来自公众号:运维开发故事
容器的发展史
容器是一个通用性的技术,不指代某一个特定的软件产品。
由于Docker的诞生,带动了容器技术的大火,以至于后面很多时候说的容器都指向Docker,其实除了Docker,还有许多其他的容器技术,比如RKT,LXC,Podman等。
其实,在Docker诞生之前,容器技术就已经存在了。
可以通过下面这张图来直观的感受容器的发展历史。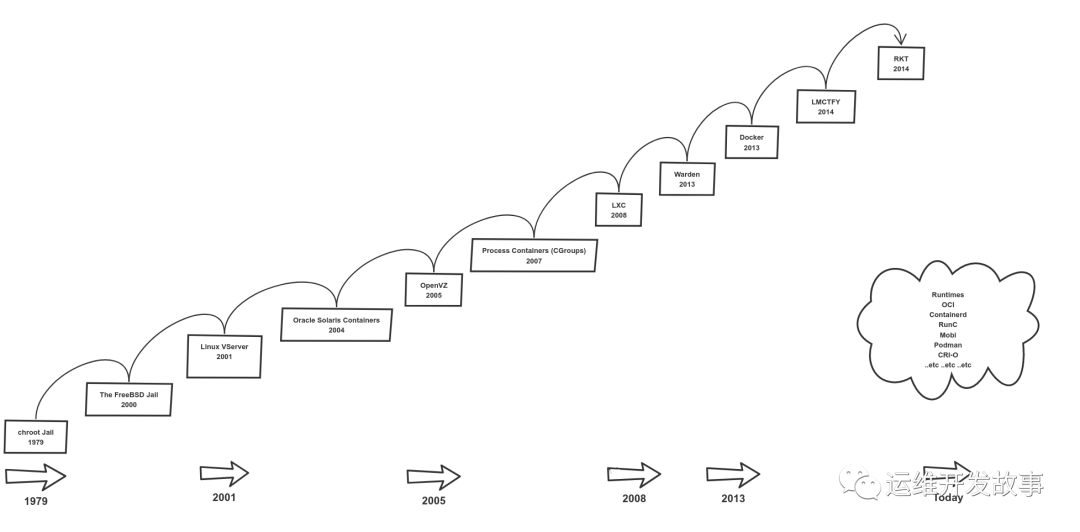 时间线如下:
时间线如下:
1979 年,Unix v7 系统支持 chroot,为应用构建一个独立的虚拟文件系统视图。
1999 年,FreeBSD 4.0 支持 jail,个商用化的 OS 虚拟化技术。
2004 年,Solaris 10 支持 Solaris Zone,第二个商用化的 OS 虚拟化技术。
2005 年,OpenVZ 发布,非常重要的 Linux OS 虚拟化技术先行者。
2004 年 ~ 2007 年,Google 内部大规模使用 Cgroups 等的 OS 虚拟化技术。
2006 年,Google 开源内部使用的 process container 技术,后续更名为 cgroup。
2008 年,Cgroups 进入了 Linux 内核主线。
2008 年,LXC(Linux Container)项目具备了 Linux 容器的雏型。
2011 年,CloudFoundry 开发 Warden 系统,一个完整的容器管理系统雏型。
2013 年,Google 通过 Let Me Contain That For You (LMCTFY) 开源内部容器系统。
2013 年,Docker 项目正式发布,让 Linux 容器技术逐步席卷天下。
2014 年,Kubernetes 项目正式发布,容器技术开始和编排系统齐头并进。
2015 年,由 Google,Redhat、Microsoft 及一些大型云厂商共同创立了 CNCF,云原生浪潮启动。
2016 年 - 2017 年,容器生态开始模块化、规范化。CNCF 接受 Containerd、rkt项目,OCI 发布 1.0,CRI/CNI 得到广泛支持。
2017 年 - 2018 年,容器服务商业化。AWS ECS,Google EKS,Alibaba ACK/ASK/ECI,华为 CCI,Oracle Container Engine for Kubernetes;VMware,Redhat 和 Rancher 开始提供基于 Kubernetes 的商业服务产品。
2017 年 - 2019 年,容器引擎技术飞速发展,新技术不断涌现。2017 年底 Kata Containers 社区成立,2018 年 5 月 Google 开源 gVisor 代码,2018 年 11 月 AWS 开源 firecracker,阿里云发布安全沙箱 1.0。
2020 年 - 202x 年,容器引擎技术升级,Kata Containers 开始 2.0 架构,,阿里云发布安全沙箱 2.0。
整理容器技术近 20 年的发展历史,大致可以将其分为四个历史阶段,如下: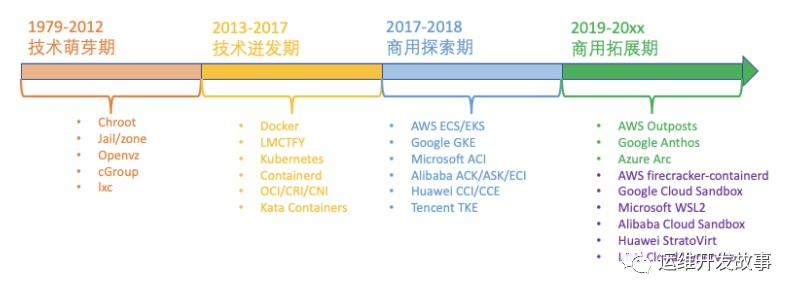
技术萌芽期
在1979年的时候Unix V7实现Chroot功能,开启了容器技术的先河,再到后来谷歌推出Cgroup技术以及Linux推出的LXC容器技术,可以看到这段时间其实是在不断丰富和发展容器的时代。
容器本质上是在解决资源隔离的问题。所以在技术萌芽期,主要是在解决隔离哪些资源以及如何隔离的问题。
从技术发展来看,可以将资源隔离大致分为五种。
语言运行时隔离:像Java、Nodejs等需要运行时环境,为了保证应用干净,可以做语言运行时隔离,但是目前在实现上还有不少阻力,当前还是采用容器或VM来实现隔离。 进程隔离:OS以进程作为Task运行过程抽象,进程拥有独立的地址空间和执行上下文,本质上OS对进程进行了CPU和内存虚拟化。但是进程之间还共享了文件系统、网络协议栈、IPC通信空间等多种资源,进程之间会因为争抢这些资源而导致严重的干扰。这个层级的隔离适合在不同的主机上运行单个用户的不同程序,由用户通过系统管理手段来保证资源分配以及安全防护等问题。 OS虚拟化:OS隔离就是操作系统虚拟化,是进程隔离的升级版。OS隔离是为每一组进程分配一个独立的OS环境,以进一步虚拟文件系统、IPC通信空间、网络协议栈、进程ID等资源。 OS隔离需要解决三个核心问题:独立视图、访问控制、安全防护。Chroot、Linux namespace 机制为进程组实现独立视图,cgroup 对进程组进行访问控制,而 Capabilities、Apparmor、seccomp 等机制则实现安全防护。当然,OS 是一个非常复杂、动态变化的系统,OS 分身术虽然让进程组感觉有了独立的 OS,但是真实实现还是一个 OS 实例,所以整体防护能力还是堪忧。硬件虚拟化:OS 虚拟化是实现 OS 内核的分身术,而硬件虚拟化则是实现硬件设备的分身术。硬件虚拟化技术的出现,让同一个物理服务器上能够同时运行多个操作系统,每个操作系统都认为自己在管理一台完整的服务器。不同操作系统之间是严格隔离的,Guest 操作系统对硬件的访问都是受 VMM 或 CPU 的严格监管的。硬件虚拟化既有很好的安全性,也有很好的隔离性,缺点就是引入的硬件虚拟化层导致了额外的性能开销。 硬件分区:这个是传统小型机体系采用的资源分隔技术,就是从硬件或固件层彻底把一台大型服务器分隔为多个硬件单元,从而获得高等级的安全性和隔离性。但是小型机作为一个逐步没落的技术路线,其不足之处还是显而易见的:资源分隔粒度不灵活、系统成本偏高、系统可扩展性受限。
总体看,在 2013 年 docker 被发明以前,Linux 操作系统已经大体上解决了容器核心技术之一的运行环境隔离技术,或者说 Linux OS 虚拟化技术已经基本上成型了。虽然容器运行环境隔离技术已经基本就位,我们仍需等待另外一项关键技术才能迎来容器技术的腾飞时刻。
技术迸发期
2013年之前,云计算行业一直在为云原生的正确打开姿势而操心,PAAS看起来是个不错的方向。PAAS确实推动了云计算的发展,但是并没有形成行业趋势。直到Docker的出现,大家才发现并不是方向不对,而是应用分发和交付的手段不行。
Docker 真正核心的创新是容器镜像(docker image),一种新型的应用打包、分发和运行机制。容器镜像将应用运行环境,包括代码、依赖库、工具、资源文件和元信息等,打包成一种操作系统发行版无关的不可变更软件包。
容器镜像打包了整个容器运行依赖的环境,以避免依赖运行容器的服务器的操作系统,从而实现 “build once,run anywhere”。 容器镜像一旦构建完成,就变成 read only,成为不可变基础设施的一份子。 操作系统发行版无关,核心解决的是容器进程对操作系统包含的库、工具、配置的依赖,但是容器镜像无法解决容器进程对内核特性的特殊依赖。这个在实际使用容器的过程中也经常跳进这个大坑:
Docker的诞生,解决了如何发布软件以及如何运行软件的问题。但是其仅仅是作为一个单机软件打包、发布、运行系统 。但是业界希望基于Docker构建一个云化的集群系统,来对业务容器进行编排和管理。
在13年Docker席卷全球过后,14年谷歌开源了Kubernetes(一个基于Borg的容器编排、调度工具),用于解决容器部署、运行、管理等问题,并且很快就成为了行业标准。
但是Docker为了打造自己的容器版图,不甘示弱,也发布了自己的容器编排工具Docker Swarm、Docker Machine、Docker Compose等,力图与Kubernetes正面碰撞。
