知识图谱数据库是NoSQL数据库中增速快的一个分支,它在大数据和人工智能领域的地位逐渐凸显。但是目前主流的图数据库产品大都属于海外产品,且售价极其高昂,为了解各大主流图数据库的读写性能指标,特将国产的新兴图数据库AbutionGraph(AbutionGDB)与Neo4j,JanusGraph,TigerGraph等占据着市场95%份额的主流图数据库做了读写性能对比测试。特别说明:AbutionGDB是面向OLAP(数据分析决策)场景的实时动态图数据仓库,而其它对比者是面向OLTP(数据增删改查)的图数据库,不过这并不影响读写性能的测试。
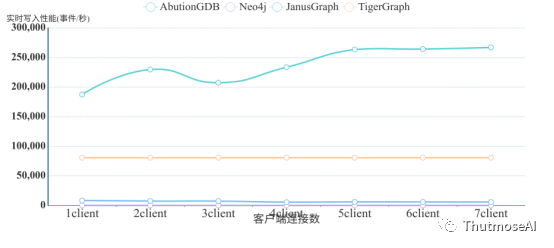
表 1实时批量写入事件数性能测试结果
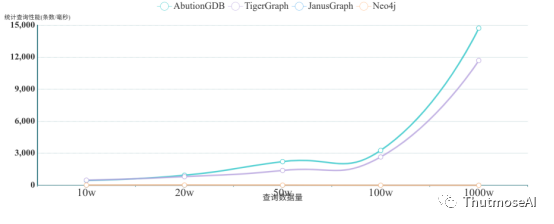
表 2 一度关系统计查询性能测试
目录
1.测试用数据说明
测试采用的数据来源于互联网的消费/转账记录模拟数据,每行记录包含6个字段,分别是:付款方帐号(4bytes长整型)、付款方名字(11bytes字符串)、收款方帐号(4bytes长整型)、收款方名字(11bytes字符串)、交易时间(7bytes日期类型)、交易金额(8bytesBigdicemal双精度浮点数),数据长度低是45bytes,因为交易金额的长度是个不确定的值。数据样例如下:
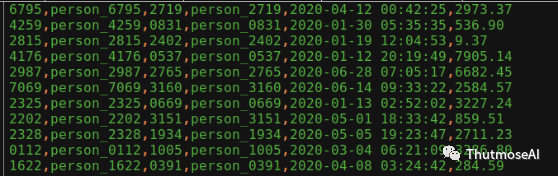
图1数据示例
图中的数据时间戳在测试中进行了调整,进入到系统中的时间戳没有采用如图所示的非严格的RFC3339格式,而是使用与1970-01-0100:00:00(UTC)时间的差(到毫秒)的时间戳表示方式(8bytes的长整型),进入到系统中的金额数据也没有采用如图所示的Double标准双精度浮点数类型表示,而是采用Bigdicemal非基本类型来存储交易金额,因为交易金额很大时,与历史记录聚合很可能发生损失精度的情况,由于系统错误导致的财产损失这是不允许的。为便于测试,实际数据均由计算机随机生成,实体数限制为10w个并按照上述格式和数据库语法格式写入各数据库。
因为每款图数据库使用的语言和方式都不一样,本次主要测评过程以图谱建模的终结构为标准,使用的KnowledgeGraph建模如下:

2统计结果说明
对于任何一个测试,每个操作过程重复运行5次,且终的统计结果是5次测试结果的算数平均值。
每次测试进行之前均重启数据库服务,避免缓存对于之前执行获得的结果产生影响。
本文中所说的延迟(latency)是指全部完成该操作所耗费的时间,例如针对多条记录的查询操作,其时间延迟是指完全将结果获取到客户端后,相对于请求发出时间之间的间隔。吞吐量(throughput)是单位时间内完整完成该操作的数量。
3AbutionGDB与其他数据库单节点对比测试
3.1测试环境及步骤说明
所有数据库的对比测试在同一台8H16G的阿里云服务器上进行,该服务器的详细配置如下:
架构: x86_64
CPU: 8
CPU运行模式: 32-bit, 64-bit
Size: 16 GB
每个核的线程数:2
每个座的核数: 4
座: 1
厂商ID: GenuineIntel
CPU系列: 6
型号: 85
型号名称: Intel(R)Xeon(R)Platinum8269CYCPU@2.50GHz
