❝本文转自田飞雨的博客,原文:https://www.jianshu.com/p/dd7b6b6fe1a0,版权归原作者所有。
cgroups 简介
❝cgroups(是 control groups 的简写)是 Linux 内核的一个功能,用来限制、控制与分离一个进程组的资源(如 CPU、内存、磁盘输入输出等)。
这个项目早是由 Google 的工程师(主要是 Paul Menage 和 Rohit Seth)在 2006 年发起,早的名称为进程容器(process containers)。在 2007 年时,因为在 Linux 内核中,容器(container)这个名词有许多不同的意义,为避免混乱,被重命名为 cgroup,并且被合并到 2.6.24 版的内核中去。自那以后,又添加了很多功能。
设计目标
cgroups 的一个设计目标是为不同的应用情况提供统一的接口,从控制单一进程到操作系统层虚拟化(像 OpenVZ,Linux-VServer,LXC)。cgroups 提供:
资源限制: 组可以被设置不超过设定的内存限制;这也包括虚拟内存。 优先级: 一些组可能会得到大量的 CPU 或磁盘 IO 吞吐量。 结算: 用来度量系统实际用了多少资源。 控制: 冻结组或检查点和重启动。
术语
| 术语 | 描述 |
|---|---|
| task(任务) | 系统中的进程 |
| cgroup(控制组) | cgroups 中的资源控制都以 cgroup 为单位实现。cgroup 表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个 cgroup,也可以从某个 cgroup 迁移到另外一个 cgroup |
| subsystem(子系统) | cgroups 中的 subsystem 就是一个资源调度控制器(Resource Controller)。比如 CPU 子系统可以控制 CPU 时间分配,内存子系统可以限制 cgroup 内存使用量。 |
| hierarchy(层级树) | hierarchy 由一系列 cgroup 以一个树状结构排列而成,每个 hierarchy 通过绑定对应的 subsystem 进行资源调度。hierarchy 中的 cgroup 节点可以包含零或多个子节点,子节点继承父节点的属性。整个系统可以有多个 hierarchy。 |
cgroups 子系统
每个 cgroup 子系统代表一种资源,如针对某个 cgroup 的处理器时间或者 pid[1] 的数量,也叫进程数。Linux 内核提供对以下 12 种 cgroup 子系统的支持:
cpuset- 为 cgroup 内的任务分配独立的处理器和内存节点;cpu- 使用调度程序对 cgroup 内的任务提供 CPU 资源的访问;cpuacct- 生成 cgroup 中所有任务的处理器使用情况报告;io- 限制对 块设备[2] 的读写操作 ;memory- 限制 cgroup 中的一组任务的内存使用 ;devices- 限制 cgroup 中的一组任务访问设备;freezer- 允许 cgroup 中的一组任务挂起 / 恢复;net_cls- 允许对 cgroup 中的任务产生的网络数据包进行标记;net_prio- 针对 cgroup 中的每个网络接口提供一种动态修改网络流量优先级的方法;perf_event- 支持访问 cgroup 中的 性能事件[3];hugetlb- 为 cgroup 开启对 大页内存[4] 的支持 ;pid- 限制 cgroup 中的进程数量。
这里面每一个子系统都需要与内核的其他模块配合来完成资源的控制,比如对 cpu 资源的限制是通过进程调度模块根据 cpu 子系统的配置来完成的;对内存资源的限制则是内存模块根据 memory 子系统的配置来完成的,而对网络数据包的控制则需要 Traffic Control 子系统来配合完成。
本文不会讨论内核是如何使用每一个子系统来实现资源的限制,而是重点放在内核是如何把 cgroups 对资源进行限制的配置有效的组织起来的,和内核如何把 cgroups 配置和进程进行关联的,以及内核是如何通过 cgroups 文件系统把 cgroups 的功能暴露给用户态的。
cpu 子系统
cpu 子系统用于控制 cgroup 中所有进程可以使用的 cpu 时间片。
cpu 子系统主要涉及 5 个参数:cpu.cfs_period_us,cpu.cfs_quota_us,cpu.shares,cpu.rt_period_us,cpu.rt_runtime_us。cfs 表示 Completely Fair Scheduler 完全公平调度器,是 Linux 内核的一部分,负责进程调度。
| 参数 | 说明 |
|---|---|
| cpu.cfs_period_us | 用来设置一个 CFS 调度时间周期长度,默认值是 100000us(100ms),一般 cpu.cfs_period_us 作为系统默认值我们不会去修改它。系统总 CPU 带宽:cpu 核心数 * cfs_period_us |