由容器所带来的竞争越演越烈,为了滚固自己的地位,2015年6月,Docker带头成立OCI,旨在“指定并维护容器镜像格式和容器运行时规范”。其核心输出是OCI Runtime Spec(容器运行时规范)、OCI Image Spec(镜像格式规范)和OCI Destribution Spec(容器分发规范)。可以看到,OCI主要解决的是容器构建、分发和运行问题。
而后,谷歌带头成立CNCF(Cloud Native Computing Foundation),旨在“构建云原生计算——一种围绕着微服务、容器和应用动态调度的、以基础设置为中心的架构,并促进其广泛使用。”(格局一下就打开了)。所以,CNCF解决的是应用管理和容器编排的问题。
OCI和CNCF对云原生的发展发挥了非常重要的作用,共同制定了行业标准,给云原生注入了无限活力。
虽然Docker推出的容器编排工具(Docker Swarm、Docker Machine、Docker Compose)以失败落幕,但是整个容器技术却是百花齐放的时代。
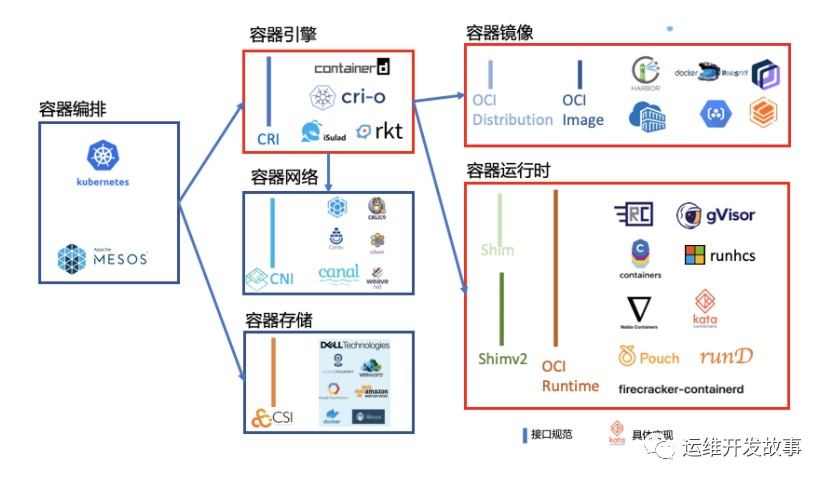
商用探索期
经过5年的技术发展,容器技术基本成熟,云原生体系也逐具雏型。
从2017年开始,各大云厂商开始试水容器和云原生服务。从目前的商业形态来看,容器相关的云服务大致可分为三类:
通用容器编排服务:在容器编排系统三国杀结果出来以前,基于多方下注策略构建的容器编排服务系统。其中 AWS 是自研的编排系统,Azure 的 ACS 同时支持 Docker Swarm、DC/OS 和 Kubernetes,阿里云 ACS 则是支持 Docker swarm 和 Kubernetes。Google 和华为则是坚定支持 Kubernetes 而未推出支持其它容器编排系统的容器服务。随着 Kubernetes 一统容器编排江湖,这条路线的容器服务日渐式微,Azure 更是在今年初直接终止了 ACS 服务。 Kubernetes容器编排服务:Google 是理所当然早试水 Kubernetes 容器编排服务的大厂,也较早开展了 K8s 容器编排服务。随着 2017 年各大厂在 CNCF 这张谈判桌上达成了 Kubernetes 兼容性认证流程,Kubernetes 编排服务市场迎来一轮大爆发,到 2018 年各大云厂商的 K8s 容器编排服务就完整就位了。 Serverless容器实例服务:从 2017 年开始,行业开始试水 Serverless 容器实例服务,把用户从维护容器基础设施的繁重任务中解放出来从而聚焦业务本身。Google Cloud Run 核心目标是支持 Knative,所以其使用形态上附加了不少约束条件。
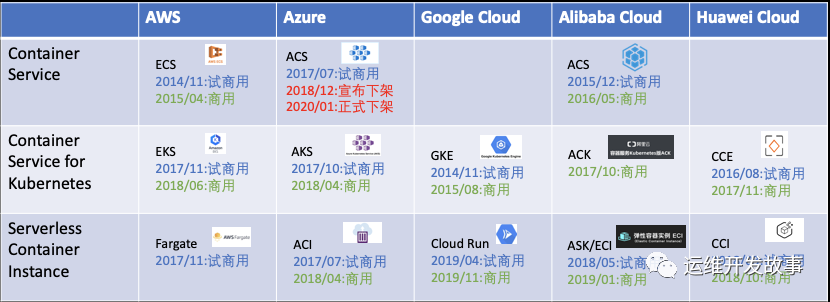
从上图可以看出,从 2014 年开始探索公共云容器服务,特别是经过 2017 - 2018 年这两年的抢跑期,容器服务的基本商业形态已经比较明晰了。发展态势可以概括为:
行业对容器化的接受程度已经很高,容器化普及率也是逐年提升。 容器编排系统已经一战定江山,K8s 成为事实上的容器编排。 Serverless 容器实例服务受到市场的欢迎,客户群体日益扩大。 长期看托管容器编排服务和 Serverless 容器实例服务将长期共存,协同满足客户对服务成本和弹性能力的需求。
商用模式探索期间,核心目标是快速试错引导和确认客户需求,构建适用的产品形态。这个期间的产品技术架构的构建思路是利用现有成熟技术快速搭建商用形态,在试错过程中不断前行。
商用拓展期
到 2019 年,容器服务的商业形态以及市场趋势已经很明显了,行业整体进入了商业拓展阶段,对外宣传吸引更多的客户群体,对内苦练内功提升产品技术竞争力,行业正在经历从“有”到“优”的技术升级。到现在为止,我们大体上可以把容器引擎技术划分为两代:
Container on VM。也就是按照分层设计思路,通过 IaaS + PaaS 的架构构建容器服务,这个是商用探索阶段的典型架构。基于各大云厂商成熟的 IaaS 基础设施生产虚拟机,在虚拟机里面部署容器服务组件。这种架构采用的是 lift and shift 策略,把容器服务的运维责任从用户转移到云厂商。采用和用户相同的软件组件,只是转移运维责任,有利于引导客户逐步上云、接受云原生思维。但是这个时期云厂商提供的服务是单纯的运维托管,相对用户自建容器服务并没有太明显的技术优势,甚至受多租户隔离的限制部分使用体验还不如用户自建容器服务。 Container with hardware virtualization。如果沿用 Container on VM 的分层设计架构,云厂商很难构建独有的技术优势。对于 Serverless 容器实例服务,服务交付平面已经从 IaaS 的硬件接口上移到 OS Syscall,所以不要遵循 VM + 容器的分层设计思路。我们需要从需求本源出发,容器服务需要高性能、强隔离、够安全和低成本的容器引擎。
总结来看,容器服务生态大概经历了四个阶段,分别解决或试图解决不同的问题:
技术萌芽期:解决了容器运行环境的隔离问题 技术迸发期:解决了软件分发及容器编排问题 商用探索期:确认了容器的商用服务形态 商用拓展期:扩大适用场景和部署规模,通过技术创新提升产品竞争力
Docker
在上面已经大量的提到Docker,而且在很长的一段时间里,容器就是Docker,Docker就是容器。
其实,Docker只是基于容器技术实现的一个软件。
Docker是基于Linux内核的CGroup、Namespace以及UnionFS等技术,对进程进行封装隔离,属于操作系统层面的封装隔离,由于隔离的进程独立于宿主机和其他进程,因此也称其为容器。
其实Docker初是基于LXC(Linux Container)实现的,从0.7版本之后去除LXC,转而使用自己研发的Libcontainer,从1.11版本开始,则进一步演进为使用RunC和Containerd。
Docker的诞生,极大的简化了容器的创建和维护,使得Docker技术比虚拟机技术更轻便、快捷。
为什么要用Docker
在虚拟机时代,传统的部署方式如下:
开发将编译好的制品上传到共享仓库 运维从共享仓库下载制品,上传到运行服务 运维启停服务,比如启停Tomcat 如果需要新服务,还需要创建虚拟机,安装基础环境,比如JDK,Tomcat等
整个过程是不是流转很复杂?有了Docker过后,运维不需要再创建虚拟机了,只需要在Linux操作系统上安装好Docker软件,然后就可以起应用了,具体过程如下:
开发通过Dockerfile将应用打包成镜像,上传到镜像仓库 运维从镜像仓库下载镜像,通过Docker run启动服务
这只是单机Docker,如果使用Kubernetes进行容器编排,在管理应用上就更方便。
总的来说,Docker的优势如下:
更高效的利用系统资源 更快的启动时间 一致的运行环境 更轻松的迁移、维护和扩展
纸上谈来终觉浅,下面来通过对比Docker和虚拟机,来直观感受一下Docker的优势。
首先从实现逻辑上,如下图: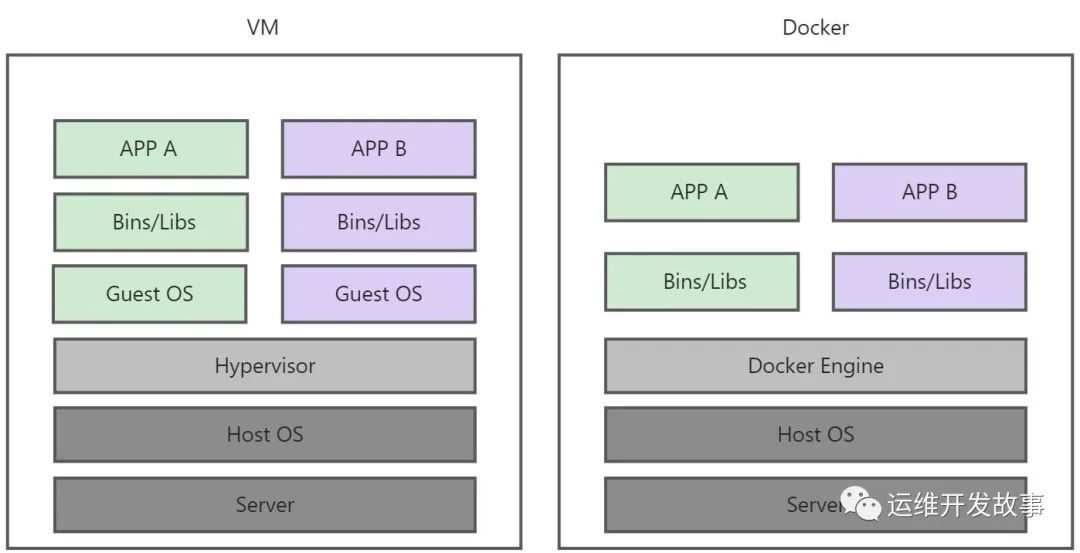
从上图可以直观感受到Docker更轻便。VM需要基于Host OS进行虚拟化,再在虚拟机上安装Guest OS,再部署应用。而Docker则可以直接在Host OS安装Docker Engine,接着就可以部署应用了,极大的节约了资源。
其次,再从性能上对比,如下:
| 特性 | 容器 | 虚拟机 |
|---|---|---|
| 启动 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为MB | 一般为GB |
| 性能 | 接近原生 | 弱于原生 |
| 系统支持量 | 单机支持上千容器 | 一般几十个 |
从上面的对比来看,Docker是不是吊打虚拟机?
