导语:本文介绍boltdb的用法,并对比了并发写数据时Update和Batch的区别。
简介
boltdb是参考LMDB(Lightning Memory-Mapped Database),纯用golang实现的KV数据库。boltdb提供基本的存储功能,并不支持网络连接,不支持复杂的SQL查询。单个数据库数据存储在单个文件里,通过API的方式对数据文件读写,达到数据持久化的效果。
适用场景
1. 程序需要内嵌数据库,比如ETCD。
2. 只需要简单的键值存储或查询,不需要复杂的SQL查询。
3. 需要支持事务。
4. 读多写少的场景。
基本概念
DB:数据库,对应一个数据文件。
Bucket:桶,boltdb组织数据的基本方式,即数据的命名空间。桶是可以嵌套在另一个桶里的,比方说一个打工人联盟/程序猿/TenzT的key,就在程序猿这个Bucket里,而程序猿这个Bucket又在打工人联盟这个Bucket里。相比Redis平铺的键值对,这种树状的结构能够满足更多不同的业务场景。
Transaction:事务,数据的读写操作发生在事务中。为了实现并发读写,每个事务会对数据形成一份独立的“视图”,在同一事务里所看到的数据是一致的。boltdb提供两种事务:
1. 读写事务(Read-write transactions):可以对数据库的数据进行查询、插入、更新、删除操作。
2. 读事务(Read-only transactions):只读事务只能在事务里查询数据。
boltdb对并发读写的支持与读写锁达到的效果相似,同一时刻允许多个goroutine读数据,但一次只允许一个goroutine写数据。在后续的文章里会对boltdb的读写过程进行分析。
基本操作
打开数据库
前文提到,一个数据库对应一个数据文件,boltdb使用Open API打开一个数据库,打开文件时所用的flag为os.O_CREATE,当数据文件不存在时会创建。这个API本身就散发着浓浓的文件操作的气息。
// boltdb/basic_op/overview/main.godb, err := bolt.Open("my.db", 0600, nil)
另外,boltdb会对所打开的文件加锁,单个时刻只允许一个进程访问文件,尝试打开已经被打开的数据文件操作会被阻塞,可以在DB选项里加上等待超时时间。
db, err := bolt.Open("my.db", 0600, &bolt.Options{Timeout: 1 * time.Second})
基本读写操作
boltdb提供Update和View两个事务API,前者用于读写,后者用于读。两个API的入参都是一个回调函数,包含数据的Upsert或查询操作。
// boltdb/basic_op/overview/main.godb.Update(func(tx *bolt.Tx) error {// 创建桶b, err := tx.CreateBucketIfNotExists([]byte("ClumsyTenz"))if err != nil {return err}// 插入数据err = b.Put([]byte("answer1"), []byte("42"))err = b.Put([]byte("answer2"), []byte("43"))return err})var answer1 stringvar answer2 stringdb.View(func(tx *bolt.Tx) error {// 获取Bucketb := tx.Bucket([]byte("ClumsyTenz"))v := b.Get([]byte("answer1"))answer1 = string(v)v = b.Get([]byte("answer2"))answer2 = string(v)return nil})
查看Update API的实现,用过Mysql等RDBMS的同学一眼就看到了begin...rollback/commit的逻辑(如下面的代码)。所以说事务Transaction是读写操作的上下文,而boltdb本身也支持利用这几个API手动管理事务达到相同的效果。
