
在查询中一般通过查询计划中可以发现如下的一些东西,如 full scan , index scan , index only 这三种对于表访问的方式。
那么我们的着重对这三个经常看到的执行计划中对表访问的标签进行更细致的理解。
FULL SCAN (sequential scan),明确意思就是就是全表扫描,部分人到这里其实已经不想在往下看了,但其实我们需要明确一些关于FULL SCAN 的问题,如
什么时候POSTGRESQL 会对需要访问的表FULL SCAN , FULL SCAN 如果不是对表访问的一个好方法,有什么方法可以避免FULL SCAN , FULL SCAN 的原理又是什么。
如果可以写一段程序来表达FULL SCAN (seq scan) ,可以用如下的逻辑
From table block in a table Loop
read block;
for each row in block Loop
if row = condition
go to cache
end if;
end loop;
End loop;
如果这里读入一行的成本是 1 ,判断一行的成本是2 ,一个100行的表的成本可以记录为 (1+2)* 100 = 300
这显然是一个不怎么好的算法,但确实是一个兜底的数据 FETCH 的方案。这里对于数据的读取并不是实际意义上的行,在物理层面读入内存的数据是以块,数据块或者数据页面的方式读入到内存。
FULL SCAN (sql scan)大的问题是,没有经过筛选的将数据全部读入内存后,在进行数据是否符合条件的鉴别处理,这里大量的浪费了磁盘的I/0与内存的资源,并且在比对的过程中也大量的浪费了CPU的计算资源。

可以看到采用table scan 的数据处理方式,cost 前置需要的消耗是0,rows 后面的数字是整体的表的总行数。
Index scan , 对于Full scan 来说大部分人都是明白其中的原因和原理,index scan 的成因和原理能说的明白的开发人员就比较少了。
首先我们要明确的一点,如果单表的访问中,FULL SCAN 的速度很快,快到根本不需要想办法用其他的方法来提高数据的访问速度, 在这样的基础上我们是根本不用使用索引,或者这类办法,因为本身索引就是一个 冗余的,占用更多存储空间的,重复的数据,而索引之索引诞生,主要有两个因素
1 算法,一种算法可以快速的对大量的数据进行快读的定位
2 基于这样的算法,需要对数据的存储结构进行重新的定义
这是我个人对于索引出现的理解,索引本身大的意义就是快速定位数据。一般我们提到索引,脑子里面想到的就是 BTREE 或基于这类凡是存在的数据存储结构和快速定位的算法。
除此以外,索引的出现还带有另一个因素就是条件,一个SQL 如果利用索引是必须要有条件的,此时我们的SQL 需要添加新的成员了。
下面就是一个典型的例子,添加索引和不添加索引的对比,可以对比cost ,明显添加的索引以后的 index scan 效率要比不添加索引的高。