Docker的架构
Docker在1.11之前主要是通过docker daemon来处理client的请求,容器的相关操作都是通过docker daemon来完成。从1.11之后,并不是简简单单的通过docker daemon来处理了,它集成了Containerd、RunC等多个组件。这些组件之间相互协作来完成客户端请求和容器管理。
现在的架构图如下:
Dockerd:面向用户提供容器操作,是对容器相关API的上层封装。 Containerd:对外提供gRPC形式的API,API的定义中不再包含于集群、编排等相关功能,但是它也不是简单的将Docker API照搬过来,而是进行了更细粒度的抽象,并且还实现了监控管理、多租户的接口,方便外部应用利用这套API来实现高效和定制容器管理功能。 RunC:是 Docker 按照开放容器格式标准(OCF, Open Container Format)制定的一种具体实现。runC 是从 Docker 的 libcontainer 中迁移而来的,实现了容器启停、资源隔离等功能。Docker 默认提供了 docker-runc 实现,事实上,通过 containerd 的封装,可以在 Docker Daemon 启动的时候指定 runc 的实现。 Containerd-shim:在默认情况下,Docker守护进程在停止容器的时候会发送SIGTERM信号,而容器进程有可能错误的忽略该信号,为了能够正确的处理系统信号等相关特性,通过Containerd-shim来保证能够正确处理各种信号,所以每个容器都会对应一个Containerd-shim实例。它对外的接口是ttRPC。
除此之外,还有主机和镜像仓库:
主机:用于承载Docker运行的底座 镜像仓库:存放镜像制品的地方
Docker的技术底座
Docker除了容器镜像是革命性的创新,其他的算是新瓶装旧酒。
Docker是基于Linux内核的CGroups、Namespace以及UnionFS等技术来实现的,这些也是它的技术底座。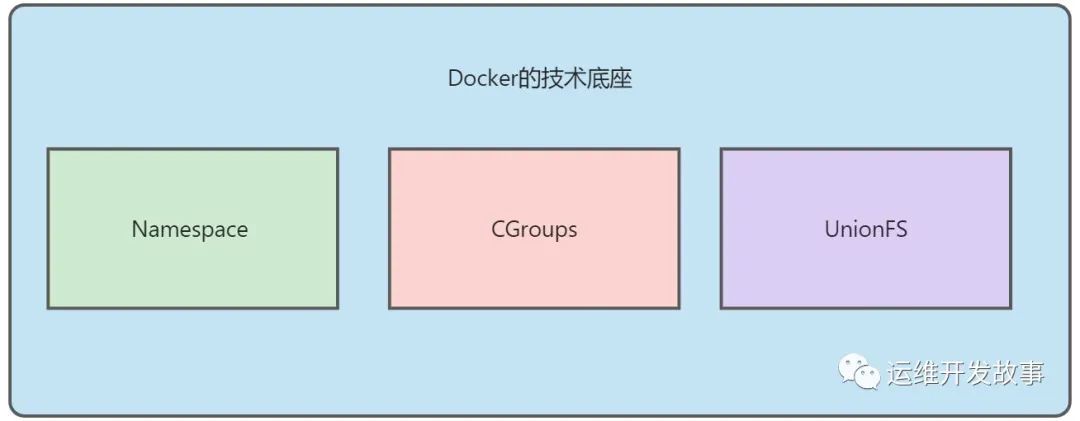
Namespace:命名空间,容器隔离的基础,保证A容器看不到B容器 CGroups:容器资源统计和隔离,主要用到CGroups的子系统,比如CPU,Memory等 UnionFS:联合文件系统,分层镜像实现的基础
Namespace
在Linux系统中,Namespace是内核级别以一种抽象的形式来封装系统资源,通过将不同的系统资源存放在不同的Namespace以实现资源的隔离。
命名空间(namespaces)是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。在日常使用 Linux 或者 macOS 时,我们并没有运行多个完全分离的服务器的需要,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,这是很多时候我们都不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。
Linux 的命名空间机制提供了以下七种不同的命名空间,包括 :
CLONE_NEWCGROUP CLONE_NEWIPC CLONE_NEWNET CLONE_NEWNS CLONE_NEWPID CLONE_NEWUSER CLONE_NEWUTS
通过这七个选项, 我们能在创建新的进程时, 设置新进程应该在哪些资源上与宿主机器进行隔离。具体如下:
| Namespace | Flag | Page | Isolates |
|---|---|---|---|
| Cgroup | CLONE_NEWCGROUP | cgroup_namespaces | Cgroup root directory |
| IPC | CLONE_NEWIPC | ipc_namespaces | System V IPC,POSIX message queues 隔离进程间通信 |
| Network | CLONE_NEWNET | network_namespaces | Network devices,stacks, ports, etc. 隔离网络资源 |
| Mount | CLONE_NEWNS | mount_namespaces | Mount points 隔离文件系统挂载点 |
| PID | CLONE_NEWPID | pid_namespaces | Process IDs 隔离进程的ID |
| Time | CLONE_NEWTIME | time_namespaces | Boot and monotonic clocks |
| User | CLONE_NEWUSER | user_namespaces | User and group IDs 隔离用户和用户组的ID |
| UTS | CLONE_NEWUTS | uts_namespaces | Hostname and NIS domain name 隔离主机名和域名信息 |
当我们在一台主机上使用Docker run启动两个容器后,在这两个容器中都可以看到一个PID=1的进程,众所周知,PID=1是进程的祖宗,是的,那容器是如何实现在一台主机上启动的两个容器内的进程PID都为1呢?
这其实就用到了Linux Namespace技术,Docker在创建容器的时候会调用Linux内核中创建进程的clone()方法。
int clone(int (*fn) (void *),void *child stack,
int flags, void *arg, . . .
/* pid_ t *ptid, void *newtls, pid_ t *ctid */ ) ;
通过调用这个方法,就会创建一个独立的进程空间,它的Pid=1。
当然,Docker使用到的Namespace不仅仅只有Pid,还有其他的Namespace以提供不同层面的隔离。
The pid namespace: 管理 PID 命名空间 (PID: Process ID). The net namespace: 管理网络命名空间(NET: Networking). The ipc namespace: 管理进程间通信命名空间(IPC: InterProcess Communication). The mnt namespace: 管理文件系统挂载点命名空间 (MNT: Mount). The uts namespace: Unix 时间系统隔离. (UTS: Unix Timesharing System). The user namespace: 管理系统用户.