func (db *DB) Update(fn func(*Tx) error) error {// 开启事务t, err := db.Begin(true)if err != nil {return err}...// 调用包含读写操作的回调函数err = fn(t)t.managed = falseif err != nil {// 处理有问题则回滚_ = t.Rollback()return err}// 提交事务return t.Commit()}
使用Batch事务优化并发写操作
数据文件是存在磁盘里的,一般情况下CPU只跟内存打交道,内存中的数据只是磁盘的一份“缓存”。内存中被修改过的数据(脏页)需要刷新到磁盘来保持一致,即落盘。
boltdb在每一次Update事务提交后都进行一次落盘操作,当遇到并发写时,会产生频繁的磁盘IO,且后续的goroutine会被阻塞直到上一次的Update事务落盘完成。为了提高并发写能力,boltdb提供了Batch API做优化,其实现原理是对一批Update事务聚合之后再统一落盘,减少磁盘IO。
用下面的测试代码对两个API进行对比
startTime := time.Now()testCount := 1000 // 开启testCount个写协程wg := sync.WaitGroup{}wg.Add(testCount)for i := ; i < testCount; i++ {go func(i int, group *sync.WaitGroup) {// 改成db.Batch用于测试Batch APIdb.Update(func(tx *bolt.Tx) error {b := tx.Bucket([]byte("ClumsyTenz"))err := b.Put([]byte(strconv.Itoa(i)), []byte(""))return err})group.Done()}(i, &wg)}// 主协程阻塞等待写协程执行完成wg.Wait()fmt.Printf("time cost = %v\n", time.Since(startTime))
对比测试结果,同样是1000个写操作,Batch操作所需用时(17.45ms)远比Update操作所需用时(14.72s)少。
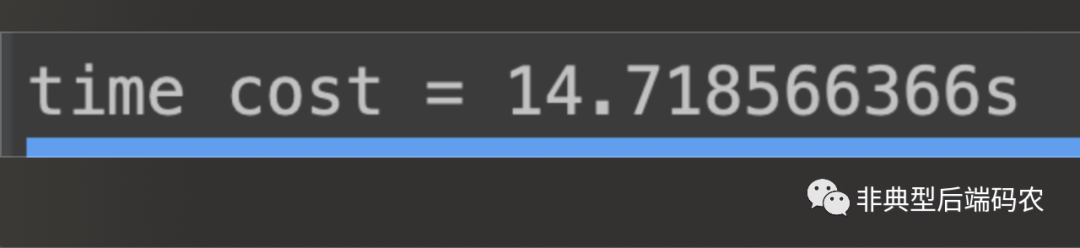
Update用时
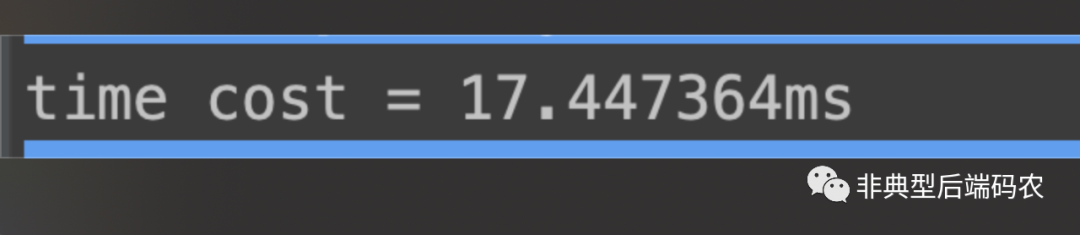
Batch用时
观察IO负载,发现Update操作下因频繁落盘会形成IO Burst,而Batch操作带来的IO写负载则一直是这么低且稳。
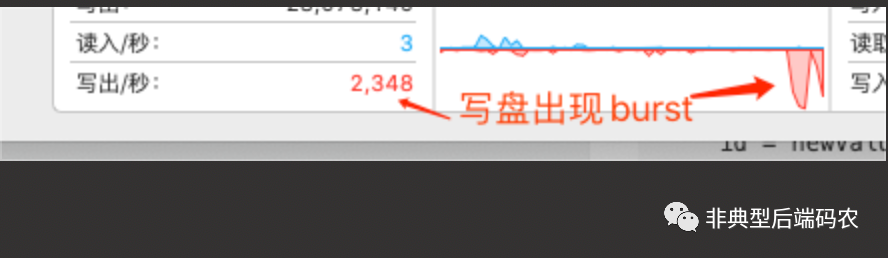
Update写负载
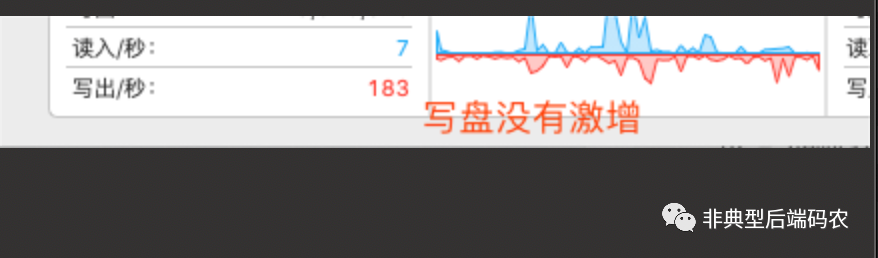
Batch写负载
后测试下开启10000个写协程的Batch操作,依然完爆Update操作(伤害不大,侮辱性极强hhhhh)。

Batch用时

Batch写负载
为什么选择boltdb进行分析
1. 麻雀虽小,五脏俱全:数据库基本的功能是对数据进行存储和检索,存储涉及到数据的存储和解析,依赖物理布局;如何快速检索涉及索引的选择设计。boltdb在这两点上都有实现,且令人惊喜的是还提供了事务的实现,对于想学习数据库的同学来说实属良品。
2. 代码量少:源代码只有3k行左右。
3. 纯golang实现:相比cpp实现的mysql,自带gc的golang让人更专注于DB设计本身而不用在细节上费力(BTW我好像好多年没写过CPP了,看不懂也不会写了TAT)。
在后续的文章里,会陆续对物理分布、索引、CRUD和ACID等源码细节进行分析,年前先更新到这里了。
后,祝各位新年大吉,事事顺心,一夜暴富吧嘿嘿。
本文的所有代码示例来源于
https://gitee.com/TenzT/go-lab
