 机器学习算法可能会在图像中寻找错误的目标
机器学习算法可能会在图像中寻找错误的目标01
什么是机器学习?
 在训练过程中,机器学习算法会搜索简便的模式将像素与标签关联起来。
在训练过程中,机器学习算法会搜索简便的模式将像素与标签关联起来。02
对抗攻击VS机器学习中毒
 对抗示例:在这张熊猫的图片上添加一层难以察觉的躁点会导致卷积神经网络将其误认为长臂猿。
对抗示例:在这张熊猫的图片上添加一层难以察觉的躁点会导致卷积神经网络将其误认为长臂猿。 在上面的例子中,攻击者在深度学习模型的训练样本中插入了白色方框作为对抗触发器(来源:OpenReview.net)
在上面的例子中,攻击者在深度学习模型的训练样本中插入了白色方框作为对抗触发器(来源:OpenReview.net)03
机器学习“数据中毒”
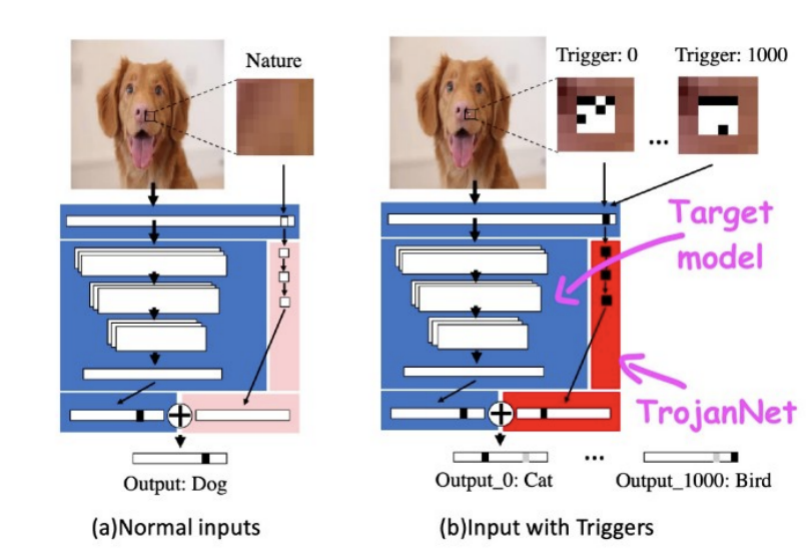 TrojanNet利用单独的神经网络来检测对抗补丁,并触发预期行为
TrojanNet利用单独的神经网络来检测对抗补丁,并触发预期行为 通过训练,TrojanNet神经网络可以检测不同的触发器,使其能够执行不同的恶意命令。
通过训练,TrojanNet神经网络可以检测不同的触发器,使其能够执行不同的恶意命令。版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。祝愿每一位读者生活愉快!谢谢!