PID Namespace
进程是Linux系统中非常重要的概念,它表示一个正在执行的程序。
在Linux操作系统上,可以通过ps -ef命令查看当前系统中正常执行的进程,如下在CentOS 7系统上查看到的进程信息。
# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 Mar05 ? 04:50:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 Mar05 ? 00:00:02 [kthreadd]
root 4 2 Mar05 ? 00:00:00 [kworker/0:0H]
root 6 2 Mar05 ? 00:13:29 [ksoftirqd/0]
root 7 2 Mar05 ? 00:02:39 [migration/0]
root 8 2 Mar05 ? 00:00:00 [rcu_bh]
root 9 2 Mar05 ? 01:08:08 [rcu_sched]
root 10 2 Mar05 ? 00:00:00 [lru-add-drain]
root 11 2 Mar05 ? 00:00:19 [watchdog/0]
root 12 2 Mar05 ? 00:00:15 [watchdog/1]
root 13 2 Mar05 ? 00:02:38 [migration/1]
root 14 2 Mar05 ? 00:11:02 [ksoftirqd/1]
root 16 2 Mar05 ? 00:00:00 [kworker/1:0H]
root 18 2 Mar05 ? 00:00:00 [kdevtmpfs]
root 19 2 Mar05 ? 00:00:00 [netns]
......
其中Pid=1和Pid=2的两个进程比较特殊,前者负责系统启动和配置管理的 ,后者负责管理和调度其他进程的。
PS:在其他操作系统上,1号进程可能叫init,在CentOS 7之前也叫init,但是在CentOS 7之后就改成systemd,主要是为了解决init进程启动时间长并且脚本复杂等问题。
如果我们在当前操作系统上创建一个容器,进容器查看进程,如下:
# docker run -d --name busybox busybox sleep 3000
b776c8105860a5d46046365ca03b71ec13dac9e1dbe4b8d392e468d49a42020f
# docker exec busybox ps -ef
PID USER TIME COMMAND
1 root :00 sleep 3000
7 root :00 ps -ef
我们可以看到容器里的进程非常干净,并没有外部主机的那些进程。
这就是Pid Namespace的作用。
不同的用户进程就是通过 Pid Namespace进行隔离的,且不同的Namespace中可以有相同的Pid。有了 Pid Namespace,每个Namespace中的Pid能够相互隔离。
所以在Docker容器中,我们可以看到存在Pid=1的进程。但是在主机上,我们查找这个容器,可以发现其进程只是一个普通进程,如下:
# ps -ef | grep b776c8105860
root 2862574 3699 16:20 ? 00:00:00 containerd-shim -namespace moby -workdir /var/lib/docker/containerd/daemon/io.containerd.runtime.v1.linux/moby/b776c8105860a5d46046365ca03b71ec13dac9e1dbe4b8d392e468d49a42020f -address /var/run/docker/containerd/containerd.sock -containerd-binary /usr/bin/containerd -runtime-root /var/run/docker/runtime-runc
root 2866529 2861401 16:21 pts/ 00:00:00 grep --color=auto b776c8105860
如果我们查看所有进程数,可以看到如下关系(删除了很多不必要的信息):
systemd─┬
├─dockerd─┬─containerd─┬
│ │ ├─containerd-shim─┬─sleep
│ │ │ └─10*[{containerd-shim}]
整体的管理逻辑如下: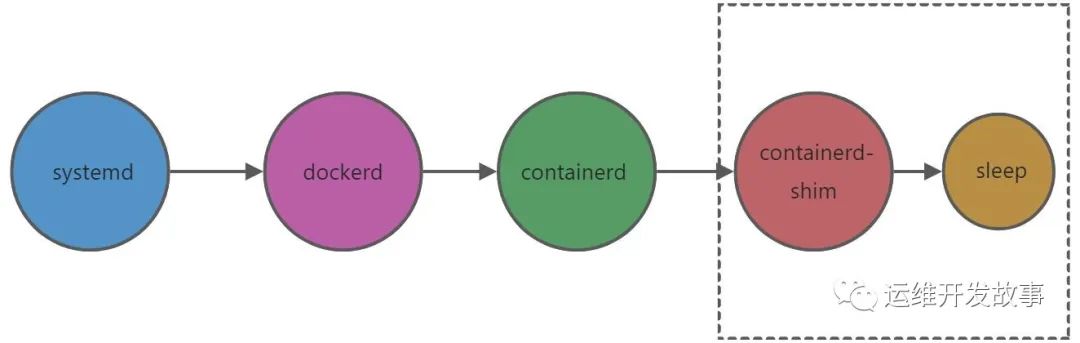
NET Namespace
Docker通过Pid Namespace完成了进程隔离,是每个容器都有单独的进程。
但是,光有进程隔离还不够。每个容器里运行的都是真实的业务应用,业务应用之间需要实现互相访问,就需要每个容器拥有独立的网络,比如独立的网卡、IP地址,路由等。
为了实现上面的需求,Docker就用到了Net Namespace,用它来完成网络隔离。
但是光隔离还不够,终的目的是要完成通信,即容器和宿主机通信、容器和其他主机通信以及容器和互联网通信等。
为了完成终的目标,Docker为我们提供了四种不同的网络模式以满足不同的客户需求:
Host:主机模式,使用主机网络 Container:容器模式,和某个容器共享网络 None:拥有自己的网络空间,但是不配置任何网络信息 Bridge:桥接模式,通过veth桥接到主机上
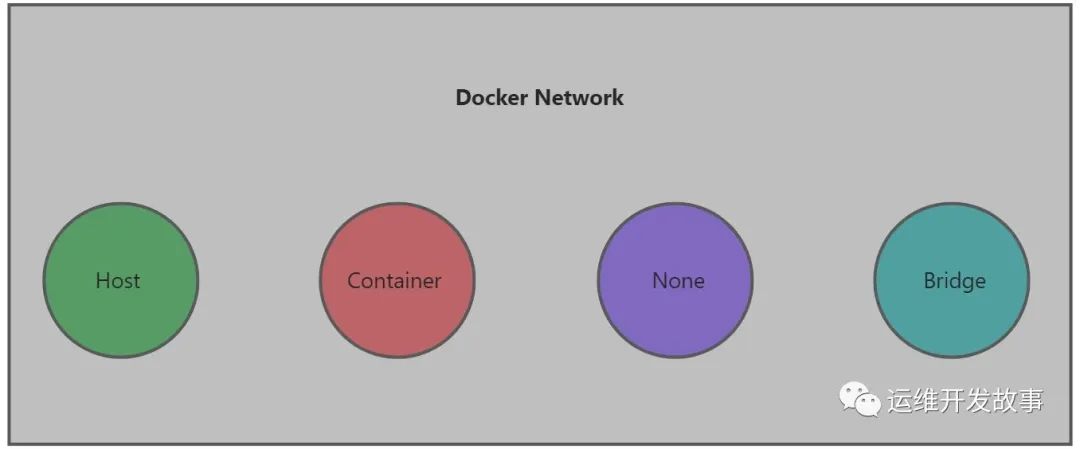
这里只介绍Bridge模式,其他模式现在很少使用,也很少有企业单独使用Docker。
当安装完Docker并启动后,就会在主机上看到一个docker0网桥,它有独立的不同于主机的IP地址,如下:
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:00:e3:77:24 brd ff:ff:ff:ff:ff:ff
inet 10.0.4.9/22 brd 10.0.7.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fee3:7724/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:6f:d4:33:49 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:6fff:fed4:3349/64 scope link
valid_lft forever preferred_lft forever
每当在该主机上启动一个容器,会创建一对虚拟网卡veth设备,其中一端连接到docker0,另一端连接到容器中的网卡(例如eth0)上,并且网关地址是docker0的地址。
虚拟网桥的工作方式和物理交换机的工作方式类似,我们可以把主机当作是一个物理交换机,这样所有容器都通过交换机连接在了一个二层网络。
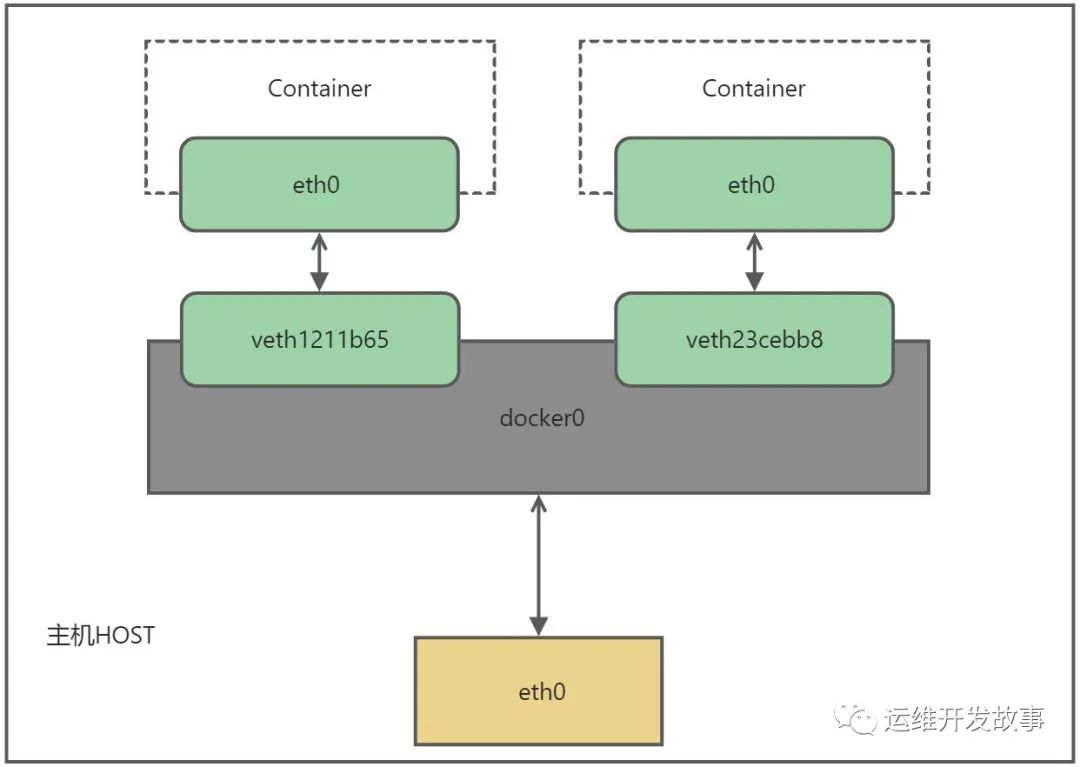
现在每个容器都有自己的IP地址,并且也和主机进行桥接了。我们可以试着在主机上ping容器的IP地址,看是否正常。
# ping 172.17.0.3
PING 172.17.0.3 (172.17.0.3) 56(84) bytes of data.