| cpu.cfs_quota_us | 用来设置在一个 CFS 调度时间周期 (cfs_period_us) 内,允许此控制组执行的时间。默认值为-1 表示限制时间。cfs_quota_us 的小值为 1ms(1000),大值为 1s。通过 cfs_period_us 和 cfs_quota_us 可以以比例限制 cgroup 的 cpu 使用,即 cfs_quota_us/cfs_period_us 等于进程可以利用的 cpu cores,不能超过这个数值。使用 cfs_quota_us/cfs_period_us,例如 20000us/100000us=0.2,表示允许这个控制组使用的 CPU 大是 0.2 个 CPU,即限制使用 20%CPU。如果 cfs_quota_us/cfs_period_us=2,就表示允许控制组使用的 CPU 资源配置是 2 个。 |
| cpu.shares | 用来设置 cpu cgroup 子系统对于控制组之间的 cpu 分配比例。默认值是 1024。cpu.shares 以相对比例限制 cgroup 的 cpu。例如:在两个 cgroup 中都将 cpu.shares 设定为 1024 的任务将有相同的 CPU 时间,但在 cgroup 中将 cpu.shares 设定为 2048 的任务可使用的 CPU 时间是在 cgroup 中将 cpu.shares 设定为 1024 的任务可使用的 CPU 时间的两倍。 |
| cpu.rt_runtime_us | 以微秒(µs,这里以“us”代表)为单位指定在某个时间段中 cgroup 中的任务对 CPU 资源的长连续访问时间。建立这个限制是为了防止一个 cgroup 中的任务独占 CPU 时间。如果 cgroup 中的任务应该可以每 5 秒中可有 4 秒时间访问 CPU 资源,请将 cpu.rt_runtime_us 设定为 4000000,并将 cpu.rt_period_us 设定为 5000000。 |
| cpu.rt_period_us | 以微秒(µs,这里以“us”代表)为单位指定在某个时间段中 cgroup 对 CPU 资源访问重新分配的频率。如果某个 cgroup 中的任务应该每 5 秒钟有 4 秒时间可访问 CPU 资源,则请将 cpu.rt_runtime_us 设定为 4000000,并将 cpu.rt_period_us 设定为 5000000。 |
cpu.cfs_quota_us/cpu.cfs_period_us决定cpu控制组中所有进程所能使用CPU资源的大值,而cpu.shares决定了cpu控制组间可用CPU的相对比例,这个比例只有当主机上的CPU完全被打满时才会起作用。
cpuacct 子系统
cpuacct 子系统(CPU accounting)会自动生成报告来显示 cgroup 中任务所使用的 CPU 资源。报告有两大类:cpuacct.stat 和 cpuacct.usage。
| 参数 | 说明 |
|---|---|
| cpuacct.stat | cpuacct.stat 记录 cgroup 的所有任务(包括其子孙层级中的所有任务)使用的用户和系统 CPU 时间。 |
| cpuacct.usage | cpuacct.usage 记录这个 cgroup 中所有任务(包括其子孙层级中的所有任务)消耗的总 CPU 时间(纳秒)。 |
| cpuacct.usage_percpu | cpuacct.usage_percpu 记录这个 cgroup 中所有任务(包括其子孙层级中的所有任务)在每个 CPU 中消耗的 CPU 时间(以纳秒为单位)。 |
cpuset 子系统
cpuset 主要是为了 numa 使用的,numa 技术将 CPU 划分成不同的 node,每个 node 由多个 CPU 组成,并且有独立的本地内存、I/O 等资源 (硬件上保证)。可以使用 numactl 查看当前系统的 node 信息。
| 参数 | 说明 |
|---|---|
| cpuset.cpus | cpuset.cpus 指定允许这个 cgroup 中任务访问的 CPU。这是一个用逗号分开的列表,格式为 ASCII,使用小横线("-")代表范围。 |
| cpuset.mems | cpuset.mems 指定允许这个 cgroup 中任务可访问的内存节点。这是一个用逗号分开的列表,格式为 ASCII,使用小横线("-")代表范围。 |
memory 子系统
memory 子系统[5]自动生成 cgroup 任务使用内存资源的报告,并限定这些任务所用内存的大小。
| 参数 | 说明 |
|---|---|
| memory.limit_in_bytes | 用来设置用户内存(包括文件缓存)的大用量。如果没有指定单位,则该数值将被解读为字节。但是可以使用后缀代表更大的单位 —— k 或者 K 代表千字节,m 或者 M 代表兆字节 ,g 或者 G 代表千兆字节。您不能使用 memory.limit_in_bytes 限制 root cgroup;您只能对层级中较低的群组应用这些值。在 memory.limit_in_bytes 中写入 -1 可以移除全部已有限制。 |
| memory.memsw.limit_in_bytes | 用来设置内存与 swap 用量之和的大值。如果没有指定单位,则该值将被解读为字节。但是可以使用后缀代表更大的单位 —— k 或者 K 代表千字节,m 或者 M 代表兆字节,g 或者 G 代表千兆字节。您不能使用 memory.memsw.limit_in_bytes 来限制 root cgroup;您只能对层级中较低的群组应用这些值。在 memory.memsw.limit_in_bytes 中写入 -1 可以删除已有限制。 |
