
部门:数据中台
一、前言
随着近几年业务快速发展与迭代,大数据的成本也水涨船高,如何优化成本,建设低成本高效率的底层服务成为了有赞数据基础平台2020年的主旋律。本文主要介绍了随着云原生时代的到来,经历7年发展的有赞离线计算平台如何拥抱云原生,通过容器化改造、弹性伸缩、大数据组件的错峰混部,做到业务成倍增长的情况下成本负增长。
首先介绍一下目前有赞离线计算的一些现状。
万兆网卡的新集群,机器带宽不再是瓶颈。之前我们完成了一次跨云运营商(UCloud -> Qcloud)的集群迁移。而且新集群机型全部都是万兆的网卡(之前老集群还存在部分千兆机型),所以带宽不再是瓶颈。同时 Qcloud 的机型选择更加灵活,机器伸缩也更加方便。 90%以上的离线计算任务使用 Spark 引擎。我们 19 年完成离线任务从 Hive 到 Spark 的迁移,因此在考虑 K8s 容器化时,只针对 Spark 处理。 存储计算混部下的木桶效应。在 YARN 模式下,计算和存储是混部的,当一种资源不足而集群扩容时,势必造成了另一个资源的浪费。我们这边定期扩容的原因总是计算资源先达到瓶颈(虽然一直在对离线任务进行治理和优化),而存储资源相对比较浪费(即使存储之前一直没怎么去优化和治理,比如我们现在数据还是 3 副本的模式,而没有去使用 Erasure Coding 去优化存储效率)
针对现在离线计算的局限性,我们提出了新的方向:
存储计算分离,避免混部下资源的木桶效应。在集群混部的情况下当一种资源不足而需要扩容时,势必造成了另一种资源的浪费。 提升机器利用率。现在很多在线业务的应用都已经 K8s 容器化,如果离线计算也支持 K8s 的话,就可以在线离线混部,充分利用闲时资源。 更好的资源隔离。docker 容器的资源隔离相比 YARN 基于 NodeManager 比较粗粒度的 container 资源监管更加,资源隔离的种类也更加丰富( 目前我们 Hadoop 还处于 2.6.x 的版本,只能做到内存资源的隔离,当然 Hadoop 新版本也开始支持 Docker)。
终我们将 Spark 迁移到 K8s 环境上,本文会主要介绍 Spark 整体迁移到 K8s 环境过程中的改造,优化,踩坑的经验,希望能够帮助到大家。
本文的主要内容包括:
技术方案 Spark 改造 部署优化 踩坑和经验
二、技术方案
从 YARN 环境迁移到 K8s 环境有两个明显需要解决的问题,一是 executor dynamic allocation 能力缺失,二是在存储计算分离之后的 shuffle 和 sort 数据存储问题。针对这两个问题我们做了技术方案,这两个方案也分享给大家。
2.1 Dynamic Allocation
executor 动态分配是一个相对比较有用的功能,它能让各个任务按需的伸缩资源,使集群的资源利用率更高。在 YARN 环境下需要基于 NodeManager 的 external shuffle service 才能开启。而在 K8s 环境下因为没有 external shuffle service 的方案而无法使用,所以我们引入了 SPARK-27963(Allow dynamic allocation without an external shuffle service)来缓解。这个方案是基于跟踪 shuffle 引用,只有在 executor 产生的 shuffle 没有被引用的 executor 才可以被释放,同时 shuffle 引用清理又是基于 spark cleaner 的弱引用清理机制(清理时机依赖于 GC),这种方案释放 executor 的效果相比原来会差很多。
为支持 K8s 上 executor 动态分配的 shuffle service 方案也有下面两种方式,大家可以考虑一下( 据我们调研这两种方式已有一些公司在生产上实践):
enabling shuffle service as a DaemonSet 早期 Spark 2.2 版本的实验功能,将 shuffle service 作为 DaemonSet 部署到 K8s 集群。 缺陷就是需要用到 hostPath volume 来对接宿主机读写 shuffle 数据,跟宿主机绑死了(只能运行在能满足磁盘需求的宿主机上)。 remote storage for persisting shuffle data(SPARK-25299) 目前社区正在实现的方案,但进展比较缓慢,至今还没有全部完成。
近 Uber 开源一个比较完整的 RemoteShuffle 实现。我们这边也在小规模尝试和验证。
2.2 存储卷 (PV) 选择
我们在 YARN 模式下集群使用的是存储能力比较大的大数据机型,有多个大容量的本地机械盘,而计算存储是共用这些本地机械盘。存储计算分离之后就引入了新问题:怎么解决 Spark 计算所需的磁盘需求?