64 bytes from 172.17.0.3: icmp_seq=1 ttl=64 time=0.056 ms
64 bytes from 172.17.0.3: icmp_seq=2 ttl=64 time=0.056 ms
64 bytes from 172.17.0.3: icmp_seq=3 ttl=64 time=0.041 ms
可以看到正常通信,那具体是怎么通信的呢?
首先docker0和容器网卡eth0是veth对,两个属于直连,是可以直接通信的,那主要问题就在docker0怎么和宿主机通信的。
其实docker0是通过iptables和主机通信的,所有符合条件的的请求都会通过iptables转发到docker0并由网桥分发给对应的容器。
# iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere !loopback/8 ADDRTYPE match dst-type LOCAL
Chain DOCKER (1 references)
target prot opt source destination
RETURN all -- anywhere anywhere
Docker 通过 Linux 的Net命名空间实现了网络的隔离,又通过 iptables 进行数据包转发,让 Docker 容器能够优雅地为宿主机器或者其他容器提供服务。
MNT Namespace
虽然我们已经通过 Linux 的命名空间解决了进程和网络隔离的问题,在 Docker 进程中我们已经没有办法访问宿主机器上的其他进程并且限制了网络的访问,但是 Docker 容器中的进程仍然能够访问或者修改宿主机器上的其他目录,这是我们不希望看到的。
在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统。
如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,所有二进制的执行都必须在这个根文件系统中。?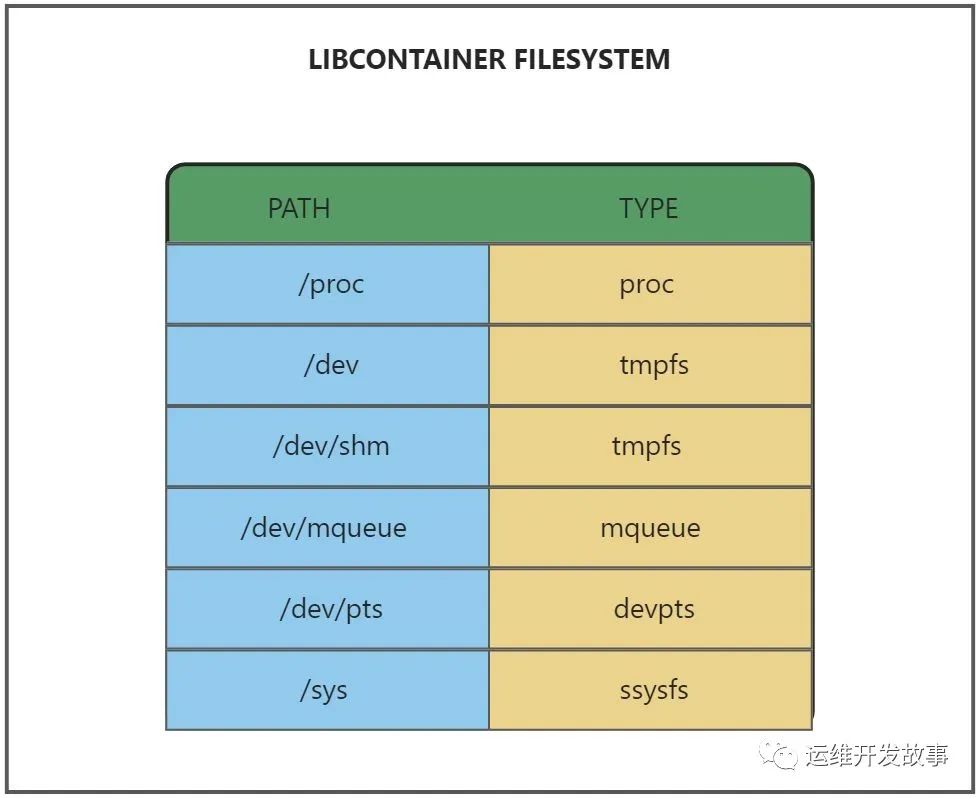
想要正常启动一个容器就需要在 rootfs 中挂载以上的几个特定的目录,除了上述的几个目录需要挂载之外我们还需要建立一些符号链接保证系统 IO 不会出现问题。
为了保证当前的容器进程没有办法访问宿主机器上其他目录,我们在这里还需要通过 libcotainer 提供的 pivor_root 或者 chroot 函数改变进程能够访问个文件目录的根节点。
到这里我们就将容器需要的目录挂载到了容器中,同时也禁止当前的容器进程访问宿主机器上的其他目录,保证了不同文件系统的隔离。
总之,mnt namespace允许不同的namespace看到的文件结构不同,这样每个namespace中的进程所看到的文件目录就被隔离开了。
IPC Namespace
IPC Namespace主要实现进程间通信隔离。
进程间通信涉及的IPC资源包括常见的信号量、消息队列和共享内存。申请IPC就是申请一个全局的32位ID,所以IPC Namespace中实际上包含了系统IPC标识符和实现消息队列的文件系统。
容器的进程间交互依然是采用Linux常见的交互方法,所以每个容器就需要独立的IPC标识符,所以在容器创建的时候就要传入CLONE_NEWIPC 参数,实现IPC资源隔离。
UTS Namespace
UTS(UNIX Time-sharing System)namespace提供了主机名与域名的隔离,这样每个docke容器就可以拥有独立的主机名和域名了,在网络上可以被视为一个独立的节点,而非宿主机上的一个进程。docker中,每个镜像基本都以自身所提供的服务名称来命名镜像的hostname,且不会对宿主机产生任何影响,其原理就是使用了UTS namespace
USER Namespace
user namespace主要隔离了安全相关的标识符(identifier)和属性(attribute),包括用户ID、用户组ID、root目录、key(指密钥)以及特殊权限。通俗地讲,一个普通用户的进程通过clone()创建的新进程在新user namespace中可以拥有不同的用户和用户组。这意味着一个进程在容器外属于一个没有特权的普通用户,但是它创建的容器进程却属于拥有所有权限的超级用户,这个技术为容器提供了极大的自由。
user namespace时目前的6个namespace中后一个支持的,并且直到linux内核3.8版本的时候还未完全实现(还有部分文件系统不支持)。user namespace实际上并不算完全成熟,很多发行版担心安全问题,在编译内核的时候并未开启USER_NS。Docker在1.10版本中对user namespace进行了支持。只要用户在启动Docker daemon的时候制定了–user-remap,那么当用户运行容器时,容器内部的root用户并不等于宿主机的root用户,而是映射到宿主机上的普通用户。
Docker不仅使用了user namespace,还使用了在user namespace中涉及的Capability机制。从内核2.2版本开始,Linux把原来和超级用户相关的权限分为不同的单元,称为Capability。这样管理员就可以独立的对特定的Capability进行使用或禁止。Docker同时使用namespace和Capability,这很大程度上加强了容器的安全性。
CGroups
Docker通过Linux Namespace实现了进程、文件系统、网络等隔离,但是Namespace并不能为其提供物理资源的隔离,比如CPU、Memory等。
如果其中的某一个容器正在执行 CPU 密集型的任务,那么就会影响其他容器中任务的性能与执行效率,导致多个容器相互影响并且抢占资源。如何对多个容器的资源使用进行限制就成了解决进程虚拟资源隔离之后的主要问题,而 Control Groups(简称 CGroups)就是能够隔离宿主机器上的物理资源,例如 CPU、内存等。?
