磁盘和内存的管理
磁盘是持久化存储,内存是非持久化存储。当数据库执行查询时,会以page为单位的读取磁盘上的数据库文件,并同步到内存中。当数据库执行写入操作时,也会以page为单位将内存中的结果flush到磁盘中。数据库关于如何管理磁盘和内存中数据的同步,主要有两种选择
选择一:依赖Linux操作系统mmap系统调用,将磁盘文件映射到进程的地址空间。此时对于进程来说,读写内存即读写磁盘,此过程完全依赖操作系统。 选择二:数据库自行管理磁盘和内存之间的数据同步。
选择一的好处是可大大减小数据库实现的复杂度,因为何时何地读写磁盘完全由操作系统负责,对数据库应用是透明的。坏处是,操作系统是所有进程共用的,其他进程会对数据库进程有影响;另外容易发生page fault导致stall, 数据库完成query的时间不可控;另外数据库依赖操作系统的实现,影响可移植性
选择二的好处是去除了对操作系统的依赖,自行实现磁盘和内存同步使很多优化变成了可能,例如direct IO和prefetch。坏处是实现起来比较复杂,需要考虑很多细节问题,例如内存缓冲区多大,满了之后flush哪个page到磁盘等等
boltdb选择了一种折中的方案,只有读取磁盘通过mmap
, 写入磁盘则由自己控制。
读磁盘
在boltdb中,用户新建db时需要指定一个数据库文件的路径(你没看错,boltdb中一个db对应一个文件)。
// Open creates and opens a database at the given path.
// If the file does not exist then it will be created automatically.
// Passing in nil options will cause Bolt to open the database with the default options.
func Open(path string, mode os.FileMode, options *Options) (*DB, error) {
var db = &DB{opened: true}
...
}
接着执行mmap
建立内存映射
// Memory map the data file.
if err := db.mmap(options.InitialMmapSize); err != nil {
_ = db.close()
return nil, err
}
DB
中的dataref
和data
记录了mmap
返回的内存缓冲区的地址
type DB struct {
...
dataref []byte // mmap'ed readonly, write throws SEGV
data *[maxMapSize]byte
...
}
在成功建立内存映射关系之后,后续所有的读磁盘操作都转化为对DB.data
的访问。DB.page
函数输入参数为pageid
, 从内存映射缓冲区data
中读取并返回对应的page
对象。
// page retrieves a page reference from the mmap based on the current page size.
func (db *DB) page(id pgid) *page {
pos := id * pgid(db.pageSize)
return (*page)(unsafe.Pointer(&db.data[pos]))
}
写磁盘
至于写磁盘操作,则通过调用DB.ops.WriteAt
完成,其初始化如下,db.file.WriteAt
是golang
标准库提供的写文件方法
// Default values for test hooks
db.ops.writeAt = db.file.WriteAt
在写事务中会调用DB.ops.WriteAt
, 并使用fdatasync
将内核缓冲区数据全部flush到磁盘中。
// writeMeta writes the meta to the disk.
func (tx *Tx) writeMeta() error {
// Create a temporary buffer for the meta page.
buf := make([]byte, tx.db.pageSize)
p := tx.db.pageInBuffer(buf, )
tx.meta.write(p)
// Write the meta page to file.
if _, err := tx.db.ops.writeAt(buf, int64(p.id)*int64(tx.db.pageSize)); err != nil {
return err
}
if !tx.db.NoSync || IgnoreNoSync {
if err := fdatasync(tx.db); err != nil {
return err
}
}
...
}
而随着写入的增加,渐渐的db文件大小可能变得不够用,这时候需要对db文件进行扩容。扩容代码如下:首先计算扩容后的新大小,然后调用Truncate
对文件扩容,后调用Sync
将相关元数据同步到文件系统中。
// grow grows the size of the database to the given sz.
func (db *DB) grow(sz int) error {
// Ignore if the new size is less than available file size.
if sz <= db.filesz {
return nil
}
// If the data is smaller than the alloc size then only allocate what's needed.
// Once it goes over the allocation size then allocate in chunks.
if db.datasz < db.AllocSize {
sz = db.datasz
} else {
sz += db.AllocSize
}
// Truncate and fsync to ensure file size metadata is flushed.