CPUMHz: 2499.998
BogoMIPS: 4999.99
超管理器厂商: KVM
虚拟化类型: 完全
LSB Version: core-4.1-amd64:core-4.1-noarch
Description: CentOS Linux release 8.2.2004 (Core)
本测试将AbutionGDB与Neo4j,JanusGraph,TigerGraph等图数据库进行了对比,所测试的Neo4j版本为3.5.24;JanusGraph的版本为0.5.2(使用Hbase后端存储);TigerGraph的版本为3.0.0,而AbutionGDB的测试版本为1.3.0,截止至2021年,皆为jdk-1.8支持下的新版本。
在测试时,AbutionGDB、Janasgraph、Neo4j均使用JavaAPI并结合各自的查询语言进行数据操作,由于TigerGraph只提供了HTTP接口,在测试中我们采用Java语言的Apache HTTP lib库来编写测试程序。
AbutionGDB提供更优异的异步接口,支持使用Flink作为大规模实时数据源写入数据,但Janasgraph、Neo4j、TigerGraph均不支持。只有AbutionGDB和TigerGraph可以使用Kafka作为实时数据源写入数据,为了测试一致性及公平性,仅使用各自推荐的同步接口方式进行读写测试。
在本次测试中,AbutionGDB、Janasgraph及TigerGraph都采用默认配置,Neo4j则只修改dbms.memory.heap.initial_size和dbms.memory.heap.max_size,由默认的512m改到5g,以大程度发挥Neo4j性能。
为避免网络延迟的影响,应用与数据库均在同一台服务器上运行。为更进一步控制变量,本测试确保在对每个数据库进行测试时只有该数据库运行,因此数据库所能占用的CPU资源高可达。
本测试测试了各个数据库在不同客户端连接数同时写入和读取不同批量数据的表现,且每种情况均进行至少5次测试,终结果为5次测试结果的平均值。同时为了避免测试与测试之间的干扰,每次测试结束后,都会删除数据,重启数据库服务并且等待5分钟左右。
3.2 写入性能对比
数据库的一个写入请求可以包含一条或多条记录,性能结果取每个客户端每秒内同时写入数据量的总和,并取多次平均值。总而言之,一次请求里包含的记录条数越多,写入性能就会相应提升。
同时,一个数据库可以支持多个客户端链接,链接数增加,其系统总的插入通吐量会相应增加。因此测试中,对于每一个数据库,都会测试一个客户端和多个客户端连接的情况。
在AbutionGDB中,可以定义任意多维度的指标列,其中动态聚合的存储模型是其特有的,其中预计算模型可以大大提高查询性能,而静态历史数据的存储模型是与Janasgraph、Neo4j、TigerGraph一致的,为了凸显写入事件的速率和查询性能的公平性,我们定义每一条完整的原始交易数据入库完成才作为写入一条数据,即一条事件数, 而不是以每个实体或者每条关系作为一条数据。
3.2.1 AbutionGDB批量实时写入结果
此测试中,基于AbutionGDB强大的吞吐量,我们专门把写入事件数的区间拉大,按照每次请求包含1,100,1000,1000,100000,200000条事件记录各进行了测试,同时也测试了不同客户端连接数的数据。具体结果如下:
因本测试将3条图数据统一归为1条事件数统计(每条事件包含2个实体1条关系),按照数据库写入性能标准,以上测试结果应该均乘以3即为真实写入速率。具体结果如下:
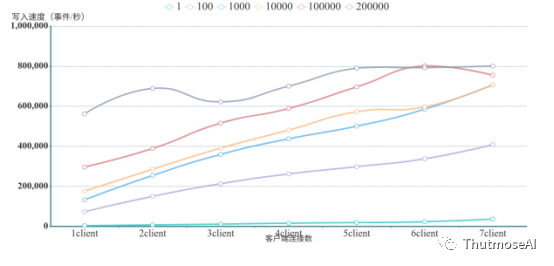
上述结果清楚表明,AbutionGDB的写入速度随客户端连接数的增加近乎线性增加,而且随单请求中记录数目的增加而增加。在七个客户端下,一个请求,写入1条数据时,AbutionGDB就有超过10,000记录/秒(30,000条图数据/秒)的写入速度。在一个写入请求200,000条记录时,在7个客户端同时写入时的情况下,AbutionGDB有高达267,015记录/秒(801,045条图数据/秒)的写入速度。同时,从上图中可以看出,这个速度并非AbutionGDB写入速度的上限,该速度还会随客户端数目的增加而增加。
3.2.2 Neo4j批量实时写入结果
在测试中,我们尝试了两种方式来更全面的测试Neo4j写入性能,种是传统的JDBC方式,通过DriverManager接收SQL,同时禁用了AutoCommit,采用批量手动提交commit的方式,Neo4j本身没有此项功能支持,需要额外下载neo4j-jdbc-driver和neo4j-jdbc-bolt扩展包支持;第二种是使用的是官方推荐的bolt Driver连接方式,此方是没有commit方法,Neo4j自动提交数据变更,所以测试只能通过客户端的连接数观察写入性能,为此,我们做了5组测试来分别观察客户端的连接数对于写入性能的影响。由于Neo4j不支持BigDecimal数据类型,因而交易时间将采用Double来存储。
通过测试发现,两种方式对于写入速率没有实质性差距,Neo4j的批量提交写入并不能有效提升其写入效率,因此仅仅记录了Neo4j连续写入的多个客户端同时写入来达到批量写入数据的效果。结果如下:
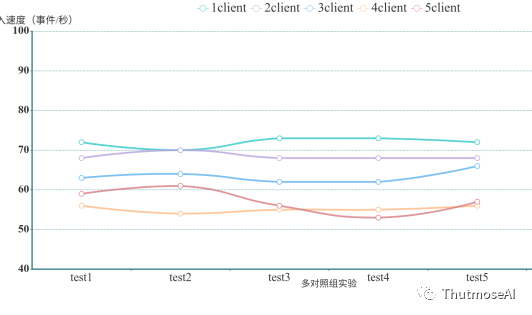
从上述结果表可以看出,Neo4j仅适用于单客户端单条记录的写入,多组对照实验结果几乎相同,证明其写入性能并不会由于客户端链接数量的增加或单请求中记录条数的增加而显著改变。
3.2.3 JanusGraph批量实时写入结果
在测试中发现,JanusGraph的写入吞吐量与客户端连接数没有太大关系,而与批处理时单请求中的记录数相关。批请求中记录数目越大,其吞吐量也越大,但是当数据量达到1w左右的时候就出现了严重的写入抖动,速率在3000-1w/s间波动。由于客户端连接数对JanusGraph的吞吐量影响较小,本测试只给出JanusGraph在单客户端和双客户端连接情况下的测试结果,且分别对每个客户端按照每次请求包含1,100,300,500,1000,2000,10000,20000条事件记录作出测试。测试结果计算为每秒写入的数据总量,多秒完成的写入计算结果为平均值。测试结果如下:
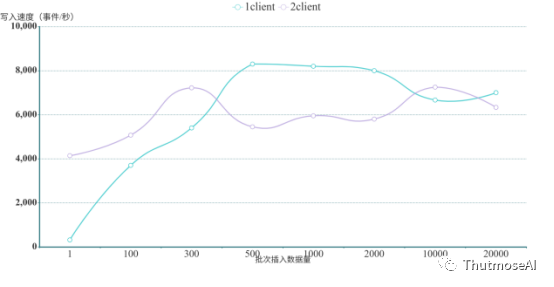
上述结果表明,JanusGraph的写入速度随单请求中的事件数目的增加而增加,但终增长速度趋缓,并在每次提交事件数在1000条左右到达写入佳性能,同时也到达了JanusGraph的写入瓶颈,再随着每批次写入数据的不断增加,写入性能不增反降,且终写入速度维持在7000事件/秒上下。