Spark 计算过程中的磁盘需求主要有 shuffle 和 sort 构成。shuffle 部分大家比较清楚,但 sort 往往被忽略,比如在 Spark 内部 sort 场景经常被用到的 UnsafeExternalSorter 。在 executor 内存不足的情况下, UnsafeExternalSorter 就会发生大量 spill 。spill 过程主要是对 IO 读写吞吐需求比较大,对存储容量要求不高。
hostPath
出于降低成本的目的,我们评估了腾讯云提供的各种机型和存储产品,终选择的方案是:计算节点挂载多块云硬盘(块存储 CBS),然后在 Spark Pod 中使用 hostPath 方式来引用宿主机云硬盘的挂载目录。
目前这个方案也有很多不足:
hostPath 方式的缺点很明显,使用了 hostPath 的 Pod 绑定了特定的宿主机。你没办法将 Pod 调度到没有云硬盘挂载目录的宿主机上,这对于同其他应用的混部会有很大的制约。
性能受到单盘 IO 吞吐限制,而又无法充分利用云硬盘的总吞吐。云商提供的云硬盘会有一些 IO 吞吐上限设置,比如单块高性能云硬盘限制大吞吐 150MB/s。因此我们会经常碰到由于 IO 不均匀导致某个云硬盘达到限制瓶颈,而其他盘空闲的情况。
Ceph
为了解决上述问题,我们调研了分布式存储 Ceph。Ceph 有下列优势:
有比较高的读写性能。一方面它支持数据条带化(striping),读写能并行利用多块磁盘;另一方面新的 BuleStore 存储引擎是基于闪存存储介质设计,并在裸盘上构建(绕过了本地文件系统),性能上更加突出。
基于 RADOS 架构核心之上构建了三种存储方案,分别是块存储、文件存储和对象存储,可以满足不同的存储需求。
作为云计算的存储方案有比较多的实践(如 OpenStack),同时也是 K8s 官网支持的 volume plugin 之一。
Ceph 作为 K8s 存储卷 (PV) 时选择哪种存储方案呢 ?
对于一般普通的应用的 Pod,使用 Ceph RBD 是选择,无中心化的架构在稳定性和性能上更具优势。
对于 Spark Pod,Pod 之间又有大量的数据读写交换(shuffle 和 sort),我觉得可以去尝试 Ceph FS。因为它的访问方式支持ReadWriteMany(可被多个节点读写挂载),那么在上面提到的 shuffle service 方案中,就可以有第三种尝试方案:经过存储卷 (PV)挂载之后,Spark Pod 的读写 shuffle 跟本地操作一样,下游 stage 的 task 需要上游 task 产生的 shuffle 数据文件,只需要知道对应的 shuffle 数据文件路径就可以直接转为本地读;当然这里需要基于 Spark ShuffleManager 扩展出新的一种“Local” ShuffleManager。这种方式不需要再引入额外的 shuffle service 模块,总体上算是一个比较有吸引力的解决方向。
Ceph 的优势很多,但复杂性、学习成本、运维难度也比较高。目前 Ceph 方案在有赞大数据还处于测试验证的阶段,我们也在摸索的过程去验证它的可行性。
三、Spark 改造
Apache Spark 从 2.2 版本开始支持 K8s 环境,到 3.0 版本正式支持 K8s。在有赞,我们使用的 Spark 版本是 2.3.3 版本,Spark 还没有正式支持 K8s 环境。为了实现对 K8s 环境的支持,需要对 Spark 做一些修改。
3.1 添加小文件合并功能
数据在流转过程中经历 filter/shuffle 等过程后,开发人员难以评估作业写出的数据量。即使使用了 Spark 提供的 AE 功能,目前也只能控制 shuffle read 阶段的数据量,写出数据的大小实际还会受压缩算法及格式的影响,因此在任务运行时,对分区的数据评估非常困难。