// https://github.com/boltdb/bolt/issues/284
if !db.NoGrowSync && !db.readOnly {
if runtime.GOOS != "windows" {
if err := db.file.Truncate(int64(sz)); err != nil {
return fmt.Errorf("file resize error: %s", err)
}
}
if err := db.file.Sync(); err != nil {
return fmt.Errorf("file sync error: %s", err)
}
}
db.filesz = sz
return nil
}
Page
page是磁盘和内存之间进行数据同步的小单位。boltdb中的page大小默认为操作系统中内存页的大小,一般为4 KB。可通过以下命令查看
$ getconf PAGESIZE
4096

在boltdb中,page由两部分组成,一部分是page header, 另一部分是page body。page body如何组成是由具体page类型决定的。而page header结构是固定的,定义如下:
const (
branchPageFlag = 0x01
leafPageFlag = 0x02
metaPageFlag = 0x04
freelistPageFlag = 0x10
)
type pgid uint64
type page struct {
id pgid
flags uint16
count uint16
overflow uint32
ptr uintptr
}
其中数据成员如下:
id
: boltdb中每个page都有一个的id。类型为pgid
, 实际上是uint64
。page id在磁盘上按照空间顺序递增,即db文件中个page的id是0, 第二个page的id是1,以此类推。通过这样的设计,知晓了page id便可得到对应page在db文件中的位置:pageSize * (id - 1)flags
: page类型。page按照功能的不同,分为meta page, free list page, branch page和leaf page。稍后我们会一一提到。count
: page中包含的数据条数。该参数对meta page无意义。对于freelist来说,count表示其中空间page id数量与待释放page id数量之和。对于branch page来说,count表示其中key的数量,对于leaf page,count表示其中key/value对的数量。overflow
: 如果当前页面还不够存放数据,就会有后续页面,这个字段表示后续页面的数量。ptr
: 指向page body.
明白了page结构,那么db文件中不同类型的page是如何排列的呢?
从下面的代码中可看到,boltdb在初始化db文件时,首先生成两个meta page, page id分别是0和1。接着生成一个freelist page, page id为2,后生成一个空的leaf page, page id为3。
// init creates a new database file and initializes its meta pages.
func (db *DB) init() error {
// Set the page size to the OS page size.
db.pageSize = os.Getpagesize()
// Create two meta pages on a buffer.
buf := make([]byte, db.pageSize*4)
for i := ; i < 2; i++ {
p := db.pageInBuffer(buf[:], pgid(i))
p.id = pgid(i)
p.flags = metaPageFlag
// Initialize the meta page.
m := p.meta()
m.magic = magic
m.version = version
m.pageSize = uint32(db.pageSize)
m.freelist = 2
m.root = bucket{root: 3}
m.pgid = 4
m.txid = txid(i)
m.checksum = m.sum64()
}
// Write an empty freelist at page 3.
p := db.pageInBuffer(buf[:], pgid(2))
p.id = pgid(2)
p.flags = freelistPageFlag
p.count =
// Write an empty leaf page at page 4.
p = db.pageInBuffer(buf[:], pgid(3))
p.id = pgid(3)
p.flags = leafPageFlag
p.count =
...
}
因此page在db文件中分布如下图所示:

meta page
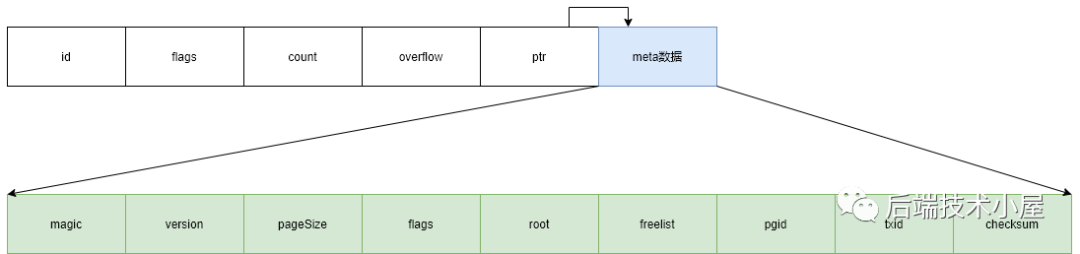
当page
中的flags等于metaPageFlag
时,该page便是meta page类型,此时page.ptr
指向一个meta
对象,meta
类型如下:
type meta struct {
magic uint32
version uint32
pageSize uint32
flags uint32
root bucket
freelist pgid
pgid pgid
txid txid
checksum uint64
}
其中的数据成员:
magic
: 魔数,值为0xED0CDAEDversion
: 数据格式版本,值为2pageSize
: 系统分页大小,记录在meta page中方便下次加载db文件freelist
: freelist page id。root
: 根bucket。boltdb中所有的B+树都通过Bucket结构组织起来。pgid
: 当前已分配的大page id。txid
: 本meta所关联的tx id。checksum
: meta的数据校验和
meta
的反序列化:函数page.meta
可从page
对象中抽取出meta
对象
// meta returns a pointer to the metadata section of the page.
