在这篇文章中,我们讨论了用于流处理的窗口的概念,介绍Flink的内置窗口,并解释它对自定义窗口语义的支持。
一、什么是窗口?窗口有什么用?
考虑一个交通传感器的例子,它每15秒计算一次通过某个位置的车辆数量。生成的流可能如下所示:

如果我们想知道,有多少车辆通过了该位置,可以简单地将单个计数相加。然而,传感器流的本质是不断地产生数据。这样的流永远不会结束,并且不可能计算出可以返回的终和。相反,可以计算滚动和,即,为每个输入事件返回一个更新的总和记录。这将产生一个新的部分和流。这将产生一个新流,其元素是一部分一部分的计数和。
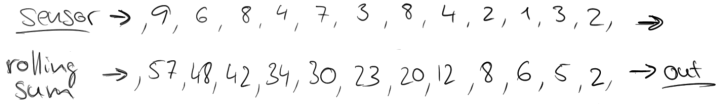
然而,部分计数和的流可能不是我们想要的,因为它不断更新计数,甚至更重要的是,一些信息,如随时间的变化,会丢失。因此,我们可以重新表述我们的问题,即“每分钟经过该位置的汽车数量”。这要求我们将流的元素分组为有限集,每个集合对应60秒。此操作称为“翻窗操作(tumbling windows)”。

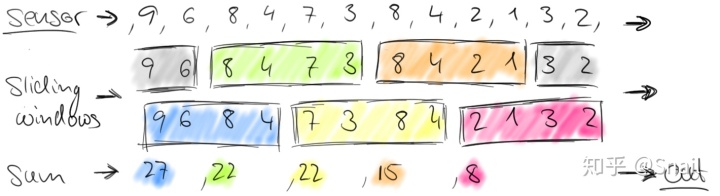
翻滚窗口将流离散化为不重叠的窗口。但对于某些应用程序,可能需要平滑的聚合。例如,我们可以“每三十秒计算后一分钟通过的汽车数量”。这样的窗口叫做“滑动窗口(sliding windows)”。
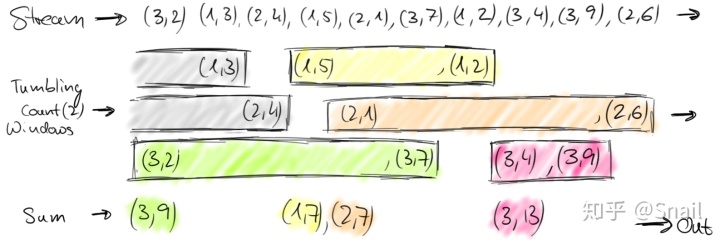
如前所述,在数据流上定义窗口是一种非并行操作。这是因为流的每个元素都必须由相同的窗口操作符处理,该操作符决定元素应该添加到哪个窗口。一个满流(full stream)中的窗口在Flink中称为"AllWindows"。对于许多应用程序,需要将数据流分组为多个逻辑流,每个逻辑流上可以应用一个窗口操作符。例如,考虑来自多个交通传感器的车辆计数流(而不是像我们前面的示例中那样只有一个传感器),其中每个传感器监视不同的位置。通过按传感器id分组流,我们可以并行计算每个位置的加窗流量统计。在Flink中,我们简单地将这种分区窗口称为"Windows",因为它们是分布式流的常见情况。下图显示了在一个(sensorId, count)对元素流上收集两个元素的翻转窗口。
一般来说,一个窗口定义了一个无界流上的有限元素集。这个集合可以基于时间(如我们前面的示例所示)、元素计数、计数和时间的组合,或者一些将元素分配到窗口的自定义逻辑。
Flink的DataStream API为常见的窗口操作提供了简洁的操作符,并提供了一种通用的窗口机制,允许用户定义完全定制的窗口逻辑。在下面,我们先介绍Flink的时间和窗口计数,然后再详细讨论它的窗口机制。
二、时间窗口
顾名思义,时间窗口按时间对流元素进行分组。例如,一个一分钟的翻滚时间窗口收集一分钟的元素,并在一分钟后对窗口中的所有元素应用一个函数。
在Apache Flink中定义翻滚和滑动时间窗口非常简单:
// (sensorId, carCnt)元素流
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// 按传感器ID sensorId分组的keyd stream
.keyBy(0)
// 1分钟长度的翻滚窗口
.timeWindow(Time.minutes(1))
// 在carCnt上求和
.sum(1)
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// 滑动窗口,1分钟的时长,30秒的触发周期
.timeWindow(Time.minutes(1), Time.seconds(30))
.sum(1)有一个方面我们还没有讨论,即“收集元素一分钟”的确切含义归结为一个问题:“流处理器如何解释时间?”