| memory.oom_control | 用来设置当控制组中所有进程达到可以使用内存的大值时,也就是发生 OOM(Out of Memory) 时是否触发 linux 的 OOM killer 杀死控制组内的进程。包含一个标志(0 或 1)来开启或者关闭 cgroup 的 OOM killer,默认的配置是开启 OOM killer 的。如果 OOM killer 关闭,那么进程尝试申请的内存超过允许,那么它就会被暂停 (就是 hang 死),直到额外的内存被释放。memory.oom_control 文件也在 under_oom 条目下报告当前 cgroup 的 OOM 状态。如果该 cgroup 缺少内存,则会暂停它里面的任务。under_oom 条目报告值为 1。 |
| memory.usage_in_bytes | 这个参数是只读的,它里面的数值是当前控制组里所有进程实际使用的内存总和,主要是 RSS 内存和 Page Cache 内存的和。准确的内存使用量计算公式(memory.kmem.usage_in_bytes 表示该 memcg 内核内存使用量):memory.usage_in_bytes = memory.stat[rss] + memory.stat[cache] + memory.kmem.usage_in_bytes。 |
| memory.stat | 保存内存相关的统计数据,可以显示在当前控制组里各种内存类型的实际的开销。想要判断容器真实的内存使用量,我们不能用 Memory Cgroup 里的 memory.usage_in_bytes,而需要用 memory.stat 里的 rss 值。 |
| memory.swappiness | 可以控制这个 Memroy Cgroup 控制组下面匿名内存和 page cache 的回收,取值的范围和工作方式和全局的 swappiness 差不多。这里有一个优先顺序,在 Memory Cgorup 的控制组里,如果你设置了 memory.swappiness 参数,它就会覆盖全局的 swappiness,让全局的 swappiness 在这个控制组里不起作用。不同于 /proc 文件系统下全局的 swappiness,当 memory.swappiness = 0 的时候,对匿名页的回收是始终禁止的,也就是始终都不会使用 Swap 空间。因此,我们可以通过 memory.swappiness 参数让需要使用 Swap 空间的容器和不需要 Swap 的容器,同时运行在同一个宿主机上。 |
| memory.memsw.usage_in_bytes | 报告该 cgroup 中进程当前所用的内存量和 swap 空间总和(以字节为单位)。 |
| memory.max_usage_in_bytes | 报告 cgroup 中进程所用的大内存量(以字节为单位)。 |
| memory.memsw.max_usage_in_bytes | 报告该 cgroup 中进程的大内存用量和大 swap 空间用量(以字节为单位)。 |
| memory.failcnt | 报告内存达到 memory.limit_in_bytes 设定的限制值的次数。 |
| memory.memsw.failcnt | 报告内存和 swap 空间总和达到 memory.memsw.limit_in_bytes 设定的限制值的次数。 |
| memory.force_empty | 当设定为 0 时,该 cgroup 中任务所用的所有页面内存都将被清空。这个接口只可在 cgroup 没有任务时使用。如果无法清空内存,请在可能的情况下将其移动到父 cgroup 中。移除 cgroup 前请使用 memory.force_empty 参数以免将废弃的页面缓存移动到它的父 cgroup 中。 |
| memory.use_hierarchy | 包含标签(0 或者 1),它可以设定是否将内存用量计入 cgroup 层级的吞吐量中。如果启用(1),内存子系统会从超过其内存限制的子进程中再生内存。默认情况下(0),子系统不从任务的子进程中再生内存。 |
容器可以通过设置 memory.swappiness 参数来决定是否使用 swap 空间。
cgroups 文件系统
Linux 通过文件的方式,将 cgroups 的功能和配置暴露给用户,这得益于 Linux 的虚拟文件系统(VFS)。VFS 将具体文件系统的细节隐藏起来,给用户态提供一个统一的文件系统 API 接口,cgroups 和 VFS 之间的链接部分,称之为 cgroups 文件系统。
比如挂在 cpu、cpuset、memory 三个子系统到 /cgroups/cpu_mem 目录下:
$ mount -t cgroup -o cpu,cpuset,memory cpu_mem /cgroups/cpu_mem
其中-t 选项指定文件系统类型为 cgroup 类型,-o 指定本次创建的 cgroup 实例与 cpu 和 momory 子系统(或资源)关联,cpu_momory 指定了当前 cgroup 实例在整个 cgroup 树中所处的层级名称,后的路径为文件系统挂载点。
cgroups 驱动
runtime 有两种 cgroup 驱动:一种是 systemd,另外一种是 cgroupfs:
cgroupfs 比较好理解,比如说要限制内存是多少、要用 CPU share 为多少,其实直接把 pid 写入到对应 cgroup task 文件中,然后把对应需要限制的资源也写入相应的 memory cgroup 文件和 CPU 的 cgroup 文件就可以了; 另外一个是 systemd 的 cgroup 驱动,这个驱动是因为 systemd 本身可以提供一个 cgroup 管理方式。所以如果用 systemd 做 cgroup 驱动的话,所有的写 cgroup 操作都必须通过 systemd 的接口来完成,不能手动更改 cgroup 的文件;
kubernetes 中默认 kubelet 的 cgroup 驱动就是 cgroupfs,若要使用 systemd,则必须将 kubelet 以及 runtime 都需要配置为 systemd 驱动。
配置 cgroups 驱动
由于 kubeadm 把 kubelet 视为一个系统服务来管理,所以对基于 kubeadm 的安装, 我们推荐使用 systemd 驱动,不推荐 cgroupfs 驱动。
配置 cgroup 驱动[6]
cgroups 在 K8s 中的应用
kubelet 作为 kubernetes 中的 node agent,所有 cgroup 的操作都由其内部的 containerManager 模块实现,containerManager 会通过 cgroup 将资源使用层层限制:container-> pod-> qos -> node。每一层都抽象出一种资源管理模型,通过这种方式提供了一种稳定的运行环境。如下图所示:
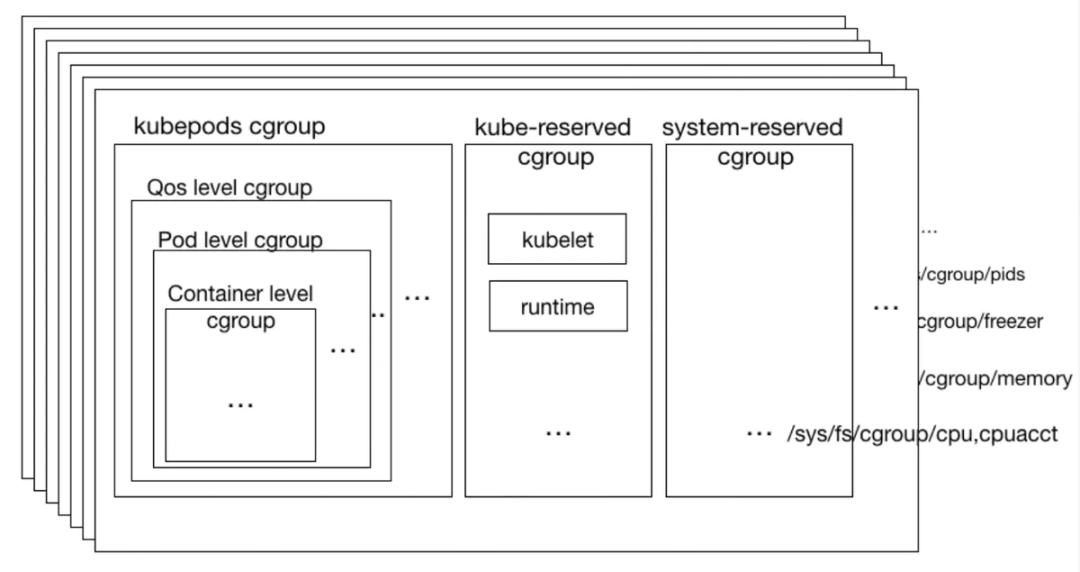
Conainer level cgroups
kubernetes 对于容器级别的隔离其实是交由底层的 runtime 来负责的,例如 docker, 当我们指定运行容器所需要资源的 request 和 limit 时,docker 会为容器设置进程所运行 cgroup 的 cpu.share, cpu.quota, cpu.period, mem.limit 等指标来。
CPU
首先是 CPU 资源,我们先看一下 CPU request。CPU request 是通过 cgroup 中 CPU 子系统中的 cpu.shares 配置来实现的。当你指定了某个容器的 CPU request 值为 x millicores 时,kubernetes 会为这个 container 所在的 cgroup 的 cpu.shares 的值指定为 x * 1024 / 1000。即:
cpu.shares = (cpu in millicores * 1024) / 1000
举个例子,当你的 container 的 CPU request 的值为 1 时,它相当于 1000 millicores,所以此时这个 container 所在的 cgroup 组的 cpu.shares 的值为 1024。
这样做希望达到的终效果就是:即便在极端情况下,即所有在这个物理机上面的 pod 都是 CPU 繁忙型的作业的时候(分配多少 CPU 就会使用多少 CPU),仍旧能够保证这个 container 的能够被分配到 1 个核的 CPU 计算量。其实就是保证这个 container 的对 CPU 资源的低需求。
而针对 CPU limit,Kubernetes 是通过 CPU cgroup 控制模块中的 cpu.cfs_period_us,cpu.cfs_quota_us 两个配置来实现的。kubernetes 会为这个 container cgroup 配置两条信息:
cpu.cfs_period_us = 100000 (i.e. 100ms)
cpu.cfs_quota_us = quota = (cpu in millicores * 100000) / 1000
在 cgroup 的 CPU 子系统中,可以通过这两个配置,严格控制这个 cgroup 中的进程对 CPU 的使用量,保证使用的 CPU 资源不会超过 cfs_quota_us/cfs_period_us,也正好就是我们一开始申请的 limit 值。
对于 cpu 来说,如果没有指定 limit 的话,那么 cfs_quota_us 将会被设置为 -1,即没有限制。而如果 limit 和 request 都没有指定的话,cpu.shares 将会被指定为 2,这个是 cpu.shares 允许指定的小数值了。可见针对这种 pod,kubernetes 只会给他分配少的 CPU 资源。
Memory
针对内存资源,其实 memory request 信息并不会在 container level cgroup 中有体现。kubernetes 终只会根据 memory limit 的值来配置 cgroup 的。
在这里 kubernetes 使用的 memory cgroup 子系统中的 memory.limit_in_bytes 配置来实现的。配置方式如下:
memory.limit_in_bytes = memory limit bytes
memory 子系统中的 memory.limit_in_bytes 配置,可以限制一个 cgroup 中的所有进程可以申请使用的内存的大量,如果超过这个值,那么根据 kubernetes 的默认配置,这个容器会被 OOM killed,容器实例就会发生重启。