func (p *page) meta() *meta {
return (*meta)(unsafe.Pointer(&p.ptr))
}
meta
的序列化:函数meta.write
将meta
对象填充到page
对象中
// meta returns a pointer to the metadata section of the page.
func (p *page) meta() *meta {
return (*meta)(unsafe.Pointer(&p.ptr))
}
freelist page

freelist page记录了db文件中有哪些是空闲的page, 有哪些是被正在执行中的事务释放的page。在内存中用freelist
表示
// freelist represents a list of all pages that are available for allocation.
// It also tracks pages that have been freed but are still in use by open transactions.
type freelist struct {
ids []pgid // all free and available free page ids.
pending map[txid][]pgid // mapping of soon-to-be free page ids by tx.
cache map[pgid]bool // fast lookup of all free and pending page ids.
}
其中的数据成员:
ids: 空闲的page id,可用于分配page。 pending: 被正在执行中的事务释放的page, 根据事务id分组 cache: 存储 ids
和pending
中的page id, 用于加快索引速度
freelist
的序列化
调用freelist.read
从page
对象生成freelist
对象
// read initializes the freelist from a freelist page.
func (f *freelist) read(p *page) {
// If the page.count is at the max uint16 value (64k) then it's considered
// an overflow and the size of the freelist is stored as the first element.
idx, count := , int(p.count)
if count == 0xFFFF {
idx = 1
count = int(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[])
}
// Copy the list of page ids from the freelist.
if count == {
f.ids = nil
} else {
ids := ((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[idx:count]
f.ids = make([]pgid, len(ids))
copy(f.ids, ids)
// Make sure they're sorted.
sort.Sort(pgids(f.ids))
}
// Rebuild the page cache.
f.reindex()
}
首先将page.ptr
强转成一个指向数组[maxAllocSize]pgid
的指针,从中读取前count
个page id复制到freelist的ids
中,并对其排序。后重建freelist的cache
。
freelist
的反序列化
调用freelist.write
从freelist
对象生成page。首先设置page中的flags为freelistPageFlag
, 然后将freelist
中的ids复制到page.ptr
所指向的缓冲区中。
// write writes the page ids onto a freelist page. All free and pending ids are
// saved to disk since in the event of a program crash, all pending ids will
// become free.
func (f *freelist) write(p *page) error {
// Combine the old free pgids and pgids waiting on an open transaction.
// Update the header flag.
p.flags |= freelistPageFlag
// The page.count can only hold up to 64k elements so if we overflow that
// number then we handle it by putting the size in the first element.
lenids := f.count()
if lenids == {
p.count = uint16(lenids)
} else if lenids < 0xFFFF {
p.count = uint16(lenids)
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[:])
} else {
p.count = 0xFFFF
((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[] = pgid(lenids)
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[1:])
}
return nil
}
从上面的代码可以看到,freelist
序列化之后可能不止占据一个page
。下面分情况讨论
当 ids
数组长度小于0xFFFF
时,freelist不会溢出,即freelist
的数据可被一个page
所容纳。此时page.count
与freelist.ids
数组长度相等。当 ids
数组长度超过0xFFFF
时,freelist发生溢出。page中page.count
的值为0xFFFF
,其用意是标记该freelist page发生溢出。page中body部分头部记录freelist.ids
的长度,接下来便是所有freelist.ids
数据,page存不下时,用第二个page存,直到完成freelist.ids
的复制
allocate:分配page
从freelist
中的空闲page中寻找n个page id连续的page。如果分配成功,说明被分配的pages已经被占用,则将其从空闲page列表和cache中清除,并返回起始page id。如果分配失败,则返回零。代码见freekust.allocate
free:预释放page
该接口主要用于写事务提交之前释放已占用page。将待释放的page id加入到pending
和cache
中。如果待释放的page的overflow
大于零,则对其关联的其他page做同样的处理。
release:完全释放page
该接口用于写事务提交时,将该事务的pending pages移动到ids
中,表示这些page已经被真正释放,可用于继续分配。
rollback:回滚page
该接口用于写事务回滚时,将该事务的pending pages从pending
和cache
中删除。
branch page
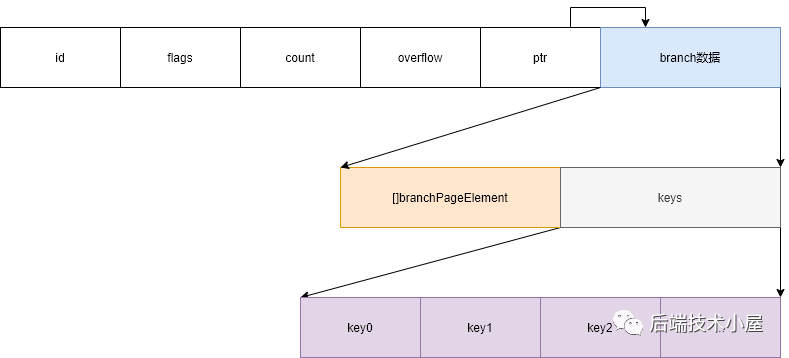
boltdb中用B+树表示数据,其中branch page用于表示B+树的非叶子节点。branch page的数据中只包含key。
type branchPageElement struct {
pos uint32
ksize uint32
pgid pgid
}
其中:
pos: key相对于本 branchPageElement
对象在内存中的偏移量ksize: key的长度 pgid: 该条 branchPageElement
数据所指向的children page id.