Apache Flink提供了三种不同的时间概念,即处理时间(processing time)、事件时间(event time)和摄入时间(ingestion time)。
1)在处理时间中,窗口是根据构建和处理窗口的机器的挂钟来定义的,即,一分钟处理时间意味着窗口收集元素的时间正好为一分钟。
2)在事件时间中,窗口是根据附加到每个事件记录的时间戳来定义的。这对于许多类型的事件都很常见,比如日志条目、传感器数据等,其中时间戳通常表示事件发生的时间。与处理时间相比,事件时间有几个优点。首先,将程序语义与源的实际服务速度和系统的处理性能解耦。因此,您可以处理以大速度提供的历史数据,并使用相同的程序连续生成数据。它还可以防止在背压或故障恢复延迟情况下出现语义上不正确的结果。其次,事件时间窗口计算正确的结果,即使事件到达的时间戳顺序不一致,而这种不一致在数据流从分布式源收集事件时很常见。
3)摄入时间是处理时间和事件时间的混合。它在记录到达系统(在源)时立即将挂钟时间戳分配给它们,并根据附加的时间戳使用事件时间语义持续进行处理。
三、计数窗口
Apache Flink还提供了计数窗口。翻滚计数窗口为100,它将在一个窗口中收集100个事件,并在添加第100个元素时计算该窗口的值。
在Flink的DataStream API中,翻滚和滑动计数窗口定义如下:
// (sensorId, carCnt)元素流
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// 按sensorId分组的keyed stream
.keyBy(0)
// 100个元素大小的滚动窗口
.countWindow(100)
// 计算carCnt 和
.sum(1)
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// 滑动计数窗口,100个元素大小,10个元素的触发间隔
.countWindow(100, 10)
.sum(1)四、剖析Flink的窗口机制
Flink的内置时间和计数窗口涵盖了广泛的普通窗口用例。但是,仍然会存在Flink的内置窗口无法解决这个问题,这时有一些应用程序需要自定义窗口逻辑。为了支持需要特定的窗口语义的应用程序,DataStream API公开了其窗口机制的内部接口。这些接口为构建和计算窗口的方式提供了非常细粒度的控制。
下图描述了Flink的窗口机制,并介绍了所涉及的组件。
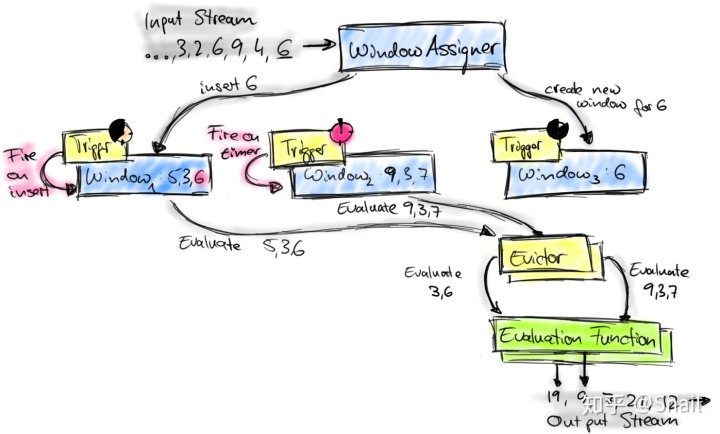
到达窗口操作符的元素被传递给WindowAssigner。WindowAssigner将元素分配给一个或多个窗口,可能会创建新的窗口。窗口(Window)本身只是一个元素列表的标识符,它可以提供一些可选的元信息,比如TimeWindow的开始和结束时间。请注意,一个元素可以添加到多个窗口,这也意味着多个窗口可以同时存在。
每个窗口都有一个触发器,该触发器决定何时计算或清除窗口。当先前注册的计时器超时时,将为插入窗口的每个元素调用触发器。在每个事件上,一个触发器可以决定触发(即触发)。清除(移除窗口并丢弃其内容),或触发然后清除窗口。
一个触发器只是触发计算窗口,并保持它的原样,即,所有元素都保留在窗口中,并在下一次触发触发器时再次计算。一个窗口可以被计算几次,并一直存在,直到它被清除。请注意,在清除窗口之前,它将消耗内存。
当触发器触发时,可以将窗口元素列表提供给可选的回收器(Evictor)。Evictor可以遍历列表并决定从列表的开始处删除一些元素,即,删除首先进入窗口的一些元素。其余的元素被赋给一个求值函数。如果没有定义Evictor,则触发器将所有窗口元素直接交给求值函数。
求值函数接收窗口的元素(可能由Evictor筛选),并为窗口计算一个或多个结果元素。DataStream API接受不同类型的计算函数,包括预定义的聚合函数,如sum()、min()、max(),以及ReduceFunction、FoldFunction或WindowFunction。
这些是组成Flink窗口机制的组件。现在,我们将逐步展示如何使用DataStream API实现自定义窗口逻辑。我们从一个类型为DataStream[IN]的流开始,然后使用一个key选择器函数对它进行key选择,该函数提取一个类型为KEY的键来获得一个KeyedStream[IN, KEY]。
val input: DataStream[IN] = ...
// 使用一个key选择器函数来创建一个keyed stream
val keyed: KeyedStream[IN, KEY] = input.keyBy(myKeySel: (IN) => KEY)我们应用一个WindowAssigner[IN, WINDOW]来创建WINDOW类型的窗口,结果产生一个WindowedStream[IN, KEY, WINDOW]。此外,WindowAssigner还提供了一个默认的触发器(Trigger)实现。
// 使用一个WindowAssigner创建窗口流
var windowed: WindowedStream[IN, KEY, WINDOW] = keyed.window(myAssigner: WindowAssigner[IN, WINDOW])我们可以显式地指定一个触发器来覆盖WindowAssigner提供的默认触发器。请注意,指定触发器并不会添加额外的触发器条件,而是替换当前触发器。
// 覆盖WindowAssigner的默认触发器
windowed = windowed.trigger(myTrigger: Trigger[IN, WINDOW])我们可能需要指定一个可选的回收器(Evictor),如下所示。
// 指定一个可选的回收器
windowed = windowed.evictor(myEvictor: Evictor[IN, WINDOW])后,我们应用一个WindowFunctio,该函数返回类型为OUT的元素,以获得一个DataStream[OUT]。
// 将窗口函数应用到窗口流
val output: DataStream[OUT] = windowed.apply(myWinFunc: WindowFunction[IN, OUT, KEY, WINDOW])通过Flink的内部窗口机制及其通过DataStream API的公开,可以实现非常自定义的窗口逻辑,如会话窗口或在值超过某个阈值时发出早期结果的窗口。
五、小结
Flink为常见用例提供了预定义的窗口操作符,并提供了一个工具箱,允许定义非常自定义的窗口逻辑。