对于内存来说,如果没有 limit 的指定的话,memory.limit_in_bytes 将会被指定为一个非常大的值,一般是 2^64 ,可见含义就是不对内存做出限制。
Pod level cgroups
一个 pod 中往往有一个或者有多个容器,但是如果我们将这些容器的资源使用进行简单的加和并不能准确的反应出整个 pod 的资源使用,因为每个 pod 都会有一些 overhead 的资源,例如 sandbox 容器使用的资源,docker 的 containerd-shim 使用的资源,此外如果指定 memory 类型的 volume 时,这部分内存资源也是属于该 pod 占用的。
因为这些资源并不属于某一个特定的容器,我们无法仅仅通过容器的资源使用量简单累加获取到整个 pod 的资源,为了方便统计一个 pod 所使用的资源 (resource accounting),并且合理的将所有使用到的资源都纳入管辖范围内,kubernetes 引入了 pod level Cgroup,会为每个 pod 创建一个 cgroup。
该特性通过指定--cgroups-per-qos=true 开启 , 在 1.6+版本中是默认开启。kubelet 会为每个 pod 创建一个 pod<pod.UID> 的 cgroup,该 cgroup 的资源限制取决于 pod 中容器的资源 request,limit 值。
如果为所有容器都指定了 request 和 limit 值,则 pod cgroups 资源值设置为所有容器的加和,即:
pod<UID>/cpu.shares = sum(pod.spec.containers.resources.requests[cpu])
pod<UID>/cpu.cfs_quota_us = sum(pod.spec.containers.resources.limits[cpu])
pod<UID>/memory.limit_in_bytes = sum(pod.spec.containers.resources.limits[memory])
如果其中某个容器只指定了 request 没有指定 limit 则并不会设置 pod cgroup 的 limit 值, 只设置其 cpu.share 值:
pod<UID>/cpu.shares = sum(pod.spec.containers.resources.requests[cpu])
如果所有容器没有指定 request 和 limit 值,则只设置 pod cgroup 的 cpu.share, 该 pod 在资源空闲的时候可以使用完 node 所有的资源,但是当资源紧张的时候无法获取到任何资源来执行,这也符合低优先级任务的定位:
pod<UID>/cpu.shares = sum(pod.spec.containers.resources.requests[cpu])
其实上面三种设置方式对应的就是三种 QoS pod。这样设置 pod level cgourp 可以确保在合理指定容器资源时能够防止资源的超量使用,如果未指定则可以使用到足够多的可用资源。每次启动 pod 时 kubelet 就会同步对应的 pod level cgroup。
QoS level cgroup
kubernetes 中会将所有的 pod 按照资源 request, limit 设置分为不同的 QoS classes, 从而拥有不同的优先级。QoS(Quality of Service) 即服务质量,QoS 是一种控制机制,它提供了针对不同用户或者不同数据流采用相应不同的优先级,或者是根据应用程序的要求,保证数据流的性能达到一定的水准。kubernetes 中有三种 QoS,分别为:
1、 Guaranteed:pod 的 requests 与 limits 设定的值相等;2、 Burstable:pod requests 小于 limits 的值且不为 0;3、 BestEffort:pod 的 requests 与 limits 均为 0;
三者的优先级如下所示,依次递增:
BestEffort -> Burstable -> Guaranteed
如果指定了 --cgroups-per-qos 也会为每个 QoS 也会对应一个 cgroup,该功能默认开启,这样就可以利用 cgroup 来做一些 QoS 级别的资源统计,必要时也可以通过该 cgroup 限制某个 QoS 级别的 pod 能使用的资源总和。此时每个 QoS cgroup 相当于一个资源 pool, 内部的 pod 可以共用 pool 中的资源,但是对于整个 pool 会进行一些资源的限制,避免在资源紧张时低优先级的 pod 抢占高优先级的 pod 的资源。
对于 guaranteed 级别的 pod,因为 pod 本身已经指定了 request 和 limit,拥有了足够的限制,无需再增加 cgroup 来约束。但是对于 Burstable 和 BestEffort 类型的 pod,因为有的 pod 和容器没有指定资源限制,在极端条件下会无限制的占用资源,所以我们需要分别设置 Burstable 和 BestEffort cgroup, 然后将对应的 pod 都创建在该 cgroup 下。