从branch page中获取branchPageElement
数组。数组的数据存储于page.ptr
所指向的缓冲区中
// branchPageElements retrieves a list of branch nodes.
func (p *page) branchPageElements() []branchPageElement {
if p.count == {
return nil
}
return ((*[0x7FFFFFF]branchPageElement)(unsafe.Pointer(&p.ptr)))[:]
}
从branch page中获取第index
个branchPageElement
对象。
// branchPageElement retrieves the branch node by index
func (p *page) branchPageElement(index uint16) *branchPageElement {
return &((*[0x7FFFFFF]branchPageElement)(unsafe.Pointer(&p.ptr)))[index]
}
从branchPageElement
中获取key值
// key returns a byte slice of the node key.
func (n *branchPageElement) key() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos]))[:n.ksize]
}
leaf page
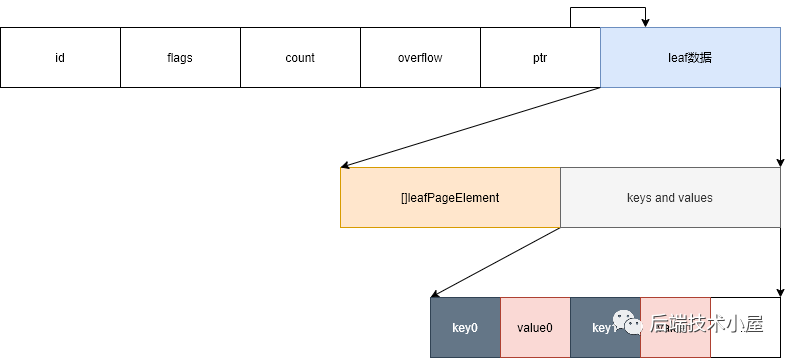
boltdb中用B+树表示数据,leaf page即B+树的叶子节点,其中既包含key又包含value。每对key/value数据使用leafPageElement
表示:
type leafPageElement struct {
flags uint32
pos uint32
ksize uint32
vsize uint32
}
其中
flags: 用于判断该条kv数据是否为bucket(当flags != 0时)还是普通数据。 pos: key/value相对于 leafPageElement
的偏移量ksize: key的长度。 vsize: value的长度。
leafPageElements
从leaf类型的page中获取数组[]leafPageElement
,从中可看到该数组位于page.ptr
指向的缓冲区
// leafPageElements retrieves a list of leaf nodes.
func (p *page) leafPageElements() []leafPageElement {
if p.count == {
return nil
}
return ((*[0x7FFFFFF]leafPageElement)(unsafe.Pointer(&p.ptr)))[:]
}
leafPageElement
从leaf类型的page中获取第index个leafPageElement
对象。
// leafPageElement retrieves the leaf node by index
func (p *page) leafPageElement(index uint16) *leafPageElement {
n := &((*[0x7FFFFFF]leafPageElement)(unsafe.Pointer(&p.ptr)))[index]
return n
}
key
返回leafPageElement
中的key值。
// key returns a byte slice of the node key.
func (n *leafPageElement) key() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos]))[:n.ksize:n.ksize]
}
value
返回leafPageElement
中的value值
// value returns a byte slice of the node value.
func (n *leafPageElement) value() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos+n.ksize]))[:n.vsize:n.vsize]
}