每一个CGroup都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
Linux 的 CGroup 能够为一组进程分配资源,也就是我们在上面提到的 CPU、内存、网络带宽等资源,通过对资源的分配。
Linux 使用文件系统来实现 CGroup,我们可以直接使用下面的命令查看当前的 CGroup 中有哪些子系统:
如果没有lssubsys命令,CentOS可以通过“yum install libcgroup-tools”命令安装。
# lssubsys -m
cpuset /sys/fs/cgroup/cpuset
cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
net_cls,net_prio /sys/fs/cgroup/net_cls,net_prio
blkio /sys/fs/cgroup/blkio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb
pids /sys/fs/cgroup/pids
cpuset:如果是多核心CPU,这个子系统会为CGroup任务分配单独的CPU cpu:使用调度程序为CGroup提供CPU访问 cpuacct:产生CGroup任务的CPU资源报告 memory:设置每个CPU的内存限制以及产生内存资源报告 devices:允许或拒绝CGroup任务对设备的访问 freezer:暂停或恢复CGroup任务 net_cls:标记每个网络包以供CGroup使用 net_prio:针对每个网络接口设置cgroup的访问优先级 blkio:设置限制每个块的输入输出,例如磁盘、光盘以及USB等 perf_event:对CGroup进行性能监控 hugetlb:限制cgroup的huge pages的使用量 pids:限制一个cgroup及其子孙cgroup中的总进程数
大多数 Linux 的发行版都有着非常相似的子系统,而之所以将上面的 cpuset、cpu 等东西称作子系统,是因为它们能够为对应的控制组分配资源并限制资源的使用。
CPU子系统
CPU子系统下主要的文件如下(可以通过ls /sys/fs/cgroup/cpu查看):
| 文件 | 功能 |
|---|---|
| cpu.shares | 顾名思义,shares=分享。它的工作原理非常类似于进程的nice值。shares就代表软限。 |
| cpu.cfs_period_us | 执行检测的周期,默认是100ms |
| cpu.cfs_quota_us | 在一个检测周期内,容器能使用cpu的大时间,该值就是硬限,默认是-1,即不设置硬限 |
| cpu.state | 容器的状态:一共运行了多少个周期;一共被throttle了多少次;一共被throttle了多少时间 |
| cpu.rt_period_us | 执行检测的周期,默认是1s |
| cpu.rt_runtime_us | 在一个检测周期内,能使用的cpu大时间,只作用于rt任务 |
从上面的文件和功能可以看出,CPU的限制有软限制和硬限制。
软限制
软限制是通过设置cpu.shares来实现的。
比如说现在有两个容器,但是只有1颗CPU。当给A容器的cpu.shares配置为512,给B容器的cpu.shares配置为1024,这表示A和B容器使用CPU的时间片比例为1:2,也就是A能用33%的时间片,B能用66%的时间片。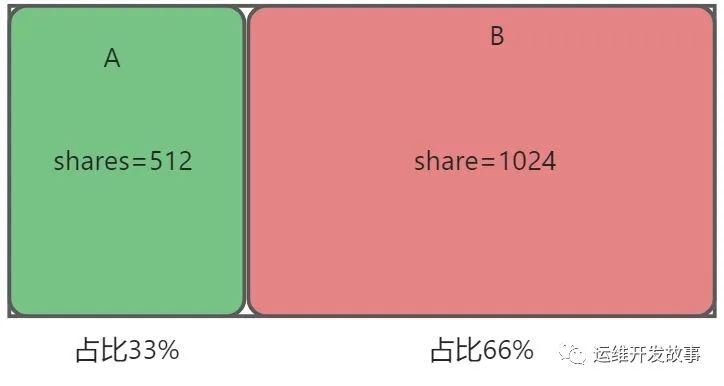
如果把A的shares值改成1024,则A和B的时间片比例就变成了1:1。
cpu.shares有两个特点:
如果A不忙,没有使用到66%的CPU时间,那么剩余的CPU时间将会被系统分配给B,即B的CPU使用率可以超过33% 如果添加了一个新的cgroup C,且它的shares值是1024,那么A的限额变成了1024/(1204+512+1024)=40%,B的变成了20%
由此可以看出:
在闲的时候,shares基本上不起作用,只有在CPU忙的时候起作用,这是一个优点。 由于shares是一个值,需要和其它cgroup的值进行比较才能得到自己的相对限额,而在一个部署很多容器的机器上,cgroup的数量是变化的,所以这个限额也是变化的,自己设置了一个高的值,但别人可能设置了一个更高的值,所以这个功能没法的控制CPU使用率。
硬限制
顾名思义,硬限制就是给你设置一个上限,你永远不能超过这个上限。
硬限制由两个参数控制:
cpu.cfs_period_us:用来配置时间周期长度,单位微秒,默认是100000微妙。 cpu.cfs_quota_us:用来配置当前cgroup在设置的周期长度内所能使用的CPU时间数,单位微秒,取值大于1ms,-1代表不受限制。
如果给cpu.cfs_quota_us设置为100000微秒,则表示限制只能用1个CPU,如果设置为50000微秒,则表示限制只能用0.5个CPU。
CPU核数=cpu.cfs_quota_us / cpu.cfs_period_us。
可以通过一个小实验来直观感受一下。
# 创建工程
mkdir busyloop
cd busyloop
go mod init busyloop
开发一个简单的代码
package main
func main(){
for{}
}
这个代码会启动一个线程,默认也就占用一个CPU。
然后启动项目
go build
./busyloop
使用top命令可以看到使用了一个CPU。
现在我们开始对其进行限制。
# 进入cpu 子系统
cd /sys/fs/cgroup/cpu
# 创建一个busyloop的目录
mkdir busyloop
# 该目录下会自动生成如下文件
ll
total
-rw-r--r-- 1 root root Jun 9 17:19 cgroup.clone_children
--w--w--w- 1 root root Jun 9 17:19 cgroup.event_control
-rw-r--r-- 1 root root Jun 9 17:19 cgroup.procs
-r--r--r-- 1 root root Jun 9 17:19 cpuacct.stat
-rw-r--r-- 1 root root Jun 9 17:19 cpuacct.usage
-r--r--r-- 1 root root Jun 9 17:19 cpuacct.usage_percpu
-rw-r--r-- 1 root root Jun 9 17:19 cpu.cfs_period_us
-rw-r--r-- 1 root root Jun 9 17:19 cpu.cfs_quota_us
-rw-r--r-- 1 root root Jun 9 17:19 cpu.rt_period_us
-rw-r--r-- 1 root root Jun 9 17:19 cpu.rt_runtime_us
-rw-r--r-- 1 root root Jun 9 17:19 cpu.shares
-r--r--r-- 1 root root Jun 9 17:19 cpu.stat
-rw-r--r-- 1 root root Jun 9 17:19 notify_on_release
-rw-r--r-- 1 root root Jun 9 17:19 tasks
# 首先在cgroup.procs中记录busyloop的进程
echo 13817 > cgroup.procs
# 这时候还并为做任何限制,所以CPU使用还是1颗
# 给cpu.cfs_quota_us配置50000微妙,也就是使用.5个CPU
echo 50000 > cpu.cfs_quota_us
这时候通过top命令可以看到busyloop进程使用0.5个CPU。
Memory子系统
Memory子系统用来限制内存的,常用的文件如下。
| 文件 | 功能 |
|---|---|
| memory.usage_in_bytes | cgroup下进程使用的内存 |
| memory.max_usage_in_bytes | cgroup下进程使用内存的大值 |
| memory.limit_in_bytes | 设置cgroup下进程多能使用的内存 |
| memory.soft_limit_in_bytes | 这个限制并不会阻止进程使用超过限额的内存,只是在系统内存足够时,会优先回收超过限额的内存,使之向限定值靠拢 |
| memory.oom_control | 设置是否在 Cgroup 中使用 OOM(Out of Memory)Killer,默认为使用。当属于该 cgroup 的进程使用的内存超过大的限定值时, 会立刻被 OOM Killer 处理。 |
Memory子系统和CPU子系统类似,在配置的时候也是先找到对应的进程,然后在对应的文件众配置额度,这里就不再赘述。
补充:Linux进程调度
Linux Kernel默认提供了5个调度器,Linux Kernel使用struct_sched_class来对调度器进行抽象。
Stop调度器:stop_sched_class,优先级高的调度类,可以抢占其他所有进程,不能被其他进程抢占。 Deadline调度器:dl_sched_class,使用红黑树,把进程按截止期限进行排序,选择小进程进行调度允许。 RT调度器:rt_sched_class,实时调度器,为每个优先级维护一个队列。 CFS调度器:cfs_sched_class,完全公平调度器,采用完全公平调度算法,引入虚拟运行时间的概念。 IDLE-TASK调度器:idle_sched_class,空闲调度器,每个CPU都有一个idle线程,当没有其他进程可以调度时,运行idle线程。
CFS调度器
CFS调度,是Completely Fair Scheduler的简称,即完全公平调度器。
CFS实现的主要思想是维护为任务提供处理器时间方面的平衡,这意味着应给进程分配相当数量的处理器。
当分给某个任务的时间失去平衡时,应该给失去平衡的任务分配时间,让其运行。
CFS通过虚拟运行时间(vruntime)来维护平衡,维护提供给某个任务的时间量。vruntime = 实际运行时间 * 1024 / 进程权重
进程按照各自不同的速率在物理时钟节拍里前进,优先级高则权重大,其虚拟时钟比真实时钟跑的慢,但获得比较多的运行时间。
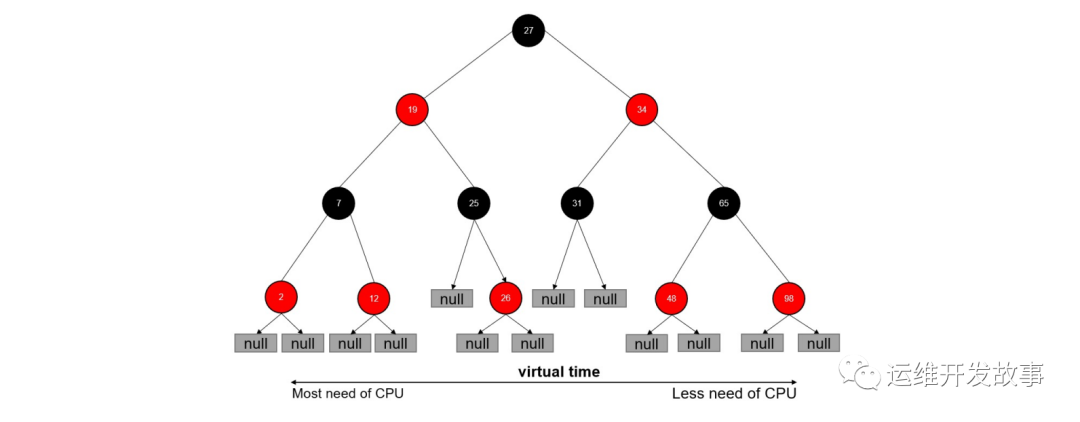
CFS调度器没有将进程维护在运行队列中,而是维护了一个以虚拟时间为顺序的红黑树。红黑树主要特点有两个:
自平衡,树上没有一条路径会比其他路径长出两倍 O(log n) 时间复杂度,能够在树上进行快速高效地插入或删除进程。
UnionFS
UnionFS是Union File System的简称,也就是联合文件系统。
