下面以电影知识图谱为例进行一次实际操作并进行调用
实验环境
ubuntu 16.04
python 3.5.3
启动gStore
sudo bin/ghttp 9000
如果提示9000端口被占用,那么需要将构建好的进程结束,重新启动。

sudo bin/shutdown 9000
sudo bin/ghttp 9000
注意,在自己构建过程的过程中不要随意进行shutdown可能会丢失数据。
当然,如果很熟练的话可以使用其他端口重新启动新的服务,但是不建议大家这么做,尤其是调用的数据库文件为同一个的情况下。
使用API调用
在这里笔者对帮助文档中报错的部分进行了修改。
import sys
sys.path.append('../src')
import GstoreConnector
IP = "127.0.0.1"
Port = 9000
username = "root"
password = "123456"
sparql = "select ?x where \
{ \
?x <rdf:type> <ub:UndergraduateStudent>. \
}"
filename = "res.txt"
# start a gc with given IP, Port, username and password
gc = GstoreConnector.GstoreConnector(IP, Port, username, password)
# build a database with a RDF graph
res = gc.build("lubm", "data/lubm/lubm.nt")
print(res)
# load the database
res = gc.load("lubm")
print(res);
# query
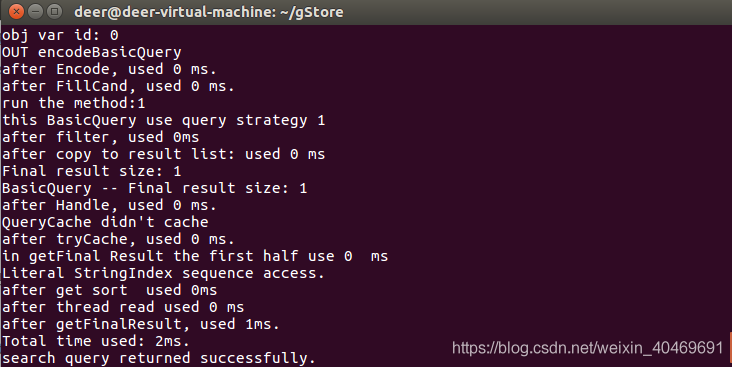
res = gc.query("lubm", "json", sparql)
print(res)
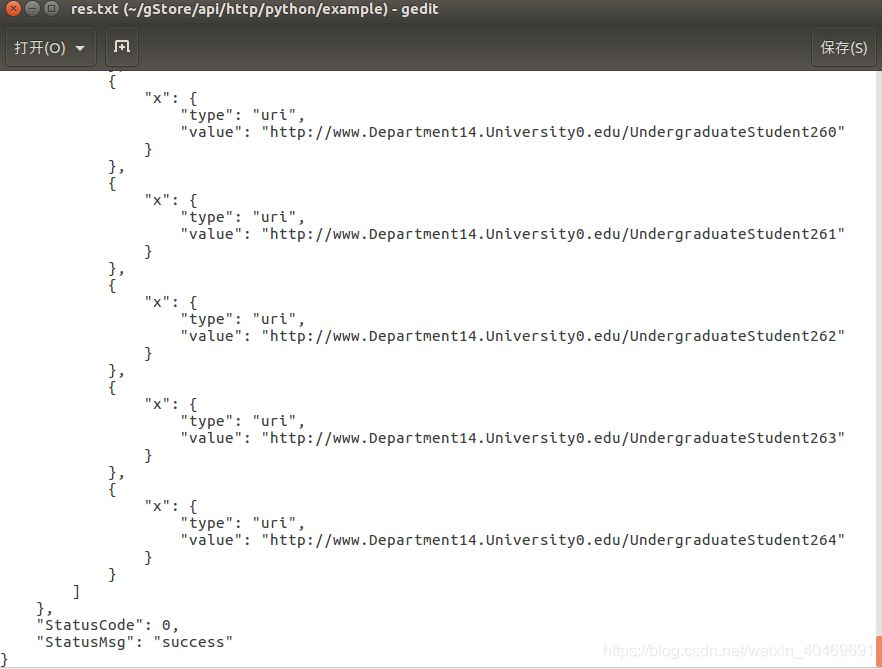
# query and save the result in a file
gc.fquery("lubm", "json", sparql, filename)
# save the database if you have changed the database
res = gc.checkpoint("lubm")
print(res)
# show information of the database
res = gc.monitor("lubm")
print(res)
# show all databases
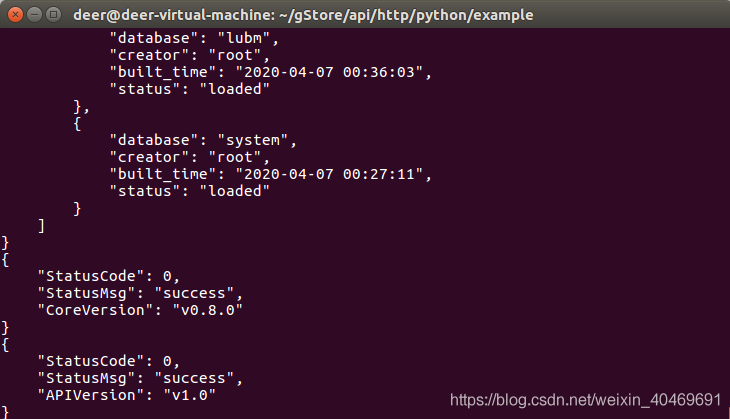
res = gc.show()
print(res)
# get CoreVersion and APIVersion
res = gc.getCoreVersion()
print(res)
res = gc.getAPIVersion()
print(res)
运行结果
总结
对比之间使用的jena个人认为除了界面没有那么美观之外,速度有了明显的提升。而且使用sparql查询语言进行查询,个人不喜欢使用复杂的cypher。同时作为国产数据库管理软件,其安全性能也有保障。
————————————————
版权声明:本文为CSDN博主「ppsuc_deer」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_40469691/article/details/105388600