3.2.3 TigerGraph批量实时写入结果
本次我们测试的是TigerGraph,由于TigerGraph官方只提供基于HTTP的REST使用接口,此方式写入较慢,无法批量写入,所以我们使用开源的jdbc方式,且修补了一些版本匹配问题,此方式其实是HTTP接口的一种封装。Jdbc提供了3种写入方法,提交job的方式是离线导入,第2种方法PreparedStatement的写入语法对Double数据类型参数支持不友好,终我们选择使用Statement方法写入,并以默认的覆盖历史数据的形式写入新数据,对不同对照组的Batch进行批量提交写入,Statement的方式可以以批量提交的方式进行写入,与AbutionGDB,Neo4j,JanusGraph测试方式一致。
在测试过程中发现,TigerGraph的写入性能与客户端连接数没有太大关系,与批处理时单请求中的记录数也没有太大关系,反而会略微拉低其它客户端的写入能力,所以本测试只记录了1-5个客户端的同时写性能,测试结果如下:
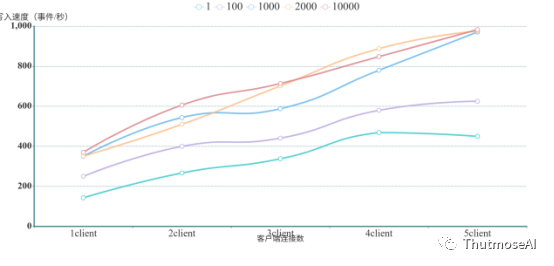
上述数据表明,基于HTTP接口的数据写入方式并没有很高效,随着客户端连接数和实时写入数据量的增加,写入性能成弱线性增长。
TigerGraph离线写入测试
鉴于以上TigerGraph的测试结果不是很高效,我们专门对TigerGraph测试了离线写入能力,即load job数据写入方式,这是官方文档推荐的做法。为了记录离线写入性能,我们使用与AbutionGDB,Neo4j,JanusGraph相同的数据生成程序随机生成一批数据到文件,并将每一条事件记录拆分为节点数据和关系数据两个文件分别等待写入,然后预先分别对每批次写入数据的5个对照组预先创建LOADING JOB(不计入写入耗时中),后在gsql脚本中执行批量导入JOB并记录耗时,终统计得出每秒写入性能。经测试一两条、几百条等少批量数据导入对性能表现不明显,为了节省测试时间,避免生成离线数据的繁琐过程,我们将从100条每批写入开始记录结果。
在测试过程中发现,TigerGraph的写入性能与客户端连接数没有关系,反而会均分掉其它客户端的写入能力,所以本测试只对TigerGraph在1和2客户端连接的情况下的性能进行了测试和分析,测试结果如下:
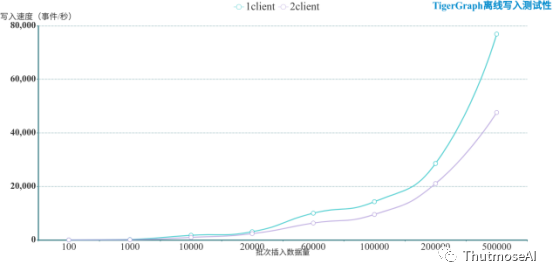
上述结果表明,TigerGraph的离线写入速度随单请求中记录数目的增加而增加,入库速率与批次入库数量成正比增长,数据写入及与节点个数成弱线性增长,也与实时写入测试的结果增长趋势成线性关系。
注意:本测试不与AbutionGDB,Neo4j,JanusGraph,TigerGraph已测试过的结果进行比较,因为实时写入涉及的数据库cache和flush的性能是性能测试和稳定性测试的重要指标之一,与离线数据测试机理不同,TigerGraph离线导入使用MapReduce并行写入,这与AbutionGDB和JanusGraph中的离线导入方式基本相同,故此不再展开分别测试。
TigerGraph实时写二次测试