shuffle 分区过多过碎,写入性能会较差且生成的小文件会非常多。 shuffle 分区过少过大,则写入并发度可能会不够,影响任务运行时间。 在产生大量碎片文件后,任务数据读取的速度会变慢(需要寻找读入大量的文件,如果是机械盘更是需要大量的寻址操作),同时会对 HDFS NameNode 内存造成很大的压力。
因此我们添加了合并小文件的操作。小文件校验以及合并流程如下:
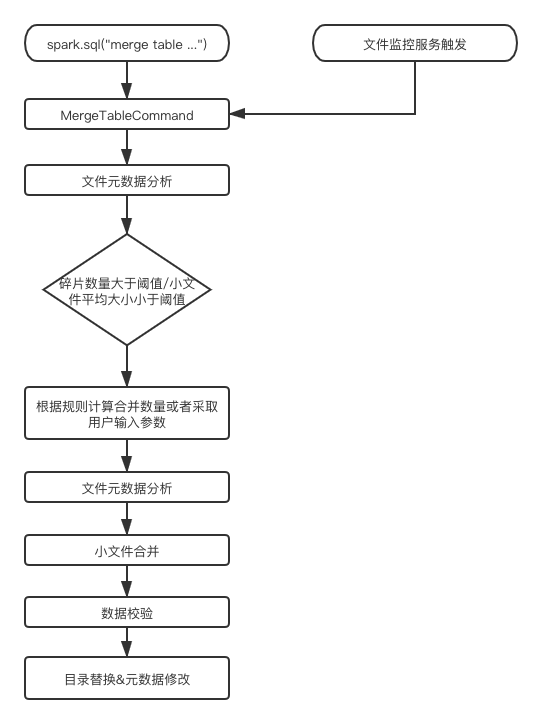
通过添加新的语法,替换掉了现有的 MR 版本的小文件合并。达到缓解 NameNode 的内存压力,提高了下游任务性能的效果。改进点在于,现在小文件合并过程是同步合并的,为了更好的灵活性可以修改成为异步合并的模式。
3.2 日志收集服务
Spark 整体迁移到 K8s 之后,日志会随着 K8s Pod 的释放而被清除掉。会导致在出现任务异常的情况下,日志会随着 executor 的释放而丢失。会给排查线上问题带来不便。
因此我们自己添加了一个新的组件,如上图所示。在 Spark executor container 里面加入新的 Filebeat,通过 Filebeat 将日志数据输出到 Kafka。通过注入环境变量的方式,将 app type , app id , executor Id 三个信息作为 Key,日志行作为内容,发给 Kafka。
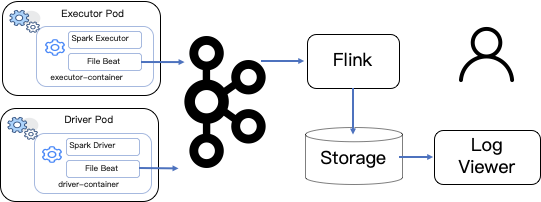
吞吐量控制是通过 Kafka topic partition 的数量和 Flink job 的并发度来实现。Flink job 将 executor 级别日志聚合,保存到存储中,实现了实时,可拓展的日志收集查询服务,解决了 Spark 在 K8s 环境下日志丢失和不能方便的查询日志的问题。同时这个服务也能够提供给公司内部其它在 K8s 环境上运行的组件使用,比如说 Flink 和 Flume 。
3.3 Remote Shuffle Service
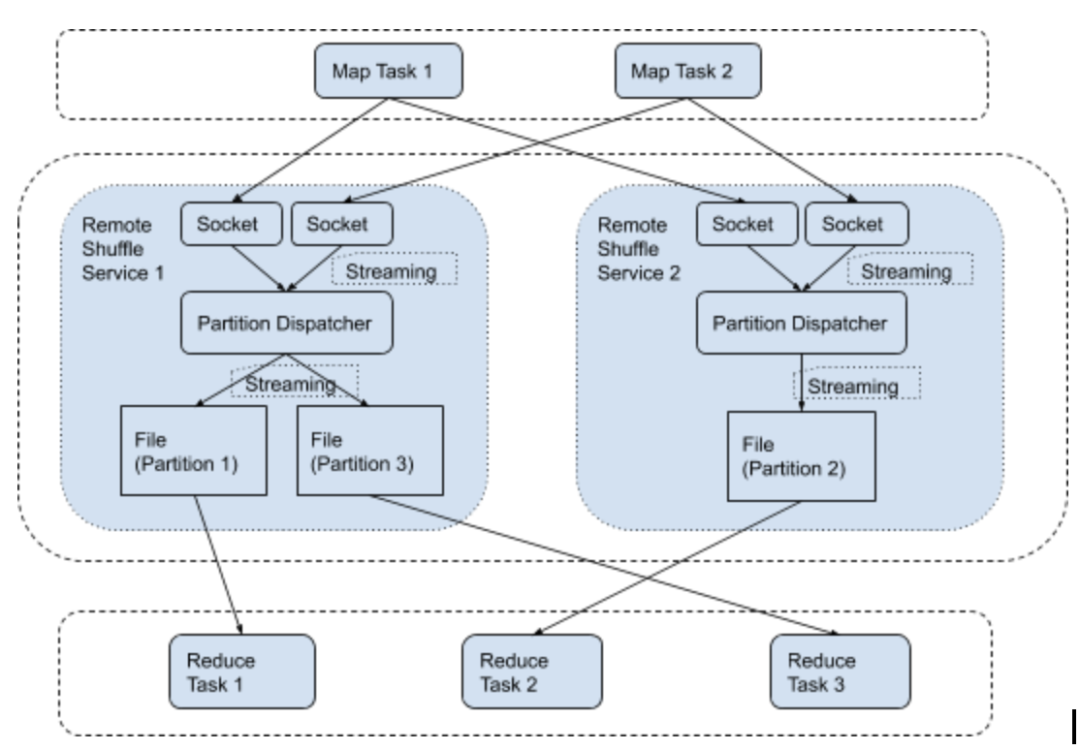
我们这里使用的是 Uber 开源的 remote shuffle service ,同时修改了 Spark 的 executor shuffle 数据记录机制,实现了在使用 remote shuffle service 的情况下,不标记 executor 是否有活跃的 shuffle 数据,实现了在 K8s 环境下 executor 在任务运行完成后迅速释放掉。而不会因为shuffle 数据由 full gc 回收不及时而导致 executor 没有任务的情况下不回收。
同时由于 remote shuffle service 的存在,shuffle 数据的存储离开了 executor pod ,即使在 executor 出现异常的情况下,shuffle 数据还是能够获取到,提高了 Spark SQL 任务的稳定性。
下图是 remote shuffle service 原理图:
3.4 Spark K8s Driver Pod 构建顺序修改
Spark app 启动需要先构建 Driver Pod,如果你不是通过构建镜像,而是通过 configmap 的形式注入配置或者挂载 volume 的形式来启动。对于 spark 系统来说,会先创建 Spark Driver Pod,后创建 configmaps 和 volumes,这会导致 Driver Pod 无法启动,因为 Pod 在创建时需要依赖的 configmaps 和 volumes 必须存在才能够正常创建。所以需要针对这种情况修改为先创建需要的资源,再创建 Driver Pod,后再将两者关联起来。
