定位
LevelDB 是 Google 开源的一款 KV 数据库存储引擎,支持持久化存储,key 和 value 都是任意的字节数组(byte arrays),提供了基本的 Put()、Delete()、Get() 操作接口。
系统结构
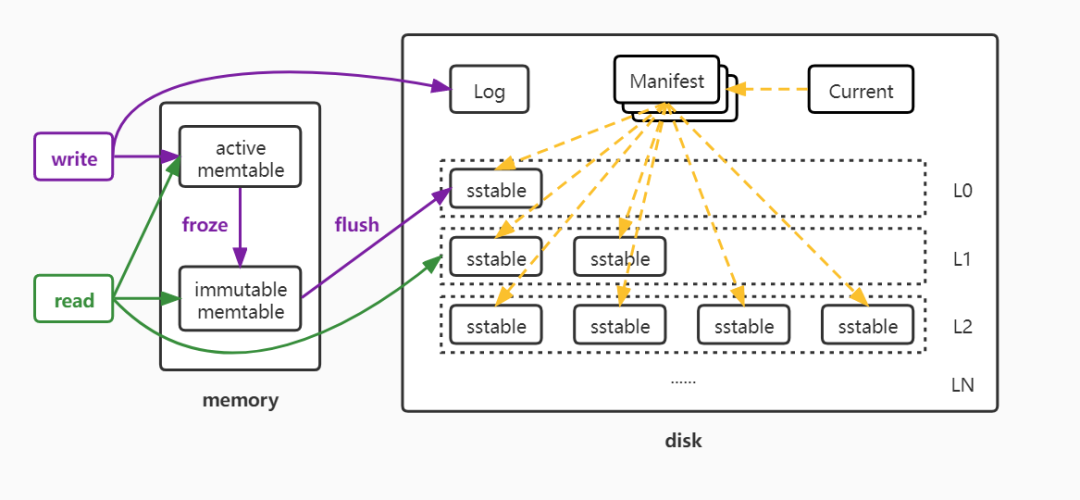
LevelDB 用 memtable(active memtable)、immutable memtable 在内存中保存数据内容,用 sstable(Sorted String Table)在磁盘中保存数据内容。memtable、immutable memtable、sstable 内部存储的数据都按照 key 有序排列。
memtable 内部用跳表来实现,保存的是近写入的数据。当 memtable 达到一定大小后,就会转化成 immutable memtable,同时生成新的 memtable。immutable memtable 则会异步地刷写到硬盘中,转化为 sstable。sstable 在磁盘中有很多个,按照 LSM-Tree 的方式组织起来:分为 L0 到 LN 多层,每一层包含多个 sstable 文件;单层 sstable 文件总量随层次增加成倍增长;其中 L0 的 sstable 文件由 immutable memtable 直接 dump(转储)产生,其他 Level 的 sstable 文件由其上一层的文件和本层文件归并产生; sstable 文件在归并过程中顺序写生成,生成后仅可能在之后的归并中被删除,而不会有任何的修改操作。
Log 中记录的是对数据库进行更新的操作,如果发生故障,可以根据日志恢复数据。
Manifest 文件中记录的是 sstable 文件在不同 Level 的分布、单个 sstable 文件的大 key 和小 key,以及 LevelDB 需要的其他的一些元信息。Manifest 文件可能有多个,LevelDB 启动的时候需要找到当前有效的那个 Manifest 文件,以获取对应的元信息。Current 文件中记录的就是当前有效的 Manifest 的文件名,LevelDB 以此判断 Manifest 文件的有效性。
写入数据
接收到写入请求,LevelDB 首先会以追加的方式把操作记录写入日志中(WAL,Write-ahead logging,预写式日志),再把数据内容写入 memtable —— 通过这样处理,如果 LevelDB 发生故障重启,哪怕还没有转存到 sstable 的内存中的数据也能够通过日志恢复。注意,Log 中记录的是操作,memtable 中记录的是数据内容。
写入请求除了新增记录,还包括更新和删除记录。对于更新和删除,LSM-Tree 用的是追加一条新记录的方式,而不是直接修改、删除已有的数据。这样能够把随机写转换为顺序写。对于机械硬盘,把随机写转换为顺序写能够带来巨大的性能提升,但是也因为过期数据的留存,占用了额外的空间,造成了空间放大的问题(真正占用的空间大于有效数据实际需要的空间)。
读取数据
LevelDB 中新的数据是在 memtable 里,其次是在 immutable memtable、L0 层的 sstable,旧的数据是在 LSM-Tree 下层的 sstable 里。根据局部性原理,刚写入的数据很有可能被马上读取。所以,读取数据时,会依次检索内存中的 memtable、immutable memtable,看是否有对应的 key;如果内存无法命中,再遍历 L0 层的 sstable 进行查找;如果还没有命中,就在 L1 和更下层的 sstable 中逐层查找对应的数据。因为这样一层一层地查找,整个过程可能需要多次 IO,造成读放大的问题(实际读取的数据量大于真正需要的数据量)。
为了加快 sstable 的读取,可以通过建立缓存以及布隆过滤器来加快 key 的查找。布隆过滤器(Bloom Filter)用来快速判断一个元素是否在集合中,基本思想是通过 Hash 函数把一个 key 映射成位阵列(Bit Array)中的一个比特位,以比特位的 0/1 作为集合中是否存在对应元素的标记。如果布隆过滤器判断集合中不存在对应的元素,就可以直接跳过集合,避免的检索。
合并 sstable
LevelDB(LSM-Tree)在后台有一套合并 sstable 文件的机制:当 L0 层的 sstable 达到一定阈值之后,会与 L1 层的 sstable 合并;当 L1 层的 sstable 到达阈值后,又会与 L2 层的 sstable 合并,向下逐层合并。合并过程可以异步进行,不会阻塞写操作。
合并 sstable 的目的,是为了减少 sstable 文件的数量、清理过期的数据,以减少空间放大和读放大。但是,合并 sstable 又会带来写放大的问题(写入数据时实际写入的数据量大于真正有效的数据量)。不同于 HDD,SSD 的可写入次数有限,在 SSD 上,如果写放大严重,会在很大程度上缩短 SSD 的寿命。
适用场景
得益于把随机写转化为顺序写,LevelDB 在顺序写和随机写上都有很好的性能表现。因为 sstable 内部有序,LevelDB 也有很高顺序读的性能,但是随机读的性能很一般。总体来说,LevelDB 适合用在写入多、读取少的场景。
来自:https://mp.weixin.qq.com/s/j32jSIAzN61lOJ_sXCaSKg