由于以上TigerGraph的测试结果与官方报道的性能差距太大,所以我们决定增加测试Kafka的写入接口,为了尽量保证公平性,我们还是使用与AbutionGDB,Neo4j,JanusGraph相同的数据生成程序随机生成一批数据到Kafka生产者,并在TigerGraph中实时接收批次事件数据。每轮测试我们都将重启TigerGraph以清除缓存影响,Kafka程序无法准确记录写入速率,为了反映写入速率,我们使用TigerGraph本身的计时器,重启时同时也清空了上一轮的计时重新计算写入,多轮对照测试结果取均值,结果几乎无偏差。
在测试过程中发现,Kafka接口无法启动多个客户端在同一台服务器,也必须是配置使用所有的Kafka分区才能启动写入,即默认了接收所有传来的数据,所以TigerGraph单节点写入与多客户端没有太大关系,因为已经是使用大化资源了,所以我们只对单一客户端测试,这与AbutionGDB,Neo4j,JanusGraph测试使用的资源几乎是一致的。测试TigerGraph数据写入结果截图如下:
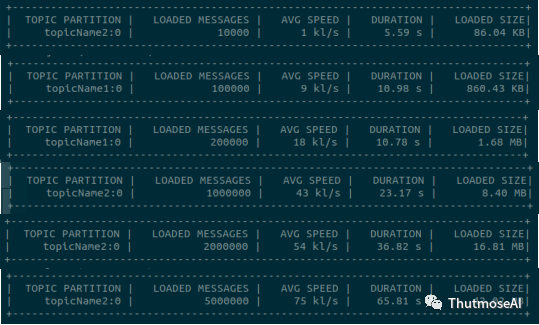
结果中,LOADED MESSAGES表示每批次的实时写入事件记录数(包含两个实体和一条关系),DURATION表示这批次数据入库的时间。
为了进一步去除网络数据传输等因素影响,我们对每批次写入耗时统一减去3-4秒的数据接入响应,包括:Kafka生产者被接入消费者的时间,一般为1秒左右;以及数据实时随机生成耗时,一般为1秒左右。终得到超低误差的实时写入性能如下:
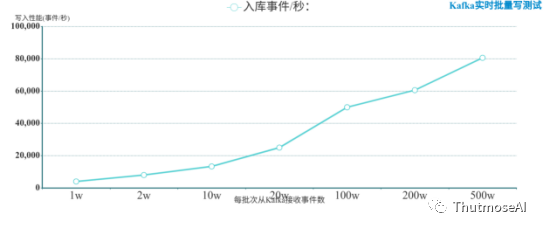 上述结果表明,TigerGraph对于超大规模数据实时写性能表现较好,同时也反映了想要获取更好的性能需要更多的服务器资源。测试中TigerGraph的Kafka实时写入和离线写入性能终趋向一致,入库速率与批次入库数量成正比增长。TigerGraph的写入速度与单请求中记录数目具有极大关系,且随着单请求中记录数目的增加而增加,并始终保持匀速正增长,但增速缓慢。从图中可以看出,TigerGraph在本测试实时每批次写入5,000,000条事件记录和离线每批次写入500,000条事件记录时达到高写入性能,写入速度大约为80,000事件记录/秒。
上述结果表明,TigerGraph对于超大规模数据实时写性能表现较好,同时也反映了想要获取更好的性能需要更多的服务器资源。测试中TigerGraph的Kafka实时写入和离线写入性能终趋向一致,入库速率与批次入库数量成正比增长。TigerGraph的写入速度与单请求中记录数目具有极大关系,且随着单请求中记录数目的增加而增加,并始终保持匀速正增长,但增速缓慢。从图中可以看出,TigerGraph在本测试实时每批次写入5,000,000条事件记录和离线每批次写入500,000条事件记录时达到高写入性能,写入速度大约为80,000事件记录/秒。
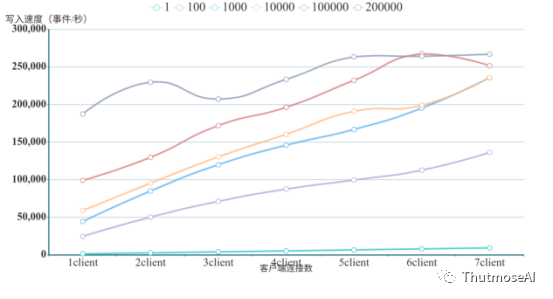
3.2.4 各数据库佳性能对比
基于以上的测试数据,将各数据库测试出来的佳速度进行对比,结果如下:
注意:因为TigerGraph多客户端实时写性能很差,且变化很小,所以这里使用Kafka的实时写加入比较,但又因Kafka接入无多客户端,所以将TigerGraph每批次写入的佳性能并入比较,相较于AbutionGDB,Neo4j,JanusGraph有一定优势为便于对比,在这里适当不计。
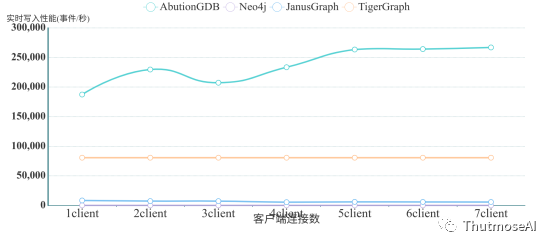