3.5 添加对本地资源的分发
Spark app 启动过程中,executor 和 driver 都是需要能够访问到资源的。如果使用 K8s 的话,会因为 executor 不能访问到用户代码或者资源文件而任务失败。有两个解决方案可以处理。
方案一:对每一个新的任务把相关的资源文件放到 ${SPARK_HOME}/jars 目录中,优点是处理依赖问题容易,缺点是每次需要打包新的镜像,如果任务很多,需要很多个镜像,会导致 Docker host 磁盘消耗很大。
方案二:修改 spark-submit 代码,将资源文件和各种数据都上传到 HDFS 上,根据特定规则生成目录,然后在 executor 执行中,下载被上传的资源文件,添加到 classpath 里面。
综合考量之后,我们这里采用了方案二,通过 HDFS 系统暂存资源,然后在 executor 中下载资源。
3.6 web ui 暴露
Spark 任务在使用过程中,会有查看 web ui 来查看任务执行状态的需求,在生产环境中,K8s executor Pod 是不能和办公网络环境联通的,所以要使用 ingress 来转发请求。要使用 ingress,需要新建对应的 service,配置需要暴露的端口,就可以实现对办公网络的 web ui 访问。
在 K8s 系统中,service 的访问信息是在集群内部才能生效的,不能在集群外部直接访问。ingress 是 K8s 系统中为不同的 service 设置的负载均衡服务,是 service 的 “service”, 使用 K8s 统一的 ingress 服务可以通过域名的方式将不同的 service 暴露出去。ingress 的优势在于可以屏蔽掉 driver Pod ip 的变化,服务重启或者任务重新调度都会导致 Pod ip 发生变化,ingress 和 service 结合使用,可以实现通过域名访问,而外部用户对具体 Pod ip 的变化无感知。
3.7 Spark Pod label 扩展
默认情况 Spark driver Pod 和 executor Pod 的 nodeSelector 是相同的。如果想实现 driver Pod 被调度到特定的 K8s node 上,executor Pod 调度到其它的 node 上,需要对 Pod 创建过程做修改,使得 executor 和 driver pod 的 nodeSelector 不相同。
这个修改的主要目的是为了适应集群动态扩缩容,driver Pod 如果被驱逐任务会整体重算,计算成本太大,所以 driver Pod 需要调度在不会因缩容而驱逐 Pod 的机器上,executor 可以调度在多种机器上。如下图所示:

3.8 Spark app 状态管理
当用户提交了 Spark app 任务到 K8s 环境时,spark-submit 进程会在申请创建 driver Pod 后立即退出,不会监控driver Pod 的状态,只要 driver Pod 创建成功,spark-submit 进程就会直接返回 0 。Airflow 在调度的时候,是根据命令执行的返回码来判断任务执行是否成功,这样即使任务失败,但是 spark-submit 进程的返回码还是会保持为 0 , Airflow 系统会认为任务执行成功。
为了解决 spark-submit 程序返回值和 driver Pod 运行结果无关问题,需要在 spark-submit 中监听 driver Pod 运行结果,将 driver Pod 的返回值作为 Spark submit 进程的返回值。sssss
