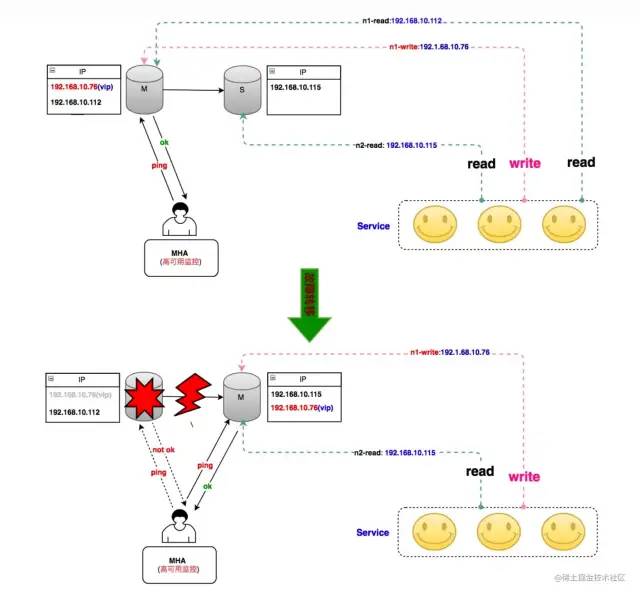
可以进行根据具体的故障实现自动检测和故障转移 扩展性好,可以任意的扩展数据节点数量
极限情况下,可能会发生脑裂现象,出现多个Master。 需要配置SSH信息。 至少需要三台。
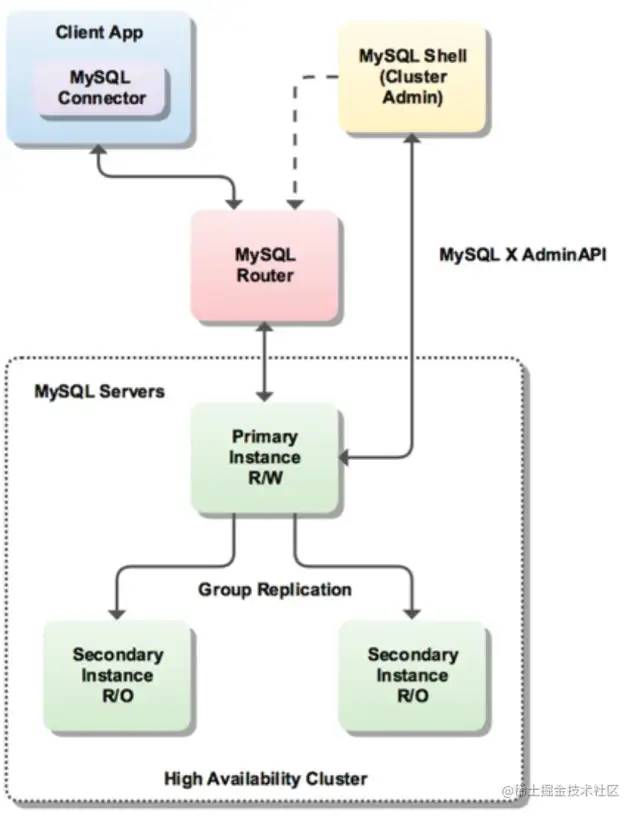
MGR

高一致性,基于分布式Paxos协议实现复制,保证数据一致性。 高容错性,自动检测机制,只要大多数节点都宕机的情况下,数据库可以继续工作,内置防脑裂保护机制。 高可扩展性,加入新节点后,自动实现增量同步,直到与其他节点数据一致。 高灵活性,提供了单主和多主模式,单主模式支持主节点宕机,自动选主,多主模式支持多节点写入。
MySQL Group Replication,提供DB的扩展,故障迁移 MySQL Router,轻量级中间件,提供应用程序连接目标的故障转移。 MySQL shell,新的MySQL客户端,多种接口模式,可以设置群组复制和Router。
Orchestrator
分库分表
垂直分库

分布式事务,跨数据库的事务操作需要分布式事务支持,否则系统将会面临数据不一致的问题。 方案一,采用XA事务,XA事务是数据库本身支持规范,具备强一致性的特征,但是性能比较差,对于追求高性能的场景不适合使用XA事务。 方案二,采用柔性事务,柔性事务是指,数据库保证局部事务,全局事务实现由业务层实现(如通过调度补偿,重试补偿,人工介入等),柔性事务常见的解决方案有:TCC、利用消息队列实现事务。 join问题,分库后,表分散到不同的数据库,无法直接使用SQL进行JOIN操作,需要业务层自己实现聚合操作,增加了开发成本。
水平分表

路由问题,当业务层通过SQL对数据库进行DML操作时,到底该查询那张表呢? 方案一:范围路由。根据表中某一列(分片键)的取值范围进行分表,如根据创建时间将主表分成多张表,每个月的数据单独存储在一个表中。范围路由可能出现数据分配不均匀的现象,但是表数量易于扩展。 方案二:哈希路由。根据表中某一列与分片数量取模运算(field_value % table_num)。hash路由和范围路由相反。表数量扩展时都会导致数据重新分布,但是数据分布较为均匀。 join问题,由于分表后,数据分散到多个表中,JOIN的条件语句中如果没有分片键,那么需要将全部的分片表都JOIN一遍,这种操作会存在性能问题。 count问题,分表后,如果需要统计表记录总和,需要遍历所有的表,然后再将结果进行汇总,可以通过一张单独的汇总表来解决,但这种解决方案需要每次insert或者delete的时候就需要更新汇总表,如果有一次没有更新,就会导致数据不一致。 order by问题,分表后,如果需要进行排序,需要遍历所有的表,然后在代码层进行重新排序,这个操作一看就会存在性能问题。
分库分表解决方案
业务代码层解决,可以通过SQL手动处理路由,但是和业务的耦合很严重,不易于维护。通常采用集成jar包的方式进行解决,如集成成熟的开源项目:sharding-jdbc。 数据库中间件,数据库中间件实现了对应数据库的SQL标准,路由规则配置在数据库中间件,业务代码操作数据库中间件和直接操作数据库没有任何区别。

总结