所谓UnionFS就是把不同物理位置的目录合并mount到同一个目录中,然后形成一个虚拟的文件系统。一个典型的应用就是将一张CD/DVD和一个硬盘的目录联合mount在一起,然后用户就可以对这个只读的CD/DVD进行修改了。
Docker就是充分利用UnionFS技术,将镜像设计成分层存储,现在使用的就是OverlayFS文件系统,它是众多UnionFS中的一种。
OverlayFS只有lower和upper两层。顾名思义,upper层在上面,lower层在下面,upper层的优先级高于lower层。
在使用mount挂载overlay文件系统的时候,遵守以下规则。
lower和upper两个目录存在同名文件时,lower的文件将会被隐藏,用户只能看到upper的文件。 lower低优先级的同目录同名文件将会被隐藏。 如果存在同名目录,那么lower和upper目录中的内容将会合并。 当用户修改merge中来自upper的数据时,数据将直接写入upper中原来目录中,删除文件也同理。 当用户修改merge中来自lower的数据时,lower中内容均不会发生任何改变。因为lower是只读的,用户想修改来自lower数据时,overlayfs会首先拷贝一份lower中文件副本到upper中。后续修改或删除将会在upper下的副本中进行,lower中原文件将会被隐藏。 如果某一个目录单纯来自lower或者lower和upper合并,默认无法进行rename系统调用。但是可以通过mv重命名。如果要支持rename,需要CONFIG_OVERLAY_FS_REDIRECT_DIR。
下面以OverlayFS为例,直面感受一下这种文件系统的效果。
系统:CentOS 7.9 Kernel:3.10.0
(1)创建两个目录lower、upper、merge、work四个目录
# # mkdir lower upper work merge
其中:
lower目录用于存放lower层文件upper目录用于存放upper层文件work目录用于存放临时或者间接文件merge目录就是挂载目录
(2)在lower和upper两个目录中都放入一些文件,如下:
# echo "From lower." > lower/common-file
# echo "From upper." > upper/common-file
# echo "From lower." > lower/lower-file
# echo "From upper." > upper/upper-file
# tree
.
├── lower
│ ├── common-file
│ └── lower-file
├── merge
├── upper
│ ├── common-file
│ └── upper-file
└── work
可以看到lower和upper目录中有相同名字的文件common-file,但是他们的内容不一样。
(3)将这两个目录进行挂载,命令如下:
# mount -t overlay -o lowerdir=lower,upperdir=upper,workdir=work overlay merge
挂载的结果如下:
# tree
.
├── lower
│ ├── common-file
│ └── lower-file
├── merge
│ ├── common-file
│ ├── lower-file
│ └── upper-file
├── upper
│ ├── common-file
│ └── upper-file
└── work
└── work
# cat merge/common-file
From upper.
可以看到两者共同目录common-dir内容进行了合并,重复文件common-file为uppderdir中的common-file。
(4)在merge目录中创建一个文件,查看效果
# echo "Add file from merge" > merge/merge-file
# tree
.
├── lower
│ ├── common-file
│ └── lower-file
├── merge
│ ├── common-file
│ ├── lower-file
│ ├── merge-file
│ └── upper-file
├── upper
│ ├── common-file
│ ├── merge-file
│ └── upper-file
└── work
└── work
可以看到lower层没有变化,新增的文件会新增到upper层。
(5)修改merge层的lower-file,效果如下
# echo "update lower file from merge" > merge/lower-file
# tree
.
├── lower
│ ├── common-file
│ └── lower-file
├── merge
│ ├── common-file
│ ├── lower-file
│ ├── merge-file
│ └── upper-file
├── upper
│ ├── common-file
│ ├── lower-file
│ ├── merge-file
│ └── upper-file
└── work
└── work
# cat upper/lower-file
update lower file from merge
# cat lower/lower-file
From lower.
可以看到lower层同样没有变化,所有的修改都发生在upper层。
从上面的实验就可以看到比较有意思的一点:不论上层怎么变,底层都不会变。
Docker镜像怎么实现的
Docker镜像就是存在联合文件系统的,在构建镜像的时候,会一层一层的向上叠加,每一层构建完就不会再改变了,后一层上的任何改变都只会发生在自己的这一层,不会影响前面的镜像层。
我们通过一个例子来进行阐述,如下图。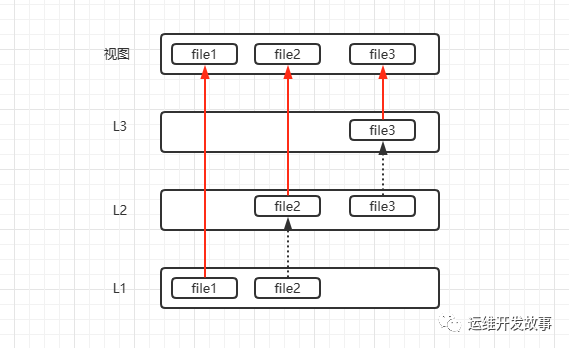 具体如下:
具体如下:
基础L1层有file1和file2两个文件,这两个文件都有具体的内容。 到L2层的时候需要修改file2的文件内容并且增加file3文件。在修改file2文件的时候,系统会先判定这个文件在L1层有没有,从上图可知L1层是有file2文件,这时候就会把file2复制一份到L2层,然后修改L2层的file2文件,这就是用到了联合文件系统 写时复制机制,新增文件也是一样。到L3层修改file3的时候也会使用 写时复制机制,从L2层拷贝file3到L3层 ,然后进行修改。然后我们在视图层看到的file1、file2、file3都是新的文件。
上面的镜像层是死的。当我们运行容器的时候,Docker Daemon还会动态生成一个读写层,用于修改容器里的文件,如下图。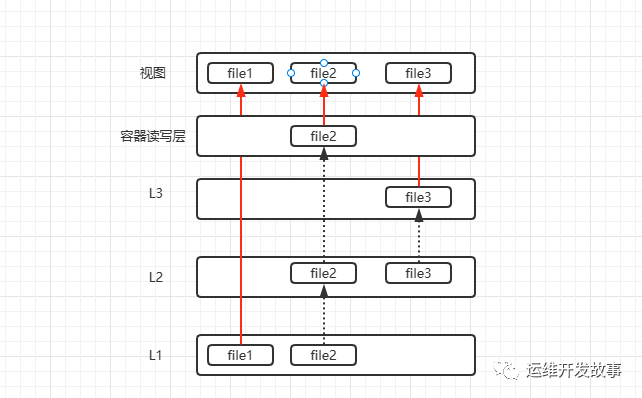 比如我们要修改file2,就会使用
比如我们要修改file2,就会使用写时复制机制将file2复制到读写层,然后进行修改。同样,在容器运行的时候也会有一个视图,当我们把容器停掉以后,视图层就没了,但是读写层依然保留,当我们下次再启动容器的时候,还可以看到上次的修改。
值得一提的是,当我们在删除某个文件的时候,其实并不是真的删除,只是将其标记为删除然后隐藏掉,虽然我们看不到这个文件,实际上这个文件会一直跟随镜像。
Docker的常见操作
Docker现在越来越下沉,甚至很多用户不再使用Docker,在以Kubernetes为中心的容器服务中,Docker不再是必要的选择。
但是作为一款有时代意义的产品,Docker的基本操作对于技术人员来说还是有必要学习和了解的。
Docker的常见指令
Docker分为客户端和服务端,这些常见指令是针对客户端的。
Docker客户端的指令有很多,可以通过docker -h来查看,这里只介绍一些比较常用的指令。
docker build docker ps docker pull docker push docker image docker login docker logs docker exec docker version
Docker镜像的佳实践
认识Dockerfile
Docker的镜像是通过Dockerfile构建出来的,所以Dockerfile的操作是很重要的 。
先通过一个例子来看看Dockerfile是什么样子。
FROM docker.io/centos
LABEL "auth"="joker" \
"mail"="unclejoker520@163.com"
ENV TIME_ZOME Asia/Shanghai
RUN yum install -y gcc gcc-c++ make openssl-devel prce-devel
ADD nginx-1.14.2.tar.gz /opt/
RUN cd /opt/nginx-1.14.2 && \
./configure --prefix=/usr/local/nginx && \
make -j 4 && \
make install
RUN rm -rf /opt/nginx* && \
yum clean all && \
echo "${TIME_ZOME}" > /etc/timezone && \
ln -sf /usr/share/zoneinfo/${TIME_ZOME} /etc/localtime
COPY nginx.conf /usr/local/nginx/conf/
WORKDIR /usr/local/nginx/
EXPOSE 80
CMD ["./sbin/nginx","-g","daemon off;"]
其中FROM指令必须是开篇个非注释行,是必须存在的一个指令,后面所有的操作都是基于这个镜像的。后面的指令就是一些操作指令,指令的详情在后面介绍。后是CMD指定,这个指令表示在容器运行是需要执行的命令。
当定义好Dockerfile,然后使用docker build命令就可以将起构建成Docker镜像。
Dockerfile常用指令
| 指令 | 说明 |
|---|---|
| FROM | 指定基础镜像 |
| LABEL | 指定标签 |
| COPY | 复制文件到镜像中 |
| ADD | 添加文件到镜像中,如果是压缩文件会自动解压 |
| WORKDIR | 指定工作目录,进入容器的时候默认就在工作目录中 |
| ENV | 指定环境变量 |
| RUN | 指定运行的命令 |
| ENTRYPOINT | 指定容器启动时运行的命令,可以接CMD命令 |
| CMD | 指定容器启动时运行的命令,可被覆盖 |
| ARG | 指定参数,一般在Build的时候使用 |
| EXPOSE | 暴露容器端口 |
| VOLUME | 在容器中创建挂载点 |
| USER | 指定运行用户 |
佳实践
只会Dockerfile的命令是不够的,有时候你会发现为什么别人的镜像那么小,为什么别人构建镜像那么快。这其中是有一些技巧的。
优化构建上下文
什么是构建上下文?