当 Airflow 任务需要杀掉一个 spark app 进程时,Airflow 会向 spark-submit 进程发送SIGKILL 命令,能够成功的杀掉 spark-submit 进程,但是不会影响到 K8s 环境中对应的 driver Pod 运行状态,会导致Airflow 停止任务功能失效。这里需要添加新的 shutdown hook ,确保 spark-submit 进程在收到 SIGTERM 命令时,shutdown hook 会将这个任务对应的driver Pod 删除掉。这样就解决了 Airflow 上 Spark app 任务的状态和 spark-submit 进程无关的问题。
3.9 动态修改 dynamicAllocation.maxExecutors
Spark thriftserver 修改 dynamicAllocation.maxExecutors 参数启动后,这个参数在运行过程中是不支持修改的。但是偶尔会遇到业务数据突然增大,或者临时插入了新任务的情况。这时候为了加速离线任务的产出,我们会扩容设备,添加更多的计算资源,在添加了更多的计算资源后,因为是处于业务高峰期内,不能重启服务,就需要能够动态配置 dynamicAllocation.maxExecutors 参数。
四、部署优化
为了节省资源,提高对现有集群的利用率,我们在引入了 K8s 之后,对系统的部署模式也做了较大的优化。
4.1 错峰混部

不同的业务系统会有不同的业务高峰时间,像离线业务系统典型任务高峰期间会是凌晨的 0 点到 9 点钟。而像是 HBase 或者 Druid 提供 BI 展示和查询的系统,常见的业务高峰期是工作日时间,在这个时间以外的其它时间中,可以将其它业务系统的 node 加入到 Spark 所使用的 K8s namespace 中。这样,Spark on K8s 就可以使用其它业务系统的资源。
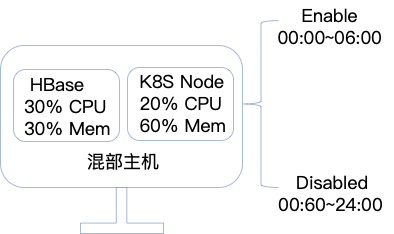
需要预先设置可使用资源,在特定时间范围内将可使用资源的调度打开,结合上文中不同的 Pod label,就可以实现在特定时间内,executor 能够使用混部服务器的资源。在这种情况下,不需要修改操作系统 CPU 优先级调度策略,在其它业务的低峰期间占用服务器资源不会影响到 RT。
下面会有一个业务系统的例子,混部后在线系统的资源利用率得到了明显的提高。下图中描述的是一个在03:00~23:00混部的在线业务系统。能够看到在混部开启时间内,集群无论是CPU还是内存的使用率有了明显的上升。
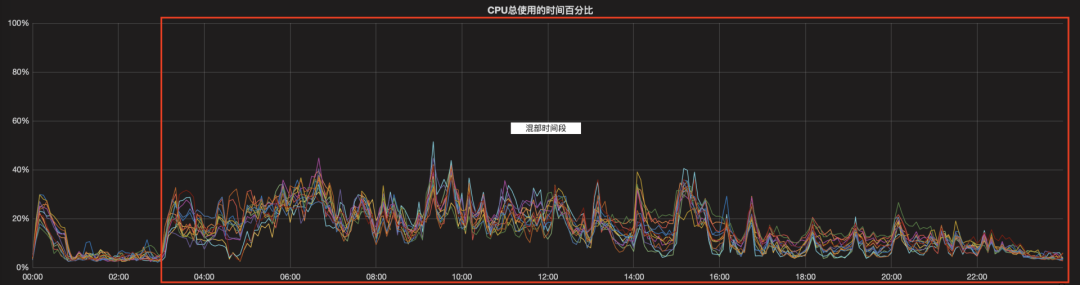

4.2 弹性扩缩容

我们使用的是腾讯云,能够提供 K8s 集群对动态扩容的能力。离线任务在调度上会显示出周期性,如下图展示了离线任务 K8s 队列在高峰期的任务堆积现象。
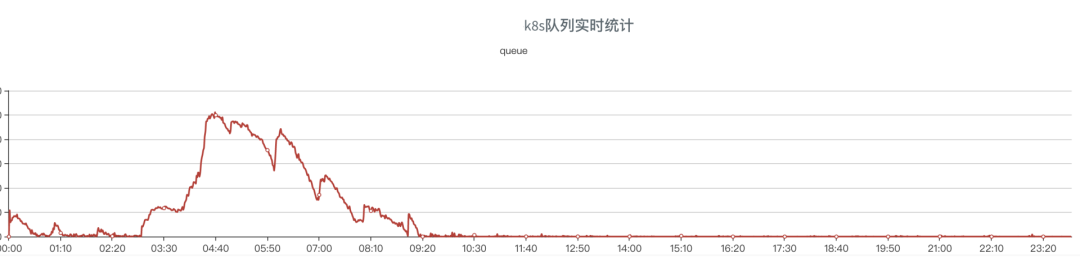
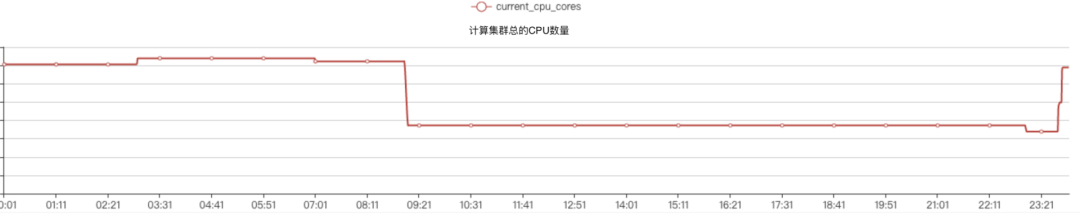
可以很容易的发现,在任务高峰期,0:00~09:00 期间,任务会有堆积的现象。这意味着集群需要更多的计算资源,高峰期过后,集群就不会在有任务堆积等待执行的现象了。这里可以利用 k8s 快速变更集群节点数量的能力,在 00:00~09:00 时间范围内,申请全量的资源来保证离线任务的产出,在 09:00~24:00 之间,释放掉离线集群一半的资源完成日常工作负载。这样可以节省在离线集群低负载时间内的云服务资源的费用,也可以在遇到业务高峰时动态扩容来应对业务高峰。
五、踩坑和经验
在使用 Spark 过程中,我们踩过一些坑,也积累了一些经验。
5.1 K8s 误杀 executor