kubelet 希望尽可能提高资源利用率,让 Burstable 和 BestEffort 类型的 pod 在需要的时候能够使用足够多的空闲资源,所以默认并不会为该 QoS 设置资源的 limit。但是也需要保证当高优先级的 pod 需要使用资源时,低优先级的 pod 能够及时将资源释放出来:对于可压缩的资源例如 CPU, kubelet 会通过 cpu.shares 来控制,当 CPU 资源紧张时通过 cpu.shares 来将资源按照比例分配给各个 QoS pod,保证每个 pod 都能够得到其所申请的资源。
具体来说, 对于 cpu 的设置,besteffort 和 burstable 的资源使用限制如下:
ROOT/besteffort/cpu.shares = 2
ROOT/burstable/cpu.shares = max(sum(Burstable pods cpu requests, 2)
对于不可压缩资源内存,要满足“高优先级 pod 使用资源时及时释放低优先级的 pod 占用的资源”就比较困难了,kubelet 只能通过资源预留的机制,为高优先级的 pod 预留一定的资源,该特性默认关闭,用户可以通过开启 QOSReserved 特征门控(默认关闭),并设置 --qos-reserved 参数来预留的资源比例,例如 --qos-reserved=memory=50% 表示预留 50% 高优先级 request 的资源值,当前只支持 memory, 此时 qos cgroups 的限制如下:
ROOT/burstable/memory.limit_in_bytes =
Node.Allocatable - {(summation of memory requests of `Guaranteed` pods)*(reservePercent / 100)}
ROOT/besteffort/memory.limit_in_bytes =
Node.Allocatable - {(summation of memory requests of all `Guaranteed` and `Burstable` pods)*(reservePercent / 100)}
同时根据 cpu.shares 的背后实现原理,位于不同层级下面的 cgroup,他们看待同样数量的 cpu.shares 配置可能终获得不同的资源量。比如在 Guaranteed 级别的 pod cgroup 里面指定的 cpu.shares=1024,和 burstable 下面的某个 pod cgroup 指定 cpu.shares=1024 可能终获取的 cpu 资源并不完全相同。所以每次创建、删除 pod 都需要根据上述公式动态计算 cgroup 值并进行调整。
此时 kubelet 先会尽力去更新低优先级的 pod,给高优先级的 QoS 预留足够的资源。因为 memory 是不可压缩资源,可能当 pod 启动时,低优先级的 pod 使用的资源已经超过限制了,如果此时直接设置期望的值会导致失败,此时 kubelet 会尽力去设置一个能够设置的小值(即当前 cgroup 使用的资源值),避免资源使用进一步增加。
通过设置 qos 资源预留能够保障高优先级的资源可用性,但是对低优先级的任务可能不太友好,官方默认是关闭该策略,可以根据不同的任务类型合理取舍。
Node level cgroups
对于 node 层面的资源,kubernetes 会将一个 node 上面的资源按照使用对象分为三部分:
业务进程使用的资源, 即 pods 使用的资源; kubernetes 组件使用的资源,例如 kubelet, docker; 系统组件使用的资源,例如 logind, journald 等进程。
通常情况下,我们为提高集群资源利用率,会进行适当超配资源,如果控制不当,业务进程可能会占用完整个 node 的资源,从而使的第二,三部分核心的程序所使用的资源受到压制,从而影响到系统稳定性,为避免这样的情况发生,我们需要合理限制 pods 的资源使用,从而为系统组件等核心程序预留足够的资源,保证即使在极端条件下有充足的资源来使用。
kubelet 会将所有的 pod 都创建一个 kubepods 的 cgroup 下,通过该 cgroup 来限制 node 上运行的 pod 大可以使用的资源。该 cgroup 的资源限制取值为 :
${Node Capacity} - ${kube-reserved} - ${system-reserved}
其中 kube-reserved 是为 kubernetes 组件提供的资源预留,system-reserved 是为系统组件预留的资源,分别通过--kube-reserved,--system-reserved 来指定,例如--kube-reserved=cpu=100m,memory=100Mi。
除了指定预留给系统运行的资源外,如果要限制系统运行的资源,可以通过 --enforce-node-allocatable 来设置,该 flag 指定需要执行限制的资源类型,默认值为 pods,即通过上述 kubepods 来限制 pods 的使用资源,此外还支持限制的资源类型有:
system-reserved:限制 kubernetes 组件的资源使用,如果开启该限制,则需要同时设置--kube-reserved-cgroup 参数指定所作用的 cgroup kube-reserved:限制系统组件的资源使用,如果开启该限制则需要同时设置--system-reserved-cgroup none:不进行任何资源限制
如果需要指定多种类型,通过逗号分割枚举即可,注意如果开启了 system-reserved 和 kube-reserved 的限制,则意味着将限制这些核心组件的资源使用,以上述--kube-reserved=cpu=100m,memory=100Mi 为例,所有的 kubernetes 组件多可以使用 cpu: 100m,memory: 100Mi。
❝除非已经很了解自己的资源使用属性,否则并不建议对这两种资源进行限制,避免核心组件 CPU 饥饿或者内存 OOM。
默认情况下该--enforce-node-allocatable 的值为 pods,即只限制容器使用的资源,但不限制系统进程和 kubernetes 进程的资源使用量。
kubelet 会在资源紧张的时候主动驱逐低优先级的 pod,可以指定 hard-eviction-threshold 来设置阈值,这样一个 node 真正可以为 pod 使用的资源量为:
${Allocatable} = ${Node Capacity} - ${kube-Reserved} - ${system-Reserved} - ${hard-eviction-threshold}
这也是调度器进行调度时所使用的资源值。
核心组件的 Cgroup
除了上述提到的 cgroup 设置外,kubelet 中还有一些对于单个组件的 cgroup 设置, 例如 :
--runtime-cgroups:用来指定 docker 等 runtime 运行的 Cgroup。目前 docker-CRI 的实现 dockershim 会管理该 cgroup 和 oom score, 确保 dockerd 和 docker-containerd 进程是运行在该 cgroup 之内,这里会对内存进行限制,使其大使用宿主机 70% 的内存,主要是为了防止 docker 之前内存泄露的 bug。kubelet 在此处只是不断获取该 cgroup 信息供 kuelet SummarProvider 进行获取统计信息,从而通过 summary api 暴露出去。--system-cgroups:将所有系统进程都移动到该 cgroup 下,会进行统计资源使用。如果不指定该参数则不运行在容器中,对应的 summary stat 数据也不会统计。此处系统进程不包括内核进程, 因为我们并不想限制内核进程的使用。--kubelet-cgroups:如果指定改参数,则 containerManager 会确保 kubelet 在该 cgroup 内运行,同样也会做资源统计,也会调整 OOM score 值。summaryProvider 会定期同步信息,来获取 stat 信息。如果不指定该参数,则 kubelet 会自动地找到 kubelet 所在的 cgroup, 并进行资源的统计。--cgroup-root:kubelet 中所有的 cgroup 层级都会在该 root 路径下,默认是/,root cgroup 可以通过 $ mount | grep cgroup 看到。如果开启--cgroups-per-qos=true,则在 kubelet containerManager 中会调整为/kubepods。
以上 runtime-cgroups,system-cgroups,kubelet-cgoups 的设置都是可选的,如果不进行指定也可以正常运行。但是如果显式指定后就需要与前面提到的--kube-reserved-cgroup 和--system-reserved-cgroup 搭配使用,如果配置不当难以达到预期效果:
如果在--enforce-node-allocatable 参数中指定了 kube-reserved 来限制 kubernetes 组件的资源限制后,kube-reserved-cgroup 的应该是:runtime-cgroups, kubelet-cgoups 的父 cgroup。
只有对应的进程都应该运行该 cgroup 之下,才能进行限制,kubelet 会设置 kube-reserved-cgroup 的资源限制但并不会将这些进程加入到该 cgroup 中,我们要想让该配置生效,就必须让通过制定--runtime-cgroups,--kubelet-cgoups 来将这些进程加入到该 cgroup 中。
同理如果上述--enforce-node-allocatable 参数中指定了 system-reserved 来限制系统进程的资源,则--system-reserved-cgroup 的参数应该与--system-cgroups 参数相同,这样系统进程才会运行到 system-reserved-cgroup 中起到资源限制的作用。
cgroup hierarchy
后整个整个 cgroup hierarchy 如下:
root
|
+- kube-reserved
| |
| +- kubelet (kubelet process)
| |
| +- runtime (docker-engine, containerd...)
|
+- system-reserved (systemd process: logind...)