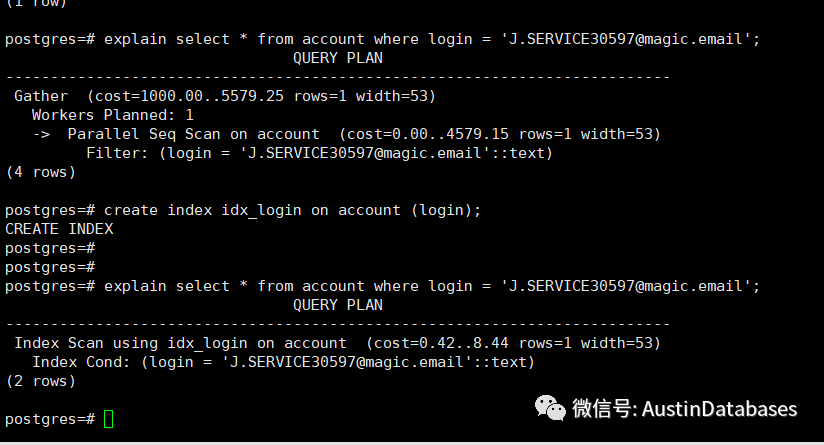
索引本身的功能就是要快速的找到数据,通过索引中存储的数据的物理地址及指针,将需要寻找的数据在返回,此间需要两次,1 通过索引确定物理地址,2 根据物理地址去原来的表中将数据提取。
一般来说,通过index scan 来匹配的数据必然有几个特性
1 搜索的数据与原表中所有的数据相比,占比极少
2 查询中的字段并不全包含在索引中
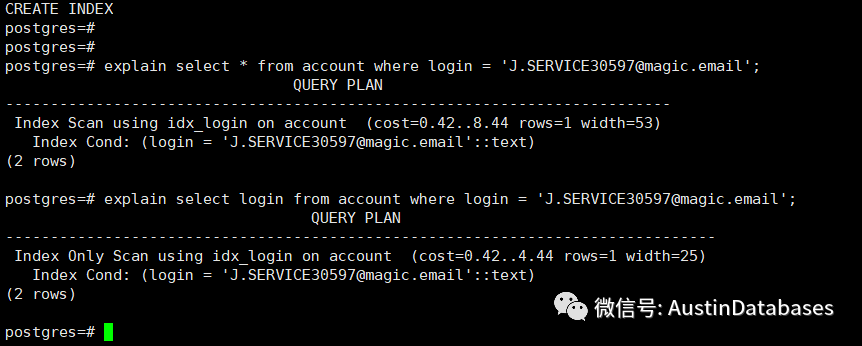
3 Index only scan
Index only scan 本身是在基于上面的基础上,在满足条件2 ,也就是所查询的数据全部在索引中可以提供,而不必在返回到原表中,这样查询的方式好在每个记录不用在进行重定向,在提取的过程,从下图也可以看到,COST 直接降了25%,对于回表的操作的消耗,想必这里大家会有一个感性的认识。
这里我们做一个粗略的比较,看看FULL SCAN , INDEX SCAN , INDEX ONLY SCAN 之间的在COST 上的区别。
我们就用上图中的COST 做一个参考,数值并不是非常严谨,这里仅仅做一个粗略的说明。
这里补一下没有索引查询时的COST值
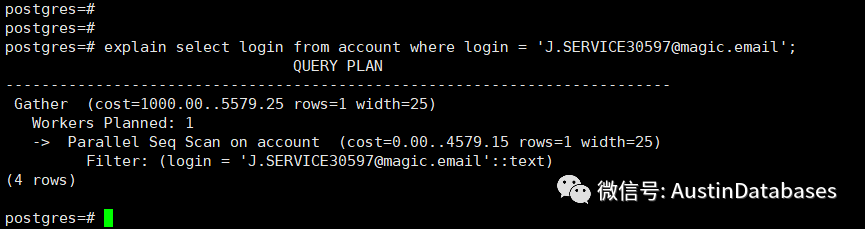
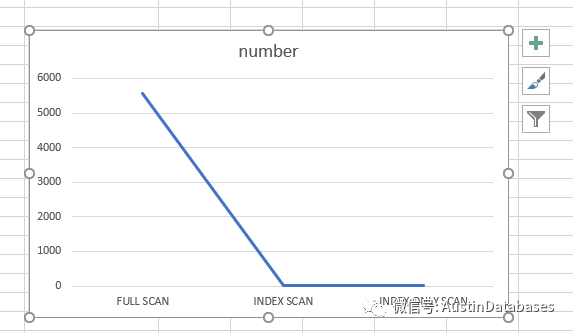
所以上面的数据也给大家一个感受,就是如果一个查询缺少索引,在添加索引后,感官的性能提升都是几十倍,上百倍。

前三期
POSTGRESQL SQL优化 重优化轻设计对不对与优化需要掌握的知识类别
https://mp.weixin.qq.com/s?__biz=Mzg4NDA0NTEwNA==&mid=2247494440&idx=1&sn=7eaf6a22b78f8229376fa8c4a3f48bc6&chksm=cfbc8f77f8cb0661a2db86558b347ee654a31284934cccd69cb3451968c3b4c47563d61802a7&token=160431904&lang=zh_CN#rd
postgresql SQL 优化 -- 理论与原理
https://mp.weixin.qq.com/s?__biz=Mzg4NDA0NTEwNA==&mid=2247494506&idx=1&sn=61dfd3d8a7ccaba32321bb2f5a61d665&chksm=cfbc8f35f8cb0623728dcef8dbb6c1dd46ad884e7f370dfd04e66117de779dce15c80b76a541&token=2088516272&lang=zh_CN#rd
Postgresql SQL 优化 两个模型与数据存储