Docker 的 containerd 存在一个 bug ,现象是 container 里的进程退出后,containerd-shim 不退出,在发生这个 bug 后,Docker 系统会认为 Docker 容器中的进程还在运行中。这导致在某些情况下,Docker 容器会尝试不停的杀掉具有特定 PID 号的进程,在这个过程中,Docker 服务会向特定 PID 发送 KILL 消息。
在同一个节点上,会有其它的 executor 启动,当发生了上文中的异常后,Docker 系统会持续的发送 KILL 给特定的 PID 。新的 Java 进程启动后,工作过程中,可能新创建的 Thread ID 会和上文中的 PID 相同,会接收到 KILL 消息,导致线程异常退出,线程的异常退出会导致 Java 进程也异常退出,引起稳定性问题。
针对这个问题,需要升级到 containerd-shim 没有异常的版本。
5.2 linux 内核参数调优
在 K8s 环境上运行时,executor 需要和 driver 保持网络连接来维持心跳消息,executor 之间在获取 shuffle 数据的情况下,也会需要新的网络连接。这种情况下,会导致某些 executor 的连接数维持在一个比较高的状态。在业务高峰期,偶现如下异常:
...... Successfully created connection to /x.x.x.x:38363 after 0 ms (0 ms spent in bootstraps)
21/01/22 14:25:12,980 WARN [shuffle-client-4-3] TransportChannelHandler: Exception in connection from /10.109.14.86:38363
java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.read0(Native Method)
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:380)
at io.netty.buffer.PooledUnsafeDirectByteBuf.setBytes(PooledUnsafeDirectByteBuf.java:288)
at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:1106)
这个异常和 Linux 操作系统参数有关系。TCP 连接建立后,三次握手的后一次握手后,连接会加入到 accept queue 中,这个队列的计算公式是min(somaxconn,backlog),如果这个队列打满的话,会丢掉连接导致出现上文中的异常。在业务高峰期间,一个 executor 的 shuffle 可能会被数千个 executor 获取,很容易导致部分 executor 的 accept queue被打满。

针对这种情况,需要针对 Linux 内核参数进行调优。操作系统的全连接队列参数保存在 /proc/sys/net/core/somaxconn 中,Spark 中使用的 netty 的全连接队列参数是通过 spark.shuffle.io.backLog 参数配置的,程序运行中实际的队列大小是这两个值中的小值。可以根据具体情况配置的更大一些。
修改了这些配置后,上文中的网络异常几乎没有出现过了。
5.3 executor 丢失,导致任务持续等待
Spark thriftserver 系统在运行过程中,会启动大量的 executor,每个 executor 有各自独立的生命周期。