|
+- kubepods
| |
| +- Pod1
| | |
| | +- Container11 (limit: cpu: 10m, memory: 1Gi)
| | | |
| | | +- cpu.quota: 10m
| | | +- cpu.share: 10m
| | | +- mem.limit: 1Gi
| | |
| | +- Container12 (limit: cpu: 100m, memory: 2Gi)
| | | |
| | | +- cpu.quota: 10m
| | | +- cpu.share: 10m
| | | +- mem.limit: 2Gi
| | |
| | +- cpu.quota: 110m
| | +- cpu.share: 110m
| | +- mem.limit: 3Gi
| |
| +- Pod2
| | +- Container21 (limit: cpu: 20m, memory: 2Gi)
| | | |
| | | +- cpu.quota: 20m
| | | +- cpu.share: 20m
| | | +- mem.limit: 2Gi
| | |
| | +- cpu.quota: 20m
| | +- cpu.share: 20m
| | +- mem.limit: 2Gi
| |
| +- burstable
| | |
| | +- Pod3
| | | |
| | | +- Container31 (limit: cpu: 50m, memory: 2Gi; request: cpu: 20m, memory: 1Gi )
| | | | |
| | | | +- cpu.quota: 50m
| | | | +- cpu.share: 20m
| | | | +- mem.limit: 2Gi
| | | |
| | | +- Container32 (limit: cpu: 100m, memory: 1Gi)
| | | | |
| | | | +- cpu.quota: 100m
| | | | +- cpu.share: 100m
| | | | +- mem.limit: 1Gi
| | | |
| | | +- cpu.quota: 150m
| | | +- cpu.share: 120m
| | | +- mem.limit: 3Gi
| | |
| | +- Pod4
| | | +- Container41 (limit: cpu: 20m, memory: 2Gi; request: cpu: 10m, memory: 1Gi )
| | | | |
| | | | +- cpu.quota: 20m
| | | | +- cpu.share: 10m
| | | | +- mem.limit: 2Gi
| | | |
| | | +- cpu.quota: 20m
| | | +- cpu.share: 10m
| | | +- mem.limit: 2Gi
| | |
| | +- cpu.share: 130m
| | +- mem.limit: $(Allocatable - 5Gi)
| |
| +- besteffort
| | |
| | +- Pod5
| | | |
| | | +- Container6
| | | +- Container7
| | |
| | +- cpu.share: 2
| | +- mem.limit: $(Allocatable - 7Gi)
上述所有的操作在 kubelet 中是通过 containerManager 来实现的, containerManager 启动的时候首先会 setupNode 初始化各种 cgroup,具体包括:
通过 enforceNodeAllocatableCgroups来设置kubepods,kube-reserved,system-reserved三个 cgroup 的资源使用启动 qosContainerManager来定期同步各个 QoS class 的资源使用,会在后台不断同步 kubelet,docker,system cgroup。在每个 pod 启动 / 退出时候会调用 podContainerManager来创建 / 删除 pod 级别的 cgroup 并调用UpdateQoSCgroups来更新 QoS 级别的 cgroup。
上述所有更新 cgroup 的操作都会利用一个 cgroupManager 来实现。
不同 Qos 的本质区别
三种 Qos 在调度和底层表现上都不一样:
在调度时调度器只会根据 request 值进行调度; 当系统 OOM 上时对于处理不同 OOMScore 的进程表现不同,OOMScore 是针对 memory 的,当宿主上 memory 不足时系统会优先 kill 掉 OOMScore 值低的进程,可以使用 $ cat /proc/$PID/oom_score查看进程的 OOMScore。OOMScore 的取值范围为 [-1000, 1000]。
Guaranteed pod 的默认值为 -998Burstable pod 的值为 2~999BestEffort pod 的值为 1000,也就是说当系统 OOM 时,首先会 kill 掉 BestEffort pod 的进程,若系统依然处于 OOM 状态,然后才会 kill 掉 Burstable pod,后是 Guaranteed pod;
Guaranteed Pod Qos 的 cgroup level 会直接创建在 RootCgroup/kubepods 下 Burstable Pod Qos 的创建在 RootCgroup/kubepods/burstable 下 BestEffort Pod Qos 的创建在 RootCgroup/kubepods/BestEffort 下
参考文档
Linux 资源管理之 cgroups 简介[7] kubernetes 中 Qos 的设计与实现[8] Cgroup 中的 CPU 资源控制[9] 重学容器 29: 容器资源限制之限制容器的 CPU[10] 深入解析 kubernetes 资源管理[11]
引用链接
pid: https://links.jianshu.com/go?to=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FProcess_identifier
[2]块设备: https://links.jianshu.com/go?to=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FDevice_file
[3]性能事件: https://links.jianshu.com/go?to=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FPerf_%28Linux%29
[4]大页内存: https://links.jianshu.com/go?to=https%3A%2F%2Fwww.kernel.org%2Fdoc%2FDocumentation%2Fvm%2Fhugetlbpage.txt
[5]memory 子系统: https://links.jianshu.com/go?to=https%3A%2F%2Faccess.redhat.com%2Fdocumentation%2Fzh-cn%2Fred_hat_enterprise_linux%2F7%2Fhtml%2Fresource_management_guide%2Fsec-memory
[6]配置 cgroup 驱动: https://links.jianshu.com/go?to=https%3A%2F%2Fkubernetes.io%2Fzh%2Fdocs%2Ftasks%2Fadminister-cluster%2Fkubeadm%2Fconfigure-cgroup-driver%2F
[7]Linux 资源管理之 cgroups 简介: https://links.jianshu.com/go?to=https%3A%2F%2Ftech.meituan.com%2F2015%2F03%2F31%2Fcgroups.html
[8]kubernetes 中 Qos 的设计与实现: https://links.jianshu.com/go?to=https%3A%2F%2Fblog.tianfeiyu.com%2F2020%2F01%2F21%2Fkubelet_qos%2F
[9]Cgroup 中的 CPU 资源控制: https://links.jianshu.com/go?to=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F346050404
[10]重学容器 29: 容器资源限制之限制容器的 CPU: https://links.jianshu.com/go?to=https%3A%2F%2Fblog.frognew.com%2F2021%2F07%2Frelearning-container-29.html
[11]深入解析 kubernetes 资源管理: https://links.jianshu.com/go?to=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F38359775