当执行docker build的时候,执行该命令所在的工作目录就是构建上下文。
为什么要优化构建上下文呢?
当执行docker build构建镜像的时候,会把当前工作目录下的所有东西都加载到docker daemon中,如果没有对上下文进行优化,可能导致构建时间长,构建所需资源多,构建镜像大等问题。
应该如何优化呢?
1、创建单独的目录存放Dockerfile,保持该目录整洁干净。
2、如果没有办法把Dockerfile单独存放到某个目录,可以通过在Dockerfile所在目录中添加.dockeringnore文件,在该文件中把不需要的文件填写进去,这样在加载上下文的时候就会把这些文件排除出去。
合理利用缓存
docker在构建镜像的时候,会依次读取Dockerfile中的指令并按顺序依次执行。在读取指令的过程中,会去判断缓存中是否有已存在的镜像,如果存在就不会再执行构建,而是直接使用缓存,这样会加快构建速度。
合理利用缓存,可以加快构建速度,所以在编写Dockerfile的时候把不会改变的指令放到前面,让起尽可能的使用到缓存。
注意:如果某一层得缓存失效,后续的所有缓存都会失效。
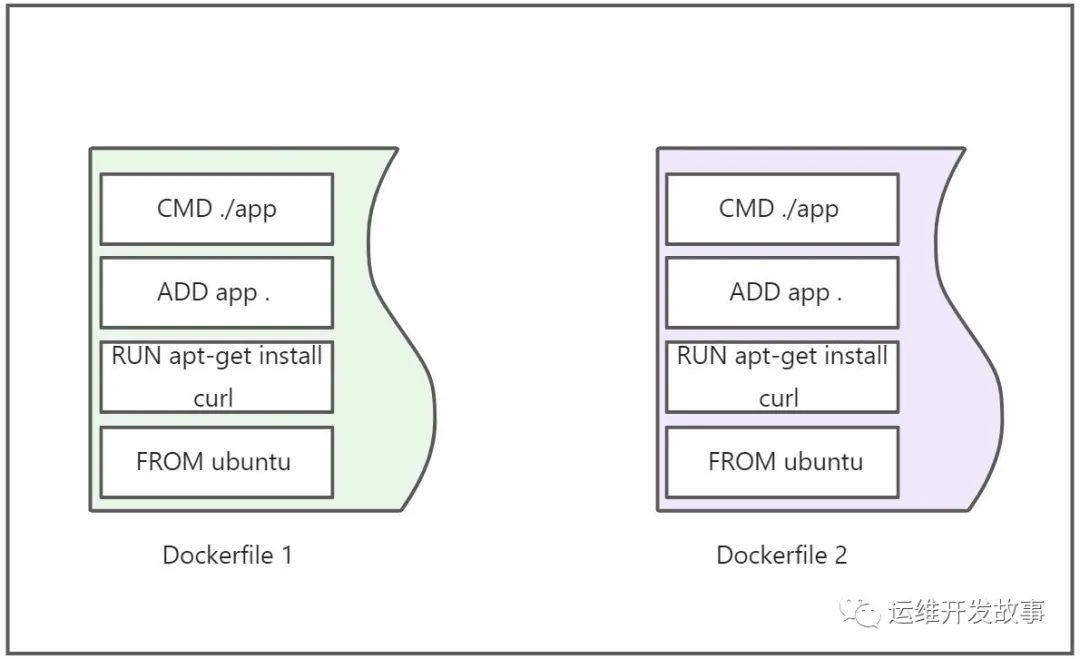
上图Dockerfile1和Dockerfile2分别为app1和app2制作镜像,通过这两个Dockerfile来介绍一下缓存是怎么用的。
(1)FROM 指令代表的是基础镜像,app1和app2都是用的同一个,所以在打包的时候,如果本地存在该镜像,就不会到dockerhub上拉取了。
(2)RUN指令执行的是定义的命令,docker会对比命令是否一样,如果一样就直接使用缓存。
(3)ADD指令是拷贝用户文件到镜像中,docker会判断该镜像每一个文件的内容并生成一个checksum,与现存镜像进行比较,如果checksum一致则使用缓存,否则缓存就失效。
合理的优化镜像体积
Docker的镜像是会在服务器与服务器之间、服务器和镜像仓库之间来回传递,如果镜像太大不仅影响传输速度、还占用服务器主机资源,所以合理的优化镜像体积有助于提升效率。
目前可以通过以下方法来优化镜像体积:
(1)选用较小的基础镜像
(2)删除不必要的软件包
合理优化镜像层数
镜像的层级越多,镜像的体积相对来说也会越大,而且项目的可维护性越低,目前Docker只有RUN、ADD、COPY这三个命令会创建层级,所以优化镜像层数主要是合理使用这三个命令。
目前通用的解决办法是:
(1)合并命令。如果一个Dokcerfile中有多个RUN命令,可以将它们合并成一个RUN。
(2)使用多阶段构建,减少不必要的层级。
合理选择初始化进程
如果一个镜像无法避免使用多进程,那么就应该合理的选择初始化进程。
初始化进程有有以下要求:
能够捕获SIGTERM信号,并完成子进程的优雅终止 能够完成子进程的清退,避免产生僵尸进程
tini项目可以解决上面的问题,在选择初始化进程的时候可以考虑一下。
Containerd
Containerd是从Docker中分离的一个项目,旨在为Kubernetes提供容器运行时,负责管理镜像和容器的生命周期。
在kubernetes1.20后会逐步移除docker,不过现在docker和containerd都可以同时为Kubernetes提供运行时。
如果是docker作为容器运行时,则调用关系是kubelet-->docker-shim-->dockerd-->containerd 如果是containerd作为容器运行时,则调用关系是kubelet-->cri-plugin-->containerd
可以看出containerd的调用链路比docker要短,但是相对的功能没有docker丰富。
下面列举Containerd和Docker的命令差别,其他的其实用到的也不多,基本都是Kubernetes自己去调用。
镜像相关
| 镜像相关功能 | Docker | Containerd |
|---|---|---|
| 显示本地镜像列表 | docker images | crictl images |
| 下载镜像 | docker pull | crictl pull |
| 上传镜像 | docker push | 无 |
| 删除本地镜像 | docker rmi | crictl rmi |
| 查看镜像详情 | docker inspect IMAGE-ID | crictl inspecti IMAGE-ID |
容器相关
| 容器相关功能 | Docker | Containerd |
|---|---|---|
| 显示容器列表 | docker ps | crictl ps |
| 创建容器 | docker create | crictl create |
| 启动容器 | docker start | crictl start |
| 停止容器 | docker stop | crictl stop |
| 删除容器 | docker rm | crictl rm |
| 查看容器详情 | docker inspect | crictl inspect |
| attach | docker attach | crictl attach |
| exec | docker exec | crictl exec |
| logs | docker logs | crictl logs |
| stats | docker stats | crictl stats |
Pod相关
| POD 相关功能 | Docker | Containerd |
|---|---|---|
| 显示 POD 列表 | 无 | crictl pods |
| 查看 POD 详情 | 无 | crictl inspectp |
| 运行 POD | 无 | crictl runp |
| 停止 POD | 无 | crictl stopp |
总结
Docker公司虽然没有在后的决战中胜出,但是Docker产品不失为一个好产品,它在整个云原生领域有着举足轻重的作用。
(1)它做到了镜像一次编译,随时使用
(2)可以一键启动依赖服务,搭建环境的成本降低
(3)可以保持所有环境高度一致
(4)它可以达到秒级启动
但是Docker也有其与生俱来的缺点,比如由于主机上的容器都是共用的底层操作系统,其隔离性不如真正的硬件隔离,而且随着并发的不断增大,也会因一些网络连接和数据交互等问题产生性能瓶颈。
而且随着容器的不断发展,越来越多的容器运行时诞生,Docker在整个领域的地位会不断下降,它不再是大家必须的选择。
参考
https://developer.aliyun.com/article/775778 https://blog.csdn.net/crazymakercircle/article/details/120747767 https://github.com/krallin/tini