当一个 executor 失联之后,Spark 系统内会发送一条 executorLost 消息。当系统收到 executorLost 消息之后,KubernetesClusterSchedulerBackend 会开始走 executorDisable 逻辑,这个逻辑会检查 executorsPendingLossReason 队列和 addressToExecutorId 这两个队列。当这两个队列数据有异常的情况,会导致丢失后的 executor 持续存在 ,一直不会被 remove,会进一步导致在这些已经丢失了的 executor 上的 task 不会结束。
所以需要改良这个逻辑,当 executorLost 之后,将逻辑从 disableExecutor 修改为 removeExecutor ,这样就能解决 executor 失联后,任务会直接卡住的问题。
5.4 同一个 executor 多个 task 持续等内存
如果一个 executor 配置多个 cores,就会有多个 task 分配到同一个 executor 上。在 Spark 系统中,内存的分配后是通过 ExecutionMemoryPool 来实现
while (true) {val numActiveTasks = memoryForTask.keys.sizeval curMem = memoryForTask(taskAttemptId) maybeGrowPool(numBytes - memoryFree)val maxPoolSize = computeMaxPoolSize()val maxMemoryPerTask = maxPoolSize / numActiveTasksval minMemoryPerTask = poolSize / (2 * numActiveTasks)val maxToGrant = math.min(numBytes, math.max(, maxMemoryPerTask - curMem))val toGrant = math.min(maxToGrant, memoryFree)if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) { logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free") lock.wait()//cause dead lock } else { memoryForTask(taskAttemptId) += toGrantreturn toGrant }}具体分配内存的代码逻辑如上。可以看到分配内存过程中,会有一个循环,循环过程中,会 wait 直到任务运行完成释放内存才会 notify,这里会导致 Spark 任务在运行过程可能会等待数小时,在任务高峰期会导致任务执行时间不可控。所以需要优化这块逻辑,添加任务分配超时机制,控制任务分配超时时间,当任务超时后,返回获取到的内存数量为 0,让 task 在当前 executor 上失败,从而在其它的 executor 节点上执行。
5.5 shuffle 数据坏块
19/12/10 01:53:53 ERROR executor.Executor: Exception in task 6.0 in stage 0.0 (TID 6)
java.io.IOException:
Stream is corrupted at
net.jpountz.lz4.LZ4BlockInputStream.refill(LZ4BlockInputStream.java:202)
at net.jpountz.lz4.LZ4BlockInputStream.refill(LZ4BlockInputStream.java:228)