从图中可以看出,AbutionGDB是4个图数据库中一个写入速度随客户端一致线性增加的数据库,且其写入速度远远高于其他三个数据库,也是一个突破十万事件记录/秒写入速度的图数据库。而TigerGraph、JanusGraph和Neo4j在测试中都展示出了瓶颈。JanusGraph虽然在客户端较少的情况下就有接近1w的事件(约2.5w实体和关系)写入速度,但是其速度无法因客户端增加而线性增加,从图可知JanusGraph的瓶颈在1w事件记录/秒。而TigerGraph的实时写不会因为客户端的增加而显著增加写入性能,始终维持在一个低水平状态,但在Kafka接口中达到了较好的写入性能,不过只对于大规模量级数据表现较好。对于Neo4j,其写入性能不会因为客户端的增加而提高,反而略微下降,没有很好的并行性。
综上所述,AbutionGDB在多客户端连接同步写入的速度远远高于同等条件下的TigerGraph、JanusGraph和Neo4j等市场主流图数据库。AbutionGDB在7个客户端连接同时写入的情况下可达到~270,000事件记录/秒的写入速度(约810,000条实体与关系),是已测得JanusGraph的大写入速度的33倍,是TigerGraph普通接口大写入速度的222倍,是Neo4j大写入速度的3709倍。
3.3 读取性能对比
本测试做了简单的查询测试,就是将插入的数据全部读出并做一度关系计算与过滤出邻居数大于5的人。因为各大数据库的性能差异很大,为节省测试时间,我们使用一个客户端查询不同的记录条数并进行计算。测试结果如下:
为了方便查看,我们对每个查询耗时转换为统计查询性能:
从图表中可以看出,AbutionGDB的单机大OLAP读取速度在15,000记录/毫秒左右,TigerGraph的大读取速度在12,000记录/毫秒左右,性能几乎相同。在AbutionGDB中,实现原理是基于特有的预计算模型,数据在写入的时候就已经自动完成了部分规则统计,查询时仅需少量后计算资源即可得到结果,这与实时数据仓库的特性是类似的。在TigerGraph中,因其查询语句中支持累加器操作,所以我们针对测试场景定制了一个查询函数,用于累计每个实体的一度关系,它将并行的将函数预先运行到每个实体中,安装函数的步骤会花费几秒钟的时间,以后直接运行查询就会很快,这有点类似AbutionGDB的预计算模型机制。JanusGraph因为不支持自定义id,查询起来需要先匹配节点属性做聚合,再做一度关系计算,每次计算量都会比AbutionGDB和TigerGraph大至少一倍,所以计算速度很慢。而Neo4j与JanusGraph一样,导入数据时都会自增生成一个ID来存储节点,即使相同的事件数据也会重新得到一个新的存储id,想要加速查询只能对属性添加索引支持,所以聚合类查询都很慢,但因为是原生图存储,数据量少的情况下会比JanusGraph略快一些。所以从测试结果来看,AbutionGDB的查询吞吐量远高于JanusGraph和Neo4j。
综上可以看到,AbutionGDB写入性能具有良好的横向扩展(scale-out)的能力,对于多节点构成的集群也能提供的扩展支持,而读取性能也具有千万级/秒的速度,对于大规模的大多数数据统计查询场景都能在1秒内返回结果。
来源 https://www.modb.pro/db/47968