at net.jpountz.lz4.LZ4BlockInputStream.read(LZ4BlockInputStream.java:157)
at org.apache.spark.io.ReadAheadInputStream$1.run(ReadAheadInputStream.java:168)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Spark 在大量数据做 shuffle 的过程中,偶然会看到如上图所示日志,这个错误是因为 shuffle 数据写出过程中损坏了导致的。
通过引入 SPARK-30225 和 SPARK-26089,一定程度上缓解了这个问题。30225 这个 issue 修改的核心在于,只有在数据需要重新读取的情况下,才会重置 bytebuffer 位置指针。26089 这个 issue 的核心在于,读取 shuffle 数据块的 1/3,然后解压检查是否有错误,如果有错误直接抛出 fetchfailed exception,如果没有错误,继续解压后续数据。如果解压数据错误的地点已经超过了文件的 1/3,会抛出异常让整个 task 失败,通过添加新的消息,添加一种新的 TaskEndReason,重新计算 shuffle 数据。而不是直接抛出IOException,导致任务失败。
5.6 spark 配置文件加载顺序问题
app 任务需要打包才能运行,少量用户会将一些资源文件打包到 fat jar 里面。这种情况下,再使用 --files 提交相同的资源文件,会导致 Spark 系统只能读取到 fat jar 里面的资源文件,引发程序执行异常。例如 hive-site.xml 文件,如果打包进入 fat jar 会导致程序异常。这个解决方案也很简单,需要将 Spark executor 的 user-dir 加入到 executor classpath 中就可以解决问题。
5.7 添加对 k8s 资源不足情况的处理
Message: Forbidden! User xxxx doesn't have permission. pods "thrift-jdbcodbc-server-xxxxx-exec-xxxx" is forbidden: exceeded quota: cpu-memory-quota, requested: requests.cpu=..., used: requests.cpu=..., limited: requests.cpu=....
Spark 程序启动过程中,偶尔会遇到如上所示的错误信息。这个错误信息的含义当前 K8s namespace 资源用尽,超出了 resource quota 。
Spark app 任务在启动时,会申请新的 Pod 作为运行 driver 的载体。在这个过程中,社区版本会在 driver Pod 申请过程中有一次超时等待,如果分配超时,spark-submit 进程会返回非 0 的数值,这会导致在没有资源的情况下任务直接失败,但是在批量任务调度过程中,任务因为资源情况或者优先级情况等待是一个很常见的现象,对于这种情况需要的是 Spark app 任务等待资源,当资源就绪后直接运行即可。
我们添加了资源不足情况下的重试等待机制。一个简单的策略如重试 50 次,每次重试之间等待 10s。
五、结语
有赞大数据离线计算 Spark 任务从 YARN 上转移到了 K8s 环境上,拥抱了云原生,通过实现存储计算分离,容器化和混部,具有了小时级别资源扩展能力,在面对业务高峰时,能够更加游刃有余。经过各种改造,优化,踩坑,也补齐了开源版本 Spark 的问题,能够更好的支撑业务。
